使用docker构建hadoop+spark全分布式集群环境
使用docker构建hadoop+spark全分布式集群环境
之所以用docker来构建集群环境而不采用虚拟机有如下方面的原因
1 在一台8G内存的笔记本上也可以运行全分布式集群环境,采用虚拟机(如vmware)的话根本是不可能的。
2 构建好镜像后,可以在任何平台上运行。方便移植和学习
3 按照微服务的设计原则,应该是最小化服务的方式,但是东西学的太死就没有必要了
集群的架构规划如下:
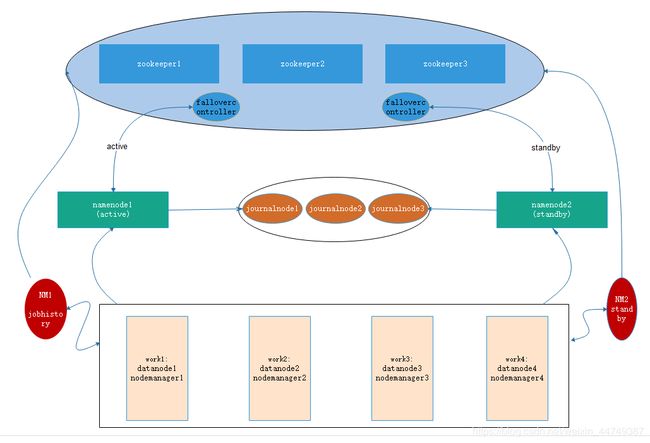
集群的网络规划如下:

1.构建ssh免密码登陆的centos镜像
为了将来方便控制容器的hostname,还是编程的方式来控制逻辑。hostname的控制在本文中非常重要,因为它将来会决定容器的启动性质。创建如下python脚本,将其命令为hostsshfileindocker.py:
# _*_ coding:utf-8 _*_
from sys import argv
def writeFile(filePath, data):
'''
函数的作用是向hosts,authorized_keys和known_hosts写入信息
:param filePath: 文件绝对路径
:param data: 要写入的数据
:return:
'''
with open(filePath, 'a+') as f:
f.write(data)
if __name__ == '__main__':
# 处理hosts文件
# 从命令行获取hostname ip
hostsdata = ""
a = 1
for i in argv[1:]:
# argv[0] 是文件名,忽略掉。构建字符串数据
a += 1
if a % 2 == 1:
hostsdata = hostsdata + i + "\n"
else:
hostsdata = hostsdata + i + " "
try:
writeFile(r"/etc/hosts",hostsdata)
except Exception as e:
pass
# 处理authorized_keys
pubkeys = r"ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC+/iX0LxBFEwbd77XeZjzCkJBngEEBHe+ckr1ooB2vwd417SV6FbkxsdwWzUHh7i1qqGMv/XDcsjfxfrmLAo7ZkrfRmt0rxDlHuPp4a4v0Nwpkl4EagFFqnrfy8UCOLks6GsaneZbXlWiguGsGlmU8ZTxVFCZzF1VQ41drN57c78Z6f+fN45Ot5UzjG7gFv67SeMYOdxVh63Yxk+VCHsylwZSqzMB5Wb6iyhP7i8XFVezHzxM26WGJRTKMr/D7oGwBqDX7Qxb8Hs5XEQKntr7TKApvrJ2ZqBdcszO5lus0zMbaZE77gtGsddfe45ffJlYCdB+RaAs7trLIp root@"
key = ""
for i in argv[1::2]:
key = key + pubkeys + i + "\n"
try:
writeFile(r"/root/.ssh/authorized_keys", key)
except Exception as e:
pass
# 处理hadoop下的works文件
hadoopworks = ""
for i in argv[1::2]:
if "work" in i:
hadoopworks = hadoopworks + i + "\n"
try:
writeFile(r"/hadoop-3.2.0/etc/hadoop/workers",hadoopworks)
except Exception as e:
pass
说明:这里的pubkeys是随便找一台机器生成的id_rsa.pub的前缀。hostname将会通过命令行参数传递进来。
创建如下shell脚本,命名为:clusterstartindocker.sh
#!/bin/sh
# 脚本必须要传入hostname1 ip1 hostname2 ip2这样的格式
# 执行python脚本
echo "Processing system files\n"
# 这里$*必须不能加引号,否则pyhon脚本传参会出问题
python /hostsshfileindocker.py $*
echo "start sshd\n"
/usr/sbin/sshd-keygen -A
/usr/sbin/sshd
# docker前台运行 加一行这个防止docker退出主进程
/bin/sh
hostsshfileindocker.py和clusterstartindocker.sh将会被打包到镜像文件中,其中clusterstartindocker.sh是为了控制服务的启动和向hostsshfileindocker.py传递参数。
准备工作做好以后就可以通过Dockerfile文件来构建镜像了。创建如下Dockerfile文件:
FROM centos:7.6.1810
COPY ./ssh/* /root/.ssh/
RUN yum install -y openssl openssh-server openssh-clients\
&& sed -i 's/#PermitRootLogin yes/PermitRootLogin yes/g' /etc/ssh/sshd_config \
&& sed -i 's/#PubkeyAuthentication yes/PubkeyAuthentication yes/g' /etc/ssh/sshd_config \
&& sed -i 's/# StrictHostKeyChecking ask/StrictHostKeyChecking no/g' /etc/ssh/ssh_config \
&& yum install -y python3
WORKDIR /
COPY ./*indocker* /
CMD /bin/bash
将Dockerfile文件和以上文件放进同一个文件夹,如下:

运行docker build -t hu/centos-sshd-python:v1.1 . (注意这里有个.)便可以构建如下镜像:

这里对以上的构建方式作以下重点说明:
1 /etc/ssh/ssh_config文件中StrictHostKeyChecking参数一定得设置为no,如若不然,每次尝试登陆时ssh服务将会询问,对于将来hadoop的namenode防止脑裂问题将会不成功。
2 ssh服务openssl openssh-server openssh-clients都得安装
3 对于Dockerfile命令RUN,能一次写完就一次写完,否则镜像构建的层数将会增加。
4 在Dockerfile中CMD命令为/bin/bash,而clusterstartindocker.sh最后一行为/bin/sh,这里的目是将来的启动容器的方式可以这样:docker run xxx hu/centos-sshd-python:v1.1 sh clusterstartindocker.sh xxx 。
docker的容器没有后台执行的概念,它的本质其实是一个进程,所以这里不能让执行的进程在执行完命令后就退出,这样的话,容器也会跟着退出,必须让它一直运行,且以前台运行的方式执行。
2.构建zookeeper集群
有了上面的基础以后,就可以很方便的构建zk集群。在apache官网下载zk,oracle官网下载jdk,并解压到一个新的目录。
下载好zk以后,修改配置文件conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#配置ZK的数据目录
dataDir=/zookeeper-3.4.12/data
#配置ZK的日志目录
dataLogDir=/zookeeper-3.4.12/datalog
# the port at which the clients will connect
#用于接收客户端请求的端口号
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#ZK集群节点配置,端口号2888用于集群节点之间数据通信,端口号3888用于集群中Leader选举
server.1=zookeeper1:2888:3888
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2888:3888
并在新创建的目录中创建一个新的Dockerfile,如下:
FROM hu/centos-sshd-python:v1.1
COPY ./jdk1.8.0_201 /jdk1.8.0_201/
COPY ./zookeeper-3.4.12 /zookeeper-3.4.12/
COPY ./*indocker* /
WORKDIR /
RUN echo -e "export JAVA_HOME=/jdk1.8.0_201\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar\nexport ZOOKEEPER_HOME=/zookeeper-3.4.12\nexport PATH=\$PATH:\$ZOOKEEPER_HOME/bin:\$JAVA_HOME/bin" >> /etc/profile
ENV JAVA_HOME=/jdk1.8.0_201 \
CLASSPATH=.:/jdk1.8.0_201/lib/dt.jar:/jdk1.8.0_201/lib/tools.jar \
ZOOKEEPER_HOME=/zookeeper-3.4.12 \
PATH=$PATH:/zookeeper-3.4.12/bin:/jdk1.8.0_201/bin
CMD /bin/bash
这里备注一下COPY和linux中cp的区别:
Dockerfile中:COPY ./zookeeper-3.4.12 /zookeeper-3.4.12/ 表示把zookeeper-3.4.12文件夹下面的所有文件复制到镜像文件的/zookeeper-3.4.12文件下,如果不存在对应文件夹,将会自动创建。
linux中:则表示将zookeeper-3.4.12这个文件夹复制到/zookeeper-3.4.12/
关于ENV最好写绝对路径,否则将会因为docker存在镜像分层的原因,在引用环境变量时,由于上层镜像的环境变量可能为空而出现问题。如:
ENV JAVA_HOME=/jdk1.8.0_201 \
PATH=$PATH:/zookeeper-3.4.12/bin:$JAVA_HOME/bin
由于上层JAVA_HOME为空,本层的PATH将会是PATH=$PATH:/zookeeper-3.4.12/bin:/bin,这不是我们想要的。
clusterstartindocker.sh文件也要增加zk的启动代码
#!/bin/sh
# 脚本必须要传入hostname1 ip1 hostname2 ip2这样的格式
# 执行python脚本
echo "Processing system files\n"
# 这里$*必须不能加引号,否则pyhon脚本传参会出问题
python /hostsshfileindocker.py $*
echo "start sshd\n"
/usr/sbin/sshd-keygen -A
/usr/sbin/sshd
#!/bin/sh
# 设置环境变量
export JAVA_HOME=/jdk1.8.0_201
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin
# 根据hostname设置zookeeper的myid
if [ $(hostname) = 'zookeeper1' ]
then
echo 1 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper2' ]
then
echo 2 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper3' ]
then
echo 3 > /zookeeper-3.4.12/data/myid
fi
# 启动zookeeper
/zookeeper-3.4.12/bin/zkServer.sh start
# docker前台运行 加一行这个防止docker退出主进程
/bin/sh
目录下的文件如下所示:

有了以上准备工作就可以开始构建镜像了。构建结果如下:

3.构建hadoop3.2.0 HA集群
参考资料:link.
在官网下载hadoop以后,解压并修改主要配置文件
3.1 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
<!-- 定义文件系统的实现,默认是file:///本地文件系统 需要我们改成 hdfs://分布式文件存储系统
使用 fs.default.name 还是 使用 fs.defaultFS ,要首先判断是否开启了 NN 的HA (namenode 的 highavaliable),如果开启了nn ha,那么就用fs.defaultFS,在单一namenode的情况下,就用 fs.default.name
如果是高可用 hdfs://后面配的是namenodeservicename,具体的端口都是在hdfs-site.xml中配置
-->
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
file:///hadoop-3.2.0/userdata/tmp
io.file.buffer.size
131072
该属性值单位为KB,131072KB即为默认的64M
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 60*12-->
fs.trash.interval
720
<!-- hdfs自动故障转移配置 -->
ha.zookeeper.quorum
zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
>
3.2 hadoop-env.sh
增加修改如下内容:
export JAVA_HOME=/jdk1.8.0_201
3.3 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>dfs.replication >
>1 >
>
<!-- the logical name for this new nameservice -->
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
最少两个,建议3个,最好不要超过5个
<!-- the fully-qualified RPC address for each NameNode to listen on -->
dfs.namenode.rpc-address.mycluster.nn1
namenode1:8020
dfs.namenode.rpc-address.mycluster.nn2
namenode2:8020
<!-- the fully-qualified HTTP address for each NameNode to listen on -->
dfs.namenode.http-address.mycluster.nn1
namenode1:50070
dfs.namenode.http-address.mycluster.nn2
namenode2:50070
<!-- 指定namenode在JournalNode上的存放位置,另外的配置方式是nfs -->
dfs.namenode.shared.edits.dir
qjournal://journalnode1:8485;journalnode2:8485;journalnode3:8485/mycluster
<!-- the Java class that HDFS clients use to contact the Active NameNode -->
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
<!-- 防止脑裂 故障转移期间使用的防护方法配置为以回车符分隔的列表,将按顺序尝试该列表,直到指示防护成功为止。 -->
>dfs.ha.fencing.methods >
>
sshfence
shell(/bin/true)
>
>
<!-- 隔离机制免密码登陆 -->
>dfs.ha.fencing.ssh.private-key-files >
>/root/.ssh/id_rsa >
>
<!-- the path where the JournalNode daemon will store its local state -->
dfs.journalnode.edits.dir
/hadoop-3.2.0/userdata/journalnodedata
<!-- 关闭权限检查 -->
dfs.permissions
false
<!--开启NameNode失败自动切换-->
dfs.ha.automatic-failover.enabled
true
>
>dfs.namenode.name.dir >
>file:///hadoop-3.2.0/userdata/namenodedata >
>设置存放NameNode的文件路径 >
>
<!--datanode数据目录可用逗号分割挂载多个盘-->
dfs.datanode.data.dir
file:///hadoop-3.2.0/userdata/datanodedata
>
>dfs.journalnode.http-address >
>0.0.0.0:8480 >
>
>
>dfs.journalnode.rpc-address >
>0.0.0.0:8485 >
>
>
3.4 5.4mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
>
>
>mapreduce.framwork.name >
>yarn >
>
<!-- 指定mapreduce jobhistory地址 -->
mapreduce.jobhistory.address
resourcemanager1:10020
<!-- 任务历史服务器的web地址 -->
mapreduce.jobhistory.webapp.address
resourcemanager1:19888
>
3.5 yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
>
<!-- yarn shuffle -->
yarn.nodemanager.aux-services
mapreduce_shuffle
<!-- 日志聚合 -->
yarn.log-aggregation-enable
true
yarn.log.server.url
http://resourcemanager1:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
10800
yarn.nodemanager.remote-app-log-dir
hdfs://mycluster/user/yarn-logs/
>
>yarn.resourcemanager.ha.enabled >
>true >
>
>
>yarn.resourcemanager.cluster-id >
>cluster1 >
>
>
>yarn.resourcemanager.ha.rm-ids >
>rm1,rm2 >
>
>
>yarn.resourcemanager.hostname.rm1 >
>resourcemanager1 >
>
>
>yarn.resourcemanager.hostname.rm2 >
>resourcemanager2 >
>
>
>yarn.resourcemanager.webapp.address.rm1 >
>resourcemanager1:8088 >
>
>
>yarn.resourcemanager.webapp.address.rm2 >
>resourcemanager2:8088 >
>
<!-- Address of the ZK-quorum. Used both for the state-store and embedded leader-election. -->
hadoop.zk.address
zookeeper1:2181,zookeeper1:2181,zookeeper1:2181
<!-- 启用自动恢复 -->
yarn.resourcemanager.recovery.enabled
true
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
>
修改clusterstartindocker.sh
[root@virtual-machine1 centos-sshd-python-zookeeper-hadoop]# cat clusterstartindocker.sh
#!/bin/sh
# 脚本必须要传入hostname1 ip1 hostname2 ip2这样的格式
# 执行python脚本
echo "Processing system files"
# 这里$*必须不能加引号,否则pyhon脚本传参会出问题
python /hostsshfileindocker.py $*
echo "start sshd"
/usr/sbin/sshd-keygen -A
/usr/sbin/sshd
#!/bin/sh
# 启动顺序 Zookeeper->JournalNode->格式化NameNode->创建命名空间zkfs->NameNode2拉取Namenode1上的格式化信息->NameNode->Datanode->ResourceManager->NodeManager
# 设置环境变量
export JAVA_HOME=/jdk1.8.0_201
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/zookeeper-3.4.12
export HADOOP_HOME=/hadoop-3.2.0
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# 根据hostname设置zookeeper的myid
if [ $(hostname) = 'zookeeper1' ]
then
echo 1 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper2' ]
then
echo 2 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper3' ]
then
echo 3 > /zookeeper-3.4.12/data/myid
fi
# 启动zookeeper
for i in `awk '{print $1}' /etc/hosts| grep "zookeeper"`
do
if [ $(hostname) = $i ]
then
echo "start journalnode"
/zookeeper-3.4.12/bin/zkServer.sh start
fi
done
# 启动JournalNode共享存储
for i in `awk '{print $1}' /etc/hosts | grep "journalnode"`
do
if [ $(hostname) = $i ]
then
echo "start journalnode"
/hadoop-3.2.0/sbin/hadoop-daemon.sh start journalnode
fi
done
sleep 15
# 格式化NameNode1和创建命名空间zkfs
if [ $(hostname) = 'namenode1' ]
then
echo "format namenode1"
# 格式化NameNode1,此时journalnode的进程必须要先启动才能格式化成功
hadoop namenode -format
sleep 1
# 创建命名空间zkfs,目的是为了使用zk的自动选举功能
hdfs zkfc -formatZK
# 这里必须要启动以下namenode1,因为NameNode2拉取Namenode1上的格式化信息时,要调用它的rpc
/hadoop-3.2.0/sbin/hadoop-daemon.sh start namenode
fi
sleep 15
# NameNode2拉取Namenode1上的格式化信息(从active namenode的 {dfs.namenode.name.dir} 目录的内容复制到 standby namenode的{dfs.namenode.name.dir} 目录下)
if [ $(hostname) = 'namenode2' ]
then
#NameNode2拉取Namenode1上的格式化信息
hdfs namenode -bootstrapStandby
# 启动NameNode->Datanode->ResourceManager->NodeManager(为了方便,就在这台机器上启动了)
/hadoop-3.2.0/sbin/start-all.sh
fi
# docker前台运行 加一行这个防止docker退出主进程
/bin/sh
创建Dockerfile
FROM hu/centos-sshd-python-jdk-zookeeper:v1.1
COPY ./hadoop-3.2.0 /hadoop-3.2.0/
COPY ./*indocker* /
WORKDIR /
RUN echo -e "export HADOOP_HOME=/hadoop-3.2.0\nexport PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> /etc/profile \
&& yum -y install psmisc
ENV HADOOP_HOME=/hadoop-3.2.0 \
PATH=$PATH:/hadoop-3.2.0/bin:/hadoop-3.2.0/sbin
CMD /bin/bash
有了以上准备就可以构建镜像了,结果如下:

4. 构建spark on yarn
官网下载对应版本的spark,修改配置文件
4.1 spark-env.sh
export HADOOP_CONF_DIR=/hadoop-3.2.0/etc/hadoop
export JAVA_HOME=/jdk1.8.0_201
export SPARK_DIST_CLASSPATH=$(/hadoop-3.2.0/bin/hadoop classpath)
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://mycluster/user/spark/applicationHistory"
4.2 spark-defaults.conf
spark.yarn.historyServer.address=spark:18080
spark.history.ui.port=18080
spark.eventLog.dir=hdfs://mycluster/user/spark/applicationHistory
spark.eventLog.enabled=true
修改clusterstartindocker.sh
#!/bin/sh
# 脚本必须要传入hostname1 ip1 hostname2 ip2这样的格式
# 执行python脚本
echo "Processing system files"
# 这里$*必须不能加引号,否则pyhon脚本传参会出问题
python /hostsshfileindocker.py $*
echo "start sshd"
/usr/sbin/sshd-keygen -A
/usr/sbin/sshd
#!/bin/sh
# 启动顺序 Zookeeper->JournalNode->格式化NameNode->创建命名空间zkfs->NameNode2拉取Namenode1上的格式化信息->NameNode->Datanode->ResourceManager->NodeManager->JobHistoryServer->sparkhistory
# 设置环境变量
export JAVA_HOME=/jdk1.8.0_201
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/zookeeper-3.4.12
export HADOOP_HOME=/hadoop-3.2.0
export SPARK_HOME=/spark-2.4.3
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
# 根据hostname设置zookeeper的myid
if [ $(hostname) = 'zookeeper1' ]
then
echo 1 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper2' ]
then
echo 2 > /zookeeper-3.4.12/data/myid
elif [ $(hostname) = 'zookeeper3' ]
then
echo 3 > /zookeeper-3.4.12/data/myid
fi
# 启动zookeeper
for i in `awk '{print $1}' /etc/hosts| grep "zookeeper"`
do
if [ $(hostname) = $i ]
then
echo "start journalnode"
/zookeeper-3.4.12/bin/zkServer.sh start
fi
done
# 启动JournalNode共享存储
for i in `awk '{print $1}' /etc/hosts | grep "journalnode"`
do
if [ $(hostname) = $i ]
then
echo "start journalnode"
/hadoop-3.2.0/sbin/hadoop-daemon.sh start journalnode
fi
done
# 格式化NameNode1和创建命名空间zkfs
if [ $(hostname) = 'namenode1' ]
then
sleep 15
echo "format namenode1"
# 格式化NameNode1,此时journalnode的进程必须要先启动才能格式化成功
hadoop namenode -format
sleep 1
# 创建命名空间zkfs,目的是为了使用zk的自动选举功能
hdfs zkfc -formatZK
# 这里必须要启动以下namenode1,因为NameNode2拉取Namenode1上的格式化信息时,要调用它的rpc
/hadoop-3.2.0/sbin/hadoop-daemon.sh start namenode
fi
# NameNode2拉取Namenode1上的格式化信息(从active namenode的 {dfs.namenode.name.dir} 目录的内容复制到 standby namenode的{dfs.namenode.name.dir} 目录下)
if [ $(hostname) = 'namenode2' ]
then
sleep 30
#NameNode2拉取Namenode1上的格式化信息
hdfs namenode -bootstrapStandby
# 启动NameNode->Datanode->ResourceManager->NodeManager(为了方便,就在这台机器上启动了)
/hadoop-3.2.0/sbin/start-all.sh
#启动完成后为spark历史日志创建一个目录,不然spark历史服务器起不来
hadoop fs -mkdir -p /user/spark/applicationHistory
fi
# 启动JobHistoryServer
if [ $(hostname) = 'resourcemanager1' ]
then
sleep 40
/hadoop-3.2.0/sbin/mr-jobhistory-daemon.sh start historyserver
fi
# 启动spark-history-server
if [ $(hostname) = 'spark' ]
then
sleep 40
/spark-2.4.3/sbin/start-history-server.sh
fi
# docker前台运行 加一行这个防止docker退出主进程
/bin/sh
创建Dockerfile
FROM hu/centos-sshd-python-jdk-zookeeper-hadoopha:v1.1
COPY ./spark-2.4.3 /spark-2.4.3/
COPY ./*indocker* /
WORKDIR /
RUN echo -e "export SPARK_HOME=/spark-2.4.3\nexport PATH=\$PATH:\$SPARK_HOME/bin:\$SPARK_HOME/sbin" >> /etc/profile
ENV SPARK_HOME=/spark-2.4.3 \
PATH=$PATH:/spark-2.4.3/bin:/spark-2.4.3/sbin
CMD /bin/bash
构建的最后镜像如下:

5.运行总结
创建一个容器启动脚本:
docker run -d -t --net docker-br0 --name zookeeper1 --hostname zookeeper1 --ip 172.20.0.2 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name zookeeper2 --hostname zookeeper2 --ip 172.20.0.3 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name zookeeper3 --hostname zookeeper3 --ip 172.20.0.4 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name journalnode1 --hostname journalnode1 --ip 172.20.0.5 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name journalnode2 --hostname journalnode2 --ip 172.20.0.6 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name journalnode3 --hostname journalnode3 --ip 172.20.0.7 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name namenode1 --hostname namenode1 --ip 172.20.0.8 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name namenode2 --hostname namenode2 --ip 172.20.0.9 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name work1 --hostname work1 --ip 172.20.0.10 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name work2 --hostname work2 --ip 172.20.0.11 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name work3 --hostname work3 --ip 172.20.0.12 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name work4 --hostname work4 --ip 172.20.0.13 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name resourcemanager1 --hostname resourcemanager1 --ip 172.20.0.14 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
docker run -d -t --net docker-br0 --name resourcemanager2 --hostname resourcemanager2 --ip 172.20.0.15 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
sleep 30
docker run -d -t --net docker-br0 --name spark --hostname spark --ip 172.20.0.16 hu/centos-sshd-python-jdk-zookeeper-hadoopha-spark:v1.1 sh /clusterstartindocker.sh zookeeper1 172.20.0.2 zookeeper2 172.20.0.3 zookeeper3 172.20.0.4 journalnode1 172.20.0.5 journalnode2 172.20.0.6 journalnode3 172.20.0.7 namenode1 172.20.0.8 namenode2 172.20.0.9 work1 172.20.0.10 work2 172.20.0.11 work3 172.20.0.12 work4 172.20.0.13 resourcemanager1 172.20.0.14 resourcemanager2 172.20.0.15 spark 172.20.0.16
启动将会跑起来15个容器,如下图所示: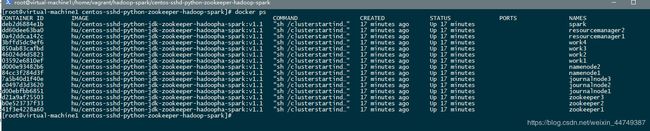
等所有进程运行完毕就来测试一下spark on yarn吧
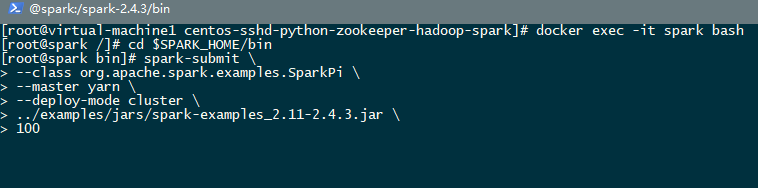

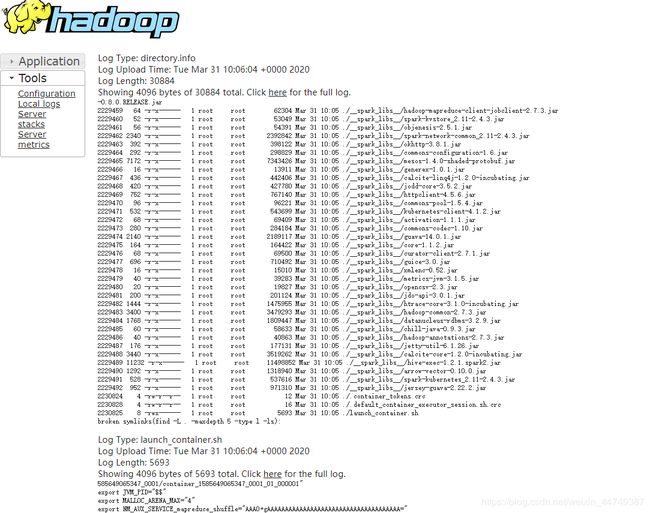
这就是最终运行的结果了。