地铁译:Spark for python developers --- 搭建Spark虚拟环境1
一个多月的地铁阅读时光,阅读《Spark for python developers》电子书,不动笔墨不看书,随手在evernote中做了一下翻译,多年不习英语,自娱自乐。周末整理了一下,发现再多做一点就可基本成文了,于是开始这个地铁译系列。
本章中,我们将为开发搭建一个独立的虚拟环境,通过Spark和Anaconda提供的PyData 库为该环境补充能力。 这些库包括Pandas,Scikit-Learn, Blaze, Matplotlib, Seaborn, 和 Bokeh. 我们的操作如下:
- 使用Anaconda 的Python 发布包搭建开发环境,包括使用 IPython Notebook 环境来完成我们的数据探索任务。
- 安装并使Spark以及 PyData 库正常工作,例如Pandas,Scikit- Learn, Blaze, Matplotlib, 和 Bokeh.
- 构建一个 word count例子程序来保证一切工作正常.
近些年来涌现出了很多数据驱动型的大公司,例如Amazon, Google, Twitter, LinkedIn, 和 Facebook. 这些公司,通过传播分享,透漏它们的基础设施概念,软件实践,以及数据处理框架,已经培育了一个生机勃勃的开源软件社区,形成了企业的技术,系统和软件架构,还包括新型的基础架构,DevOps,虚拟化,云计算和软件定义网络。
受到Google File System (GFS)启发,开源的分布式计算框架Hadoop和MapReduce被开发出来处理PB级数据。在保持低成本的同时克服了扩展的复杂性,着也导致了数据存储的新生,例如近来的数据库技术,列存储数据库 Cassandra, 文档型数据库 MongoDB, 以及图谱数据库Neo4J。
Hadoop, 归功于他处理大数据集的能力,培育了一个巨大的生态系统,通过Pig, Hive, Impala, and Tez完成数据的迭代和交互查询。
当只使用MapReduce的批处理模式时,Hadoop的操作是笨重而繁琐的。Spark 创造了数据分析和处理界的革命,克服了MapReduce 任务磁盘IO和带宽紧张的缺陷。Spark 是用 Scala实现的, 同时原生地集成了 Java Virtual Machine (JVM) 的生态系统. Spark 很早就提供了Python API 并使用PySpark. 基于Java系统的强健表现,使 Spark 的架构和生态系统具有内在的多语言性.
本书聚焦于PySpark 和 PyData 生态系统 Python 在数据密集型处理的学术和科学社区是一个优选编程语言. Python已经发展成了一个丰富多彩的生态系统. Pandas 和 Blaze提供了数据处理的工具库 Scikit-Learn专注在机器学习 Matplotlib, Seaborn, 和 Bokeh完成数据可视化 因此, 本书的目的是使用Spark and Python为数据密集型应用构建一个端到端系统架构. 为了把这些概念付诸实践 我们将分析诸如 Twitter, GitHub, 和 Meetup.这样的社交网络.我们通过访问这些网站来关注Spark 和开源软件社区的社交活动与交互.
构建数据密集型应用需要高度可扩展的基础架构,多语言存储, 无缝的数据集成, 多元分析处理, 和有效的可视化. 下面要描述的数据密集型应用的架构蓝图将贯穿本书的始终. 这是本书的骨干.
我们将发现spark在广阔的PyData 生态系统中的应用场景.
理解数据密集型应用的架构
为了理解数据密集型应用的架构 使用了下面的概念框架 该架构 被设计成5层:
• 基础设施层
• 持久化层
• 集成层
• 分析层
• 参与层
下图描述了数据密集型应用框架的五个分层:
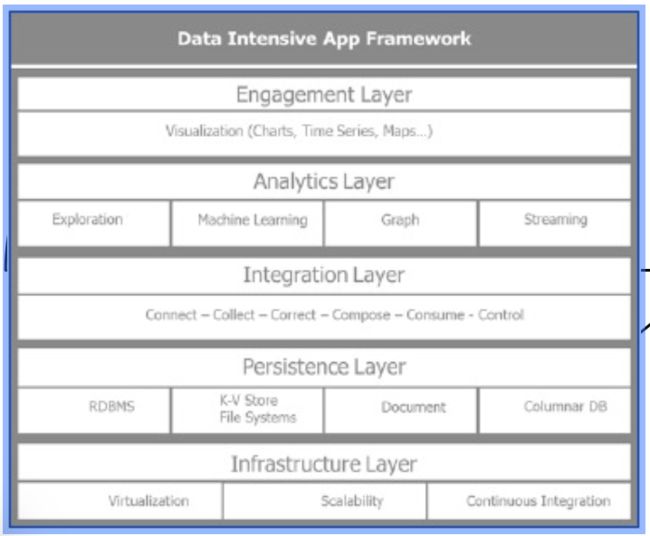
从下往上 我们遍历各层的主要用途.
基础设施层(Infrastructure layer)
基础设施层主要关注虚拟化,扩展性和持续集成. 在实践中, 虚拟化一词, 我们指的是开发环境 的VirtualBox以及Spark 和Anaconda 的虚拟机环境。 如果扩展它,我们可以在云端创建类似的环境。创建一个隔离的开发环境,然后迁移到测试环境,通过DevOps 工具,还可以作为持续集成的一部分被部署到生产环境,例如 Vagrant, Chef, Puppet, 和Docker. Docker 是一个非常流行的开源项目,可以轻松的实现新环境的部署和安装。本书局限于使用VirtualBox构建虚拟机. 从数据密集型应用架构看,我们将在关注扩展性和持续集成前提下只阐述虚拟化的基本步骤.
持久化层(Persistence layer)
持久化层管理了适应于数据需要和形态的各种仓库。它保证了多元数据存储的建立和管理。 这包括关系型数据库如 MySQL和 PostgreSQL;key-value数据存储 Hadoop, Riak, 和 Redis ;列存储数据库如HBase 和 Cassandra; 文档型数据库 MongoDB 和 Couchbase; 图谱数据库如 Neo4j. 持久化层还管理了各种各样的文件系统,如 Hadoop’s HDFS. 它与各种各样的存储系统交互,从原始硬盘到 Amazon S3. 它还管理了各种各样的文件存储格式 如 csv, json, 和parquet(这是一个面向列的格式).
集成层(Integration layer)
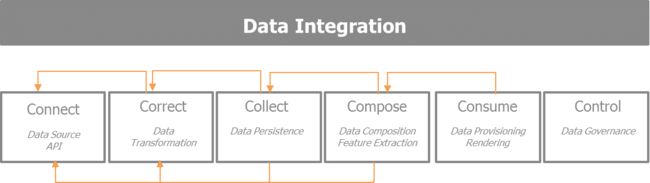
集成层专注于数据的获取、转移、质量、持久化、消费和控制.基本上由以下的5C来驱动: connect, collect, correct, compose和consume.这五个步骤描述了数据的生命周期。它们聚焦于如何获取有兴趣的数据集、探索数据、反复提炼使采集的信息更丰富,为数据消费做好准备. 因此, 这些步骤执行如下的操作:
- Connect: 目标是从各种各样数据源选择最好的方法.如果存在的话,这些数据源会提供APIs,输入格式,数据采集的速率,和提供者的限制.
- Correct: 聚焦于数据转移以便于进一步处理 同时保证维护数据的质量和一致性
- Collect: 哪些数据存储在哪 用什么格式 方便后面阶段的组装和消费
- Compose: 集中关注如何对已采集的各种数据集的混搭, 丰富这些信息能够构建一个引入入胜的数据驱动产品。
- Consume: 关注数据的使用、渲染以及如何使正确的数据在正确的时间达到正确的效果。
- Control: 这是随着数据、组织、参与者的增长,早晚需要的第六个附加步骤,它保证了数据的管控。
下图描述了数据获取以及提炼消费的迭代过程:
分析层(Analytics layer)
分析层是Spark 处理数据的地方,通过各种模型, 算法和机器学习管道从而得出有用的见解. 对我们而言, 本书的分析层使用的是Spark. 我们将在接下来的章节深入挖掘Spark的优良特性. 简而言之,我们使它足够强大以致于在单个同一平台完成多周范式的分析处理。 它允许批处理, 流处理和交互式分析. 在大数据集上的批处理尽管有较长的时延单使我们能够提取模式和见解,也可以在流模式中处理实时事件。 交互和迭代分析更适合数据探索. Spark 提供了Python 和R语言的绑定API,通过SparkSQL 模块和Spark Dataframe, 它提供了非常熟悉的分析接口.
参与层(Engagement layer)
参与层完成与用户的交互,提供了 Dashboards,交互的可视化和告警. 我们将聚焦在 PyData 生态系统提供的工具如Matplotlib, Seaborn, 和Bokeh.