kafka连接flink流计算,实现flink消费kafka的数据
一、启动Kafka集群和flink集群
- 环境变量配置(注:kafka 3台都需要设置,flink仅master设置就好)
[root@master ~]# vim /etc/profile
配置完执行命令:
[root@master ~]# source /etc/profile2.创建执行文件,添加启动服务
[root@master ~]# vim start_kafka.sh
添加(注:3台都需要设置):
zookeeper-server-start.sh
-daemon $KAFKA_HOME/config/zookeeper.properties &
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties &
[root@master ~]# vim start_flink.sh
添加(仅master创建即可):
start-cluster.sh3.分别启动kafka集群
由于kafka集群依赖于zookeeper集群,所以kafka提供了通过kafka去启动zookeeper集群的功能
[root@master ~]# ./start_kafka.sh4.master启动flink集群
[root@master ~]# ./start_flink.sh5.验证:进程及WebUI
(1)进程
[root@master ~]# jps
1488 QuorumPeerMain
2945 Kafka
1977 SecondaryNameNode
2505 JobManager
1900 NameNode
2653 Jps
(2)WebUI
输入:ip:8081

二、编写Flink程序,实现consume kafka的数据
1.代码前的操作及配置
使用idea创建maven创建工程前准备:
Jdk(1.8.0_181)
Scala plugin for IDEA(在IDEA中下载)
Maven(3.5.3)
Scala的jar包(2.11.0)
(1)打开IDEA软件
(2)更改字体(非必须)
导航栏:File—->settings—->appearance&behavior—->appeareance—>override default fonts by(not recommended)
编辑器:file—–>settings—–>editor—->colors&fonts—–>font
控制台:file—–>settings—–>editor—->colors&fonts—–>font—->console font
(3)下载scala for intellij idea的插件(若有则跳过此步)
Flie->settings->plugins

点击下载安装插件,然后重启Intellij IDEA。
(4)使用"new project"创建一个带scala的maven工程

(5)指定程序的groupId和artifactId

(6)指定程序的工程名和路径


(7)更换下载源(根据需要)
安装路径下更改plugins\maven\lib\maven3\conf\settings.xml
然后找到mirrors标签替换即可,瞬间满速下载jar
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
(8)pom.xml配置(主要添加依赖和将项目打成jar包的插件),添加以下依赖:
添加的依赖:
| groupId |
artifactId |
version |
| org.apache.flink |
flink-core |
1.3.2 |
| org.apache.flink |
flink-connector-kafka-0.10_2.11 |
1.3.2 |
| org.apache.kafka |
kafka_2.11 |
0.10.2.0 |
| org.apache.flink |
flink-streaming-java_2.11 |
1.3.2 |
添加的插件:
| groupId |
artifactId |
version |
| org.apache.maven.plugins |
maven-assembly-plugin |
2.4.1 |
具体配置如下:(注意修改maven-assembly-plugin的mainClass为自己主类的路径)
4.0.0
com.wugenqiang.flink
flink_kafka
1.0-SNAPSHOT
2008
2.11.8
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
org.scala-lang
scala-library
${scala.version}
junit
junit
4.4
test
org.specs
specs
1.2.5
test
org.apache.flink
flink-core
1.3.2
compile
org.apache.flink
flink-connector-kafka-0.10_2.11
1.3.2
compile
org.apache.kafka
kafka_2.11
0.10.2.0
compile
org.apache.flink
flink-streaming-java_2.11
1.3.2
compile
src/main/scala
src/test/scala
org.apache.maven.plugins
maven-compiler-plugin
1.8
1.8
org.apache.maven.plugins
maven-jar-plugin
true
false
lib/
com.wugenqiang.test.ReadingFromKafka
org.scala-tools
maven-scala-plugin
compile
testCompile
${scala.version}
-target:jvm-1.5
org.apache.maven.plugins
maven-eclipse-plugin
true
ch.epfl.lamp.sdt.core.scalabuilder
ch.epfl.lamp.sdt.core.scalanature
org.eclipse.jdt.launching.JRE_CONTAINER
ch.epfl.lamp.sdt.launching.SCALA_CONTAINER
org.apache.maven.plugins
maven-assembly-plugin
2.4.1
jar-with-dependencies
com.wugenqiang.flink.ReadingFromKafka
make-assembly
package
single
org.scala-tools
maven-scala-plugin
${scala.version}
2.正式开始,编写Flink程序,实现consume kafka的数据
(1)在scala文件夹下创建scala类
(2)编写flink读取kafka数据的代码
这里就是简单的实现接收kafka的数据,要指定zookeeper以及kafka的集群配置,并指定topic的名字。
最后将consume的数据直接打印出来。
package com.wugenqiang.flink
import java.util.Properties
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
/**
* 用Flink消费kafka
*/
object ReadingFromKafka {
private val ZOOKEEPER_HOST = "master:2181,slave1:2181,slave2:2181"
private val KAFKA_BROKER = "master:9092,slave1:9092,slave2:9092"
private val TRANSACTION_GROUP = "com.wugenqiang.flink"
def main(args : Array[String]){
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.enableCheckpointing(1000)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// configure Kafka consumer
val kafkaProps = new Properties()
kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST)
kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKER)
kafkaProps.setProperty("group.id", TRANSACTION_GROUP)
//topicd的名字是new,schema默认使用SimpleStringSchema()即可
val transaction = env
.addSource(
new FlinkKafkaConsumer08[String]("mastertest", new SimpleStringSchema(), kafkaProps)
)
transaction.print()
env.execute()
}
}(3)编译测试

3.生成kafka到flink的连接jar包
(1)找窗口右边的Maven Projects选项,,点击Lifecycle,再选择打包package(如需重新打包先clean,再package),

(2)成功code为0,项目目录会生成target目录,里面有打好的jar包

4.验证jar包是否可以将kafka数据传输给flink
(1)将jar包传输进centos中指定目录下(比如说:/root,接下来操作在此目录下完成)
(2)kafka生产数据
命令行输入(集群和topic根据实际修改):
[root@master ~]# kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic mastertest(3)flink运行jar进行连接消费kafka数据
(根据实际修改:com.wugenqiang.test.ReadingFromKafka(mainclass名)
root/flink_kafka-1.0-SNAPSHOT-jar-with-dependencies.jar(存路径jar名))
[root@master ~]# flink run -c com.wugenqiang.test.ReadingFromKafka /root/flink_kafka-1.0-SNAPSHOT-jar-with-dependencies.jar(4)打开网址ip:8081查看是否正常启动运行
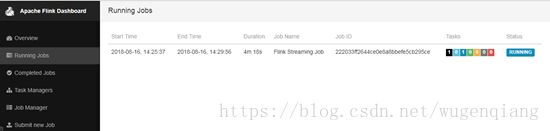
(5)查看flink的标准输出,验证是否正常消费
到taskmanager节点上查看,根据上一步知道所在服务器,在taskmanager工作的服务器上执行命令操作:
[root@slave1 ~]# cd /opt/flink-1.3.2/log/
[root@slave1 log]# tail -F flink-root-taskmanager-0-master.*注:第(2)步输入kafka生产数据,第(5)步接收flink消费数据日志反馈
到此,数据从kafka到flink传输任务完成···