【深度学习系列(六)】:RNN系列(5):RNN模型的奇淫巧技之动态路由
动态路由与注意力机制类似,其主要目的是为序列数据分配对应参数c这点有点类似与注意力机制。从实践中证明,与注意力机制相比,动态路由的算法在精度有所提升。与注意力机制中采用相似度算法计算权重不同,本文采用动态路由的算法来分配权重。动态路由算法使用于胶囊网络,这里主要借鉴这一算法,并运用于RNN中。在实践中证明,CNN或RNN中的一些算法可以相互借鉴,有时会有奇效。具体实践细节看一看本篇。。。
目录
一、动态路由算法
二、RNN中的动态路由算法实践
三、基于动态路由的RNN模型的实践——对路透社新闻的分类
3.1、数据加载
3.2、使用IndyLSTM单元搭建RNN模型
一、动态路由算法
深度学习开创者之一、反向传播等神经网络经典算法的发明人Geoffrey Hinton提出胶囊网络,胶囊网络是一种基于胶囊的新型神经网络,胶囊网络是用囊间动态路由算法来训练的。Hinton等人早期报告中描述胶囊和囊间路由的示意图如下图所示:
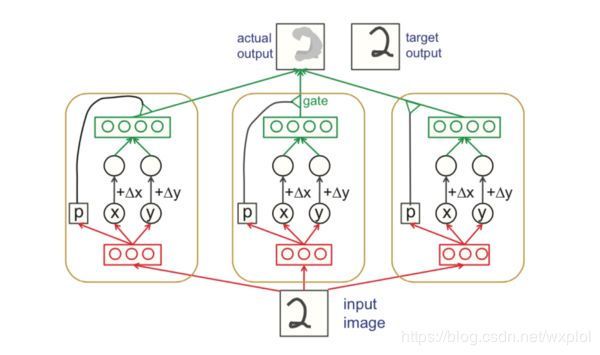
这里简单介绍下胶囊网络中的路由算法,在胶囊网络中,动态路由将胶囊分组形成低层胶囊和父胶囊,并计算父胶囊的输出。具体如何计算呢?在动态路由中,我们用一个变换矩阵去转换输入胶囊的向量,构成一个投票,并用相似的投票分组。这些选票最终成为父胶囊的输出向量。具体计算如下:
- 计算相似度权重(耦合系数)

![]()
其中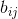 为低层胶囊与上一层胶囊的相似度,在每次迭代之前都会默认初始化为0。这里使用Softmax来归一化相似度,最终得到相似度权重。使用Softmax能够确保所有权重cij均为非负数,且其总和等于一。本质上,softmax强制实施了我在上文描述的系数cij的概率性质。从概念上讲, 计算相似度权重衡量胶囊有多大可能激活胶囊。
为低层胶囊与上一层胶囊的相似度,在每次迭代之前都会默认初始化为0。这里使用Softmax来归一化相似度,最终得到相似度权重。使用Softmax能够确保所有权重cij均为非负数,且其总和等于一。本质上,softmax强制实施了我在上文描述的系数cij的概率性质。从概念上讲, 计算相似度权重衡量胶囊有多大可能激活胶囊。
- 计算胶囊的输出(激活向量)

首先我们知道低层胶囊网络的输出(预测向量)为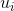 ,这里我们需要变换矩阵与低层胶囊的输出相乘来变换维度,得到新的输出(预测向量)
,这里我们需要变换矩阵与低层胶囊的输出相乘来变换维度,得到新的输出(预测向量)![]() 。
。
![]()
然后根据相似度权重(耦合系数)计算加权和,最终得到胶囊的输出 。
。
![]()
进一步的我们需要通过squash非线性函数,这确保了胶囊的输出的方向被保留下来,而长度被限制在1以下。该函数能够将小向量压缩为零,大向量压缩为单位向量。。
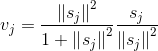
- 更新相似度权重
直观上看,预测向量是来自胶囊的预测(投票)并对胶囊的输出产生影响。如果激活向量与预测向量有很高的相似度,那么我们就可以断定这两个胶囊是高度相关的。这种相似性是通过预测向量和激活向量的标量积来度量的。的更新计算如下:
![]()
因此,相似度得分会同时考虑到可能性和特征属性,而不像神经元只考虑可能性。下面是动态路由的最终伪代码:

参考连接:
CapsNet入门系列之三:囊间动态路由算法
关于胶囊之间的动态路由的理解(基于Hinton的胶囊网络)
如何看待Hinton的论文《Dynamic Routing Between Capsules》?
慢学NLP / Capsule Net 胶囊网络
二、RNN中的动态路由算法实践
将胶囊网络中的动态路由算法应用于RNN模型中还需要作一定的改动,具体如下:
(1)使用全链接网络将RNN的输出结果转化为预测向量![]() ,见shared_routing_uhat()函数
,见shared_routing_uhat()函数
(2)对输入的序列长度作掩码处理,使用动态路由算法支持动态长度的序列数据输入,见masked_routing_iter()函数
(3)对RNN输出的结果进行信息聚合,对动态路由计算后的结果进行dropout处理,使其具有更强的范化能力,见routing_mask类
具体实现代码如下:
def mkMask(input_tensor,maxLen):
'''
计算变长RNN模型的掩码,根据序列长度生成对应的掩码
:param input_tensor:输入标签文本序列的长度list,(batch_size)
:param maxLen:输入标签文本的最大长度
:return:
'''
shape_of_input=tf.shape(input_tensor)
shape_of_output=tf.concat(axis=0,values=[shape_of_input,[maxLen]])
oneDtensor=tf.reshape(input_tensor,shape=(-1,))
flat_mask=tf.sequence_mask(oneDtensor,maxlen=maxLen)
return tf.reshape(flat_mask,shape_of_output)
def shared_routing_uhat(caps,out_caps_num,out_caps_dim):
'''
定义函数,将输入转化成uhat
:param caps: 输入向量,[batch_size,max_len,cap_dims]
:param out_caps_num:输出胶囊的个数
:param out_cap_dim:输出胶囊的维度
:return:
'''
batch_size,max_len=caps.shape[0],caps.shape[1]
caps_uchat=tf.keras.layers.Dense(out_caps_num*out_caps_dim,activation='tanh')(caps)
caps_uchat=tf.reshape(caps_uchat,[batch_size,max_len,out_caps_num,out_caps_dim])
return caps_uchat
def _squash(in_caps,axes):
'''
定义_squash激活函数
:param in_caps:
:param axes:
:return:
'''
_EPSILON=1e-9
vec_squared_norm=tf.reduce_sum(tf.square(in_caps),axis=axes,keepdims=True)
scalar_factor=vec_squared_norm/(1+vec_squared_norm)/tf.sqrt(vec_squared_norm+_EPSILON)
vec_squared=scalar_factor*in_caps
return vec_squared
def masked_routing_iter(caps_uhat,seqLen,iter_num):
'''
动态路由计算
:param caps_uhat:输入向量,(batch_size,max_len,out_caps_num,out_caps_dim)
:param seqLen:
:param iter_num:
:return:
'''
assert iter_num>0
#获取批次和长度
batch_size,max_len=tf.shape(caps_uhat)[0],tf.shape(caps_uhat)[1]
#获取胶囊的个数
out_caps_num=int(tf.shape(caps_uhat)[2])
seqLen=tf.where(tf.equal(seqLen,0),tf.ones_like(seqLen),seqLen)
mask=mkMask(seqLen,max_len) #(batch_size,max_len)
float_mask=tf.cast(tf.expand_dims(mask,axis=-1),dtype=tf.float32)#(batch_size,max_len,1)
#初始化相似度权重b
B=tf.zeros([batch_size,max_len,out_caps_num],dtype=tf.float32)
#迭代更新相似度权重b
for i in range(iter_num):
#计算相似度权重(耦合系数)c
c=tf.keras.layers.Softmax(axis=2)(B)#(batch_size,max_len,out_caps_num)
c=tf.expand_dims(c*float_mask,axis=-1)#(batch_size,max_len,out_caps_num,1)
#计算胶囊的输出(激活向量)v
weighted_uhat=c*caps_uhat#(batch_size,max_Len,out_caps_num, out_caps_dim)
s=tf.reduce_sum(weighted_uhat,axis=1)# (batch_size, out_caps_num, out_caps_dim)
#squash非线性函数
v=_squash(s,axes=[2])#(batch_size, out_caps_num, out_caps_dim)
v=tf.expand_dims(v,axis=1)#(batch_size, 1, out_caps_num, out_caps_dim)
#更新相似度权重b
B=tf.reduce_sum(caps_uhat*v,axis=-1)+B#(batch_size, maxlen, out_caps_num)
v_ret = tf.squeeze(v, axis=[1]) # shape(batch_size, out_caps_num, out_caps_dim)
s_ret = s
return v_ret, s_ret
#定义函数,使用动态路由对RNN结果信息聚合
def routing_masked(in_x, xLen, out_caps_dim, out_caps_num, iter_num=3,
dropout=None, is_train=False, scope=None):
assert len(in_x.get_shape()) == 3 and in_x.get_shape()[-1].value is not None
b_sz = tf.shape(in_x)[0]
with tf.variable_scope(scope or 'routing'):
caps_uhat = shared_routing_uhat(in_x, out_caps_num, out_caps_dim, scope='rnn_caps_uhat')
attn_ctx, S = masked_routing_iter(caps_uhat, xLen, iter_num)
attn_ctx = tf.reshape(attn_ctx, shape=[b_sz, out_caps_num*out_caps_dim])
if dropout is not None:
attn_ctx = tf.layers.dropout(attn_ctx, rate=dropout, training=is_train)
return attn_ctx三、基于动态路由的RNN模型的实践——对路透社新闻的分类
3.1、数据加载
这里使用的是tf.keras接口的数据集,该数据集包括11228条新闻,共46个主题。具体接口为:
tf.keras.datasets.reuters
主要实现如下:
- 使用 tf.keras.datasets.reuters.load_data函数加载数据
- 使用tf.keras.preprocessing.sequence.pad_sequences函数对齐数据
具体代码实现如下:
#定义参数
NUM_WORDS=2000 #字典的最大长度
MAXLEN=80 #设置句子的最大长度
def load_data(num_words=NUM_WORDS,maxlen=MAXLEN):
'''加载数据'''
# 加载数据
print("load datasets ...")
(x_train, y_train), (x_test, y_test) = \
tf.keras.datasets.reuters.load_data(path='./reuters.npz', num_words=num_words)
#数据预处理:对齐序列数据并计算长度
#使用tf.keras.preprocessing.sequence函数对齐标签
# 对于句子长度大于maxlen的,从前面截断,只保留前maxlen个数据;
#对于句子长度小于maxlen的,需要在句子后面补零
x_train=tf.keras.preprocessing.sequence.pad_sequences(x_train,maxlen=maxlen,padding='post')
x_test=tf.keras.preprocessing.sequence.pad_sequences(x_test,maxlen,'post')
print('Pad sequences x_train shape:', x_train.shape)
#计算每个句子的真实长度
len_train=np.count_nonzero(x_train,axis=1)
len_test = np.count_nonzero(x_test, axis=1)
return (x_train,y_train,len_train),(x_test,y_test,len_test)
def dataset(batch_size):
(x_train,y_train,len),_=load_data()
dataset=tf.data.Dataset.from_tensor_slices(((x_train,len),y_train))
dataset=dataset.shuffle(1000).batch(batch_size,drop_remainder=True)#丢弃剩余数据
return dataset3.2、使用IndyLSTM单元搭建RNN模型
主要步骤如下:
(1)将3层IndyLSTM单元传入tf.nn.dynamic_rnn()函数中,搭建动态RNN模型;
(2)使用routing_masked()函数对RNN模型的输出结果作基于动态路由的信息聚合;
(3)用分类后的结果计算损失值,并定义优化器用于训练。
x = tf.placeholder("float", [None, maxlen]) #定义输入占位符
x_len = tf.placeholder(tf.int32, [None, ])#定义输入序列长度占位符
y = tf.placeholder(tf.int32, [None, ])#定义输入分类标签占位符
nb_features = 128 #词嵌入维度
embeddings = tf.keras.layers.Embedding(num_words, nb_features)(x)
#定义带有IndyLSTMCell的RNN网络
hidden = [100,50,30]#RNN单元个数
stacked_rnn = []
for i in range(3):
cell = tf.contrib.rnn.IndyLSTMCell(hidden[i])
stacked_rnn.append(tf.nn.rnn_cell.DropoutWrapper(cell, output_keep_prob=0.8))
mcell = tf.nn.rnn_cell.MultiRNNCell(stacked_rnn)
rnnoutputs,_ = tf.nn.dynamic_rnn(mcell,embeddings,dtype=tf.float32)
out_caps_num = 5 #定义输出的胶囊个数
n_classes = 46#分类个数
outputs = routing_masked(rnnoutputs, x_len,int(rnnoutputs.get_shape()[-1]), out_caps_num, iter_num=3)
print(outputs.get_shape())
pred =tf.layers.dense(outputs,n_classes,activation = tf.nn.relu)
#定义优化器
learning_rate = 0.001
cost = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
iterator1 = tf.data.Iterator.from_structure(dataset.output_types,dataset.output_shapes)
one_element1 = iterator1.get_next() #获取一个元素
#训练网络
with tf.Session() as sess:
sess.run( iterator1.make_initializer(dataset) ) #初始化迭代器
sess.run(tf.global_variables_initializer())
EPOCHS = 20
for ii in range(EPOCHS):
alloss = [] #数据集迭代两次
while True: #通过for循环打印所有的数据
try:
inp, target = sess.run(one_element1)
_,loss =sess.run([optimizer,cost], feed_dict={x: inp[0],x_len:inp[1], y: target})
alloss.append(loss)
except tf.errors.OutOfRangeError:
#print("遍历结束")
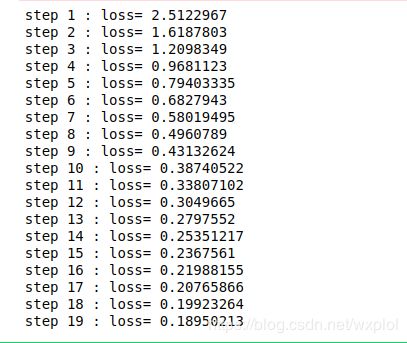
print("step",ii+1,": loss=",np.mean(alloss))
sess.run( iterator1.make_initializer(dataset) ) #从头再来一遍
break
最终的训练结果如下: