Oracle 学习之 MODEL
Oracle 学习之 MODEL
文章目录
- Oracle 学习之 MODEL
- 概念
- 官网格式
- 自己用到的简略版格式
- 官网例程练习
- 1. 通过具体的维度进行四则运算
- 2. 直接赋值
- 3. 新生成的字段(左边)中指定范围,使用 <、>、<=、>=
- 4. 数据计算字段(右边) 指定范围
- 5. CV()
- 6. ANY
- 7. 等号左边的维度需要选择一个范围,并且获取到新值
- 8. 设置规则评估的顺序
- 9. null处理(缺失单元格在规则中会被定义为null)
- 10. 创建参考模型
- 11. 创建迭代模型
- 12. 左侧数据获取有序(使用有序规则)
官网学习教程
概念
千篇一律:
model语句是Oracle10g的新功能,可以在select语句里面像其他编程语言操作数组一样,对SQL的结果集进行处理。执行顺序是位于Having之后。
Oracle官网介绍:
对于某些应用,MODEL子句可以替换基于PC的电子表格。SQL中的模型利用了Oracle数据库在可伸缩性,可管理性,协作和安全性方面的优势。核心查询引擎可以处理无限数量的数据。通过在数据库中定义和执行模型,用户可以避免在独立的建模环境之间传输大型数据集。可以在工作组之间轻松共享模型,从而确保所有应用程序的计算结果都是一致的。正如可以共享模型一样,访问也可以通过Oracle的安全性功能进行精确控制。MODEL子句具有丰富的功能,可以增强所有类型的应用程序。 – 谷歌翻译而来,见谅。
自我理解:
MODEL 可以实现类似excel中 = 的功能,可以减少表的子连接(它也可以实现多表之间的连接),可以直接在表字段后追加一个字段,用于输出按定义好的规则计算的值。
官网格式
MODEL
[<global reference options>]
[<reference models>]
[MAIN <main-name>]
[PARTITION BY (<cols>)]
DIMENSION BY (<cols>)
MEASURES (<cols>)
[<reference options>]
[RULES] <rule options>
(<rule>, <rule>,.., <rule>)
<global reference options> ::= <reference options> <ret-opt>
<ret-opt> ::= RETURN {ALL|UPDATED} ROWS
<reference options> ::=
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
<rule options> ::=
[UPDATE | UPSERT | UPSERT ALL]
[AUTOMATIC ORDER | SEQUENTIAL ORDER]
[ITERATE (<number>) [UNTIL <condition>]]
<reference models> ::= REFERENCE ON <ref-name> ON (<query>)
DIMENSION BY (<cols>) MEASURES (<cols>) <reference options>
整理后的格式:
MODEL
RETURN {ALL|UPDATED} ROWS
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
REFERENCE ON <ref-name> ON (<query>)
DIMENSION BY (<cols>) MEASURES (<cols>)
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
[MAIN <main-name>]
[PARTITION BY (<cols>)]
DIMENSION BY (<cols>)
MEASURES (<cols>)
[ [IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]]
[RULES]
[UPDATE | UPSERT | UPSERT ALL]
[AUTOMATIC ORDER | SEQUENTIAL ORDER]
[ITERATE (<number>) [UNTIL <condition>]]
(<rule>, <rule>,.., <rule>)
解析:
参考:oracle中MODEL子句的再探
-
MODEL: 关键字。
-
RETURN {ALL|UPDATED} ROWS:
- RETURN ALL ROWS: 返回符合的所有结果集,包括新生成的。
- RETURN UPDATED ROWS: 只返回数据有变化的,这里数据变化包括新增字段有值的。
- [IGNORE NAV | [KEEP NAV]: 替换null|保留null,0替换数组,空格替换字符,01-JAN-2001 替换日期,null替换其他,默认是KEEP NAV 。
- [UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]: 组内维度唯一|右侧引用唯一,默认是UNIQUE DIMENSION,右侧引用唯一的另一个区别是可能更新多个单元,因为左侧单元可能不唯一。
- REFERENCE ON ON (): 维度、指标定义,内嵌子MODEL,
ref-name为别名,主MODEL 使用别名引用, DIMENSION BY (这部分是关联) MEASURES ( ) : 子model的,MEASURES关键字,(表示规则中要使用到的字段。) - [IGNORE NAV | [KEEP NAV]: 为子
MODEL的限制条件,与主 MODLE 功能一样。 - [UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]: 为子
MODEL的限制条件,与主 MODLE 功能一样。 [MAIN当有引用子MODEL时,标示以下条件是主MODEL的条件。]: [PARTITION BY (按参数中的列分组,之后的运算都是分组进行的;参数可以是表达式,但是必须有别名。)]: DIMENSION BY (声明各分组中的维度字段,相当于多维键值对的建,字段值即键;参数可以是表达式,但是必须有别名。): MEASURES (声明各分组中的指标字段,即键值对中的值;参数可以是表达式,但是必须有别名。): - [RULES]: 关键字。
- [UPDATE | UPSERT | UPSERT ALL]: 指标计算规则,更新|更新和简单插入|更新和复杂插入,默认是UPSERT 。
- [AUTOMATIC ORDER | SEQUENTIAL ORDER]: 指标计算的顺序,逻辑依赖顺序|书写顺序,默认是SEQUENTIAL ORDER 。
[ITERATE (重复) [UNTIL ]]: number次的计算,直到满足condition的条件退出。(具体的规则。, ,.., ):
注意:
- UPDATE 只更新已有单元,不存在则无效果。
- UPSERT 在上面的基础上,如果左侧单元是以位置引用的话,则不存在就插入;FOR也是位置引用,但是更新的单元为FOR列表和其他维度的交叉乘集;左侧单元使用ANY引用,不会产生新单元,ANY的意思是IS NULL OR IS NOT NULL。
- UPSERT ALL 在上面的基础上,左侧单元可以使用IN,ANY等谓词。
UPSERT的执行过程:
1、找出左侧单元的逻辑引用,谓词也是逻辑引用。
2、计算出逻辑引用的笛卡尔积集合。
3、和位置引用一起得出需要运算的单元集。
4、根据RULE规则更新或新增记录。
自己用到的简略版格式
MODEL --行间计算
PARTITION BY(分组字段1, 分组字段2, 分组字段3...) -- 分组
DIMENSION BY(维度字段1,维度字段2...) -- 维度
MEASURES(成员字段1,成员字段2...) --成员(包含新增的成员字段列)
IGNORE NAV --空值处理
RULES(成员字段[维度字段1,维度字段2...] = 成员字段[维度字段1,维度字段2...]
官网例程练习
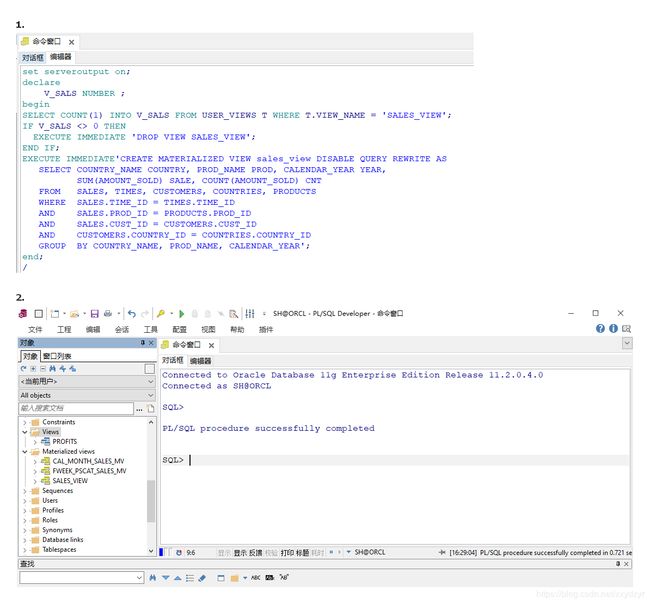
我们已经按照例程创建好了视图,但是发现直接查询视图的速度并不快,因为普通视图会将语句转换成对应的查询语句,然后再执行。所以我们这里修改一下,创建物化视图。
set serveroutput on;
declare
V_SALS NUMBER ;
begin
SELECT COUNT(1) INTO V_SALS FROM USER_VIEWS T WHERE T.VIEW_NAME = 'SALES_VIEW';
IF V_SALS <> 0 THEN
EXECUTE IMMEDIATE 'DROP VIEW SALES_VIEW';
END IF;
EXECUTE IMMEDIATE'CREATE MATERIALIZED VIEW sales_view DISABLE QUERY REWRITE AS
SELECT COUNTRY_NAME COUNTRY, PROD_NAME PROD, CALENDAR_YEAR YEAR,
SUM(AMOUNT_SOLD) SALE, COUNT(AMOUNT_SOLD) CNT
FROM SALES, TIMES, CUSTOMERS, COUNTRIES, PRODUCTS
WHERE SALES.TIME_ID = TIMES.TIME_ID
AND SALES.PROD_ID = PRODUCTS.PROD_ID
AND SALES.CUST_ID = CUSTOMERS.CUST_ID
AND CUSTOMERS.COUNTRY_ID = COUNTRIES.COUNTRY_ID
GROUP BY COUNTRY_NAME, PROD_NAME, CALENDAR_YEAR';
end;
/
1. 通过具体的维度进行四则运算
根据划分,可以直接指定确定的维度进行四则运算。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country IN ('Italy','Japan')
and prod in ('Bounce','Y Box')
MODEL RETURN UPDATED ROWS -- 返回更新的行数:这里返回的是年份为2002的数据
PARTITION BY (country) -- 根据国家分组
DIMENSION BY (prod, year) -- 维度字段:划分为产品和时间维度
MEASURES (sale sales) -- 成员字段:这里其实只有一个成员 sale,sales是个别名
RULES ( -- 规则
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001],
sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002])
ORDER BY country, prod, year;
此语句按国家/地区划分,因此规则一次应用于一个国家/地区的数据。请注意,数据以2001结尾,因此任何定义2002或更高版本的值的规则都将插入新的单元格。第一条规则将2002年Bounce的销售额定义为2000年和2001年的销售额之和。第二条规则将2002年Y Box的销售额定义为与2001年的销售额相同。第三条规则将类别2_Products定义为,这是2002 Bounce和Y Box值加在一起的总和。请注意,2_Products的值是从两个先前规则的结果得出的,因此这些规则必须在2_Products规则之前执行。

2. 直接赋值
直接赋值给具体的维度。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['Bounce', 2000] = 10 )
ORDER BY country, prod, year;

3. 新生成的字段(左边)中指定范围,使用 <、>、<=、>=
在1999年之后的所有年份中更新SALES f或产品Bounce,在该年份中记录了意大利的值并将其设置为10。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales[prod='Bounce', year>1999] = 10 )
ORDER BY year

4. 数据计算字段(右边) 指定范围
注意:
1. 在数据计算的右边指定范围的话,则需要使用聚合函数(MAX、MIN、SUM、COUNT等)
2. 聚合函数只需要选定成员字段即可,不需要框起全部。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['Bounce', 2005] =
100 + max(sales)['Bounce', year BETWEEN 1998 AND 2002] )
ORDER BY country, prod, year

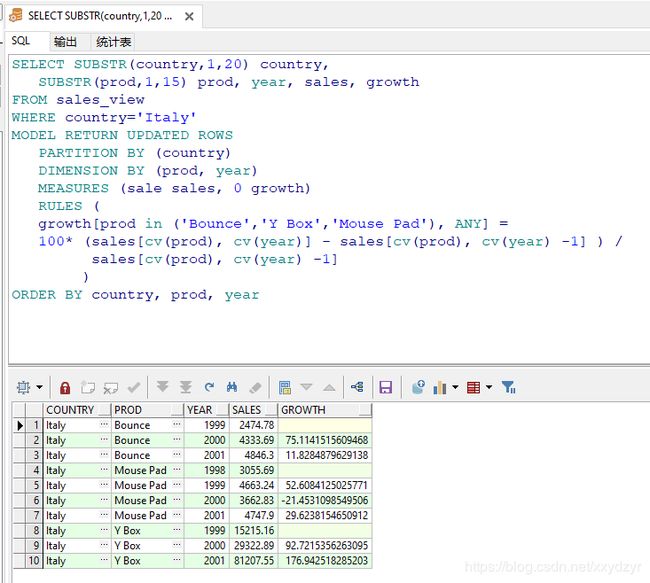
5. CV()
该CV()函数是一个非常强大的工具,CV() 用于规则的右侧,以复制左侧指定的维的当前值。无论左侧的规则涉及多个单元格,该功能都将很有用。就关系数据库概念而言,它的作用类似于联接操作。
CV()允许非常灵活的表达式。例如,通过从CV(year) 值中减去,您可以引用数据集中的其他行。如果单元格引用中有表达式CV(year)- 2,则可以访问两年前的数据。 CV()函数最常用作单元格引用的一部分,但它们也可以在单元格引用之外用作表达式的独立元素。
CV 是 model 中的一大元素,可以把它理解为:在取右侧维度的时候,如果右侧维度值为 CV,那么右侧这个维度值等于左侧对应的维度值。
就是右边为CV的维度等于等号左边的的维度值,计算时,左边的维度是什么,右边对应为CV的维度就取啥。
CV只能用于右边,中间可以填维度字段名,也可以不填。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales, growth
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED ROWS
PARTITION BY (country) -- 根据国家分组
DIMENSION BY (prod, year) -- 维度字段:划分为产品和时间维度
MEASURES (sale sales, 0 growth) -- 成员字段:两个成员,一个是sale(表本身存在),一个growth(新增)
RULES (
growth[prod in ('Bounce','Y Box','Mouse Pad'), year between 1998 and 2001] =
100* (sales[cv(prod), cv(year)] - sales[cv(prod), cv(year) -1] ) /
sales[cv(prod), cv(year) -1] )
ORDER BY country, prod, year
规则解析:
- 新增一个字段名为 growth,维度还是产品和时间,产品限定为三个
prod in ('Bounce','Y Box','Mouse Pad'),时间限定为1998到2001year between 1998 and 2001; - 使用
CV获取与左边相同的维度值,使用 CV() -1 获取上一年的数据,从而计算增长比。 - 没有获取到上一年的数据,则 growth 值为空。
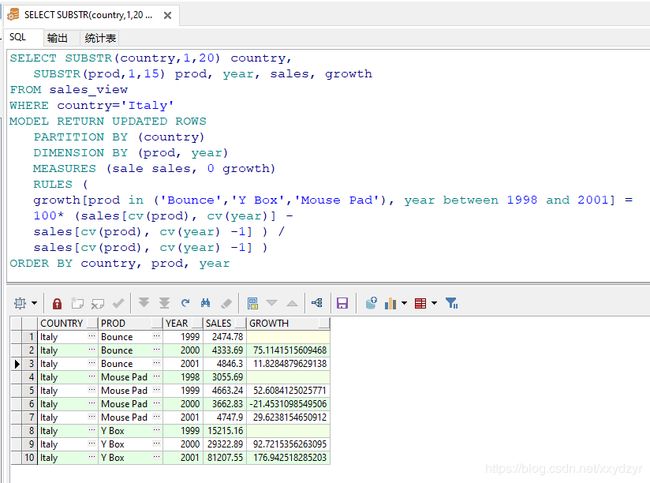
6. ANY
ANY可以在单元格引用中使用,以包括所有维度值(包括NULL)。在符号引用符号中,使用短语 IS ANY。请注意,ANY 通配符在与位置或符号表示法一起使用时会阻止单元格插入。
通配符运算符对于单元格规范非常有用,您可以为此使用ANY关键字。您可以将其与前面的示例一起使用,以替换1998年至2001年之间的规格年份,如下所示。
any用于等号的左边,理解为:使用ANY的维度所有值都有,即不加以任何限制,同时,null值也会取到。
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales, growth
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales, 0 growth)
RULES (
growth[prod in ('Bounce','Y Box','Mouse Pad'), ANY] =
100* (sales[cv(prod), cv(year)] - sales[cv(prod), cv(year) -1] ) /
sales[cv(prod), cv(year) -1]
)
ORDER BY country, prod, year
7. 等号左边的维度需要选择一个范围,并且获取到新值
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
and prod in ('Mouse Pad', 'Bounce', 'Y Box')
MODEL
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales[FOR prod in ('Mouse Pad', 'Bounce', 'Y Box'), 2005] =
1.3 * sales[cv(prod), 2001] )
order by year desc;
这里注意有 FOR 和 没 FOR 的区别:当没有使用 FOR 时,数据为当前存在的数据,新数据不会产生;当使用了FOR 时,如果等号左边定义的是新增的数据(不存在与之前数据库的数据)时,会按照规则生成这个数据。
官方解释:如果编写的规范与上述规范相似,但没有FOR关键字,则只会更新已经存在的单元格,并且不会插入新的单元格。

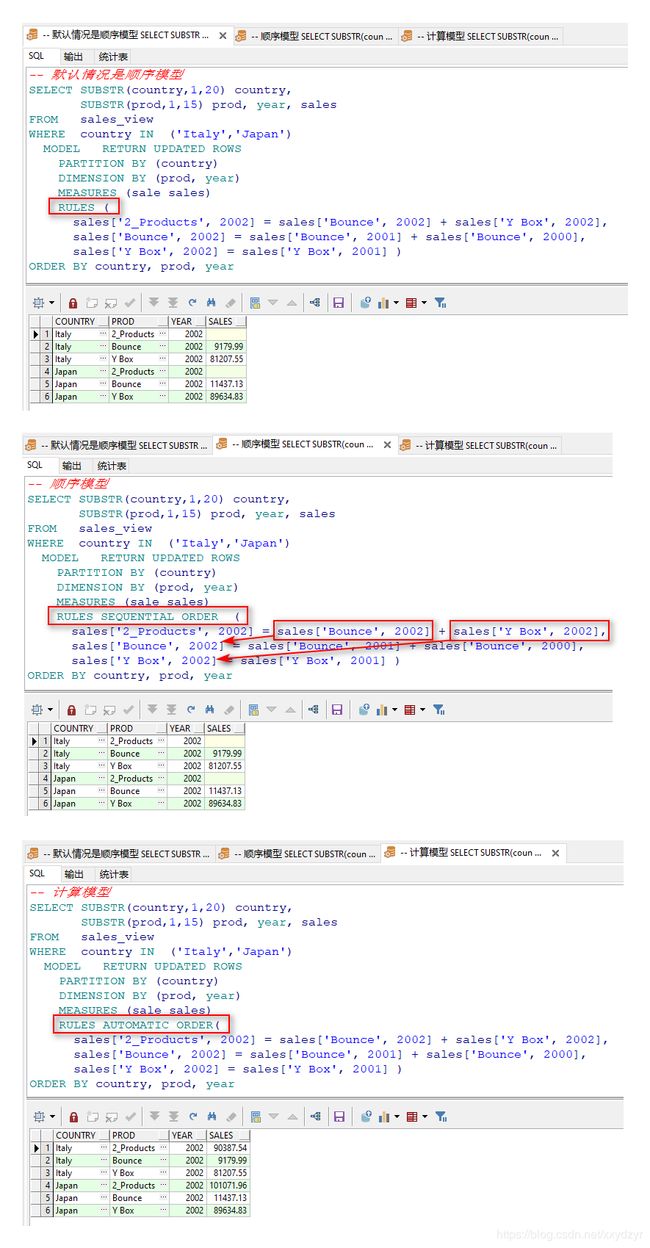
8. 设置规则评估的顺序
官网解释:
默认情况下,规则按照它们在 MODEL 子句中出现的顺序进行评估。可以在 MODEL 子句中指定可选关键字 **SEQUENTIAL ORDER **,以使这种评估顺序明确。具有顺序评估规则顺序的 SQL 模型称为 顺序模型。
计算模型,以便以正确的顺序考虑和处理所有规则依赖性,请使用 **AUTOMATIC ORDER ** 关键字。当模型具有大量规则时,使用 **AUTOMATIC ORDER ** 选项可能比手动检查规则是否在逻辑上正确的顺序列出的效率更高。这样可以更有效地开发和维护模型。
理解:
在涉及多条规则时,如果当前规则使用到了后面规则生成的数据,但是数据库中的数据中又不存在,
- 如果按顺序模型处理,则该条规则运行时应该按照数据库中的数据处理,即为空值。
- 如果按计算模型处理,则应取后面计算后得到的数据处理,即有值。
举例:
-- 默认情况
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country IN ('Italy','Japan')
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002],
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001] )
ORDER BY country, prod, year;
-- 顺序模型
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country IN ('Italy','Japan')
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES SEQUENTIAL ORDER (
sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002],
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001] )
ORDER BY country, prod, year;
-- 计算模式
SELECT SUBSTR(country,1,20) country,
SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country IN ('Italy','Japan')
MODEL RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES AUTOMATIC ORDER (
sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002],
sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000],
sales['Y Box', 2002] = sales['Y Box', 2001] )
ORDER BY country, prod, year;
9. null处理(缺失单元格在规则中会被定义为null)
由于NULL 值导致许多规则返回空值,因此将空值和缺失值视为0值可能对您更有用。这样,将不会通过一组计算传播空值。您可以使用选项(NAV代表“不可用值”)将默认的空值和缺少的单元格设置为以下值:
由于NULL 值导致许多规则返回空值,Oracle提供关键词 IGNORE NAV 避免因为 NULL 值使得数据也变为NULL值。
IGNORE NAV :
- 规则中如果是获取数字,缺失则置为 0
- 规则中如果是获取字符串,缺失则置为空字符串
- 规则中如果获取的是时间,缺失则置为 01-JAN-2001
- 如果获取的是其他数据类型,缺失则仍然置为 NULL
举例:
-- 加入 IGNORE NAV
SELECT SUBSTR(country,1,20) country, SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL IGNORE NAV RETURN UPDATED ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['Mouse Pad', 2005] =
sales['Mouse Pad', 1999] + sales['Mouse Pad', 2004])
ORDER BY country, prod, year;

10. 创建参考模型
官网解释:
除了运行规则的多维数组(称为 Main SQL MODEL )之外,还可以创建一个或多个只读多维数组(称为 Reference MODEL ),并在 MODEL 子句中对其进行引用以用作查找表。使用参考模型,可以关联不同维度的对象。像 Main SQL MODEL 一样,Reference MODEL 在查询块上定义,并具有 DIMENSION BY 和 MEASURE 子句分别指示其维和度量。
自我理解:
这部分可以这样认为:引进一张实体表,然后调用里面具体的数据,比如说,再外汇转换方面,引进一张汇率表,然后在处理数据的时候乘以汇率,当然汇率在这里是固定的。
示例:(将不同国家/地区的预测销售数字(以各自的货币)转换为美元,并同时显示这两个数字。)
- 为实现这个功能,需要先创建一张表,并插入两条数据。
CREATE TABLE dollar_conv(
country VARCHAR2(30),
exchange_rate NUMBER
);
INSERT INTO dollar_conv VALUES('Canada', 0.75);
INSERT INTO dollar_conv VALUES('Brazil', 0.14);
commit;
- 根据2001年的销售额和到2005年项目市场的增长,加拿大的增长率为22%,巴西的增长率为34%。要将2005年加拿大和巴西的预计销售额转换为美元,可以使用参考模型。
SELECT SUBSTR(country,1,20) country, year,
localsales, -- 计算出来的销售值(没有乘以汇率)
dollarsales -- 乘以汇率的销售值
FROM sales_view
WHERE country IN ( 'Canada', 'Brazil')
GROUP BY country, year
MODEL RETURN UPDATED ROWS -- 只返回更新行
REFERENCE conv_refmodel ON ( -- 这里取了一个别名用来引用
SELECT country, exchange_rate AS er FROM dollar_conv) -- 获取关联字段国家和汇率值
DIMENSION BY (country) MEASURES (er) -- 这里的 country 不是主表的country,而是汇率表中的country
IGNORE NAV
MAIN main_model -- 表示下面为主 MODEL 的条件
DIMENSION BY (country, year)
MEASURES (SUM(sale) sales, 0 localsales, 0 dollarsales)
IGNORE NAV
RULES (
localsales['Canada', 2005] = sales[cv(country), 2001] * 1.22,
dollarsales['Canada', 2005] = sales[cv(country), 2001] * 1.22 * conv_refmodel.er['Canada'],
localsales['Brazil', 2005] = sales[cv(country), 2001] * 1.34,
dollarsales['Brazil', 2005] = sales['Brazil', 2001] * 1.34 * er['Brazil'] -- 貌似可以不用别名点的方式引用
)

11. 创建迭代模型
自我理解: 这里其实就是建立一个循环,并设置一个条件,当达到循环次数或者达到条件的时候停止循环,输出结果。
官方例子: 您想为一个薪水为$ 100,000且资本收益为$ 15,000的人做财务计划。他的净收入将计算为工资减去利息支付减去税款。他为贷款支付可抵税的利息。他还按两种税率纳税:扣除利息费用后的工资收入的28%,资本收益的38%。这个人希望他的利息支出恰好代表其收入的30%。您如何计算将产生的税金,利息支出和净收入?
-
先创建好表,并插入对应的值。
CREATE TABLE ledger ( account VARCHAR2(20), balance NUMBER(10,2) ); INSERT INTO ledger VALUES ('Salary', 100000); INSERT INTO ledger VALUES ('Capital_gains', 15000); INSERT INTO ledger VALUES ('Net', 0); INSERT INTO ledger VALUES ('Tax', 0); INSERT INTO ledger VALUES ('Interest', 0); commit; -
不设置终止条件,直接循环
SELECT b, account FROM ledger MODEL IGNORE NAV DIMENSION BY (account) MEASURES (balance b) RULES ITERATE (100) ( b['Net'] = b['Salary'] - b['Interest'] - b['Tax'], b['Tax'] = (b['Salary'] - b['Interest']) * 0.38 + b['Capital_gains'] *0.28, b['Interest'] = b['Net'] * 0.30 ); -
设置终止条件,当符合条件的时候终止循环。
SELECT b, account FROM ledger MODEL IGNORE NAV DIMENSION BY (account) MEASURES (balance b) RULES ITERATE (100) UNTIL ( ABS( (PREVIOUS(b['Net']) - b['Net']) ) < 0.01 ) ( b['Net'] = b['Salary'] - b['Interest'] - b['Tax'], b['Tax'] = (b['Salary'] - b['Interest']) * 0.38 + b['Capital_gains'] *0.28, b['Interest'] = b['Net'] * 0.30, b['Iteration Count']= ITERATION_NUMBER + 1 -- 循环次数 -- the '+1' is needed because the ITERATION_NUMBER starts at 0 );这部分脚本是可以跑的,不想详细解释。
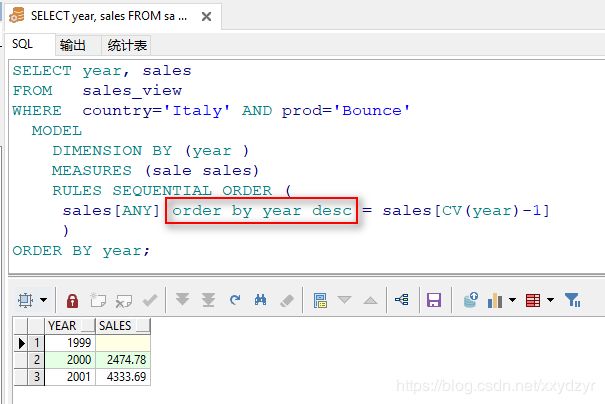
12. 左侧数据获取有序(使用有序规则)
数据库中存储的数据不是顺序的,有的时候我们只需要按顺序获取一下数据,但是可能直接引用会报错误。
SELECT year, sales
FROM sales_view
WHERE country='Italy' AND prod='Bounce'
MODEL
DIMENSION BY (year )
MEASURES (sale sales)
RULES SEQUENTIAL ORDER (
sales[ANY] = sales[CV(year)-1]
)
ORDER BY year;

这里我们可以使用有序规则来进行修复:
SELECT year, sales
FROM sales_view
WHERE country='Italy' AND prod='Bounce'
MODEL
DIMENSION BY (year )
MEASURES (sale sales)
RULES SEQUENTIAL ORDER (
sales[ANY] order by year desc = sales[CV(year)-1]
)
ORDER BY year;