Redis从入门到高可用分布式实践(一)
初识
nosql介绍
- 泛指非关系型的数据库
- 不支持SQL语法
- 数据类型k-v
- 无通用的语言,每种nosql数据库都有自己的api和语法,以及擅长的业务场景
- NoSQL中的产品种类相当多
- redis
- mogodb
- hadoop
NoSQL和SQL数据库的比较
- 适用场景不同:sql数据库适合用于关系特别复杂的数据查询场景,nosql反之
-事务 特性的支持:sql对事务的支持非常完善,而nosql基本不支持事务 - 两者在不断地取长补短,呈现融合趋势
redis简介
- Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
- 属于NoSQL,通过多种键值数据类型来适应不同场景下的存储需求,借助一些高层级的接口使用其可以胜任,如缓存、队列系统的不同角色
- 默认端口:6379
特性目录
1. 速度快
- 底层用C开发
- 内存型数据库
- 单线程
2. 持久化
- 提供了持久化存储方案——RDB\AOF
3. 支持多种数据类型
- string
- hash
- list
- set
- zset
衍生类型:
- BitMaps:位图——用很小的内存,实现高效存储。(本质是字符串)
- 2.8.19提供HyperLogLog:超小内存(12k)唯一值计数——超小内存完成上亿级技术。
缺点:计数不太准确,有一定的误差率。(本质是字符串)
GEO:地理信息定位——比如算经纬度——用于地图中。
… - 不依赖外部库
- 单线程模型:无论是服务端、开发端都很方便。
4. 备份
主从复制——主服务器的数据可同步到从服务器:为高可用和分布式提供很好的基础。
5. 高可用和分布式
- Redis_Sentinel(V2.8)支持高可用
- Redis_Cluster(v3.0)支持分布式
使用场景
-
缓存系统 :
- APP Server
- Cache(缓存)
- Storage(数据源)
用户访问App Server —>Cache(有数据直接返回给用户,若不存在则访问Storage)—>Storage
-
计数器 : 提供 incr命令,可在单线程下进行非常高效的计数,且不会出现计数错误的问题。适用于微博评论,转发计数,这种场景。
-
消息队列系统 : rabitmq…
-
排行榜 : 提供有序集合
-
社交网络 : 天然吻合
-
实时系统:消息队列缓冲…位图:垃圾邮件处理,实时过滤…
修改常用redis配置
在Linux系统中,redis的配置信息在
三种启动方式
- redis-server
验证方法:- ps -ef | grep redis
- netstat -antpl | grep redis
- redis-cli -h ip -p port ping
- redis-server --port 6380 # 指定端口启动
- redis-server configPath # 配置文件启动——生产环境,单机多实例配置文件可以用端口区分。
API
通用命令
- keys : * 、补齐
keys 命令一般不再生产环境使用: 1.键值对比较多,该命令比较重o(n)——慢!2.本身也没什么意义。
若要查出所有的key,可选用热备从节点(从一般不再生产环境使用吗?)、scan - dbsize : 计算key的总数。o(1) (Redis内置一个计算器,会自动计数key-value值)
- exists key : 检查key是否存在 。存在返回1,不存在返回0。
- del key # 成功删除返回1,
- expire key seconde :默认以秒为单位。
- ttl key : 查看key剩余过期时间(-1—>存在且没有设置过期时间)
- persist key # 去掉key的过期时间
- type key # 返回key的类型(5种)
通配符的使用必须掌握
时间复杂度:

数据结构内部编码
学习目标:知道编码设计的目的
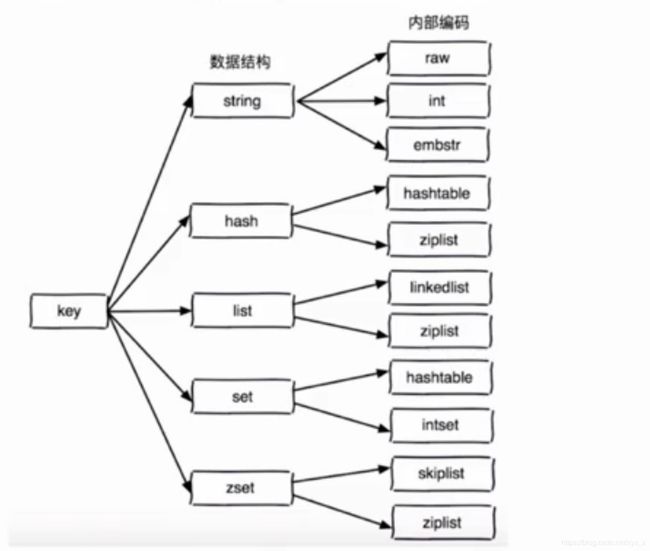
redis 源码内部有个RedisObject: 包含两个重要的属性
- 对外数据类型
- 编码方式
单线程架构
单车道的高速公路
每个瞬间只允许一辆车通过
单线程速度还快的原因:
- 纯内存 (本质)
- 非阻塞IO 不在IO上浪费过多的时间(辅)
- 避免线程切换和竞态消耗(要知道对多线成使用不合理时,甚至会比单线程慢。)(辅)
使用单线程的注意事项
- 一次只运行一条命令
- 拒绝长(慢)命令
keys ,flushall,flushdb,slow lua script,mutil/exec, operate big value(collection) - 其实不是纯粹单线程
- fysnc file descriptor
- close file descriptor
以上两个由独立线程执行。
数据结构
一、字符串
对于redis来说,所有的 key都是字符串, value可以是多种类型。
字符串: 本质上都是二进制,not Up to 512MB (其实数据大了对单线程不利,考虑到并发和流量,一般都建议在100k内)
场景:
- 缓存
- 计数器
- 分布式锁
- …
命令:
- get
- set
- del
当字符串中存储的数据为’123‘这种类型时,还可以使用以下API:
- incr --------------------------->key自增1,key不存在时,会创建一个key 值为 0 ----->incr之后:get(key) = 1
- decr
- incrby key increment ---->key 按increment增加
- decrby key decrement
set、setnx、setxx
set key value : 无论key是否存在 o(1)
setnx : key不存在
setxx :key必须存在
mget 、mset
批量、原子操作 o(n)
优:可省去网络时间,注意使用mget也要有节制。
getset
getset key newvalue # 设置新值,并返回旧值o(1)
append
append key value # 追加value
strlen
strlen key # 返回字符串长度 (注意中文长度:utf8下一个汉字俩字节)
二、hash(small redis)
| key | field | value |
|---|---|---|
| user | name | xyx |
| age | 18 | |
| gender | man |
Mapmap
Small redis
field不能相同,value可以相同。
hget 、hset、hdel
hget key field
hgetall key # 获取所有属性
hexists 、hlen
hexists # 判断hash键是否有field
hlen # 获取hash key field的数量
hmset、hmget
hmset key field1 value1 field2 value2 field3 value3…
hmget key field1 field2 field3…
应用:
-
记录网站每个用户个人主页的访问量
hincrby user1 pageview count
-
缓存视频基本信息(数据在mysql)
hgetall、hvals、hkeys o(n)
hgetall key # 获取key所有的field 和value.(小心使用,返回所有的field和value)
hvals key # 获取key所有的值
hkeys # 获取所有的field
符合关系型数据库的特点。
三、list
| key | elements |
|---|---|
列表:有序、可重复、索引取值
增
rpush key value1 value2 …valueN # 从右往左插
rpush list 1,2,3,4,5
lpush
lpush list1 a,b,c,d
linsert :
linsert key before|after value newvalue # 在list指定值前后插入
linsert list before 1 a
删
lpop # 从左边弹出一个元素。
lpop list------>2,3,4,5
rpop # 右边弹
lrem # 删除指定元素
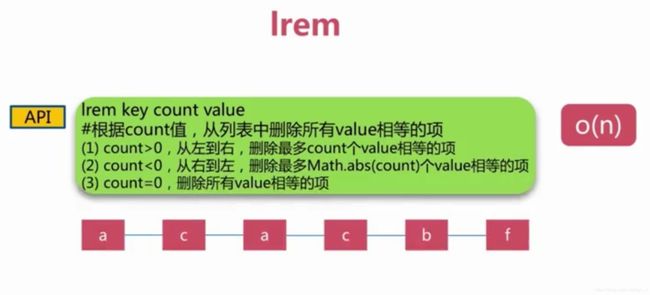
lrem key count value # 删除列表中count个值为value的元素。count:zheng’fu
a c a c b f
lrem list 0 a # 把list中所有为a的元素都删点
lren list -1 c # 从右开始删除,一个
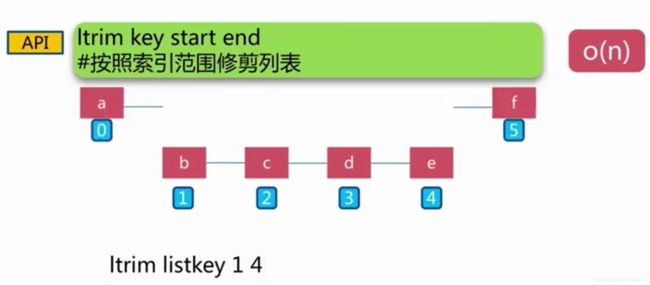
ltrim
ltrim key start end # 按照索引范围修剪列表
改:lset
lset key index newvalue
查:
lrange # 按照范围取
lrange key start end (闭区间)
lindex # 按照索引取
lindex key index
注意点:
- 下标从零开始
- 取值范围为闭区间
- 新建list时,元素之间以空格区分
llen key
微博timeline:
| weibo更新时间轴 | |
|---|---|
| weibo6 | |
| weibo5 | |
| weibo4 | |
| weibo3 | 微博对象3 |
| weibo2 | 微博对象2 |
| weibo1 | 微博对象1 |
when 关注的人更新了微博 -------lpush
blpop、brpop
blpop # lpop阻塞版本,timeout阻塞超时时间,timeout=0永不阻塞。
127.0.0.1:6379> blpop a 10
(nil)
(10.07s)
127.0.0.1:6379> lpush a 1 2 3
(integer) 3
127.0.0.1:6379> blpop a 10
1) "a"
2) "3"
127.0.0.1:6379> blpop a 10
1) "a"
2) "2"
127.0.0.1:6379> blpop a 10
1) "a"
2) "1"
TIPS:
- LPUSH + LPOP =Stack # 栈
- LPUSH +RPOP = Queue # 队列
- LPUSH +LTRIM =Capped Collection # 控制列表数量
- LPUSH + BRPOP = Message Queue # 消息队列系统
四、set
user1_like
特点:
- 无序
- 不重复
- 集合间的交叉并集
sadd 、 srem
sadd : 添加失败返回结果为0
sadd key element
srem key element
scard、sismember、srandmenber、smembers

smembers
-无序
- 返回所有
srandmember 和spop
- srandmember随机返回多个元素不会破坏原本数据
- spop 从集合中弹出
应用:
- 抽奖系统
srandmenbe弹出 - like 、赞、踩 ---->放在一个用户对应的集合中。
- 标签
给用户添加标签,用户关注的标签。
集合间的API
sdiff 、sinter、 sunion

应用:共同关注

五、zset
| key | score | value |
|---|---|---|
| user | 1 | like |
| 100 | name | |
| 100 | gender |
- 有序 (分值越大越靠前)
- 不重复
- 同分值,按字母顺序排序。
zadd key score element o(n)
zadd user 1 name 2 age 3 gender 4 id
zrem key element # 可以是多个element
zrem user name age
zscore key element
zincrby key increScore element
zrank # 查看排名
zrem
zrange key start end
zremrangebyrank # 按排名删除范围
zremrangebyrank key start end
zremrangebyscore # 按分值删除
应用:排行榜
Redis其它功能
慢查询
- 生命周期
- 客户端发送命令
- redis中排队
- 执行命令
- 返回结果
慢查询发生在第3 阶段
客户端超时不一定有慢查询
- 两个配置
- slowlog-max-len
- 先进先出队列
- 固定长度
- 保存在内存中
- slowlog-log-slower-than
- 慢查询阈值(单位:秒)
- slowlog-log-slower-than=0,记录所有命令。
- slowlog-log-slower-than<0,不记录任何命令。
- 默认值
- config get slowlog-max-len = 128
- config get slowlog-log-slower-than = 10000
- 修改配置文件重启
- 动态配置
- config set slowlog-max-len 1000
- config set slowlog-log-slower-than 1000
- 三个命令
- slowlog get[n] : 获取慢查询队列,指定n条命令
- slowlog len : 获取慢查询队列长度
- slowlog reset : 清空慢查询队列
- 运维经验
- slowlog-max-len 不要设置过大,默认10ms,通常设置1ms
- slow-log-slower-than不要设置过小,通常设置1000左右。
- 定期持久化慢查询
pipline
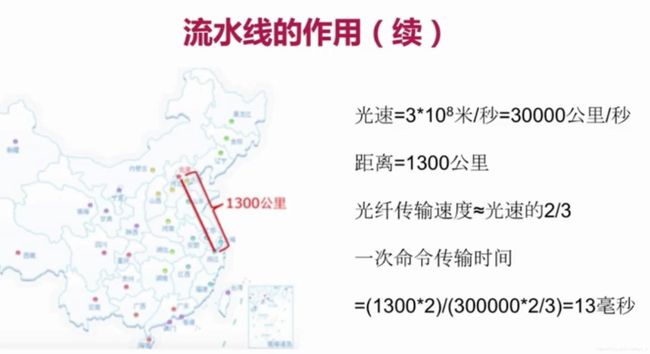
- 什么是流水线
一次网络通信模型:
一次通信时间 = 一次网络时间(发送+返回)+ 一次命令时间
n命令 = n网络时间 + n命令时间
命令时间非常快,网络时间受网络影响
流水线:
将一批命令批量打包,在服务端进行一个批量计算,最后一次性返回。
总时间 = 一次网络时间 + n次命令时间
- redis命令时间是微妙级别
- pipeline每次条数需要控制
notes:
3. 注意每次pipline携带数据量
4. pipline每次只能作用在一个redis节点上
5. M操作与pipline区别
发布订阅
-
角色
- 发布者
- 订阅者
- 频道
- 模型

注意:新的订阅者接收不到发布者发布的之前的消息。——不提供消息堆积。
-
API
- publish
publish channel message
publish keji ‘shijiebei fhrjrg’
(integer) 3 # 返回结果为订阅者个数 - subscribe
subscribe channnel # 订阅频道,一个或多个
返回订阅频道信息+发布的消息。 - unsubscribe channel # 取消订阅 一个或多个
- publish
其它API:

消息队列:

redis本身不提供消息队列,而是通过列表实现。
消息队列与发布订阅的区别在于:消息队列中的资源只用一个客户端获得。而发布订阅消息是所有订阅者均能获得。
bitmap
位图:
set hello big
getbit hello 0 # b的二进制存储的一个bit
setbit
setbit key offset value # offset 偏移量,即将key的第offset位设为value。—原本的value肯定会改变。
返回结果:之前对应位的值。
setbit hello 0 1 # 将hello的第1位设为1
getbit
getbit key offset
bitcount
bitcount key [start end] # 返回指定范围值为1 的个数
bitop
bitop op destkey key [key…]
做多个Bitmap 的and(交集)、or(并集)、not,并将操作的结果保存到destkey中。
bitpos
bitpos key targetBit[start] [end]
计算位图指定范围第一个 偏移量对应的值等于targetBit的位置
使用:独立用户统计
- 使用set和Bitmap
- 1亿用户,5千万用户
使用经验:
- type = string ,最大512MB
- 注意setbit时的偏移量,可能有较大耗时。
- 位图不是绝对的好。
hyperloglog
新的数据结构?
极小空间完成独立用户统计。——算法
type hyperloglog_key ——string
三个命令
pfadd key element [element] # 添加独立用户
pfcount key [key…] # 统计独立用户
pfmerge destkey sourcekey [key…] #
内存消耗
geo
持久化的取舍和选择(重要)
什么是持久化?
redis 数据存储在内存中,会将更新数据异步保存到磁盘。
持久化的方式:
- 快照——把某个时间点的数据记录下来
MySQLdump、redis RDB - 写日志 ——恢复时重新执行下日志文件
MySQL Binlog 、Hbase HLog、Redis AOF
RDB
redis -------->命令---------->RDB文件(二进制、硬盘)
重启(恢复redis)------------------>载入RDB文件
生成RDB
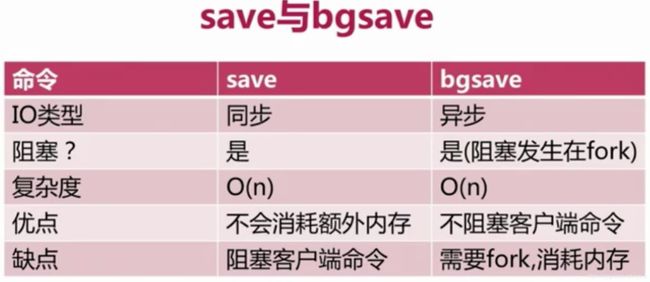
save(同步):该命令执行完前,其它命令处于等待状态。——数据量大时会造成redis阻塞。
文件策略——新替老
复杂度o(n)
bgsave(异步):单独线程执行,立即返回ok.
bgsave -->fork()子进程---->createRDB----->告诉redis bgsave successfully
因为fork()快,极少情况下会出现慢的情况阻塞redis
此时可正常访问redis-cli
对比:
自动
自动生成RDB的策略
在的多长时间内,改变了多少条数据------>内部执行bgsave
| 配置 | seconds | changes |
|---|---|---|
| save | 900 | 1 |
| save | 90 | 10 |
| save | 60 | 1000 |
900s 改了1条数据,90s改了10条数据,60s改了1000条数据,都执行bgsave.
——并不是很好的策略,因为数据写入量不受控制,所以生成的规则也不好控制。频繁的操作会对硬盘造成一定压力。
最佳配置:
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir ,/
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes #是否采用校验和
文件名:dump.rdb
默认保存:dir ./
触发机制
- 全量复制(主从复制时,主自动触发–>RDB)
- debug reload
- shutdown (shutdown save)
RDB总结
- RDB是Redis内存到硬盘的快照,用于支持化。
- save通常会阻塞Redis.
- bgsave不会阻塞Redis,但是会fork新进程。
- save自动配置满足任一就会被执行
- 有些触发机制不容忽视
RDB问题:
耗时、耗性能
- o(n)
- fork() :消耗内存,copy-on-write策略
- disk I/O :把数据写到硬盘中
不可控、数据丢失
- 因为不是同步创建
AOF
解决RDB数据丢失问题。——日志,记录每次操作命令。
redis宕机---->重启之后将AOF载入数据库。
AOF的三种策略
- always
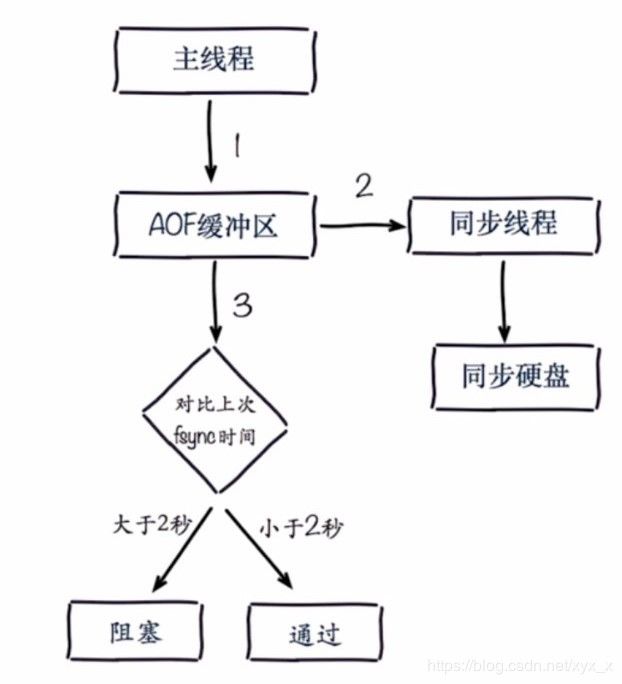
redis写命令---->缓冲区-- 每条命令fsync —>硬盘(AOF) - everysec
redis写命令---->缓冲区-- 每秒把缓冲区fsync —>硬盘(AOF)——优点:数据量巨大的时候能既减轻硬盘压力。缺点:发生故障会丢失一秒的数据。——默认策略。 - no
redis写命令---->缓冲区-- 操作系统决定 —>硬盘(AOF)
策略选择:

一般使用默认配置。
问题:
随着时间的推移,并发量的增大…——AOF文件会增大。
AOF重写

把过期的,无用的以及可以优化的命令进行化简成一个很小的AOF文件。
目的:
- 减少磁盘占用量 (想象incr 一亿次)
- 加速恢复速度
AOF重写实现两种方式:
- bgrewriteaof
client-----> redis(redis立马响应ok)----->fork —>redis子进程—>AOF重写
AOF将redis中的数据进行一次回朔——>生成AOF文件。 - AOF重写配置

- AOF重写的最小尺寸。
- AOF重写的增长速率。比如当前数据为100,设置重写增长率为100%,当数据为200时进行重写。
自动触发时机
- aof_current_size > auto-aof-rewrite-min-size
- aof_current_size-aof_base_size/aof_base_size> auto-aof-rewrite-percentage
AOF重写流程

RDB&AOF
Redis持久化开发运维常见问题
1.fork操作
- 同步操作(快 若卡则阻塞redis主进程)
- 与内存息息相关:内存越大耗时越长(redis使用的内存越大,数据量越多)
- info: latest_fork_usec 查看持久化执行的时间
改善fork
- 有限使用物理机,or 高效支持fork的虚拟化技术
- 控制redis可用最大内存:maxmemory
- 合理配置Liunx 内存分配策略:vm.overcommit_memory = 1(默认为0,当内存很小的时候则不会执行fork,造成redis阻塞。)
- 降低fork频率。放宽AOF重写 自动触发机制,不必要的全量复制
2. 进程外的开销和优化
1. cpu
- 开销 :RDB和AOF文件的生成,属于CPU密集型
- 优化: 不做CPU绑定(不把redis和cpu绑定)不要和cou密集型应用部署在一起。在单机多部署的情况下,不要发生大量的aof,重写AOF,bgsave…
2. 内存
- 开销::fork内存==(liux 提供copy-on-write 子父进程共用内存件,只有父进程执行写入请求时,会创建副本,这才消耗较多内存,而在整个期间子父进程会共享父进程内存值快照)==
- 优化:不允许单机多部署时大量产生重写,在主进程写入量较少的时候重写,在liunx上做一些优化——内存页分配(禁止echo never)
3. 硬盘
- 开销:RDB和AOF文件写入
- 优化:
- 不要和高硬盘负载服务部署到一起:存储服务,消息队列等
- no-appedfsync-on-rewrite = yes
- 根据数据量决定磁盘类型:如,数据量很大的时候可以考虑ssd
- 单机多实例持久化文件目录可以考虑分盘
3.AOF追加阻塞
每秒刷盘
主从复制
单机有什么问题
若在一台机器上部署redis节点
- 机器故障
客户端无法连接redis。只能把redis迁移到别的机器,此时需要考虑数据书否丢失的问题。节点坏了,redis可以重启。——高可用 - 容量瓶颈
内存不够,加内存钱不够——分布式 - QPS瓶颈——分布式。(redis号称可以提供十万QPS,若我们需要100万该怎么做呢?)
主从复制的作用
总:
- 一个master可以有多个slave,slave还可以有slave
- 一个slave只能由一个master
- 数据流向是单向的:master—>slave
主从之间的复制是通过网络传输的。
master:
slave:
一主一从
一主多从
读写分离:
作用: 数据副本(高可用,分布式基础)、扩展读性能
方式
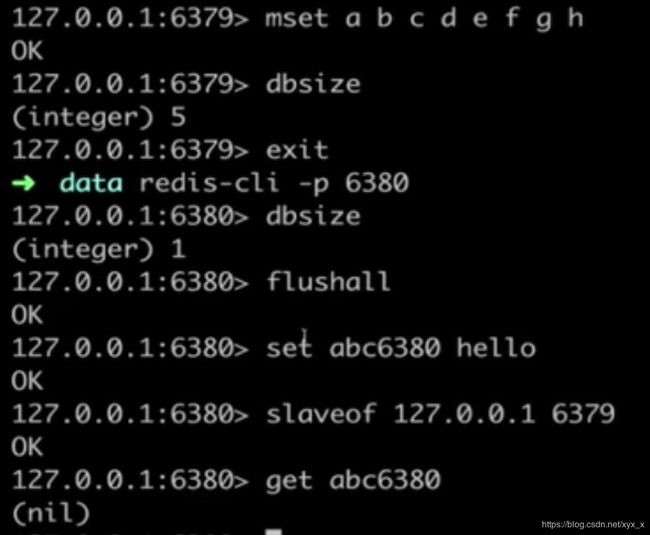
1.命令 : 在从节点执行:slaveof 127.0.0.1 (主的IP)6379(假设希望6380成为6379的从节点,此处127.0.0.1只是演示,主从在一台机器上是没有任何价值的。)
取消复制:在6380执行:slaveof no one (6380并不会清除之前从6379同步来的数据)
6380: slaveof 一个新的主,需要把6380上的所有数据删除。
2.配置
slaveof ip port
slave-read-only yes : 主从复制之读写分离。
daemonize yes : 是否已守护进程方式启动
对比:
命令: 无需重启、不便于管理
配置:统一配置、需要重启
dbfilename dump-6379.rdb:最好给不同的主从设置不同的rdb.
redis-server redis-6379.config : 指定配置文件启动
redis-cli
info replication : 查看主从信息。
127.0.0.1:6379> info replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
从:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:
master_port:6379
master_link_status:up
master_last_io_seconds_age:3
slave_repl_offset:43
slave-read-only:1
connected_slaves:0
.....
127.0.0.1:6380>