20200602 数据蛙题目一
一、操作题目
1、如何查看python已安装的第三方库(有两种方法)
通过Conda安装的:conda list
通过Pip安装的:pip list
2、Mysql特定版本 group by 后用 * 出错 ,报错出现 Error 1055 应如何解决
将group by分组的列写入select当中
二、Mysql
1、语句效率,子查询与连接后哪种效率更高?为什么?请写出具体例子。(以经典45道题为例)
连接后的效率更高(因为跳过了mysql部分的课程学习,暂时未完成经典45题)
2、left join 后的 on 条件1 and 条件2,与left join 后的 on 条件1 where 条件2,有什么区别?
前者无论筛选条件如何,左表的每一行都会输出,如果没有匹配行,用null补齐,如果on中筛选条件作用在左表,容易造成左表数据多余;
后者是先形成临时表再用where筛选,如果where筛选条件作用在右表,容易造成左表数据缺失。
三、python
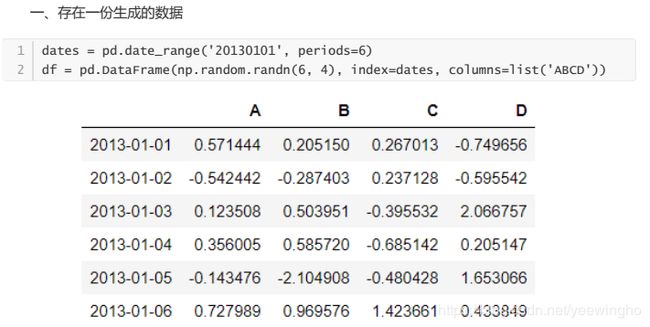
1、该生成的数据索引列的格式类型是什么?(直接回答)
Datetime
2、有哪些方式可以查看数据类型?
(1)每一列的数据类型:df.dtypes
(2)指定列数据的类型:df[A].dtypes
(3)指定行列数据的类型:df.iloc[1,2].dtype
3、如何查看索引的数据类型?
type(df.index)
4、df.loc[‘2013-01-01’] 可以取出对应第一条数据吗?
可以,或者通过索引df.iloc[0]
5、如果想要同时取 第一行和第三行数据,应该如何处理?
df.iloc[[0,2],:]
二、apply、applymap、map的区别是什么?适用场景是什么?请以上述数据搭配函数举例试验
还没学到这一部分