这就是神经网络 12:深度学习-语义分割-DeepLabV1、V2、V3和V3+
概述
说到语义分割,谷歌的DeepLab系列都是一个无法绕过的话题。目前这个系列共出了4个版本:V1、V2、V3和V3+。
本文主要关注DeepLabV3+和DeepLabV3。V1、V2作为前作,有一定的参考价值,但是我精力有限,这两篇主要从其它总结材料里学习而不是原论文,V3和V3+才是我的重点。
一个系列看下来,感觉好漫长,半辈子都快过去了,虽然实际时间不到两周。
DeepLabV1、V2的回顾
语义分割是一种对每个像素进行分类的密集预测,而普通的分类神经网络具有平移不变性,对位置不敏感,而且降采样过程会损失空间信息,不利于分割结果输出。分类网络不停的降采样,也是为了增加感知野,提取更高层的语义。那么有没有办法保存特征图的分辨率同时增加感知野呢?办法是有的,就是DeepLab采用的带孔卷积(Atrous convolution)。
带孔卷积和普通卷积核的区别示意:
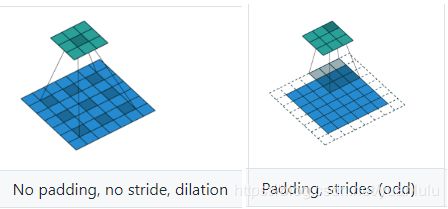
使用带孔卷积的时候,可以服用之前预训练的分类网络,把后面几层的下采样去掉,复用后面几层的卷积参数,卷积方法改为空洞卷积。这样网络最后输出的特征图分辨率提高了,感知野也保住了(计算量相对大一些)。最后进行上采样输出原图大小的score map即可。
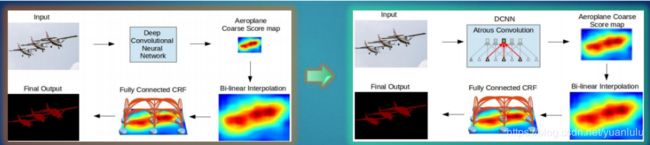
下图由左边到右边,主要是在DCNN中应用了空洞卷积密集的提取特征,左边的输出步幅是16,需要上采样16倍得到预测结果,可以看到结果是比较模糊的;而右边是在DCNN中使用空洞卷积,保持步幅为8,只需要上采样8倍,结果清晰了很多。
DeepLabV1
DeepLabv1是在VGG16的基础上做了修改:
- VGG16的全连接层转为卷积
- 最后的两个池化层去掉了下采样
- 后续卷积层的卷积核改为了空洞卷积(rate=2)
- 在ImageNet上预训练的VGG16权重上做finetune
当然,最后还采用了条件随机场(CRF)进行进一步精修,细化边缘分割效果。但是CRF已经被最新版DeepLabV3弃用了,所以这里也不多少了。
DeepLabV2
V1的带孔卷积是串行的,V2用一个ASPP模块改为并行的了,每个分支采用不同的rate(获得不同的感知野),以解决多尺度问题。同时V2也保留了CRF作为后处理手段。
V2相对V1的改进:
- 用多尺度获得更好的分割效果(使用ASPP)
- 基础层由VGG16转为ResNet
- 使用不同的学习策略(poly)
这里重点说说ASPP模块。ASPP中在给定的Input Feature Map上以r=(6,12,18,24)的3×3空洞卷积并行采样。ASPP各个空洞卷积分支采样后结果最后融合到一起(通道相同,做像素加),得到最终预测结果.

效果:

DeepLabV3
DeepLabV3给我的第一感觉是把V1的串行方法和V2的并行方法结合起来了,细节之处(rate值和BN)有改进。
DeepLabV3提出了更通用的框架,适用于任何网络。这里所说的通用是指复制了ResNet最后的block,自然也可以复制其他网络最后的block来用。
DeepLabV3 在论文中讨论了串行和并行(ASPP-Atrous Spatial Pyramid Pooling)两种风格的网络,通过对比发现并行的效果更好,所以后来再提到DeepLabV3实际是说的ASPP风格的这个版本,最终参加各种比赛刷榜的也是这个结构。
为了解决多尺度的问题,作者做了两种尝试:在串行网络结构中依次double空洞卷积率;在ASPP网络结构中采用全局池化和多种空洞卷积分支 平行计算后融合。
out_stride
论文里的out_stride参数直译过来就是输出步长,实际含义是说最后端的特征图被主干网络缩小了多少倍。论文里常用的out_stride就8和16这两个,分别表示最终特征图变为原图宽高的1/8和1/16。
注意,out_stride虽然最终的输出效果更好,但是计算量也大了很多。论文里的策略是用out_stride=16训练,用out_stride=8做推理。比赛打榜嘛,计算量什么的都不是事。
Multi-grid
Multi-grid是指在一个block内部,采用不同的空洞卷积率。
比如,在resnet的block4内有3层卷积,那么当Multi Grid = (r1, r2, r3)=(1, 2, 4),rate=2时,最终这三层卷积的空洞卷积率为 rates= 2*(1, 2, 4) = (2,4,8)。
所以空洞卷积率数是Multi-grid和rate参数的乘积。下图b中,block4的空洞卷积率为2*(1, 2, 4) = (2,4,8),block5的空洞卷积率为4*(1, 2, 4) = (4,8,16),后面的两个block同理可知。注意这个规则仅仅在串行的Multi-grid有用,在ASSP中不需要相乘。
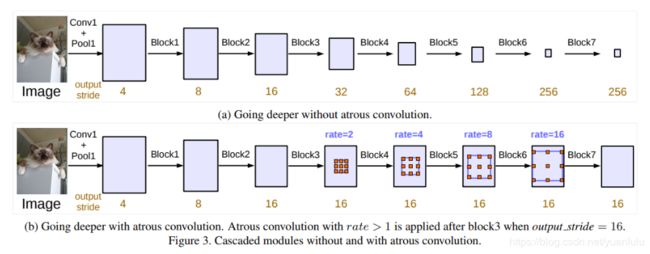
串行的DeepLabV3
上图b中已经把串行的空洞卷积画出来了,注意后面block5~7是复制的block4的结构,都是三层卷积(刚好使用Multi-grid的三个参数),只是rate参数不一样。作者实验了不同的网络结构和不同的block个数,发现网络越深效果越好。
table2表明更深的resnet101好于resnet50。table3表明使用更多block串行连接对结果也是有好处的。
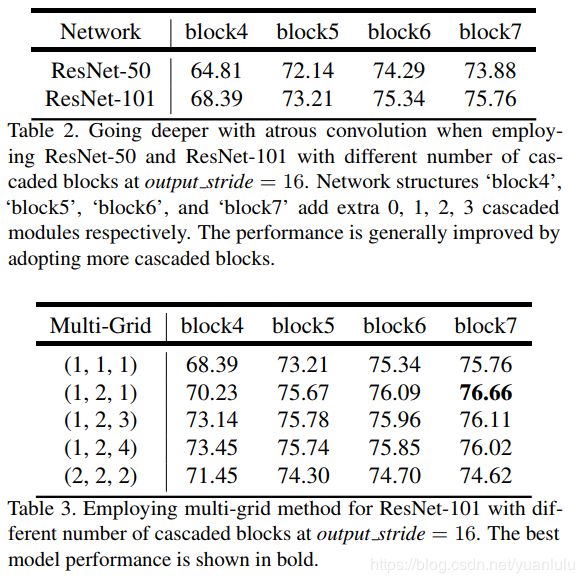
同时作者还发现了一个有趣的实验现象,那就是训练时用output stride = 16,测试时用output stride = 8,效果更好。table还说明多尺度数据增广和左右翻转数据增广也能涨点。

后续实验应该都是在ResNet-101上进行的。
并行的DeepLabV3(ASPP)
这里并行的版本是在保留block4的基础上,加入了ASPP模块。网络结构如下:
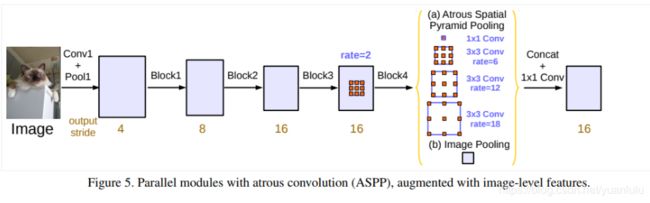
相比于DeepLabv2,DeepLabV3在ASPP中应用了BN层。因为作者实验发现BN很重要。
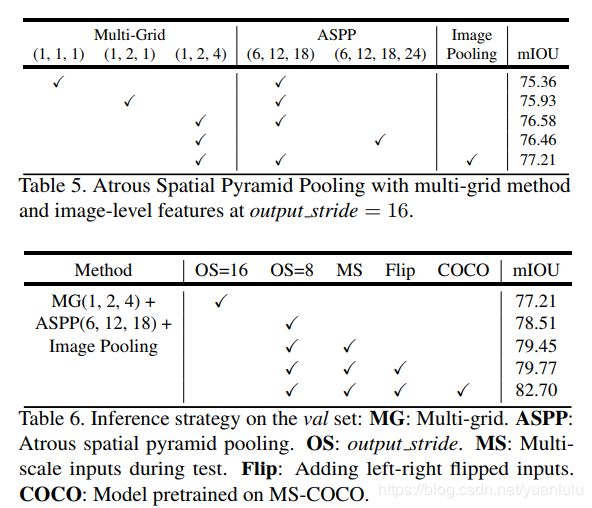
table5中作者通过实验对比发现block4的Multi Grid =(1, 2, 4)效果最好,而ASPP部分,rate为(6,12,18,24)的4个分支并不比(6,12,18)三个分支效果好。block4内的空洞卷积率还要乘以2,ASPP内的空洞卷积率不需要做变换,就等于rate值。
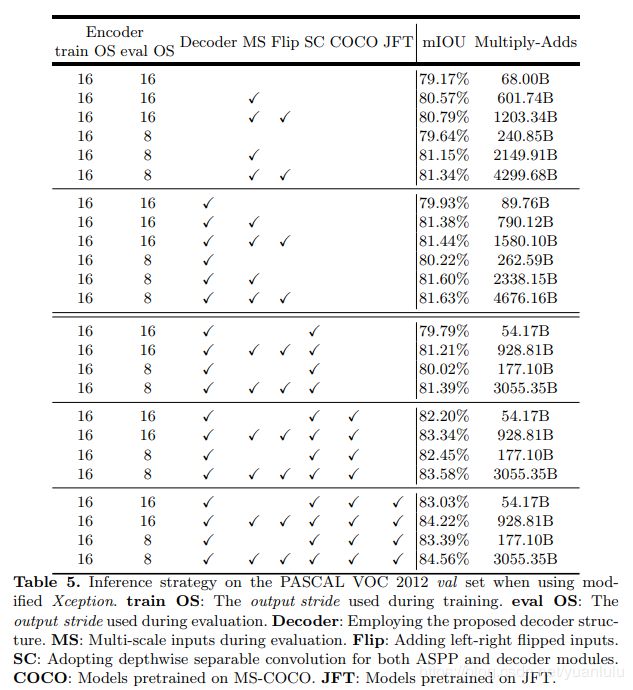
table6中,作者同样发现,out_stride=8做推理效果更好(训练时是16)。同时跟踪数据增广(不同大小和翻转图像最后求平均)和使用更大的数据集预训练都有收益。注意MS和Flip属于多次计算求平均的办法,会极大增加计算量。
注意,作者在table5中单独列了一栏image pooling。这是因为作者发现空洞卷积率太大,效果就接近1x1卷积了,起不到获取大的感受野的作用,所以作者增加了一个分支做全局平局,然后再上采样回到原来的尺度。
ASPP 最终所有分支的特征拼接在一起,再用1x1卷积将通道数降到输入特征相同的数量。
作者通过对比发现,ASPP版本的网络比串行的网络想过要好,所以最终选择ASPP版本的结果作为最终参赛的结构,后续实验都是ASPP结构上做的。
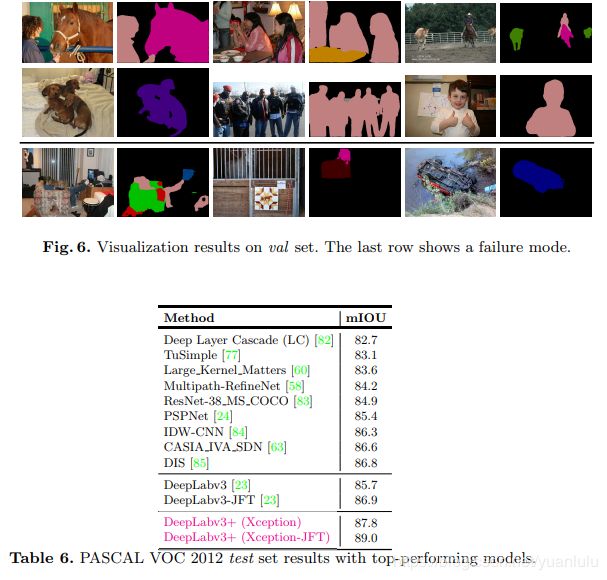
测试效果
下标的JFT版本是在JFT300M数据库上预训练的。


代码实现
看了几个实现版本,基本都是在block4内的三层卷积把空洞卷积率都设置为2。我猜测可能有两个原因,1:作者描述Multi Grid不够清晰,导致很多人没理解;2:上面ASPP版本的网络结构图画的block4的rate为2,令人迷惑,实际还要用这个rate乘以Multi Grid值;3:很多人为了利用tensorflow官方提供的预训练版本的resnet,使用了tensorflow源码中的构建计算图的代码,而这份代码我看过之后觉得是给串行方式的deeplabv3准备的,直接在block4的三层卷积空洞卷积率都设置为2,而不是遵循Multi Grid设置为不同的值。
DeepLabV3+
DeepLabV3+可以看做是DeepLabV3的改进版(名字上也体现的很明显)。主要改进就3点:
- 主干网络是微软的可变形卷积思想改造的Xception
- 增加decoder部分,融合更底层的特征
- 使用深度可分离卷积改造ASPP和decoder部分,减少计算量
网络结构
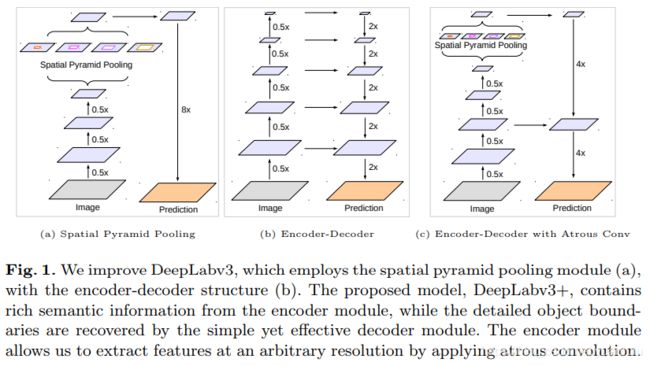
下图左侧是DeepLabV3的结构,中间是U-Net风格的编解码结构,最右侧就是DeepLabV3+的结构。和V3相比,V3+融合了一次底层特征图。
更详细的结构如下:
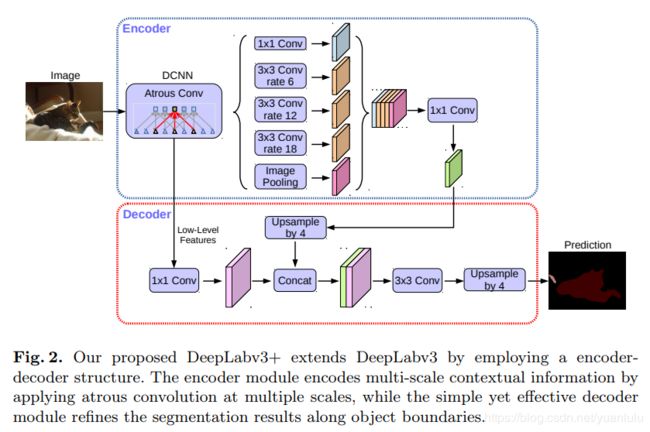
底层的特征先被1x1降维到48通道和ASPP输出特征的4倍上采样拼接,然后通过两层3x3卷积变换,最后4倍线性上采样输出到原图大小。这里的上采样时双线性插值,不是反卷积。
为何融合前用1x1降到48通道而不是更多,为何拼接后用两层3x3卷积而不是1层和3层,为何只融合一次底层特征,这都是作者一个个实验做出来最终结论,只看结果的话会失去很多乐趣。
这也许能告诉我们,计算量不是越多越好,融合哪一层特征有额没有定论,都要结合实验结果来说话。网络结构设计目前还处于炼丹极端,虽然有一些大的原则可以参考,但是没有严密的方法。
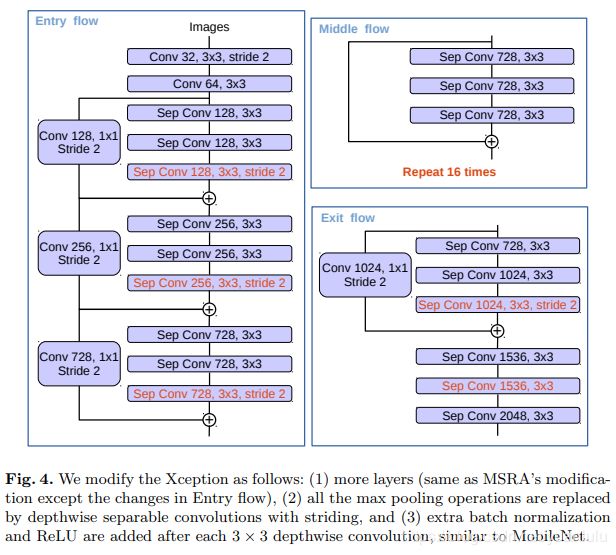
对主干网络的修改
本作的backbone是基于可变形卷积网络(Deformable Convolutional Networks)的,可变形卷积网络是基于Xception改进的。在对Xception的修改方面,本文在以下几个方面和可变形卷积网络不同:
- 虽然都增加深了Xception(中间层增加了repeat次数),但是为了节省计算资源没有修改entry flow
- 最大池化操作都被stride为2的3x3卷积代替了,为的就是用带孔卷积改造网络结构
- 每个3x3深度可分离卷积后都增加了BN和Relu
实验结果
论文
DeepLabV1:SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL
NETS AND FULLY CONNECTED CRFS
DeeplabV2:DeepLab: Semantic Image Segmentation with
Deep Convolutional Nets, Atrous Convolution,
and Fully Connected CRFs
DeeplabV3:Rethinking Atrous Convolution for Semantic Image Segmentation
DeeplabV3+:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
参考资料
知乎:如何理解空洞卷积(dilated convolution)?
DeepLabV3官方PPT,介绍了V1-V3的发展思路
Semantic Segmentation --DeepLab(1,2,3)系列总结
Deeplab 系列文章读书笔记
Deeplab V3阅读笔记
DeepLabv3+:语义分割领域的新高峰
谷歌开源最新语义图像分割模型DeepLab-v3+
如何评价 MSRA 最新的 Deformable Convolutional Networks?