ElasticSearch核心基础之索引管理
一 索引管理
1.1 创建索引
# 建立索引的时候,我们可以设置主分片和备份分片的数量通过setting字段number_of_shards和number_of_replicas字段设置
# 对于ES的文档而言,一个文档会包含一个或者多个字段,任何字段都要有自己的数据类型,例如string、integer、date等。ElasticSearch中是通过映射来进行字段和数据类型对应的。在默认的情况下ElasticSearch会自动识别字段的数据类型。同时ElasticSearch提供了mappings参数可以显示的进行映射
PUT /web //索引名字
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"site": { // 类型
"properties": {
"title": {"type" : "text"},
"content":{"type":"string","index":"not_analyzed"}
}
}
}
}
1.2 删除索引
DELETE /index
DELETE /index1,index2
DELETE /index*
DELETE /_all
1.3 修改索引
PUT /web/_settings
{
"number_of_replicas": 1
}
1.4 获取索引
GET 127.0.0.1:9200/web
1.5 打开、关闭索引
打开、关闭索引接口允许关闭一个打开的索引或者打开一个关闭的索引。关闭的索引只能显示索引元数据信息,不能进行读写操作
POST 127.0.0.1:9200/web/_open
二 索引映射管理
有时候我们在字段映射的时候,需要进行一些更加高级的设置,比如索引分词,是否存储等
2.1 增加映射
向索引web添加类型logs,字段message类型为string
PUT /web
{
"mappings": {
"logs":{
"properties": {
"messages":{"type": "string"}
}
}
}
}
或者
PUT /web/_mapping/logs
{
"properties": {
"messages":{"type": "string"}
}
}
2.2 更新字段映射
一般情况下,一旦字段映射建立,我们不会更新,但有时候可能会,比如新的属性被添加到对象数据类型字段,增加了ignore_above参数
2.3 不同类型之间的冲突
在同一个索引中, 不同类型可能存在相同的名字的字段,所以相同名字的字段中必须有相同的映射。如果视图在这种情况下更新参数,系统将会抛出异常。除非在更新的时候指定update_all_types参数。
比如数据:
PUT 127.0.0.1:9200/web
{
"mappings": {
"type1":{
"properties": {
"messages":{"type":"string","analyzer": "standard"}
}
},
"type2":{
"properties": {
"messages":{"type":"string","analyzer": "standard"}
}
}
}
}
现在修改为:
PUT 127.0.0.1:9200/web/_mapping/type1
{
"properties": {
"messages":{
"type": "string",
"analyzer": "standard",
"search_analyzer": "whitespace"
}
}
}
此时就会报错。然后增加update_all_types,此时就会同时更新type1和type2两个类型。
PUT127.0.0.1:9200/web/_mapping/type1?update_all_types
{
"properties": {
"messages":{
"type": "string",
"analyzer": "standard",
"search_analyzer":"whitespace"
}
}
}
2.4 获取映射
获取文档映射接口允许通过索引或者索引和类型来搜索:
GET 127.0.0.1:9200/web/_mapping/type1
系统支出同时获取多个索引或者类型,多个索引或者类型以逗号分割
如下:
GET 127.0.0.1:9200/{web,logs}/_mapping/type1
GET 127.0.0.1:9200/web/_mapping/{type1,type2}
也可以使用_all来表示全部索引或者直接省略_all也可以
GET 127.0.0.1:9200/_all/_mapping/type1,type2
GET 127.0.0.1:9200/_mapping/type1,type2
2.5 判断文档索引或者类型是否存在
HEAD http://127.0.0.1:9200/web/book
三 索引别名
我们可以为索引创建别名,类似于数据库中的视图
3.1 创建或者删除别名
POST http://127.0.0.1:9200/_aliases
{
"actions": [
{"add": {"index": "web","alias":"site"}},
{"add": {"index":"article","alias": "book"}}
]
}
POST http://127.0.0.1:9200/_aliases
{
"actions": [
{
"remove": {
"index": "web",
"alias": "site"
}
}
]
}
3.2 过滤索引别名
POST http://127.0.0.1:9200/_aliases
{
"actions": [
{
"add": {
"index": "web",
"alias": "site",
"filter": {
"term": {
"user": "nicky"
}
}
}
}
]
}
3.3 别名与路由
通过别名也可以和路由关联,可以避免不必要的碎片操作:
POST http://127.0.0.1:9200/_aliases
{
"actions": [
{
"add": {
"index": "web","alias":"site","routing": "1"
}
}
]
}
同时我可以指定索引路由和搜索路由,但是索引路由只能指定一个,搜索路由可以指定多个:
POST http://127.0.0.1:9200/_aliases
{
"actions": [
{
"add": {
"index": "web","alias":"site","search_routing":"2,3","index_routing":"1"
}
}
]
}
我们还可以直接通过请求参数添加别名:
语法:PUT/{index}/_alias/{name}
PUT http://127.0.0.1:9200/web/_alias/site
{
"routing": "1",
"filter": {
"term": {
"name": "tmall"
}
}
}
3.4 建索引的时候同时指定别名
PUT http://127.0.0.1:9200/web
{
"mappings": {
"type":{
"properties": {"year":{"type":"integer"}}
}
},
"aliases": {
"current_day": {},
"2014":{
"filter": {"term":{"year":2014}}
}
}
}
3.5 删除别名
DELETE http://127.0.0.1:9200/{index}/_alias/{name}
3.6 查询现有的别名
GET http://127.0.0.1:9200/{index}/_alias/{name}
GET http://127.0.0.1:9200/{index}/_alias/*
四 索引配置
在ElasticSearch中索引有很多的配置参数,有些配置是可以在建好索引重新设置的,比如索引的副本数量、索引分词等
4.1 更新索引配置
# 先关闭索引
PUT http://127.0.0.1:9200/web/_closed
# 添加分词器:
PUT http://127.0.0.1:9200/web/_settings
{
"analysis": {
"analyzer": {
"content":{"type":"custom","tokenizer":"whitespace"}
}
}
# 在打开索引
PUT http://127.0.0.1:9200/web/_open
4.2 获取配置
索引中包含很多配置参数,可以通过下面命令获取索引的参数配置
GET http://127.0.0.1:9200/web/_settings
GET http://127.0.0.1:9200/web/_settings/name=index.number.*
name=index.number.*: 表示设置将只返回number_of_replicas,number_of_shards两个参数
4.3 索引分析
索引分析(analysis)是这样一个过程:首先,把一个文本块分析称一个个单独的词term,为了后面的倒排索引做准备。然后标准化这些词为标准形式,提高他们的可搜索性,这些工作是由分析器analyzers来完成的,分析器analyzers是一个组合,用于将三个功能放到一起:
# 字符集过滤:字符串经过字符过滤器(character filter)处理,他们的工作是在标记化之前处理的字符串
# 分词器:分词器tokenizer被标记化为独立的词。一个简单的分词器可以根据空格或者逗号将单词分开
# 标记过滤器:每一个词通过所有标记过滤器token filters处理,他可以修改词(比如Quick转化为小写,去掉词比如a,an,the等或者增加同义词之类的)
ElasticSearch提供了很多内置的字符过滤器,分词器和标记过滤器。这些可以在组合起来创建自定义的分析器以应对不同的需求
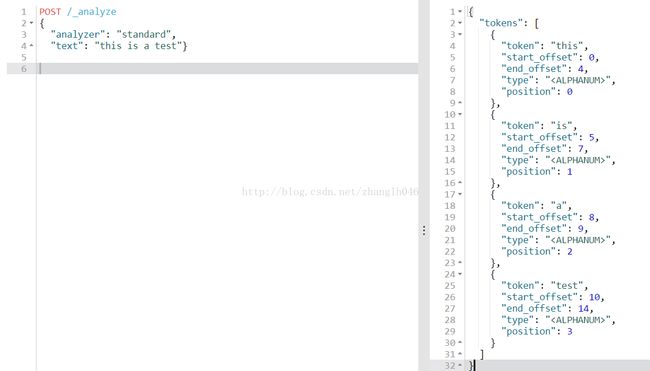
自定义分析器:
请求POSTlocalhost:9200/_anylyze
POST /_analyze
{
"tokenizer": "keyword",
"char_filter": ["html_strip"],
"explain": true,
"text": "this is a test
}
表示适用keyword分词器,字符过滤器是html_strip,explain表示获取分析器更多的细节
五 索引监控
索引监控主要就是涉及到索引的统计信息,碎片信息,恢复的状态和分片的信息,利用这些接口随时监控索引的状态
5.1 索引统计
索引统计接口提供索引中不同内容的统计数据,比如:
GET localhost:9200/_stats
GET localhost:9200/{index1,index2}/_stats
默认返回所有的统计数据,也可以在URL中指定需要返回的特定统计数据
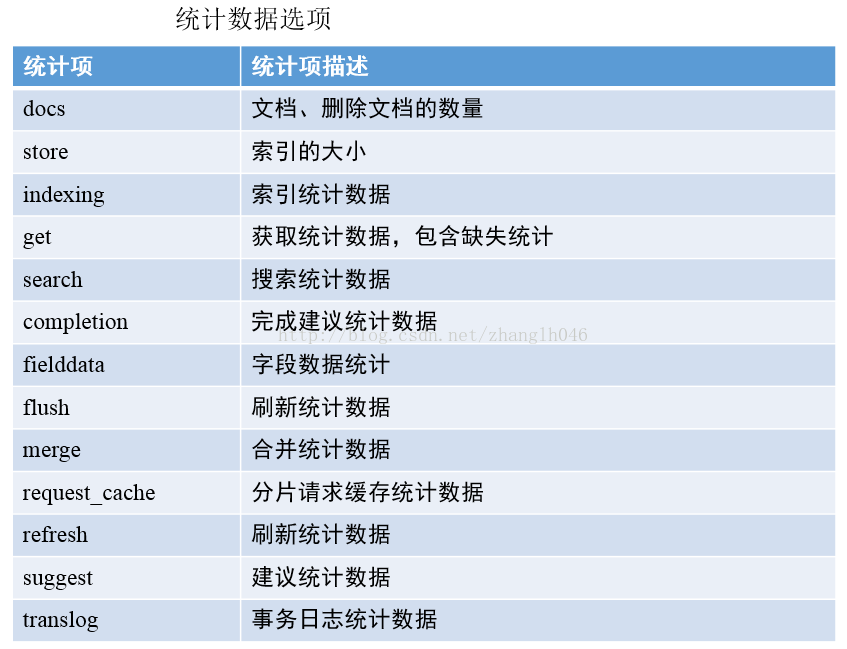
# 获取所有索引的混合和刷新统计数据
GET http://127.0.0.1:9200/_stats/merge,refresh
# 获取名为web索引中类型为type1和type2的文档统计数据
GET http://127.0.0.1:9200/web/_stats/indexing?types=type1,type2
另外返回的统计数据在索引级别发生聚合,生成名为primaries和total的聚合。其中primaries仅包含主分片的值,total是主分片和从分片的累计值。
为了获取分片级别的统计数据,需要设置level参数为shards
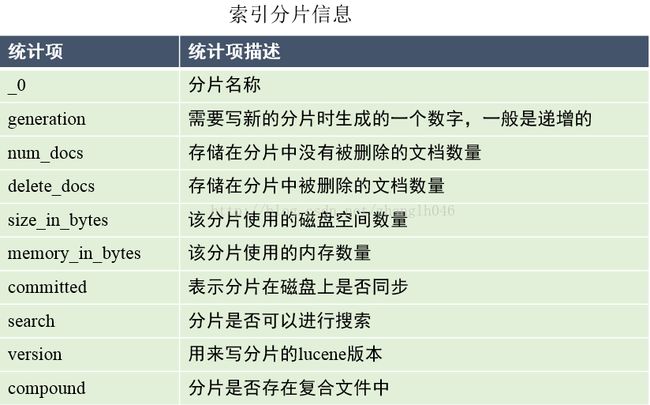
5.2 索引分片
提供Lucene索引所在的分片信息。可以用来提供分片和索引的更多统计信息,可能是优化信息,删除垃圾数据等
GET http://127.0.0.1:9200/web/_segments
GET http://127.0.0.1:9200/web,book/_segments
GET http://127.0.0.1:9200/_segments

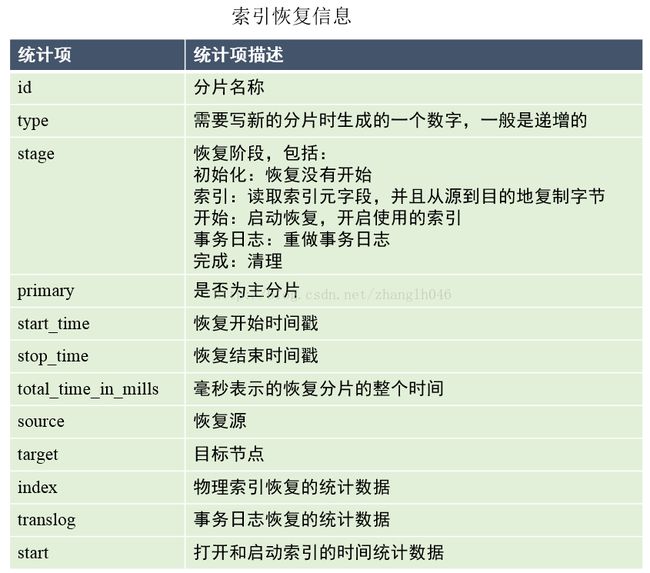
5.3 索引恢复
索引恢复接口提供正在进行恢复的索引分片信息。可以报告指定索引或者集群范围的恢复状态
GET http://127.0.0.1:9200/web,book/_recovery
去掉索引名可以查看集群范围的恢复状态:
GET http://127.0.0.1:9200/_recovery?pretty&human
六 状态管理
ElasticSearch中还有一些和索引相关的重要接口需要介绍,这些接口包括清除索引缓存、索引刷新、冲洗索引、合并索引接口
6.1 清除缓存
POST http://127.0.0.1:9200/web/_cache/clear
默认清理所有缓存,你也可以指定query,fielddata,request来清理特定缓存
6.2 索引刷新refresh
刷新接口可以明确的刷新一个或多个索引,使之前最后一次刷新之后的所有操作被执行
POST http://127.0.0.1:9200/web/_refresh
POST http://127.0.0.1:9200/web,book/_refresh
POST http://127.0.0.1:9200/_refresh
6.3 flush
可以冲洗一个或者多个索引,将数据保存到索引存储并且清除内部事务日志,以此来释放索引的内存空间
POST http://127.0.0.1:9200/_flush
6.4 合并索引
合并接口可以强制合并一个或者多个索引。合并分片数量和每一个分片保存的Lucene索引,强制合并可以通过合并减少分片数量。
调用会被阻塞一直到合并完成。如果http连接丢失,请求 后台继续执行,任何新的请求都会被阻塞直到一个强制合并完成
POST http://127.0.0.1:9200/web/_forcemerge
POST http://127.0.0.1:9200/web,book/_forcemerge
POST http://127.0.0.1:9200/_forcemerge
七 文档管理
7.1 增加文档
就是把一条文档增加到索引中,使他可以被搜索,文档的格式是JSON格式。注意,在ElasticSearch中如果有相同ID的文档存在,则更新此文档
语法:PUT /{index}/{type}/{docId}
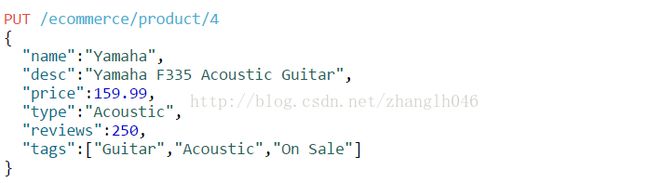
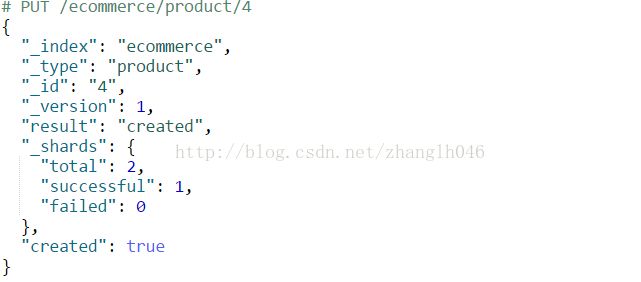
返回的信息:
total: 文档被创建的时候,在多少个分片中进行了操作,包括主分片和副本分片
successful: 成功建立索引分片的数量,当创建成功后,成功创建索引分片的数量最少是1
failed: 失败建索引分片的数量
# 自动创建索引
当创建文档的时候,如果索引不存在,则会自动创建索引。自动创建的索引会自动映射每一个字段的类型。自动创建字段类型是非常灵活的,新的字段类型将会自动匹配字段对象的类型。
我们也可以通过配置文件action.auto_create_index为fasle在所有节点禁止配置文件中禁止自动创建索引;通过设置index.mapper.dynamic为false禁止自动映射类型
# 版本号
每一个文档都有一个版本号,版本号的具体值放在创建索引返回值_version中的,通过版本号参数可以达到并发控制的效果,比如更新文档:
PUT /ecommerce/product/4?_version=1&pretty
{
"desc":"YamahaF335",
"price":129.19
}
# 操作类型
系统同时支持op_type=create参数强制命令执行创建操作,只有系统中不存在此文档的时候才会创建成功,如果不指定此操作类型,如果存在此文档,则会更新此文档
POST /ecommerce/product/4?op_type=create&pretty
{
"name":"Yamaha",
"desc":"YamahaF335 Acoustic Guitar",
"price":159.99,
"type":"Acoustic",
"reviews":250,
"tags":["Guitar","Acoustic","OnSale"]
}
# 自动创建ID
当创建文档的时候,如果不指定ID,系统会自动创建ID.自动生成的ID是一个不会重复的随机数。但是在5.x系列必须指定id,否则报错例如:
POST /ecommerce/product?op_type=create&pretty
{
"name":"RoundGlasses",
"desc":"RoundGlasses #120100",
"price":59.09,
"type":"Round",
"reviews":100,
"tags":["Round","Glasses"]
}
# 分片选择
我们在创建文档的时候,可以指定该文档散落在哪一个分片上,这个值只可以通过router来控制
POST/ecommerce/product?routing=ecommerce&pretty
{
"name":"RoundGlasses",
"desc":"RoundGlasses #120100",
"price":59.09,
"type":"Round",
"reviews":100,
"tags":["Round","Glasses"]
}
比如上面就是通过routing=ecommerce的散列值来决定落在哪一个分片上
7.2 更新删除文档
# 第一种更新方式
判断文档id是否存在,如果存在则更新,不存在则添加
POST /ecommerce/product/1/
{
"price":45.78
}
# 第二种更新方式,开启动态脚本功能,新版本 默认禁用
如果要使用,需要在elasticsearch.yml中添加如下配置:
script.inline:on
script.indexed:on
script.file:on
POST /ecommerce/product/4/_update?pretty
{
"script": {
"inline": "ctx._source.price += p",
"params": {"p":12}
}
}
7.3 查询文档
GET http://127.0.0.1:9200/ecommerce/product/1
查询操纵都是实时查询,如果不希望实时查询,则可以全局设置action.get.realtime为false
# 我们还可以禁止返回原始数据即_source
GET http://127.0.0.1:9200/ecommerce/product/1? _source=false
# 如果你只想获取source一部分内容,可以使用_source_include或者_source_exclude参数
GET /ecommerce/product/4?_source_exclude=desc,type
GET/ecommerce/product/4?_source_include=name,price,reviews
# 还可以通过fields字段过滤(以前版本)
GET /ecommerce/product/4?fields=name,price,reviews
# 只获取文档内容,不获取额外的信息
GET /ecommerce/product/4/_source
# 查询的时候指定分片
GET /ecommerce/product/4?routing=ecommerce&pretty
# 查询参数
_primary: 在主节点查询
_local: 尽可能在本地节点查询
refresh: 在搜索之前刷新相关的分片可以保证及时查询到,但是这个参数会消耗系统资源,除非有必要,否则不需要设置
GET /ecommerce/product/4? _primary=true&refresh=true
7.4 索引词频率
Term Vector(检索词向量):是Lucene的概念,就是相当于文档的每一列,如title,body这种文本类型的建立词频的多维向量空间,每一个词就是一个维度,这个维度的值就是这个词在这个列中的频率。
在ElasticSearch中,_termvectors返回索引中特定文档字段的统计信息,termvectors在ElasticSearch中是实时分析的,如果不想要实时分析,可以设置realtime参数。默认情况索引词频统计是关闭的,需要在建索引的时候手工打开。
# 设置索引
PUT http://hadoop-all-01:9200/secisland
{
"mappings": {
"secilog":{
"properties": {
"type":{
"type": "string", // 在5.x版本是text
"term_vector": "with_positions_offsets",
"store": true,
"analyzer":"fulltext_analyzer"
},
"message":{
"type": "string", // 在5.x版本是text
"term_vector":"with_positions_offsets",
"analyzer":"fulltext_analyzer"
}
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"fulltext_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["lowercase"]
}
}
}
}
}
# 添加文档
PUT http://hadoop-all-01:9200/secisland/secilog/1
{
"type":"syslog",
"message":"secilog test test test"
}
PUT http://hadoop-all-01:9200/secisland/secilog/2
{
"type":"file",
"message":"Another secilog test"
}
GET http://hadoop-all-01:9200/secisland/secilog/1/_termvectors
{
"_index": "secisland",
"_type": "secilog",
"_id": "1",
"_version": 1,
"found": true,
"took": 32,
"term_vectors": {
"message": {
"field_statistics": {
"sum_doc_freq": 5,
"doc_count": 2,
"sum_ttf": 7
},
"terms": {
"secilog": {
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 7
}
]
},
"test": {
"term_freq": 3,
"tokens": [
{
"position": 1,
"start_offset": 8,
"end_offset": 12
},
{
"position": 2,
"start_offset": 13,
"end_offset": 17
},
{
"position": 3,
"start_offset": 18,
"end_offset": 22
}
]
}
}
},
"type": {
"field_statistics": {
"sum_doc_freq": 2,
"doc_count": 2,
"sum_ttf": 2
},
"terms": {
"syslog": {
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 6
}
]
}
}
}
}
}
我们只关注term_vectors字段信息:
# message 和 type使我们要统计的字段
# field_statistics:整个索引下类型的所有文档统计
sum_doc_freq:该字段中词的数量(去掉重复的数目)
sum_ttf文档中词的数量(包含重复的数目)
doc_count涉及的文档数等等
# terms:词统计
term_freq:该次出现频率
tokens:
position: 位置,处于文本第几个单词
start_offset:词的开始偏移量
end_offset:词的结束偏移量