ElasticSearch中doc values和fielddata
一 为什么聚合排序不适合使用倒排序索引
假设现在有以下的一个搜索:
POST /ecommerce/music/_search
{
"size":0,
"query":{
"match":{
"desc":"吉他"
}
},
"aggs":{
"brands":{
"terms":{"field":"brand.keyword"}
}
}
}
对于搜索,使用倒排索引,无可争议。但是对于聚合,使用倒排索引呢?
我们知道搜索时term到document的映射,聚合或者排序是从document到term的映射。所以要聚合,我们就得找到这个10000条document的所有的term。
即从头开始一直到倒排索引结束,所有的term都有可能是处于你要查找的文档中,需要从头到尾遍历一次,举个例子:
"brand": "蝶泉",
"desc": "蝶泉乐器厂家特价直销10级全新正品163标准古筝初学者14款可选",
"color": "黑",
"origin": "中国",
"sales": 648,
"price": 558,
"review": 5708,
"c_date": "2015-11-09"
那么蝶泉, 乐器厂, 厂家,直销, 黑,中国等term都有可能包含在这个文档中,所以需要整个遍历一次。
如果假设有100万个document,那么它包含的term可能上千万,那么对于性能来说,不是很好的。
为什么正排索引就合适了?
我们知道正排索引是document到term的映射。我们构建正派索引类似于二维表中的每一列,即所谓的列式存储。比如:
Doc1: 蝶泉, 乐器厂, 厂家,直销, 黑,中国
Doc2: 雅马哈,电钢琴,黑,法国,智能,数码钢琴,数码,钢琴
如果这里有100万条document,所以这种结构,我们一次查找最多遍历1000000次,而不是遍历千万次,所以性能提升很多
二 fielddata
我们知道,倒排文档来做聚合,排序是不合适的,那么ES引入fielddata的数据结构,其实根据倒排索引反向出来的一个正排索引,即document到term的映射。
只要我们针对需要分词的字段设置了fielddata,就可以使用该字段进行聚合,排序等。我们设置为true之后,在索引期间,就会以列式存储在内存中。为什么存在于内存呢,因为按照term聚合,需要执行更加复杂的算法和操作,如果基于磁盘或者 OS 缓存,性能会比较差。
2.1fielddata加载到内存的时机
fielddata加载到内又几种策略,默认是懒加载。即对一个分词的字段执行聚合或者排序的时候,加载到内存。所以他不是在索引创建期间创建的,而是查询在期间创建的。
2.2 监控fielddata内存使用
GET /_stats/fielddata?fields=*
GET /_nodes/stats/indices/fielddata?fields=*
GET/_nodes/stats/indices/fielddata?level=indices&fields=*
2.3fielddata内存管理和限制
那么基于内存,那又会带来一些问题。如果我们不对内存加以控制,如果数据量太大,很容易造成OOM。那我们应该如何控制fielddata呢?
2.3.1 缓存限制
我们可以配置fielddata内存限制,超出这个限制就清除内存中已有的fielddata数据
indices.fielddata.cache.size: 20%
默认无限制,限制内存使用,但是会导致频繁evict和reload,大量IO性能损耗,以及内存碎片和gc
2.3.2 circuitbreaker
如果一次query load的fielddata超过总内存,就会发生内存溢出,circuit breaker会估算query要加载的fielddata大小,如果超出总内存,就短路,query直接失败
indices.breaker.fielddata.limit:fielddata的内存限制,默认60%
indices.breaker.request.limit:执行聚合的内存限制,默认40%
indices.breaker.total.limit:综合上面两个,限制在70%以内
2.3.3 frequency
min: 0.01 只是加载至少1%的doc文档中出现过的term对应的文档
比如说tiger,总共有10000个文档,tiger必须在100个文档中出现。
min_segment_size: 500 少于500 文档数的segment不加载fielddata,
加载fielddata的时候,也是按照segment去进行加载的,某个segment里面的doc数量少于500个,那么这个segment的fielddata就不加载
PUT /animals/_mapping/crawler
{
"properties":{
"desc":{
"type":"text",
"fielddata": {
"filter": {
"frequency": {
"min":0.01,
"min_segment_size": 500
}
}
}
}
}
}
2.4fielddata加载机制
如果要对分词的字段执行聚合,那么每次都在查询的时候才生成fielddata并加载到内存中来,速度可能会比较慢。
所以它提供了集中load机制。
2.4.1lazy懒加载
默认就是这个加载方式,仅在需要的时候加载到内存,即只有使用到了这个分词字段用于聚合或者排序才会被加载到内存。
2.4.2 eager预加载
当一个新的段形成时,无论是刷新还是合并,可以预先加载的字段提前把段的fielddata加载到内存,当你第一次查询的时候,如果碰到在这个段上,你不需要再触发加载fielddata的操作,它们已经在内存中了
2.4.3eager_global_ordinals 全局序数预先加载
什么是全局序数?
一项用于减少string类型的fielddata占用内存的技术叫做序数。
举个例子:
假设每一个文档都有一个有限值的字段,比如性别:男 女 男孩 女孩 人妖 5中类型的字段
Doc1: 男
Doc2: 男孩
Doc3: 男
Doc4: 人妖
Doc5: 女
Doc6: 女孩
Doc7: 男孩
Doc8: 女
有很多重复值的情况,会进行global ordinal标记,比如
男:0
女:1
男孩:2
女孩:3
人妖:4
然后就会形成:
Doc1: 0
Doc2: 2
Doc3: 0
Doc4: 4
Doc5: 1
Doc6: 3
Doc7: 2
Doc8: 1
这样的好处就是减少重复字符串的大小,减少内存的消耗
PUT /animals/_mapping/crawler
{
"properties":{
"desc":{
"type":"text",
"fielddata": {
"loading" : "eager"
}
}
}
}
"fielddata": {
"loading" : "eager_global_ordinals"
}
2.5 fielddata例子
首先创建一个索引映射
PUT /animals
{
"mappings": {
"crawler":{
"properties":{
"desc":{
"type":"text"
},
"content":{
"type":"text",
"index": "not_analyzed"
}
}
}
}
}
然后添加数据
PUT /animals/crawler/1
{
"desc":"red",
"content":"monkey"
}
PUT /animals/crawler/2
{
"desc":"red",
"content":"snake"
}
PUT /animals/crawler/3
{
"desc":"yellow",
"content":"tiger"
}
然后开始使用分词字段desc聚合,
POST /animals/crawler/_search
{
"size":0,
"aggs":{
"desc_aggs":{
"terms":{"field":"desc"}
}
}
}
这个时候,会报错的。
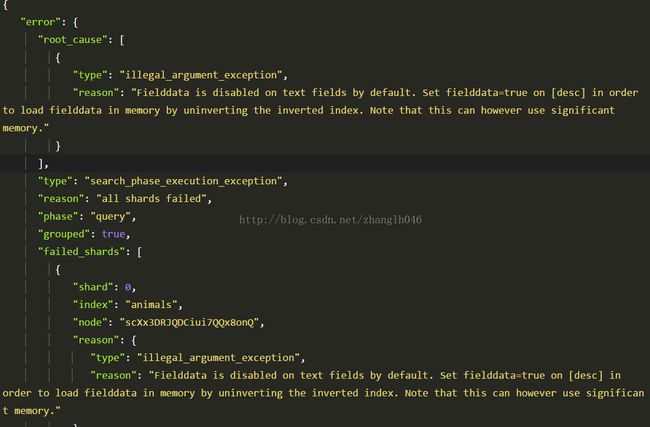
然后我们尝试修改索引映射,在分此字段desc,添加fielddata=true
PUT /animals/_mapping/crawler
{
"properties":{
"desc":{
"type":"text",
"fielddata": true
}
}
}
再去聚合的时候就有结果了:
"aggregations": {
"desc_aggs": {
"doc_count_error_upper_bound":0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "red",
"doc_count": 2
},
{
"key": "yellow",
"doc_count": 2
}
]
}
}
三 doc_value
我们知道fielddata堆内存要求很高,如果数据量太大,对于JVM来及回收来说存在一定的挑战。所以doc_value的出现我们可以使用磁盘存储,他同样是和fielddata一样的数据结构,在倒排索引基础上反向出来的正排索引,并且是预先构建,即在建倒排索引的时候,就会创建doc values。,这会消耗额外的存储空间,但是对于JVM的内存需求就会减少。总体来看,DocValues只是比fielddata慢一点,大概10-25%,则带来了更多的稳定性。
写入磁盘文件中,OS Cache先进行缓存,以提升访问doc value正排索引的性能,如果OS Cache内存大小不足够放得下整个正排索引,doc value,就会将doc value的数据写入磁盘文件中。
它是对不分词的字段,默认建立doc_values,即字段类型为keyword,他不会创建分词,就会默认建立doc_value,如果我们不想该字段参与聚合排序,我们可以设置doc_values=false,避免不必要的磁盘空间浪费。但是这个只能在索引映射的时候做,即索引映射建好之后不能修改。
对于类型是string的字段,一般会生成分词字段和不分词字段,不分词字段即使用keyword,所以我们在聚合的时候,可以直接使用field.keyword进行聚合,而这种默认就是使用doc_values,建立正排索引。
四 fielddata 和 doc_value的比较
4.1 相同点
# 都要创建正排索引,数据结构类似于列式存储
# 都是为了可以聚合,排序之类的操作
4.2 不同点
# 存储索引数据的方式不一样:
fielddata: 内存存储;doc_values: OS Cache+磁盘存储
# 对应的字段类型不一样
fielddata: 对应的字段类型是text; doc_values:对应的字段类型是keyword
# 针对的类型,也不一样
field_data主要针对的是分词字段;doc_values针对大是不分词字段
# 是否开启
fielddata默认不开启;doc_values默认是开启