鬼吹灯文本挖掘3:关键词提取extract_tags和使用sklearn TfidfTransformer 计算TF-IDF矩阵
鬼吹灯文本挖掘1:jieba分词和CountVectorizer向量化
鬼吹灯文本挖掘2:wordcloud 词云展示
鬼吹灯文本挖掘3:关键词提取和使用sklearn 计算TF-IDF矩阵
鬼吹灯文本挖掘4:LDA模型提取文档主题 sklearn LatentDirichletAllocation和gensim LdaModel
鬼吹灯文本挖掘5:sklearn实现文本聚类和文本分类
1. jieba模块进行关键词提取 : 数据gcd1_chap的准备参考鬼吹灯文本挖掘1
jiaba.analyse.extract_tags() 可以使用默认的TF-IDF模型对文档进行分析。
参数withWeight设置为True时可以显示词的权重,topK设置显示的词的个数。
# 注意:函数是在使用默认的TF-IDF模型进行分析
jieba.analyse.extract_tags(gcd1_chap.txt[1])
['胡国华','老鼠','王二','杠子','舅舅','福寿','纸人','床上','保安队','媳妇','烟瘾','军阀','大烟','典当','外甥','银元','欺负','回家',
'一看','祖父']jieba.analyse.extract_tags(gcd1_chap.txt[3], withWeight = True, topK=10) # 要求返回权重值
[('燕子', 0.11287212259623317),
('人熊', 0.08217464601938411),
('胖子', 0.08007877727840527),
('栗子', 0.05255360038559252),
('田晓萌', 0.051731342654467966),
('我们', 0.04289266606586197),
('猎枪', 0.030355338860093485),
('大树', 0.027296309722155618),
('喇嘛', 0.02617937062254605),
('树上', 0.025039129533637614)]2. Sklearn计算词频矩阵
CountVectorizer可以将文本列表转换为词频矩阵sparse matrix,且为稀疏矩阵,其中参数min_df = 5 指定筛选出至少在5篇文档中出现过的词。 words_count_mat.todense() 可将稀疏矩阵转换为标准矩阵。
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer, TfidfVectorizer
c_vectorizer = CountVectorizer(min_df = 5)
words_count_mat = c_vectorizer.fit_transform(gcd1_words_list) # 将文本列表转换为词频矩阵
words_count_mat
<33x1654 sparse matrix of type ''
with 16484 stored elements in Compressed Sparse Row format> words_count_mat.todense()
matrix([[ 0, 0, 4, ..., 0, 0, 2],
[ 0, 0, 2, ..., 0, 0, 1],
[ 3, 0, 16, ..., 0, 0, 1],
...,
[ 3, 0, 13, ..., 0, 0, 1],
[ 1, 0, 4, ..., 0, 8, 1],
[ 0, 0, 5, ..., 0, 0, 0]], dtype=int64)3. Sklearn 计算 TF-IDF 矩阵
(1) 使用TfidfTransformer: 可以将词频矩阵转换为TF-IDF矩阵
tfidf_vectorizer = TfidfTransformer()
tfidf_mat = tfidf_vectorizer.fit_transform(words_count_mat) # 将词频矩阵转换为TF-IDF矩阵
tfidf_mat
<33x1654 sparse matrix of type ''
with 16484 stored elements in Compressed Sparse Row format>
tfidf_mat.todense()
matrix([[0. , 0. , 0.09026236, ..., 0. , 0. ,
0.08517622],
[0. , 0. , 0.03498056, ..., 0. , 0. ,
0.03300946],
[0.0211808 , 0. , 0.08639816, ..., 0. , 0. ,
0.01019122],
...,
[0.03808981, 0. , 0.1262392 , ..., 0. , 0. ,
0.01832705],
[0.01730247, 0. , 0.0529336 , ..., 0. , 0.22533467,
0.02497544],
[0. , 0. , 0.04403064, ..., 0. , 0. ,
0. ]])
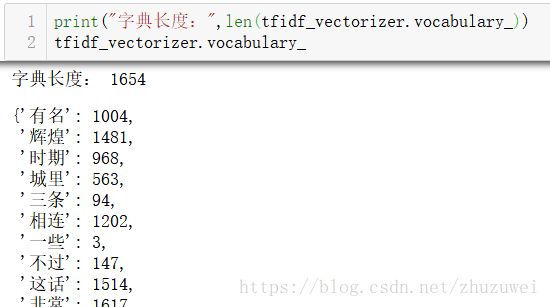
(2)使用TfidfVectorizer: 可以将文本列表直接转换为TF-IDF矩阵,相当于CountVectorizer + TfidfTransformer的效果
tfidf_vectorizer = TfidfVectorizer(min_df=5) CountVectorizer + TfidfTransformer
tfidf_mat2 = tfidf_vectorizer.fit_transform(gcd1_words_list)
tfidf_mat2
<33x1654 sparse matrix of type ''
with 16484 stored elements in Compressed Sparse Row format> tfidf_mat2.todense()
matrix([[0. , 0. , 0.09026236, ..., 0. , 0. ,
0.08517622],
[0. , 0. , 0.03498056, ..., 0. , 0. ,
0.03300946],
[0.0211808 , 0. , 0.08639816, ..., 0. , 0. ,
0.01019122],
...,
[0.03808981, 0. , 0.1262392 , ..., 0. , 0. ,
0.01832705],
[0.01730247, 0. , 0.0529336 , ..., 0. , 0.22533467,
0.02497544],
[0. , 0. , 0.04403064, ..., 0. , 0. ,
0. ]])