转载自:Beader,主要学习内容来源:
http://beader.me/2013/12/15/auc-roc/
感谢原作者的知识普及。
转载详细内容:
AUC与ROC - 衡量分类器的好坏
二元分类器
二元分类器是指要输出(预测)的结果只有两种类别的模型。例如预测阳性/阴性,有病/没病,在银行信用评分模型中,也用来预测用户是否会违约,等等。
既然是一种预测模型,则实际情况一定是有些结果猜对了,有些结果猜错了。因为二元分类器的预测结果有两种类别(以下以阴/阳为例),对应其真实值,则会有以下四种情形:
1. 预测为阳性,真实值为阴性 (伪阳性)2. 预测为阴性,真实值为阳性 (伪阴性)3. 预测为阴性,真实值真的为阴性 (真阴性)4. 预测为阴性,真实值真的为阴性 (真阴性)
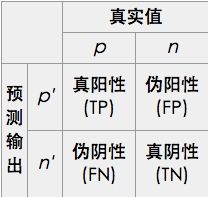
图1.confusion matrix (混乱矩阵)
ROC空间
在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种座标图式的分析工具。
要了解ROC曲线,先要了解一下ROC空间,ROC空间是一个以伪阳性率(FPR, false positive rate)为X轴,真阳性率(TPR, true positive rate)为Y轴的二维坐标系所代表平面。
TPR: 真阳性率,所有阳性样本中(TP+FN),被分类器正确判断为阳的比例。
TPR = TP / (TP + FN) = TP / 所有真实值为阳性的样本个数
FPR: 伪阳性率,所有阴性样本中(FP+TN),被分类器错误判断为阳的比例。
FPR = FP / (FP + TN) = FP / 所有真实值为阴性的样本个数
我们想象这样一种场景,接触阳性样本可以给我们带来“收益”,接触阴性样本则会给我们造成”成本”。
并且如果我们接触样本中所有的阳性样本,我们的收益是1,接触样本中的所有阴性样本,我们的成本也是1。
如果不接触样本,则既不产生收益也不产生成本。
自然的,如果不使用分类器,接触所有样本,则总的效益为1-1=0。现在让我们利用分类器来决定是否接触样本,分类器预测为阳,我们就去接触样本,分类器预测为阴,我们就不去接触。因为不接触样本不会产生收益或是成本,因此我们只需要看分类器预测为阳的样本。预测为阳的样本中,TP将产生 TPR 的收益, FP将产生FPR的成本。
那么一个分类器的分类效果就对应ROC空间里的一个点:
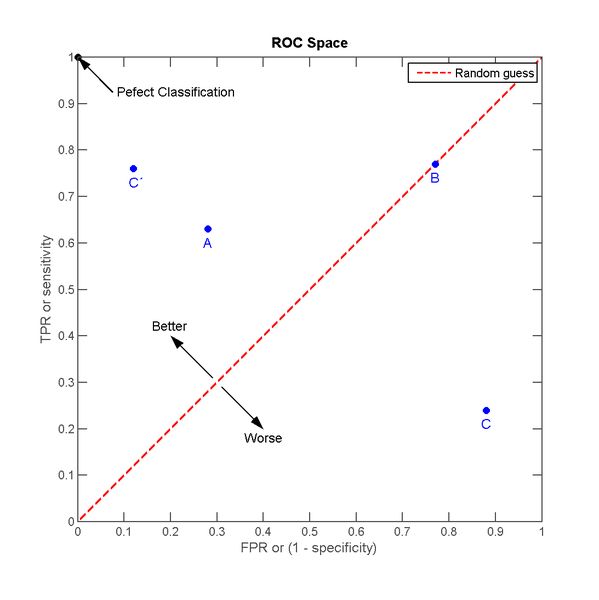
图2.ROC空间
A,B,C三个点可以分别代表三个不同的分类器对同样的样本做预测的结果。
最好的方法是A,因为他的收益大于成本(TPR > FPR),最差的是C(TPR < FPR)。中等的是B,相当于随机分类器。
这里有趣的一点是若把C以(0.5, 0.5)为中点作一个镜像,得到C’, C’的效果比A要来的好。C’相当于一个做与C预测结果完全相反的分类器。
实际的应用当中,分类器还会给出它预测某个样本为阳的概率,并且有一个事先给定的门槛值(threshold),概率高于threshold的就预测为阳性,低于threshold的就预测为阴性。假设以下是某个分类器对id为1-10的客户的分类结果:
表1.分类器预测结果
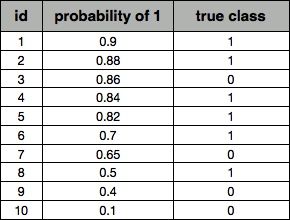
其中probability of 1为分类器判断该样本为阳性的概率,true class为该样本的真实情况。
如果我们把threshold定位0.5,即去接触id为1~8的客户。此时
TPR= TP / 所有真实值为阳性的样本个数 =6/6=1FPR= FP / 所有真实值为阴性的样本个数 =2/4=0.6
同理,如果我们把threshold定位0.8,即去接触id为1~5的客户。此时
TPR= TP / 所有真实值为阳性的样本个数 =4/6=0.67FPR= FP / 所有真实值为阴性的样本个数 =1/4=0.25
这两个threshold分别对应ROC空间中的两个点A、B

图3.不同的threshold对应ROC空间中不同的点
ROC曲线
上面的例子当中,共有10笔预测数据,则一共有11种threshold的设定方法,每一个threshold对应ROC空间中的一个点,把这些点连接起来,就成了ROC曲线。

图4.ROC曲线
这里因为数据量太少,所以曲线是一折一折的,数据量大的时候,看上去才像”曲线”。
AUC (Area under the Curve of ROC) 曲线下面积
以下直接搬维基百科:
因为是在1x1的方格里求面积,AUC必在0~1之间。
假设threshold以上是阳性,以下是阴性;
若随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本之机率。(即前文当中把C做一个镜像变为C’)
简单说:AUC值越大的分类器,正确率越高。
从AUC判断分类器(预测模型)优劣的标准:
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在AUC < 0.5的情况。
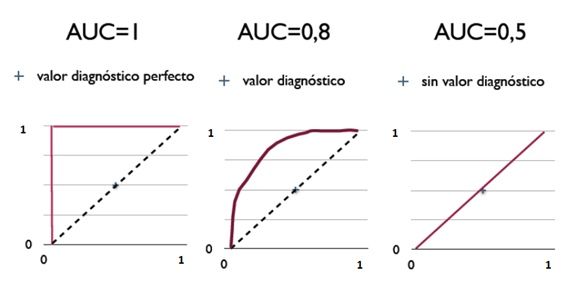
图5.用AUC来衡量不同分类器的分类能力(更准确的说是排序能力)
总结
一个分类模型的分类结果的好坏取决于以下两个部分:
分类模型的排序能力(能否把概率高的排前面,概率低的排后面)
threshold的选择
使用AUC来衡量分类模型的好坏,可以忽略由于threshold的选择所带来的影响,因为实际应用中,这个threshold常常由先验概率或是人为决定的。
补充:Gini coefficient
在用SAS或者其他一些统计分析软件,用来评测分类器分类效果时,常常会看到一个叫做gini coefficient的东西,那么这个gini coefficient又是什么呢?
gini系数通常被用来判断收入分配公平程度,具体请参阅wikipedia-基尼系数。
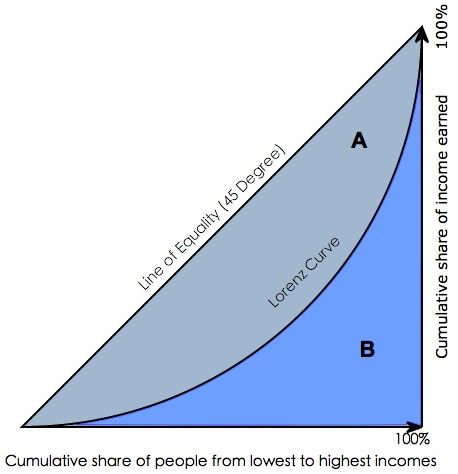
图6.洛伦茨曲线与基尼系数
Gini coefficient 是指绝对公平线(line of equality)和洛伦茨曲线(Lorenz Curve)围成的面积与绝对公平线以下面积的比例,即gini coefficient = A面积 / (A面积+B面积) 。
用在评判分类模型的预测效力时,是指ROC曲线曲线和中线围成的面积与中线之上面积的比例。

图7.Gini coefficient与AUC
因此Gini coefficient与AUC可以互相转换:
gini =A/ (A+ B) = (AUC - C) / (A+ B) = (AUC -0.5) /0.5=2*AUC -1