数据处理之缺失值处理
缺失值产生的原因:
1、有些信息暂时无法获取,或者获取信息的代价太大;
2、有些信息是被遗漏的。如认为不重要,忘记填写等人为因素,或数据采集设备故障,存储介质故障,传输媒体故障等非人为的因素;
3、属性值不存在。如未婚者的配偶姓名等。
4、对数据的缺失值处理之前,进行异常值分析。
缺失值的处理,大致分为三种情况:
1、删除法
分为两种:
(1)删除观测样本,na.omit()或data[-p,]
数据集为:
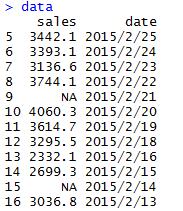
sub = which(is.na(data$sales)) #which函数返回符合条件的观测的所在位置
data1 = data[-sub,] 删除NA值所在行若删除两个变量中,任意一个变量为0的记录,可用 或运算符“|”
delet_na = datafile[-which(is.na(datafile$SUM_YR_1)|is.na(datafile$SUM_YR_2)),]若删除多个条件同时成立的记录,可用 乘号*
index= ((delet_na$SUM_YR_1 == 0 & delet_na$SUM_YR_2 == 0) * (delet_na$avg_discount != 0) * (delet_na$SEG_KM_SUM >0))
deletdata = delet_na[-which(index == 1),](2)删除变量,data[,-p]
2、替换法
分为两种:
(1)如果数值型,一般用均值替换
avg_sales = mean(data1$sales) #求出数据集未缺失部分的均值
data2 = data[sub,] #数据集缺失的部分
data2$sales = rep(avg_sales,sum(is.na(data))) #用均值进行替换,sum(is.na(data))为数据集中缺失值的个数
result2 = rbind(data1,data2) #行合并成最后的数据集(2)非数值型,一般用中位数或众数替换
3、插补法
常用的插补法有回归插补、多重插补等。
(1)回归插补利用回归模型,将需要插值补缺的变量作为因变量,其他相关变量作为自变量,通过回归函数lm()预测出因变量的值来对缺失变量进行补缺。
data$date <- as.numeric(data$date) #日期转换成数值型
model = lm(sales~date,data=data1) #回归模型拟合
data2$sales = predict(model,data2) #模型预测
result3 = rbind(data1,data2)(2)多重插补法是从一个包含缺失值的数据集中生成一组完整的数据,缺失的数据将用蒙特卡洛方法来填补。
library(mice)
imp = mice(data,m=4) #4重插补,即生成4个无缺失数据集。其中data是包含缺失值的数据集;imp是包含m个插补数据集的列表对象,m默认为5
fit = with(imp,lm(sales~date,data=data)) #fit是包含m个单独统计分析结果的列表对象
pooled = pool(fit) #pooled是包含这m个统计分析平均结果的列表对象
summary(pooled) #观察p值是否显著
result4 = complete(imp,action=3) #complete()函数观察m个插补数据集中的任意一个(3)拉格朗日插值法(Python)
import pandas as pd
from scipy.interpolate import lagrange
data = pd.read_excel('catering_sale.xls')
data[u'销量'][(data[u'销量']<400) | (data[u'销量']>5000)] = None #过滤异常值
#自定义列向量插值函数。s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s,n,k=5):
y = s[list(range(n-k,n))+list(range(n+1,n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index,list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值
data[i][j] = ployinterp_column(data[i],j)
data.to_excel('sales.xls') #输出结果写入文件