作者 刘韩 2017.3.17
也许你觉得人工智能离你还有点远,只存在于Google那巨大无比的数据中心机房,或者充满神秘感的麻省理工学院机器人实验室。其实,透过互联网和智能手机,人工智能已经开始渗入我们每天的日常生活。
假设你生活在我老家福建美丽的海滨城市厦门,早晨起来,你打开手机里的“今日头条”APP,看看今天有什么新闻,“今日头条”的人工智能推荐系统根据你过去的阅读情况,给你推荐了你特别喜欢的NBA篮球明星库里的赢球消息。上班路上,采用“百度地图”,你用语音直接说出了目的地“厦门大学”,你的手机自动识别了你略带福建口音的普通话,并为你导航了一条不那么堵车的线路。到了公司,打开邮件系统,基于人工智能的反垃圾邮件算法已经为你屏蔽了几十条垃圾邮件,默默地在帮助你提高工作效率。你利用讯飞的人工智能语音输入软件口述完成了一篇重要文件,并采用谷歌翻译软件将文件翻译成了英文和西班牙文,然后发给了你国外的客户。中午吃完午餐,你和同事到附近的公园散步,看到草坪上有一棵树开着红花,非常美丽,你想知道这种花叫什么,于是你打开手机中的“形色”APP,拍照上传,很快,人工智能图像识别算法识别出你种花学名叫“红花羊蹄甲”,又称紫荆花,花语象征着兄弟情谊……
在这些给我们带来方便和快乐的人工智能算法背后,最核心的就是目前人工智能领域最火热的“深度学习”技术。在第二章,我们讲述了人工智能在象棋和围棋领域超越人类世界冠军的故事,AlphaGo围棋软件特别强大的原因,是它的“策略网络”和“估值网络”,而这两个子系统的产生,靠的也是“深度学习”。
也许你会问,什么是“深度学习”?简单地说,“机器学习”是人工智能中很重要的一个学科,而“深度学习”是机器学习的一个分支。“机器学习”实现的是让计算机透过大量的数据或以往的经验来学习,不断优化计算机程序的性能,实现分类或预测等功能。深度学习可以让那些拥有多个处理层的神经网络计算模型来学习具有多层次抽象数据的表示,简单地说,深度学习能够发现大数据中的复杂结构。这些概念听起来有点复杂,我们在文章的后续部分会作进一步的解释。
近几年来,深度学习在图像识别、语音识别、自然语言处理、机器人、医学自动诊断、搜索引擎等方面都取得了非常惊人的成果,并且通过手机和互联网开始全面影响人类的工作和生活。本章中,让我们来一起重温“深度学习”的历史,并且探讨人工智能和深度学习的各种应用。
深度学习的概念源于“人工神经网络”的研究,早期的神经网络模型试图模仿人类神经系统和大脑的学习机理。1943年,神经生理学家Warren McCulloch和逻辑学家Walter Pitts联合发表了重要论文“神经活动中内在思想的逻辑演算”(“A logical calculus of the ideas immanent in nervous activity”), 在论文中,他们模拟人类神经元细胞结构提出了McCulloch-Pitts Neuron计算结构(参见图3-1),首次将神经元的概念引入计算领域,提出了第一个人工神经元模型,从此开启了神经网络的大门。
McCulloch-Pitts Neuron结构大致模拟了人类神经元的工作原理,就是将一些输入信号进行一些变换后得到输出结果。在图3-1中,图的下部是一个人工神经元,有N个输入信号X1,X2,……XN(对应于人类神经元的N个树突,每个树突与其它神经元连接得到信号), 每个信号对应于一个权重(对应于每个树突连接的重要性),即W11,W12,……W1N,计算这N个输入的加权和,然后经过一个阈值函数得到0或者1的输出。输出的结果,在人类神经元中,0和1可以代表神经元的压抑和激活状态,在人工神经元中,0和1可以代表逻辑上的“No”和“Yes”。
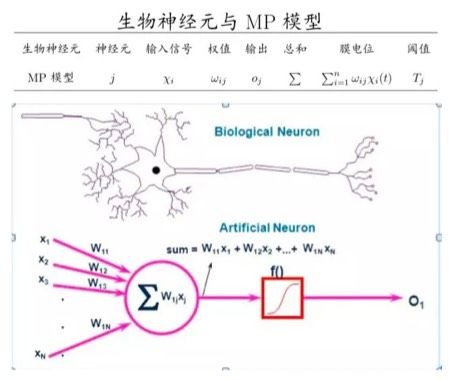
图3-1 McCulloch-Pitts Neuron计算结构
1958年,心理学家Flank Rosenblatt教授提出了感知机模型(Perceptron),感知机是基于McCulloch-Pitts Neuron计算结构的单层神经网络,是首个可以根据样例数据来学习权重特征的模型。对于线性可分为两类的数据,按照感知机的误差修正算法,可以根据样例数据经过多次迭代运算,最终实现运算收敛,确定每个输入X对应的权重W。我们把迭代运算的过程称为“神经网络的训练”,最终训练好的神经网络可以对新的数据作分类预测。这就是最简单的“机器学习”的过程。
受感知机模型的启发,60年代,有不少数学家、物理学家和计算机工程师投身于神经网络的研究。1969年时,著名的人工智能专家明斯基教授(Marvin Minsky)和Seymour Papert教授出版了《感知机:计算几何学导论》一书(《Perceptrons:An Introduction to Computational Geometry》),书中证明了感知机模型只能解决线性可分问题,明确指出了感知机无法解决异或问题等非线性可分问题。同时,书中也指出在当时的计算能力之下,实现多层的神经网络几乎是不可能的事情。明斯基教授和Seymour Papert教授对感知机研究的悲观预测,导致了神经网络研究的第一次低潮,此书出版后的十多年,基于神经网络的研究几乎处于停滞状态。
1986年,深度学习的一代宗师Geoffrey Hinton教授开始崭露头角,这一年,Hinton教授和David Rumelhart教授、Ronald Willliams教授在《自然》杂志上发表了重要论文“通过反向传播算法实现表征学习”(“Learning Representations by Back-propagating Errors”),文章中提出的反向传播算法大幅度降低了训练神经网络所需要的时间。直到30年后的今天,反向传播算法仍然是训练神经网络的基本方法。同时,Hinton教授倡导的深层神经网络,也可以很好地解决异或问题和其它的线性不可分问题。
Hinton教授出生于一个非常传奇的家族,他爷爷的外公就是伟大的数学家George Boole,布尔代数的奠基人。George Boole的太太叫Mary Everest,是一位作家,著有《代数的哲学和乐趣》。Mary的叔叔George Everest是英国著名的测绘学家和探险家,曾经担任英国殖民地印度的测量局局长,领导了整个喜马拉雅山脉的测量工作。后来英国人以他的名字命名了世界最高峰--珠穆朗玛峰,称为Mount Everest。Hinton教授全名Geoffrey Everest Hinton,当年他家人给他命名Everest时,也许已经对他未来勇攀科学高峰许下了祝福。顺便帮文艺青年八卦一下,George Boole的小女儿伏尼契(Ethel Lilian Voynich),就是中国革命者特别喜欢的一本小说《牛氓》的作者,她本人的生活和爱情也极其精彩,传说她与超级间谍Sidney Reilly(电影007中James Bond的原形人物)还有过一段浪漫的爱情,在这里我就不再赘述了。
Hinton教授1947年出生在英国,他父亲Howard Everest Hinton是昆虫学家,曾祖父Charles Howard Hinton是一个知名的数学家和最早期的科普作家和科幻小说家。从高中时代开始,Hinton就对人类大脑和神经网络的奥秘深深着迷。1970年,Hinton毕业于剑桥大学,本科拿的是实验心理学的学士学位,1978年获得爱丁堡大学的人工智能博士学位,曾经在卡耐基梅隆大学计算机系工作过5年。后来,他移居加拿大,成为多伦多大学的一位著名教授。
在Hinton教授科研生涯的前20多年,虽然取得了不少成果,但因为计算机的速度还不够快,深层神经网络的优化较为困难,基于深层神经网络的深度学习并未在学术界取得足够的重视,发表文章和获取科研经费都比较困难。Hinton教授非常坚定地默默坚持自己的研究工作,同时培养了不少优秀的学生和合作者,包括后来深度学习领域大名鼎鼎的Yann LeCun和Yoshua Bengio。
2004年,依靠来自加拿大高级研究所(CIFAR) 的资金支持,Hinton教授创立了“神经计算和自适应感知”项目,简称NCAP项目。NACP项目的目的是创建一个世界一流的团队,致力于创建生物智能的模拟——也就是模拟出大脑运用视觉、听觉和书面语言的线索来做出理解并对它的环境做出反应这一过程。Hinton教授精心挑选了研究人员,邀请了来自计算机科学、生物、电子工程、神经科学、物理学和心理学等领域的专家参与NACP项目。后来的事实证明,Hinton教授建立这样跨学科合作项目对人工智能的研究是一个伟大的创举,定期参加NCAP项目研讨会的许多研究人员,比如Yann LeCun、Yoshua Bengio和吴恩达(Andrew Ng),后来也都取得了非常突出的成果。最核心的是这一团队系统地打造了一批更高效的深度学习算法,最终,他们的显著成果推动了深度学习成为人工智能领域的主流方向。2012年,Hinton教授获得有“加拿大诺贝尔奖”之称的基廉奖(Killam Prizes),这是加拿大的国家最高科学奖。
2013年,Google公司收购了Hinton教授创立的DNN Research公司,实际上,这家公司没什么产品和客户,只有三个深度学习领域的牛人,Hinton教授和他的两个学生,曾经赢得2012年的ImageNet大赛的Alex Krizhevsky 和 Ilya Sutskever。有人调侃Google花了几千万美元买了几篇论文,我个人认为,Google公司这种大手笔引进世界最顶尖人才的方式,正好体现了Google公司两位老板Page和Brin面向未来的雄才大略,非常值得中国的企业家学习。2014年,Google花4亿美元收购DeepMind公司时,DeepMind公司也就是刚刚在《自然》杂志发表了一篇利用强化学习算法玩计算机游戏论文的小公司,很多人都不理解为什么这家公司值这么多钱。后来DeepMind发表了震惊世界的AlphaGo之后,人们才开始相信Page和Brin的远见。
说完Hinton教授,我们来聊聊深度学习领域的另一位名人,曾经跟随Hinton教授作过博士后研究的Yann LeCun。1960年,LeCun出生在法国巴黎附近,父亲是航空工程师。1988年开始,LeCun在著名的贝尔实验室工作了20年。Yann LeCun目前是纽约大学终身教授,同时是Facebook的人工智能实验室负责人。LeCun教授对人工智能领域的最核心贡献是发展和推广了卷积神经网络(Convolutional Neural Networks,简称CNN),卷积神经网络是深度学习中实现图像识别和语言识别的关键技术。和Hinton教授一样,LeCun教授也是在人工智能和神经网络的低潮时期,长期坚持科研并最终取得成功的典范。正如Hinton教授所说:“是LeCun高举着火炬,冲过了最黑暗的时代。”
卷积神经网络(CNN)是受生物自然视觉认知机制启发而来,60年代初,Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念。受此启发,1980年 Kunihiko Fukushima 提出了卷积神经网络的前身Neocognitron 。80年代,LeCun发展并完善了卷积神经网络的理论,1989年,LeCun发表了一篇著名的论文“反向传播算法用于手写邮政编码的识别”(Backpropagation Applied to Handwritten Zip Code Recognition),1998年,他设计了一个被称为LeNet-5的系统,一个七层的神经网络,这是第一个成功应用于数字识别问题的卷积神经网络。在国际通用的MNIST手写体数字识别数据集上,LeNet-5可以达到接近99.2%的正确率。这一系统后来被美国的银行广泛用于支票上数字的识别。
Yann LeCun是一位成果丰硕的计算机科学大师,不过我最佩服的还是他的业余爱好--制造飞机!在一次IEEE组织的深度对谈中,他和C++之父Bjarne Stroustrup有一个有趣的对话。Bjarne Stroustrup问:“你曾经做过一些非常酷的玩意儿,其中大多数能够飞起来。你现在是不是还有时间摆弄它们,还是这些乐趣已经被你的工作压榨光了?”LeCun回答:“工作里也有非常多乐趣,但有时我需要亲手创造些东西。这种习惯遗传于我的父亲,他是一位航空工程师,我的父亲和哥哥也热衷于飞机制造。因此当我去法国度假的时候,我们就会在长达三周的时间里沉浸于制造飞机。”
卷积神经网络通过局部感受野和权值共享的方式极大减少了神经网络需要训练的参数的个数,因此非常适合用于构建可扩展的深度网络,用于图像、语音、视频等复杂信号的模式识别。给你一个规模上的概念,目前用来作图像识别的某个比较典型的卷积神经网络,深度可达30层, 有着2400万个节点,1亿4千万个参数, 和150亿个连接。连接个数多于远远参数个数的原因就是权值共享,也就是很多连接使用相同的参数。 训练这么庞大的模型,必然要依靠大量最先进的CPU和GPU(图形处理器),并提供海量的训练数据。
谈到GPU和海量的训练数据,可以说说我们华人的贡献。目前多数深度学习系统,都采用NVIDIA公司的GPU通过大规模并行计算实现训练的加速,而NVIDIA公司的联合创始人和CEO,是来自台湾的黄仁勋(Jen-Hsun Huang)。据黄仁勋的介绍,2011 年,是人工智能领域的研究人员发现了 NVIDIA GPU的强大并行运算能力。当时谷歌大脑 (Google Brain) 项目刚刚取得了惊人的成果,谷歌大脑的深层神经网络系统通过观看一周的YouTube视频,自主学会了识别哪些是关于猫的视频。但是它需要使用谷歌一家大型数据中心内的 16,000 颗服务器 CPU。这些 CPU 的运行和散热能耗巨大,很少有人能拥有这种规模的计算资源。NVIDIA 及其 GPU 出现在人们的视野中。NVIDIA 研究院的 Bryan Catanzaro 与斯坦福大学吴恩达教授的团队展开合作,将 GPU 应用于这个项目的深度学习。事实表明,12 颗 NVIDIA GPU 可以提供相当于 2,000 颗 CPU 的深度学习性能。此后,纽约大学、多伦多大学以及瑞士人工智能实验室的研究人员纷纷在 GPU 上加速其深度神经网络。再接下来,全世界的人工智能研究者都开始使用GPU,NVIDIA公司从此开始了又一轮的高速成长。
在海量训练数据方面,1976年出生于北京的李飞飞教授功不可没。16岁时,李飞飞随父母移居美国,现在是斯坦福大学终身教授,人工智能实验室与视觉实验室主任。2007年,李飞飞与普林斯顿大学的李凯教授合作, 发起了ImageNet(图片网络)计划。利用互联网,ImageNet项目组下载了接近10亿张图片,并利用像亚马逊网站的土耳其机器人(Amazon Mechanical Turk)这样的众包平台来标记这些图片。 在高峰期时,ImageNet项目组是「亚马逊土耳其机器人」这个平台上最大的雇主之一,来自世界上167个国家的接近5万个工作者在一起工作,帮助项目组筛选、排序、标记了接近10亿张备选照片。 在2009年,ImageNet项目诞生了—— 这是一个含有1500万张照片的数据库, 涵盖了22000种物品。这些物品是根据日常英语单词进行分类组织的,对应于大型英语知识图库WordNet的22000个同义词集。 无论是在质量上还是数量上,ImageNet都是一个规模空前的数据库,同时,它被公布为互联网上的免费资源,全世界的研究人员都可以免费使用。 ImageNet这个项目,充分体现了人类通过互联网上实现全球合作产生的巨大力量。
随着机器学习算法的不断优化,并得到了GPU并行计算能力和海量训练数据的支持,原来深层神经网络训练方面的困难逐步得到解决,“深度学习”的发展迎来了新的高潮。在2012年ImageNet举办的图像分类竞赛中,由Hinton教授的学生Alex Krizhevsky教授实现的深度学习系统AlexNet获得了冠军,分类的Top5错误率,由原来的26%大幅降低到16%。 从此以后,深度学习(Deep Learning) 在性能上超越了机器学习领域的其它很多算法,应用领域也从最初的图像识别扩展到机器学习的各个领域,开启了人工智能的新浪潮。
接下来我们举几个例子,来看看深度学习的在各个领域的应用情况。首先来看计算机视觉领域,这方面较早实用化的是光学字符识别(Optical Character Recognition,OCR)。所谓光学字符识别,就是将计算机无法理解的图片文件中的字符,比如数字、字母、汉字等,转化为计算机可以理解的文本格式。谷歌公司2004年发起了谷歌图书项目(http://books.google.com),通过与哈佛大学、牛津大学、斯坦福大学等大学图书馆的合作,目前已经扫描识别了几千万本书籍,并可以实现全文检索,对没有版权问题的书籍,还提供PDF格式的文件下载。当我在谷歌图书中,打开哈佛大学图书馆珍藏的线装古本王阳明的《传习录》,还有惠能的《六祖坛经》,心里真是非常的感动,谷歌相当于把全世界的图书馆都搬到了每个人的电脑上,真是功德无量。
计算机视觉另外两个热门的应用领域就是无人驾驶车和人脸识别。2010年,7辆车组成的Google无人驾驶汽车车队开始在加州道路上试行,这些车辆使用摄像机、雷达感应器和激光测距机来“看”交通状况,并且使用详细地图来为前方的道路导航,真正控制车辆的是基于深度学习的人工智能驾驶系统。2012年5月8日,在美国内华达州允许无人驾驶汽车上路3个月,经过了几十万公里的测试之后,机动车驾驶管理处为Google的无人驾驶汽车颁发了一张合法车牌。2014年,Facebook研发了DeepFace,这个深度学习系统可以识别或者核实照片中的人物,在全球权威的人脸识别评测数据集LFW中,人脸识别准确率达97.25%。
在不远的将来,十年以内,肯定会有很多无人驾驶车开始上路行驶。到那时,除了马路上那些固定的摄像头,又会多出无人车上成千上万的移动摄像头,配合基于深度学习的人脸识别技术和高速的通讯网络,保护社会安全、抓捕罪犯的工作也许会得到很多的方便,同时,所有人的隐私也受到极大的威胁,只能祈祷人工智能的强大力量被善用了。
随着深度学习的快速发展,人工智能科学家近年来在语音识别、自然语言处理、机器翻译、语音合成这些与人类语言交流相关的领域都实现了巨大的技术突破。2012年,在微软亚洲研究院的二十一世纪计算大会上,微软高级副总裁Richard Rashid现场演示了微软开发的从英语到汉语的同声传译系统,这次演讲得到了全世界的广泛关注,YouTube有超过1百万次的播放量。同声传译系统,结合了语音识别、机器翻译和语音合成的最新技术,并且要求在很短的时间内高效完成。微软的同声传译系统,已经被应用到Skype网络电话中,支持世界各地持不同语言的人们改善交流。苹果公司的Siri、谷歌公司的Google Now这些智能手机上的语音助手已经打入了很多人的日常生活,而亚马逊公司基于Alexa语音交互系统的Echo智能音箱更加厉害,可以直接实现语音购物和语音支付,并且每天回答你包裹运到什么地方,还能播放你喜欢的音乐、设置闹钟、叫外卖、叫Uber出租车,与智能开关、智能灯具连接后,可以把你的整个家庭变成全声控的智能家居。
当然,目前这些人工智能系统还都处于比较初级的阶段,有时Siri或者Echo这些系统的回答会让你啼笑皆非,我也经常听到朋友逗这些语音助手取乐的故事。期待未来有更多的杰出人士投身这一领域,做出更智能更通人性的系统。如果你有家有个天才少年,我特别推荐一本深度学习方面的经典著作,由Ian Goodfellow、Yoshua Bengio、Aaron Courville三位大师合作推出的《Deep Learning》,这本书的作者非常无私,将这本书的内容和相关资料都放在互联网上让大家免费学习,网址是http://www.deeplearningbook.org 。
最后,如果要再给你家的天才少年送上一点建议,请允许我引述深度学习领域另一位大师Yoshua Bengio的一个对话。2014年时,Bengio教授有一次在著名网络社区Reddit的机器学习板块参加了“Ask Me AnyThing”活动,回答了机器学习爱好者许多问题。
有一个学生问:“我正在写本科论文,关于科学和逻辑的哲学方面。未来我想转到计算机系读硕士,然后攻读机器学习博士学位。除了恶补数学和编程以外,您觉得像我这样的人还需要做些什么来吸引教授的目光呢?”
Bengio教授回答:
“1.阅读深度学习论文和教程,从介绍性的文字开始,逐渐提高难度。记录阅读心得,定期总结所学知识。
2.把学到的算法自己实现一下,从零开始,保证你理解了其中的数学。别光照着论文里看到的伪代码复制一遍,实现一些变种。
3.用真实数据来测试这些算法,可以参加Kaggle竞赛。通过接触数据,你能学到很多。
4.把你整个过程中的心得和结果写在博客上,跟领域内的专家联系,问问他们是否愿意接收你在他们的项目上远程合作,或者找一个实习。
5.找个深度学习实验室,申请。
这就是我建议的路线图,不知道是否足够清楚?”
献上我的祝福,并期待在未来的某一天,可以和你家的天才少年,或者和他/她开发的超级智能机器人相遇。