文本分类 LDA算法 学习笔记
文章目录
- 学习笔记
- 1.安装Anaconda
- 2.配置python2.7环境
- 3.例子:如何用Python提取中文关键字
- 4.例子:如何用Python做中文分词
- 5.例子:如何用Python从海量文本抽取主题
- 6.例子:如何用Python和gensim调用中文词嵌入预训练模型
- 写在最后
学习笔记
1.安装Anaconda
Anaconda是一个方便的python包管理和环境管理软件,一般用来不同的项目配置。
Anaconda详细安装及使用教程(带图文)
https://blog.csdn.net/ITLearnHall/article/details/81708148
详细的安装教程参考上面的博客,参考到配置环境变量就行,需要注意几点的是:
- 下载Anaconda的版本为Python2版本的
- 出现’conda’ 不是内部或外部命令,也不是可运行的程序 或批处理文件。是环境变量配置有问题
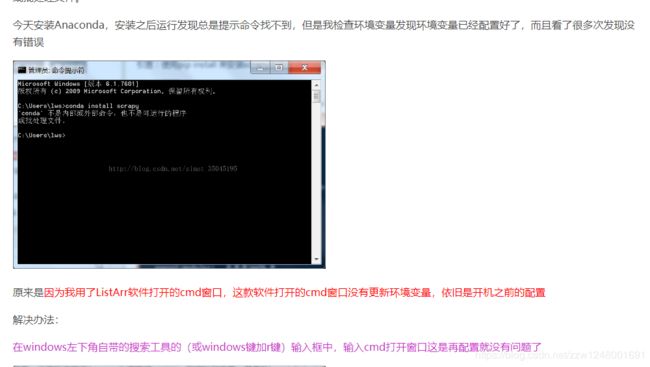
2.配置python2.7环境
打开命令行(Cmd)
active
active 是激活Anaconda默认的base环境
conda create -n python27 python=2.7
创建python2.7的环境
activate python27
激活刚刚创建的python2.7的环境
其他的命令可以查看上面安装Anaconda博客或者自行百度
可以在自己的电脑上个人中心-WorkSpace创建一个Jupyter的工作空间,把之后的工程文件夹都放在这里面
3.例子:如何用Python提取中文关键字
如何用Python提取中文关键字
https://zhuanlan.zhihu.com/p/31870596
打开命令行(Cmd)
cd C:\Users\Una\WorkSpace\Python27\demo-keyword-extraction-master
进入博客上下载的文件夹(我移动了位置)
pip install jieba
安装jieba分词
jupyter notebook
进入Jupyter笔记本环境
- 这里报错了…ImportError: DLL load failed: 找不到指定的模块。

通过浏览器进入Jupyter,打开demo-extract-keyword.ipynb,然后按照博客shift+enter运行第一句话导入结巴分词的包时就报错了

百度了半天有的说是Jupyter导包更新的慢,特地去python27环境下看了已经安装jieba分词了,最后
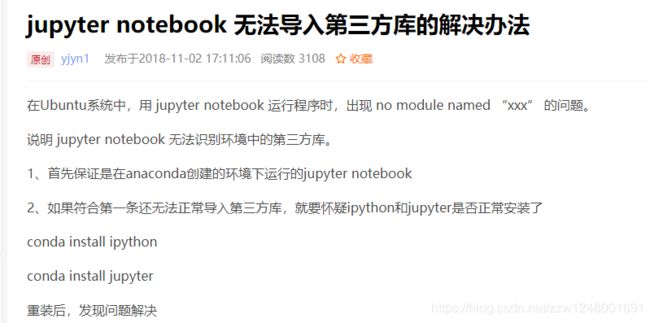
我的猜想是我打开的Jupyter是Anaconda自带的Jupyter,而在自己新建的环境Python27上还没有安装Jupyter。
打开命令行(Cmd)
activate python27
conda install jupyter
cd C:\Users\Una\WorkSpace\Jupyter\demo-nanjing
jupyter notebook
C:\Users\Una\WorkSpace\Jupyter\demo-nanjing 是我创建的工作空间

这个demo第一个就是让你熟悉一下你安装的环境和python
第二个就是让你熟悉分词 这个好好看这个demo的博客
4.例子:如何用Python做中文分词
如何用Python做中文分词
https://www.jianshu.com/p/721190534061
在Jupyter上new一个python2文件,重命名为wordcloud-cn
新打开一个终端(Cmd)
activate python27
cd C:\Users\Una\WorkSpace\Jupyter\demo-nanjing
pip install wordcloud
以后都可以开着两个终端,一个用来Jupyter的运行,一个用来包的安装

5.例子:如何用Python从海量文本抽取主题
如何用Python从海量文本抽取主题
https://zhuanlan.zhihu.com/p/28992175
在Jupyter上new一个python2文件,重命名为topic-model
pip install pyldavis
pip install sklearn
import pandas as pd
df = pd.read_csv("datascience.csv", encoding='gb18030')
import jieba
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
df["content_cutted"] = df.content.apply(chinese_word_cut)
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
n_features = 1000
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words='english',
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(df.content_cutted)
from sklearn.decomposition import LatentDirichletAllocation
n_components = 5
lda = LatentDirichletAllocation(n_components=n_components, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
lda.fit(tf)
n_top_words = 20
tf_feature_names = tf_vectorizer.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
data = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
pyLDAvis.show(data)

6.例子:如何用Python和gensim调用中文词嵌入预训练模型
如何用Python和gensim调用中文词嵌入预训练模型
https://zhuanlan.zhihu.com/p/38089841
写在最后
由衷感谢 王树义老师
玉树芝兰