matlab批量处理excel(CSV)文件数据
今天是2019-1-29,参加完2019年美国大学生数学建模竞赛,小伙伴都回家了,就我一个人在寝室,太无聊了,就把在比赛中遇到的excel批处理,写一下思路(ps:其实我在比赛中 利用的是SQLServer数据库和matlab相结合的数据处理方法,但是一般情况下遇到的都是matlab对excel数据批处理,所以降低要求写了matlab对excel数据批处理,此思路都是小编凭感觉自己摸索出来的,如有错误欢迎指出)。
今天介绍怎么批量读取excel文件的数据,首选我把excel文件名称分为以下几种情况(全凭个人经验,比如读取图片文件,txt文件思路大同小异,希望我的思路起到抛砖引玉的效果)
1. 有规律的数值型名字
%date:2019-01-29-夜晚
%author:猪猪侠
%邮箱:[email protected]
clear %清除变量
clc%清屏
filename=dir('*.xlsx');%获取全部的.xlsx文件
n=length(filename);%文件数目
for i=2010:2010+n-1%也就是2010:2014
%思路:声明三维数组储存数据
%[int2str(i),'.xlsx']是为了遍历excel文件
[Num(:,:,i-2010+1),TxT(:,:,i-2010+1),Raw(:,:,i-2010+1)]=xlsread([int2str(i),'.xlsx'])
end运行结果:

2. 有规律的数值型+相同文本的名字

%date:2019-01-29-夜晚
%author:猪猪侠
%邮箱:[email protected]
clear %清除变量
clc%清屏
filename=dir('*.xlsx');%获取全部的.xlsx文件
n=length(filename);%文件数目
for i=2015:2015+n-1%也就是2015:2019
%思路:声明三维数组储存数据
%['我是',int2str(i),'.xlsx']拼凑excel名称的字符串是为了遍历excel文件
[Num(:,:,i-2015+1),TxT(:,:,i-2015+1),Raw(:,:,i-2015+1)]=xlsread(['我是',int2str(i),'.xlsx'])
end
运行结果

3. 没有规律的文本的名字
dir函数可以有调用方式为:
dir('.') 列出当前目录下所有子文件夹和文件
dir('D:\Matlab') 列出指定目录下所有子文件夹和文件
dir('*.xlsx') 列出当前目录下符合正则表达式的文件夹和文件
得到的为结构体数组每个元素都是如下形式的结构体:
name -- filename
date -- modification date
bytes -- number of bytes allocated to the file
isdir -- 1 if name is a directory and 0 if not
datenum -- modification date as a MATLAB serial date number
%date:2019-01-29-夜晚
%author:猪猪侠
%邮箱:[email protected]
clear %清除变量
clc%清屏
filename=dir('*.xlsx');%获取全部的.xlsx文件
n=length(filename);%文件数目
for i=1:n
name=filename(i).name;
[Num(:,:,i),Txt(:,:,i),dict(:,:,i)]=xlsread(['',name,''])%批量读取数据
end

源码:
链接:https://pan.baidu.com/s/1iat-mzAAEmCdK4uPR0GjXQ
提取码:yr2c

记得点赞和关注是对我最大的鼓励
实战案例1
2019-5-20今天没事突然想继续更新这篇博客
我首先介绍我在数据处理遇到的问题
1.我这里有93个.csv文件,要按照需求批量处理csv文件数据,然后批量输出excel文件,且文件名不变。
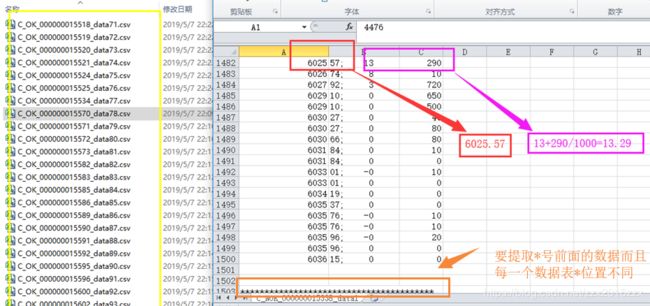
2.每个csv文件如下图所示,第一列的数据和第二列的“ ;”前的数据组成数据,第二列“ ;”后面数据和第三列数据按照要求组成数据
比如:6025和57组成6025.57,
13和290组成13+290/1000=13.29
剩下数据以此规律类推;
3.每一个数据表会有*******作为分割线,分割线前面的数据为需要按照以上方法处理的数据,分割线位置是随机变化的
难点:1.字符串拼接问题(主要涉及num2str,cell2mat,chr,str2double ,find ,isnan等函数)
2.数据文件的批量读入和输出
3. 异常处理try......catch
代码如下:
%author:猪猪侠
%E-mail:[email protected]
clear %清除变量
clc%清屏
s=what;
p=s.path; %当前目录
filename=dir([p,'\data\','*.csv']);%获取data文件夹下面全部的.csv文件
n=length(filename);%文件数目
for i=1:n
name=filename(i).name;%文件 名称遍历循环
[Num,Txt,Raw]=xlsread([p,'\data\',name]);%读取数据
index=find(isnan(Num(:,1)));
%% ---------对特殊数据表进行处理-----------------------------------------------------------------------------
try%异常出错处理
chr=cell2mat(Raw(1:index(1,1)-1,2));
catch
data1=ones(1,index(1,1)-1);%声明空间
data2=ones(1,index(1,1)-1);%声明空间
for j=1:index(1,1)-1
data1(j)=str2double([num2str(cell2mat(Raw(j,1))),'.',chr(j,1:2)]); %对第一列数据和第二列数据进行字符串拼接
data2(j)=str2double(chr(j,8:9))+str2double(num2str(cell2mat(Raw((j),3))/1000));%对第2列数据和第3列数据进行字符串拼接
end
data=[data1',data2'];%拼接后的数据
xlswrite([p,'\result\',strtok(name,'.'),'.xlsx'],data)%输出特殊数据表
end
%% ---------对符合规范的数据表进行处理-------------------------------------------------------------------------
data1=ones(1,index(1,1)-1);
data2=ones(1,index(1,1)-1);
for j=1:index(1,1)-1
data1(j)=str2double([num2str(cell2mat(Raw(j,1))),'.',chr(j,1:2)]);
data2(j)=str2double(chr(j,8:9))+str2double(num2str(cell2mat(Raw((j),3))/1000));
end
data=[data1',data2'];
xlswrite([p,'\result\',strtok(name,'.'),'.xlsx'],data)
end
数据我已经上传群里欢迎加群获取

实战案例2,
前几天在家陪老舅钓鱼,没掉几条,备受打击,所以今天不去了,2019-8-16今天没事干所以继续更新这篇博客,思路如下。
我这里有三个Excel数据文件,文件名称为无序没有规律的

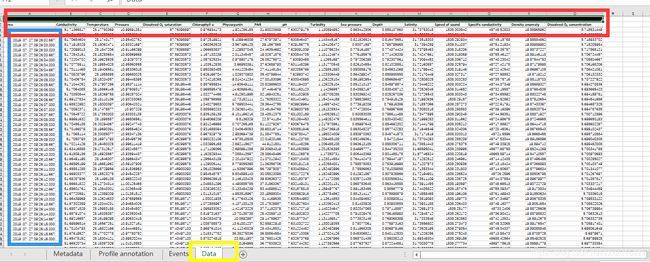
要获取三个Excel文件Data表单的全部数据,拼接在一起,然后共用一个表头,经过分析三个Data数据的列数是一样的,不一样的是行数,这样难点就是怎么动态的获取行数,然后再拼接在一起。
代码如下:
%author:zhuweijie
%email:[email protected]
%data:2019-08-15
clc,clear;
s=what;
p=s.path;%路径
filename=dir([p,'\data\','*.xlsx']);%总文件名
n=length(filename);%文件个数
for i=1:n
name=filename(i).name;%单个文件名
[Num,TxT,Raw]=xlsread([p,'\data\',name],'data');%读入数据
[row(i),col(i)]=size(Raw);%动态获取数据维度大小
Row=row-2;%去除表头
data(1,:)=Raw(2,:);%设置表头
if 1==i
data(2:sum(Row(i))+1,:)=Raw(3:end,:);%如果第一次(i=1),则从第二行开始到第一个数据维度+1
else
data(sum(Row(1:i-1))+2:sum(Row(1:i))+1,:)=Raw(3:end,:);%如果i>1,从第i-1次数据的下一行(也就是+1)开始到i+1行
end
%ps:i=1的if语句可以直接去掉也可以,为了读者方便理解,所以没有删
end
xlswrite('result.xlsx',data);%输出
代码已经上传群文件
实战案例3,
今天是2019-12-28,无聊帮研究生学姐写写代码……废话少说,要求如下
要求:
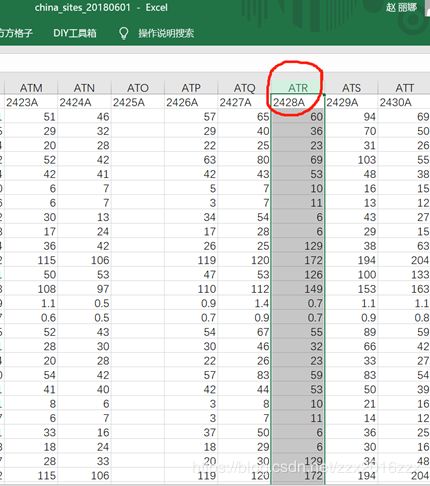
每个excel里面都是要2428A这一列,我看了几个都是ATR 这一列。
92个excel弄成92列,放在一个excel里面
感谢猪猪侠,哈哈哈
代码如下:
%author:猪猪侠
%email:[email protected]
clc;clear;
s=what;
p=s.path;
file=dir([p,'\data\','*.csv']);%拼接路径,读入all文件名
% delete([p,'\result\','data.xlsx'])
filenum=length(file);%文件数目
data=cell(361,92);
for i=1:filenum
name=file(i).name;%文件 名称遍历循环
[Num,Txt,Raw]=xlsread([p,'\data\',name],strrep(name,'.csv',''));%读取数据
data(:,i)=Raw(:,1214);
end
xlswrite([p,'\result\','data.xlsx'],data)%输出数据表完整版数据可以百度云下载
链接:https://pan.baidu.com/s/1shhVYq9DUre3Nm7rG3ZXrw
提取码:kxy9


matlab对excel数据批处理程序改进
2019-8-7今天是七夕节也是小编的生日,大清早小编在朋友圈吃饱了狗粮,总感觉要写点什么,抽空写写博客散散心。没啥心情学习,高兴的是我收到了QQ邮箱的祝福

坚持人丑多读书的宗旨继续写自己的代码,改进excel批量读入的方法,废话少说思路和代码如下
1.无规律的excel文件名批处理:
思路:dir(‘*.格式’)一股脑读入所有相同的格式,然后对filename的结构体进行操作(具体过程往上翻,excel无规律的处理有dir函数属性的详细介绍)
无论文件名咋样的,爱咋样咋样,对于所有excel进行读入,具有普适性的文件,文件如下
代码如下
%author:zhuweijie
%email:[email protected]
%date:2019-8-7-早
%对于的excel:无论文件名咋样的,爱咋样咋样,对于所有excel进行读入,具有普适性
clc,clear;
s=what;
p=s.path;%当前文件夹路径
filename=dir([p,'\','*.xlsx']);%拼接路径,读入all文件名
mydata=cell(1,length(filename));%初始文件元胞数组
for i=1:length(filename)
mydata{i}=xlsread(filename(i).name);%导入数据
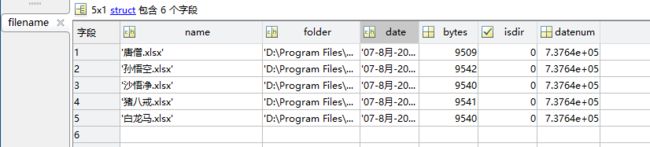
end运行效果:成功读入文件和数据

2.有规律的excel文件名批处理:
思路:1、构造文件名
2、路径和文件名字符串拼接
%author:zhuweijie
%email:[email protected]
%date:2019-8-7-早
%对于的excel:文件名+序号
clc,clear
s=what;
p=s.path;%当前文件夹路径
filename=dir([p,'\','*.xlsx']);%拼接路径,读入all文件名
filenum=length(filename);%文件数目
mydata=cell(1,filenum);%初始文件元胞数组
for k=1:filenum
filename=sprintf('data%02d.xlsx',k);
%构造文件名,注:文件名的读入也可以利用字符串拼接,循环读入
%对于data1.xlsx……data10.xlsx文件构造文件名为:sprintf('data%d.xlsx',k);
mydata{k}=xlsread(filename);%导入数据
end
运行效果:可以循环读入相应的文件名
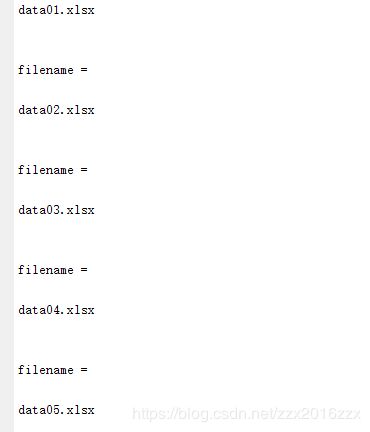
读入五个excel文件的数据
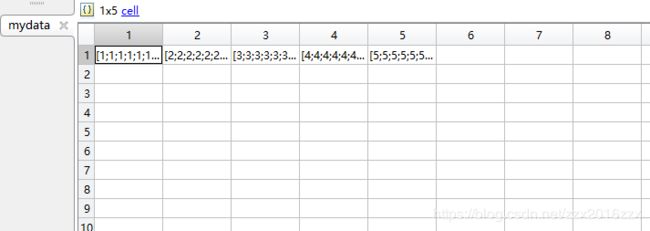
详细的文件数据和代码已经上传群里
有偿帮忙处理批量处理Excel、Txt、CSV数据 ,需要的朋友可以加我QQ:2377389590,非诚勿扰。 |

群资料