【mysql】哦买噶!多么强大的group by语句
GROUP BY 语句
- group by语句介绍
- 工具:
- 实例
- 建表 user表
- (1)基本用法
- (2)`GROUP BY`语句中的`GROUP_CONCAT`函数()
- (3)利用 `count`函数来查询性别的总人数
- (4)`where`语句
- (5) `SUM` `MAX` `MIN` `AVG` 函数
- (6)`HAVING ` 子句
- (7)`WITH ROLLUP` 子句:
- 结尾
group by语句介绍
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
工具:
sqlyog
实例
建表 user表
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) COLLATE utf8_unicode_ci DEFAULT NULL,
`number` int(11) DEFAULT NULL,
`sex` varchar(4) COLLATE utf8_unicode_ci DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci

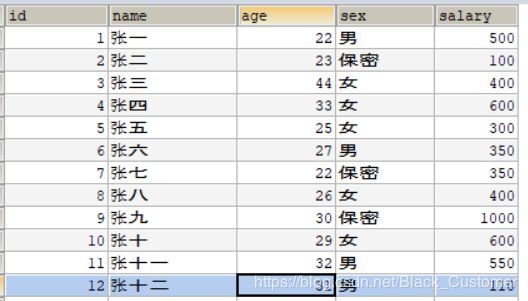
信息就不补充了~
(1)基本用法
根据性别 sex 来进行分组,查询 user 表中的姓名,年龄,性别。虽然是分组了,但只显示一个用户,其他的不显示。
SELECT NAME,age,sex FROM USER GROUP BY sex;

(2)GROUP BY语句中的GROUP_CONCAT函数()
根据 sex 字段,来查询 name字段和 age字段的详细信息。
SELECT sex ,GROUP_CONCAT(NAME), GROUP_CONCAT(age)FROM USER GROUP BY sex;

(3)利用 count函数来查询性别的总人数
根据 sex 字段来查询 name 字段的详细信息和 sex 字段性别的人数。
SELECT sex ,GROUP_CONCAT(NAME),COUNT(sex) FROM USER GROUP BY sex;

(4)where语句
根据 sex字段进行分组,用 where语句来查询年龄大于25的人数
SELECT sex ,GROUP_CONCAT(NAME),COUNT(sex) FROM USER WHERE age >25 GROUP BY sex;

(5) SUM MAX MIN AVG 函数
根据 sex 用 SUM MAX MIN AVG 函数来查询用户的总资金,最大资金,最小资金,平局资金
SELECT sex ,GROUP_CONCAT(NAME),COUNT(sex),SUM(salary),MAX(salary),MIN(salary),AVG(salary) FROM USER GROUP BY sex;

(6)HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
根据 sex 语句进行分组,来查询各组中资金大于1500的组
SELECT sex ,GROUP_CONCAT(NAME),COUNT(sex) FROM USER GROUP BY sex HAVING SUM(salary)>1500;

(7)WITH ROLLUP 子句:
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
SELECT sex ,GROUP_CONCAT(NAME),COUNT(sex),SUM(salary),MAX(salary),MIN(salary),AVG(salary) FROM USER GROUP BY sex WITH ROLLUP;

结尾
从中发现 GROUP BY 函数还是十分强大的,使得分组查找效率更高!
