一次搞定各种数据库SQL执行计划

作者 | 董旭阳TonyDong
出品 | CSDN 博客
执行计划(execution plan,也叫查询计划或者解释计划)是数据库执行 SQL 语句的具体步骤,例如通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。如果 SQL 语句性能不够理想,我们首先应该查看它的执行计划。本文主要介绍如何在各种数据库中获取和理解执行计划,并给出进一步深入分析的参考文档。
现在许多管理和开发工具都提供了查看图形化执行计划的功能,例如 MySQL Workbench、Oracle SQL Developer、SQL Server Management Studio、DBeaver 等;不过我们不打算使用这类工具,而是介绍利用数据库提供的命令查看执行计划。
我们先给出在各种数据库中查看执行计划的一个简单汇总:
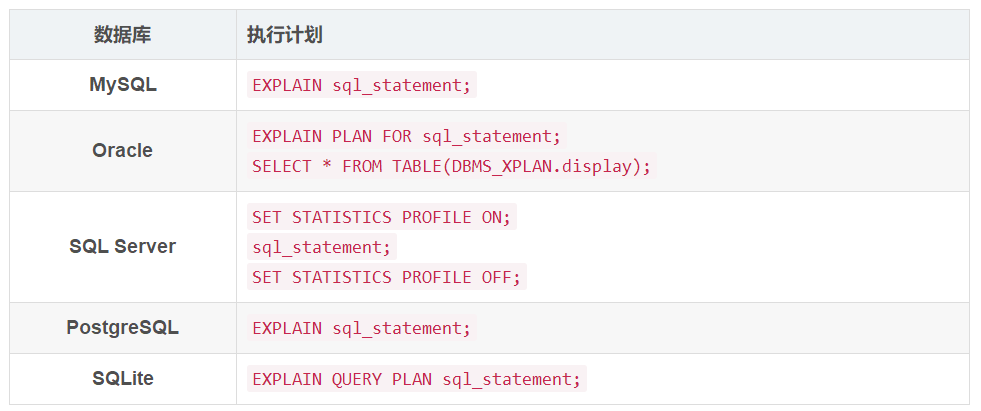
本文使用的示例表和数据可以点击链接《SQL 入门教程》示例数据库(https://tonydong.blog.csdn.net/article/details/86518676)。
MySQL 执行计划
MySQL 中获取执行计划的方法很简单,就是在 SQL 语句的前面加上EXPLAIN关键字:
EXPLAIN
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;执行该语句将会返回一个表格形式的执行计划,包含了 12 列信息:
id|select_type|table|partitions|type |possible_keys |key |key_len|ref |rows|filtered|Extra |
--|-----------|-----|----------|------|-----------------|-------|-------|--------------------|----|--------|-----------|
1|SIMPLE |e | |ALL |emp_department_ix| | | | 107| 33.33|Using where|
1|SIMPLE |d | |eq_ref|PRIMARY |PRIMARY|4 |hrdb.e.department_id| 1| 100| |MySQL 中的EXPLAIN支持 SELECT、DELETE、INSERT、REPLACE 以及 UPDATE 语句。
接下来,我们要做的就是理解执行计划中这些字段的含义。下表列出了 MySQL 执行计划中的各个字段的作用:
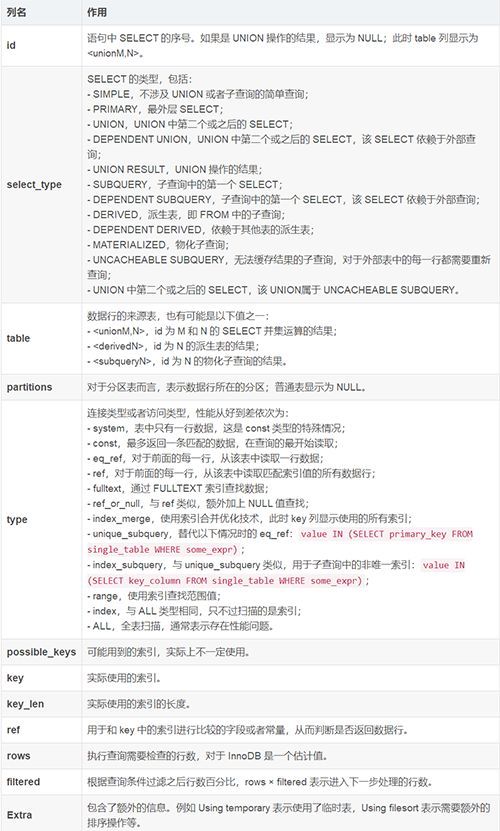
对于上面的示例,只有一个 SELECT 子句,id 都为 1;首先对 employees 表执行全表扫描(type = ALL),处理了 107 行数据,使用 WHERE 条件过滤后预计剩下 33.33% 的数据(估计不准确);然后针对这些数据,依次使用 departments 表的主键(key = PRIMARY)查找一行匹配的数据(type = eq_ref、rows = 1)。
使用 MySQL 8.0 新增的 ANALYZE 选项可以显示实际执行时间等额外的信息:
EXPLAIN ANALYZE
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;
-> Nested loop inner join (cost=23.43 rows=36) (actual time=0.325..1.287 rows=3 loops=1)
-> Filter: ((e.salary > 15000.00) and (e.department_id is not null)) (cost=10.95 rows=36) (actual time=0.281..1.194 rows=3 loops=1)
-> Table scan on e (cost=10.95 rows=107) (actual time=0.266..0.716 rows=107 loops=1)
-> Single-row index lookup on d using PRIMARY (department_id=e.department_id) (cost=0.25 rows=1) (actual time=0.013..0.015 rows=1 loops=3)其中,Nested loop inner join 表示使用嵌套循环连接的方式连接两个表,employees 为驱动表。cost 表示估算的代价,rows 表示估计返回的行数;actual time 显示了返回第一行和所有数据行花费的实际时间,后面的 rows 表示迭代器返回的行数,loops 表示迭代器循环的次数。
关于 MySQL EXPLAIN 命令的使用和参数,可以参考 MySQL 官方文档 EXPLAIN 语句(https://dev.mysql.com/doc/refman/8.0/en/explain.html)。
关于 MySQL 执行计划的输出信息,可以参考 MySQL 官方文档理解查询执行计划(https://dev.mysql.com/doc/refman/8.0/en/execution-plan-information.html)。
Oracle 执行计划
Oracle 中提供了多种查看执行计划的方法,本文使用以下方式:
使用EXPLAIN PLAN FOR命令生成并保存执行计划;
显示保存的执行计划。
首先,生成执行计划:
EXPLAIN PLAN FOR
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;EXPLAIN PLAN FOR命令不会运行 SQL 语句,因此创建的执行计划不一定与执行该语句时的实际计划相同。
该命令会将生成的执行计划保存到全局的临时表 PLAN_TABLE 中,然后使用系统包 DBMS_XPLAN 中的存储过程格式化显示该表中的执行计划。以下语句可以查看当前会话中的最后一个执行计划:
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
--------------------------------------------------------------------------------------------|
Plan hash value: 1343509718 |
|
--------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
--------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 44 | 1672 | 6 (17)| 00:00:01 ||
| 1 | MERGE JOIN | | 44 | 1672 | 6 (17)| 00:00:01 ||
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 ||
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 | | 1 (0)| 00:00:01 ||
|* 4 | SORT JOIN | | 44 | 968 | 4 (25)| 00:00:01 ||
|* 5 | TABLE ACCESS FULL | EMPLOYEES | 44 | 968 | 3 (0)| 00:00:01 ||
--------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID") |
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID") |
5 - filter("E"."SALARY">15000) |Oracle 中的EXPLAIN PLAN FOR支持 SELECT、UPDATE、INSERT 以及 DELETE 语句。
接下来,我们同样需要理解执行计划中各种信息的含义:
Plan hash value 是该语句的哈希值。SQL 语句和执行计划会存储在库缓存中,哈希值相同的语句可以重用已有的执行计划,也就是软解析;
Id 是一个序号,但不代表执行的顺序。执行的顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。Id 前面的星号表示使用了谓词判断,参考下面的 Predicate Information;
Operation 表示当前的操作,也就是如何访问表的数据、如何实现表的连接、如何进行排序操作等;
Name 显示了访问的表名、索引名或者子查询等,前提是当前操作涉及到了这些对象;
Rows 是 Oracle 估计的当前操作返回的行数,也叫基数(Cardinality);
Bytes 是 Oracle 估计的当前操作涉及的数据量
Cost (%CPU) 是 Oracle 计算执行该操作所需的代价;
Time 是 Oracle 估计执行该操作所需的时间;
Predicate Information 显示与 Id 相关的谓词信息。access 是访问条件,影响到数据的访问方式(扫描表还是通过索引);filter 是过滤条件,获取数据后根据该条件进行过滤。
在上面的示例中,Id 的执行顺序依次为 3 -> 2 -> 5 -> 4- >1。首先,Id = 3 扫描主键索引 DEPT_ID_PK,Id = 2 按主键 ROWID 访问表 DEPARTMENTS,结果已经排序;其次,Id = 5 全表扫描访问 EMPLOYEES 并且利用 filter 过滤数据,Id = 4 基于部门编号进行排序和过滤;最后 Id = 1 执行合并连接。显然,此处 Oracle 选择了排序合并连接的方式实现两个表的连接。
关于 Oracle 执行计划和 SQL 调优,可以参考 Oracle 官方文档《SQL Tuning Guide》(https://docs.oracle.com/en/database/oracle/oracle-database/19/tgsql/)。
SQL Server 执行计划
SQL Server Management Studio 提供了查看图形化执行计划的简单方法,这里我们介绍一种通过命令查看的方法:
SET STATISTICS PROFILE ON以上命令可以打开 SQL Server 语句的分析功能,打开之后执行的语句会额外返回相应的执行计划:
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;
first_name|last_name|salary |department_name|
----------|---------|--------|---------------|
Steven |King |24000.00|Executive |
Neena |Kochhar |17000.00|Executive |
Lex |De Haan |17000.00|Executive |
Rows|Executes|StmtText |StmtId|NodeId|Parent|PhysicalOp |LogicalOp |Argument |DefinedValues |EstimateRows|EstimateIO |EstimateCPU|AvgRowSize|TotalSubtreeCost|OutputList |Warnings|Type |Parallel|EstimateExecutions|
----|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|------|------|--------------------|--------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------|------------|------------|-----------|----------|----------------|----------------------------------------------------------------------|--------|--------|--------|------------------|
3| 1|SELECT e.first_name,e.last_name,e.salary,d.department_name¶ FROM employees e¶ JOIN departments d ON (e.department_id = d.department_id)¶ WHERE e.salary > 15000 | 1| 1| 0| | | | | 2.9719627| | | | 0.007803641| | |SELECT | 0| |
3| 1| |--Nested Loops(Inner Join, OUTER REFERENCES:([e].[department_id])) | 1| 2| 1|Nested Loops |Inner Join |OUTER REFERENCES:([e].[department_id]) | | 2.9719627| 0| 0| 57| 0.007803641|[e].[first_name], [e].[last_name], [e].[salary], [d].[department_name]| |PLAN_ROW| 0| 1|
3| 1| |--Clustered Index Scan(OBJECT:([hrdb].[dbo].[employees].[emp_emp_id_pk] AS [e]), WHERE:([hrdb].[dbo].[employees].[salary] as [e].[salary]>(15000.00))) | 1| 3| 2|Clustered Index Scan|Clustered Index Scan|OBJECT:([hrdb].[dbo].[employees].[emp_emp_id_pk] AS [e]), WHERE:([hrdb].[dbo].[employees].[salary] as [e].[salary]>(15000.00)) |[e].[first_name], [e].[last_name], [e].[salary], [e].[department_id]| 3|0.0038657407| 2.747E-4| 44| 0.004140441|[e].[first_name], [e].[last_name], [e].[salary], [e].[department_id] | |PLAN_ROW| 0| 1|
3| 3| |--Clustered Index Seek(OBJECT:([hrdb].[dbo].[departments].[dept_id_pk] AS [d]), SEEK:([d].[department_id]=[hrdb].[dbo].[employees].[department_id] as [e].[department_id]) ORDERED FORWARD)| 1| 4| 2|Clustered Index Seek|Clustered Index Seek|OBJECT:([hrdb].[dbo].[departments].[dept_id_pk] AS [d]), SEEK:([d].[department_id]=[hrdb].[dbo].[employees].[department_id] as [e].[department_id]) ORDERED FORWARD|[d].[department_name] | 1| 0.003125| 1.581E-4| 26| 0.0035993|[d].[department_name] | |PLAN_ROW| 0| 3|SQL Server 中的执行计划支持 SELECT、INSERT、UPDATE、DELETE 以及 EXECUTE 语句。
SQL Server 执行计划各个步骤的执行顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。接下来,我们需要理解执行计划中各种信息的含义:
Rows 表示该步骤实际产生的记录数;
Executes 表示该步骤实际被执行的次数;
StmtText 包含了每个步骤的具体描述,也就是如何访问和过滤表的数据、如何实现表的连接、如何进行排序操作等;
StmtId,该语句的编号;
NodeId,当前操作步骤的节点号,不代表执行顺序;
Parent,当前操作步骤的父节点,先执行子节点,再执行父节点;
PhysicalOp,物理操作,例如连接操作的嵌套循环实现;
LogicalOp,逻辑操作,例如内连接操作;
Argument,操作使用的参数;
DefinedValues,定义的变量值;
EstimateRows,估计返回的行数;
EstimateIO,估计的 IO 成本;
EstimateCPU,估计的 CPU 成本;
AvgRowSize,平均返回的行大小;
TotalSubtreeCost,当前节点累计的成本;
OutputList,当前节点输出的字段列表;
Warnings,预估得到的警告信息;
Type,当前操作步骤的类型;
Parallel,是否并行执行;
EstimateExecutions,该步骤预计被执行的次数;
对于上面的语句,节点执行的顺序为 3 -> 4 -> 2 -> 1。首先执行第 3 行,通过聚集索引(主键)扫描 employees 表加过滤的方式返回了 3 行数据,估计的行数(3.0841121673583984)与此非常接近;然后执行第 4 行,循环使用聚集索引的方式查找 departments 表,循环 3 次每次返回 1 行数据;第 2 行是它们的父节点,表示使用 Nested Loops 方式实现 Inner Join,Argument 列(OUTER REFERENCES:([e].[department_id]))说明驱动表为 employees ;第 1 行代表了整个查询,不执行实际操作。
最后,可以使用以下命令关闭语句的分析功能:
SET STATISTICS PROFILE OFF关于 SQL Server 执行计划和 SQL 调优,可以参考 SQL Server 官方文档执行计划。
PostgreSQL 执行计划
PostgreSQL 中获取执行计划的方法与 MySQL 类似,也就是在 SQL 语句的前面加上EXPLAIN关键字:
EXPLAIN
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;
QUERY PLAN |
----------------------------------------------------------------------|
Hash Join (cost=3.38..4.84 rows=3 width=29) |
Hash Cond: (d.department_id = e.department_id) |
-> Seq Scan on departments d (cost=0.00..1.27 rows=27 width=15) |
-> Hash (cost=3.34..3.34 rows=3 width=22) |
-> Seq Scan on employees e (cost=0.00..3.34 rows=3 width=22)|
Filter: (salary > '15000'::numeric) |PostgreSQL 中的EXPLAIN支持 SELECT、INSERT、UPDATE、DELETE、VALUES、EXECUTE、DECLARE、CREATE TABLE AS 以及 CREATE MATERIALIZED VIEW AS 语句。
PostgreSQL 执行计划的顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。对于以上示例,首先对 employees 表执行全表扫描(Seq Scan),使用 salary > 15000 作为过滤条件;cost 分别显示了预估的返回第一行的成本(0.00)和返回所有行的成本(3.34);rows 表示预估返回的行数;width 表示预估返回行的大小(单位 Byte)。然后将扫描结果放入到内存哈希表中,两个 cost 都等于 3.34,因为是在扫描完所有数据后一次性计算并存入哈希表。接下来扫描 departments 并且根据 department_id 计算哈希值,然后和前面的哈希表进行匹配(d.department_id = e.department_id)。最上面的一行表明数据库采用的是 Hash Join 实现连接操作。
PostgreSQL 中的EXPLAIN也可以使用 ANALYZE 选项显示语句的实际运行时间和更多信息:
EXPLAIN ANALYZE
SELECT e.first_name,e.last_name,e.salary,d.department_name
FROM employees e
JOIN departments d ON (e.department_id = d.department_id)
WHERE e.salary > 15000;
QUERY PLAN |
----------------------------------------------------------------------------------------------------------------|
Hash Join (cost=3.38..4.84 rows=3 width=29) (actual time=0.347..0.382 rows=3 loops=1) |
Hash Cond: (d.department_id = e.department_id) |
-> Seq Scan on departments d (cost=0.00..1.27 rows=27 width=15) (actual time=0.020..0.037 rows=27 loops=1) |
-> Hash (cost=3.34..3.34 rows=3 width=22) (actual time=0.291..0.292 rows=3 loops=1) |
Buckets: 1024 Batches: 1 Memory Usage: 9kB |
-> Seq Scan on employees e (cost=0.00..3.34 rows=3 width=22) (actual time=0.034..0.280 rows=3 loops=1)|
Filter: (salary > '15000'::numeric) |
Rows Removed by Filter: 104 |
Planning Time: 1.053 ms |
Execution Time: 0.553 ms |EXPLAIN ANALYZE通过执行语句获得了更多的信息。其中,actual time 是每次迭代实际花费的平均时间(ms),也分为启动时间和完成时间;loops 表示迭代次数;Hash 操作还会显示桶数(Buckets)、分批数量(Batches)以及占用的内存(Memory Usage),Batches 大于 1 意味着需要使用到磁盘的临时存储;Planning Time 是生成执行计划的时间;Execution Time 是执行语句的实际时间,不包括 Planning Time。
关于 PostgreSQL 的执行计划和性能优化,可以参考 PostgreSQL 官方文档性能提示(https://www.postgresql.org/docs/12/performance-tips.html)。
SQLite 执行计划
SQLite 也提供了EXPLAIN QUERY PLAN命令,用于获取 SQL 语句的执行计划:
sqlite> EXPLAIN QUERY PLAN
...> SELECT e.first_name,e.last_name,e.salary,d.department_name
...> FROM employees e
...> JOIN departments d ON (e.department_id = d.department_id)
...> WHERE e.salary > 15000;
QUERY PLAN
|--SCAN TABLE employees AS e
`--SEARCH TABLE departments AS d USING INTEGER PRIMARY KEY (rowid=?)SQLite 中的EXPLAIN QUERY PLAN支持 SELECT、INSERT、UPDATE、DELETE 等语句。
SQLite 执行计划同样按照缩进来显示,缩进越多的越先执行,同样缩进的从上至下执行。以上示例先扫描 employees 表,然后针对该结果依次通过主键查找 departments 中的数据。SQLite 只支持一种连接实现,也就是 nested loops join。
另外,SQLite 中的简单EXPLAIN也可以用于显示执行该语句的虚拟机指令序列:
sqlite> EXPLAIN
...> SELECT e.first_name,e.last_name,e.salary,d.department_name
...> FROM employees e
...> JOIN departments d ON (e.department_id = d.department_id)
...> WHERE e.salary > 15000;
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- ------------- -- -------------
0 Init 0 15 0 00 Start at 15
1 OpenRead 0 5 0 11 00 root=5 iDb=0; employees
2 OpenRead 1 2 0 2 00 root=2 iDb=0; departments
3 Rewind 0 14 0 00
4 Column 0 7 1 00 r[1]=employees.salary
5 Le 2 13 1 (BINARY) 53 if r[1]<=r[2] goto 13
6 Column 0 10 3 00 r[3]=employees.department_id
7 SeekRowid 1 13 3 00 intkey=r[3]
8 Column 0 1 4 00 r[4]=employees.first_name
9 Column 0 2 5 00 r[5]=employees.last_name
10 Column 0 7 6 00 r[6]=employees.salary
11 Column 1 1 7 00 r[7]=departments.department_name
12 ResultRow 4 4 0 00 output=r[4..7]
13 Next 0 4 0 01
14 Halt 0 0 0 00
15 Transaction 0 0 8 0 01 usesStmtJournal=0
16 Integer 15000 2 0 00 r[2]=15000
17 Goto 0 1 0 00关于 SQLite 的执行计划和优化器相关信息,可以参考 SQLite 官方文档解释查询计划。
版权声明:本文为CSDN博主「董旭阳TonyDong」的原创文章。
想为博主点赞?
想要请教博主?
扫描下方二维码,快速获取与博主直面沟通的方式吧!

推荐阅读
☞阿里巴巴架构师:十问业务中台和我的答案
☞远程办公的33种预测
☞和疫情赛跑 30 天,湖北武汉的程序员们怎么样了?
☞“抗击”新型肺炎!阿里达摩院研发AI算法,半小时完成疑似病例基因分析
阿里腾讯华为在行动!程序员远程办公究竟用哪个视频会议好?
☞随着黑客变得越来越精明,2019年发生了有史以来最多的交易所攻击事件

用开发者的方式共克时艰!