Centos7下搭建大数据处理集群(Hadoop+Spark+Hbase+Hive+Zookeeper+Kafka+Flume)详细步骤
一.目录
左侧按钮显示
二.集群规划
准备3台虚拟机,设置IP地址和hostname,一般的三台机器的集群为了明确表示主从关系,命名master,slave1,slave2,我这边直接命名为hp1,hp2,hp3,hp1当主节点使用,集群搭建时要考虑各个组件之间的版本兼容,下列这些版本的选择也是参考了其他人资料选择的。
 为了快速方便安装,我选择了下载安装压缩包,上传解压安装,现将下载地址给出:https://mirrors.cnnic.cn/apache/
为了快速方便安装,我选择了下载安装压缩包,上传解压安装,现将下载地址给出:https://mirrors.cnnic.cn/apache/
这个地址下基本上有apache的所有开源软件的各个版本的安装包,随意下载吧!
三.虚拟机准备及基础配置设置
3.1更改主机名映射IP地址和主机名
3.1.1更改主机名
编辑/etc/hostname文件
vi /etc/hostname
将localhost更改为需要命名的主机名
3.1.2映射IP地址和主机名
编辑/etc/hosts文件
vi /etc/hosts
添加IP地址和主机名对应关系
192.168.5.142 hp1
192.168.5.143 hp2
192.168.5.144 hp3
3.2关闭防火墙
执行防火墙关闭命令,并禁止开机启动
防火墙的相关命令
停止防火墙:
service iptables stop
启动防火墙:
service iptables start
重启防火墙:
service iptables restart
永久关闭防火墙:
chkconfig iptables off
3.3设置时间同步
3.3.1设置hp1的ntp
1.安装ntp服务
yum -y install ntp #更改hp1的节点
2.设置ntp服务器
vi /etc/ntp.conf #注释掉server 0.centos.pool.ntp.org iburst,在hp1节点新添加自己的ntp服务器,在其他2个节点将ntp服务器指向master节点
*# For more information about this file, see the man pages
# ntp.conf(5), ntp_acc(5), ntp_auth(5), ntp_clock(5), ntp_misc(5), ntp_mon(5).
driftfile /var/lib/ntp/drift
# Permit time synchronization with our time source, but do not
# permit the source to query or modify the service on this system.
restrict default nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server ntp4.aliyun.com iburst
*
3.将其他2台主机的ntp服务器设置指向hp1
3.4设置主机之间的免密登录SSH
在所有节点按下列命令执行:
1.产生公钥和私钥:ssh-keygen -t rsa (一直回车直即可)
2.将公钥分发给所有节点(包括本机): ssh-copy-id -i 主机名
3.测试ssh访问: ssh root@主机名
3.5安装JDK
3.5.1卸载自带的openjdk
1.查看已安装的jdk
rpm -qa | grep java
*tzdata-java-2018e-3.el7.noarch
java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
*
2.卸载已安装的openjdk
rpm -e --nodeps 包名
3.5.2上传解压安装包
1.创建软件安装包上传目录/opt/package,Jdk安装目录/opt/java
[root@hp1 opt]# mkdir package
[root@hp1 opt]# mkdir java
2.将下载好的java安装包上传到/opt/package目录下,并解压移动到/opt/java
[root@hp1 package]# rpm -ivh jdk-8u221-linux-x64.rpm
[root@hp1 package]# mv jdk-8u221 /opt/java/jdk-1.8
3.5.3配置环境变量
1.配置环境变量
vi /etc/profile
添加以下内容
export HADOOP_HOME=/opt/hadoop/jdk-1.8
export PATH=.:${JAVA_HOME}/bin:$PATH
使配置文件生效
source /etc/profile
3.5.4查看java信息
[root@hp1 /]# java -version
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
四.Hadoop
4.1安装Hadoop
4.1.1上传解压安装包
1.创建Hadoop安装目录/opt/hadoop
[root@hp1 opt]# mkdir hadoop
2.将下载好的Hadoop安装包上传到/opt/package目录下,并解压移动到/opt/hadoop
[root@hp1 package]# tar -zxvf hadoop-2.7.7.tar.gz
[root@hp1 package]# mv hadoop-2.7.7 /opt/hadoop/
4.1.2配置环境变量
1.配置环境变量
vi /etc/profile
添加以下内容
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
注意:export PATH= 后面只是在后面添加Hadoop的{HADOOP_HOME}/bin,后面安装其他的集群组件也是一样
使配置文件生效
source /etc/profile
4.1.3更改配置文件
更改配置文件
进入/opt/hadoop/hadoop-2.7.7/etc/hadoop 这个目录修改
core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xm、slaves
cd /opt/hadoop/hadoop-2.7.7/etc/hadoop
1.修改core-site.xml
vi core-site.xml
在< configuration >后加入
# 在< configuration > 内添加以下内容
fs.default.name</name>
hdfs://hp1:9000</value>
</property>
hadoop.tmp.dir</name>
/home/hadoop/tmp</value>
</property>
io.file.buffer.size</name>
131702</value>
</property>
- fs.default.name(指定hdfs的主端口 namenode要放在哪台机器上) =》 主机名:端口号
- hadoop.tmp.dir(临时变量目录 data name secondary 如果指定了namenode datanode 可以不配)=》tmp目录
- io.file.buffer.size (流缓冲区大小 )=》131702(128M)
2.修改hadoop-env.sh
vi hadoop-env.sh
#修改 export JAVA_HOME=${JAVA_HOME}(jdk的目录)
export JAVA_HOME=/opt/java/jdk1.8
3.修改hdfs-site.xml
vi hdfs-site.xml
#在 内添加以下内容
<!-- namenode数据的存放地点。也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据-->
dfs.namenode.name.dir</name>
/opt/hadoop/hadoop-2.7.7/dfs/name</value>
</property>
<!-- datanode数据的存放地点。也就是block块存放的目录了-->
dfs.datanode.data.dir</name>
/opt/hadoop/hadoop-2.7.7/dfs/data</value>
</property>
<!-- hdfs的副本数设置。也就是上传一个文件,其分割为block块后,每个block的冗余副本个数-->
dfs.replication</name>
2</value>
</property>
<!-- secondary namenode的http通讯地址-->
dfs.secondary.http.address</name>
hp1:50090</value>
</property>
<!-- 开启hdfs的web访问接口。默认端口是50070 , 一般不配 , 使用默认值-->
dfs.webhdfs.enabled</name>
true</value>
</property>
4.修改mapred-site.xml
若无mapred-site.xml文件,复制mapred-site.xml.template重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
vi mapred-site.xml
#在 内添加以下内容
<!-- 指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 -->
mapreduce.framework.name</name>
yarn</value>
</property>
<!-- JobHistory Server ============================================================== -->
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
mapreduce.jobhistory.address</name>
hp1:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
mapreduce.jobhistory.webapp.address</name>
hp2:19888</value>
</property>
5.修改yarn-site.xml
vi yarn-site.xml
#在 内添加以下内容
yarn.resourcemanager.hostname</name>
hp1</value>
</property>
<!--yarn总管理器的IPC通讯地址-->
yarn.resourcemanager.address</name>
${yarn.resourcemanager.hostname}:8032</value>
</property>
<!--yarn总管理器调度程序的IPC通讯地址-->
yarn.resourcemanager.scheduler.address</name>
${yarn.resourcemanager.hostname}:8030</value>
</property>
<!--yarn总管理器的web http通讯地址-->
yarn.resourcemanager.webapp.address</name>
${yarn.resourcemanager.hostname}:8088</value>
</property>
The https adddress of the RM web application.</description>
yarn.resourcemanager.webapp.https.address</name>
${yarn.resourcemanager.hostname}:8090</value>
</property>
<!--yarn总管理器的IPC通讯地址-->
${yarn.resourcemanager.hostname}:8031</value>
</property>
<!--yarn总管理器的IPC管理地址-->
yarn.resourcemanager.admin.address</name>
${yarn.resourcemanager.hostname}:8033</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.scheduler.maximum-allocation-mb</name>
2048</value>
单个任务可申请最大内存,默认8192MB</discription>
</property>
<!--容器所占的虚拟内存和物理内存之比。该值指示了虚拟内存的使用可以超过所分配内存的量。默认值是2.1-->
yarn.nodemanager.vmem-pmem-ratio</name>
2.1</value>
</property>
yarn.nodemanager.resource.memory-mb</name>
2048</value>
</property>
yarn.nodemanager.vmem-check-enabled</name>
false</value>
</property>
6.修改slaves
vi slaves
默认localhost,若是单机模式则不需要改变
我们有2个从节点,所以将localhost改为从节点的地址
hp2
hp3
4.1.4将主节点(hp1)配置同步到从节点(hp2,hp3)
1.复制环境变量
scp /etc/profile root@hp2:/etc/
scp /etc/profile root@hp3:/etc/
2.复制Hadoop安装配置文件
scp -r /opt/hadoop root@hp2:/opt/
scp -r /opt/hadoop root@hp3:/opt/
4.2启动Hadoop
1.初始化Hadoop(== 注意如果在使用中修改了Hadoop的配置文件,就必须重新初始化==)
cd /opt/hadoop/hadoop-2.7.7/bin
到/opt/hadoop/hadoop-2.7.7/bin目录下执行
./hdfs namenode -format
初始化完成后
2.启动Hadoop(== 只需在主节点hp1启动从节点会自动启动的==)
切换到/opt/hadoop/hadoop-2.7.7/sbin目录
cd /opt/hadoop/hadoop-2.7.7/sbin
执行启动命令
./start-all.sh
[root@hp1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hp1]
hp1: starting namenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-root-namenode-hp1.out
hp2: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-root-datanode-hp2.out
hp3: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-root-datanode-hp3.out
Starting secondary namenodes [hp1]
hp1: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-hp1.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-root-resourcemanager-hp1.out
hp2: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-root-nodemanager-hp2.out
hp3: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-root-nodemanager-hp3.out
启动成功
执行jps命令查看各个节点启动的服务
主节点hp1
[root@hp1 sbin]# jps
25505 SecondaryNameNode
25654 ResourceManager
25304 NameNode
25950 Jps
从节点hp2,hp3
[root@hp2 hadoop]# jps
15364 NodeManager
15492 Jps
15259 DataNode
[root@hp3 hadoop]# jps
15222 DataNode
15335 NodeManager
15463 Jps
通过网页查看Hadoop启动状态是否成功
IP:50070和IP:8088

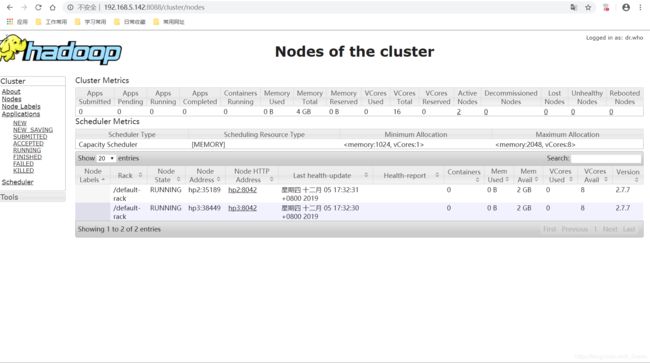
4.3停止Hadoop
执行命令关闭Hadoop
[root@hp1 sbin]# ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [hp1]
hp1: stopping namenode
hp3: stopping datanode
hp2: stopping datanode
Stopping secondary namenodes [hp1]
hp1: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
hp3: stopping nodemanager
hp2: stopping nodemanager
no proxyserver to stop
Hadoop安装成功!!!
五.Spark
5.1安装Scala
5.1.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并加压重命名到/opt/scala目录下
tar -zxvf scala-2.12.2.tgz
mv scala-2.12.2 /opt/scala/scala-2.12
5.1.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export SCALA_HOME=/opt/scala/scala-2.12
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:$PATH
使环境变量生效,并查看scala是否安装成功
[root@hp1 scala-2.12]# source /etc/profile
[root@hp1 scala-2.12]# scala -version
Scala code runner version 2.12.2 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.
Scala安装成功
5.2安装Spark
5.2.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/spark目录下
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz
mv spark-2.4.4-bin-hadoop2.7 /opt/spark/spark-2.4.4
5.2.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export SPARK_HOME=/opt/spark/spark-2.4.4
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
5.2.3更改配置文件
切换目录
cd /opt/spark/spark-2.4.4/conf
1.修改spark-env.sh
若没有spark-env.sh文件,复制spark-env.sh.template文件重命名
cp spark-env.sh.template spark-env.sh
在spark-env.sh文件中添加以下内容
export SCALA_HOME=/opt/scala/scala-2.12
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.4
export SPARK_MASTER_IP=hp1
export SPARK_EXECUTOR_MEMORY=2G
SPARK_MASTER_IP spark的主节点IP
SPARK_EXECUTOR_MEMORY spark的运行内存
上面的路径根据自己实际安装路径配置
2.修改slaves
若没有slaves文件,复制slaves.template文件重命名
cp slaves.template slaves
修改新的slaves文件
更改原来的localhost为从节点的主机名(单节点不需要修改)
hp2
hp3
5.2.4将主节点(hp1)的配置同步到从节点(hp2,hp3)
1.同步scala
scp -r /opt/scala root@hp2:/opt/
scp -r /opt/scala root@hp3:/opt/
2.同步spark
scp -r /opt/spark root@hp2:/opt/
scp -r /opt/spark root@hp3:/opt/
3.同步环境变量
scp /etc/profile root@hp2:/etc/
scp /etc/profile root@hp3:/etc/
4.使hp2,hp3的环境变量生效
source /etc/profile
5.3启动Spark
前提条件:Hadoop已启动
切换到/opt/spark/spark-2.4.4/sbin
cd /opt/spark/spark-2.4.4/sbin
执行启动命令
start-all.sh
[root@hp1 sbin]# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-hp1.out
hp3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hp3.out
hp2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hp2.out
页面查看启动结果
IP:8080查看页面

5.4停止Spark
stop-all.sh
Spark安装成功!!!
六.Zookeeper
6.1安装Zookeeper
6.1.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/zookeeper目录下
tar -zxvf zookeeper-3.4.14.tar.gz
mv zookeeper-3.4.14 /opt/zookeeper/zookeeper-3.4
6.1.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export ZOOKEEPER_HOME=/opt/zookeeper/zookeeper-3.4
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
6.1.3更改配置文件
1.在集群上创建以下目录
mkdir /opt/zookeeper/data
mkdir /opt/zookeeper/datalog
2.在/opt/zookeeper/data目录下创建文件myid,并在myid添加1
touch myid
注意:记得在主节点同步配置到从节点后修改分别修改myid的内容,hp2.myid对应 2,hp3.myid对应 3
3.修改zoo.cfg文件
在/opt/zookeeper/zookeeper-3.4/conf目录下,找到zoo.cfg,如果没有则复制zoo_sample.cfg文件并重命名
cp zoo_sample.cfg zoo.cfg
在zoo.cfg文件注释掉"dataDir=/tmp/zookeeper"并添加以下内容
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
zoo.cfg文件内容如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
server.1=hp1:2888:3888
server.2=hp2:2888:3888
server.3=hp3:2888:3888
参数解析:
- tickTime:CS通信心跳时间,单位是毫秒,系统默认是2000毫秒,客户端与服务器或者服务器与服务器之间维持心跳,也就是每个tickTime时间就会发送一次心跳。通过心跳不仅能够用来监听机器的工作状态,还可以通过心跳来控制Flower跟Leader的通信时间,默认情况下FL的会话时常是心跳间隔的两倍。
- initLimit:集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)
- syncLimit:集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数。
- clientPort:客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问!这个端口默认是2181
- dataDir:该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息等
- dataLogDir :存放运行日志的路径
- server.1=hp1:2888:3888 :配置集群信息是存在一定的格式:service.N =YYY: A:B,N:代表服务器编号(也就是myid里面的值),
YYY:服务器地址,A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888),B:表示 是选举端口(默认是3888)
6.1.4将主节点(hp1)的配置同步到从节点(hp2,hp3)
1.同步环境变量
scp /etc/profile root@hp2:/etc/profile
scp /etc/profile root@hp3:/etc/profile
使环境变量生效
source /etc/profile
2.同步配置文件
scp -r /opt/zookeeper root@hp2:/opt/
scp -r /opt/zookeeper root@hp3:/opt/
修改同步后hp2,hp3的myid文件
6.2启动Zookeeper
Zookeeper执行的是选举制度,所以需要在每台服务器都执行启动
切换到/opt/zookeeper/zookeeper-3.4/bin目录下
cd /opt/zookeeper/zookeeper-3.4/bin
执行启动命令
[root@hp1 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
在所有服务器启动成功后,查看Zookeeper的状态(只启动一个服务器的Zookeeper查看状态是未运行的)
[root@hp1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Mode: follower
[root@hp2 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Mode: leader
[root@hp3 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Mode: follower
6.3停止Zookeeper
切换到/opt/zookeeper/zookeeper-3.4/bin目录下
执行
zkServer.sh stop
[root@hp2 bin]# zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
注意:当集群中停掉leader角色的服务器Zookeeper时,会从剩余运行Zookeeper服务器中重新选举一个leader角色
Zookeeper安装成功!!!!
七.Hbase
7.1安装Hbase
7.1.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/hbase目录下
tar -zxvf hbase-2.1.7-bin.tar.gz
mv hbase-2.1.7 /opt/hbase/hbase-2.1
7.1.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export HBASE_HOME=/opt/hbase/hbase-2.1
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
7.1.3更改配置文件
切换到/opt/hbase/hbase-2.1/conf目录下
1.修改hbase-env.sh文件
添加以下内容
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HBASE_HOME=/opt/hbase/hbase-2.1
export HBASE_CLASSPATH=/opt/hadoop/hadoop-2.7.7/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false
"export HBASE_MANAGES_ZK=false"表示是否使用Hbase自带的Zookeeper,此处我们设置为false,使用我们安装的Zookeeper,其他配置根据自己实际情况设置
2.修改hbase-site.xml文件
vi hbase-site.xml
在" < configuration > < /configuration >" 中添加如下内容
hbase.rootdir</name>
hdfs://hp1:9000/hbase</value>
The directory shared byregion servers.</description>
</property>
<!-- hbase端口 -->
hbase.zookeeper.property.clientPort</name>
2181</value>
</property>
<!-- 超时时间 -->
zookeeper.session.timeout</name>
120000</value>
</property>
<!--防止服务器时间不同步出错 -->
hbase.master.maxclockskew</name>
150000</value>
</property>
<!-- 集群主机配置 -->
hbase.zookeeper.quorum</name>
hp1,hp2,hp3</value>
</property>
<!-- 路径存放 -->
hbase.tmp.dir</name>
/opt/hbase/tmp</value>
</property>
<!-- true表示分布式 -->
hbase.cluster.distributed</name>
true</value>
</property>
<!-- 指定master -->
hbase.master</name>
hp1:60000</value>
</property>
注意: hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase 。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面
3.修改regionservers
vi regionservers
将localhost更改为hp2,hp3,与hadoop的salves一样,确认主从关系
修改内容如下:
hp2
hp3
7.1.4将主节点(hp1)的配置同步到从节点(hp2,hp3)
1.同步环境变量
scp /etc/profile root@hp2:/etc/profile
scp /etc/profile root@hp3:/etc/profile
使环境变量生效
source /etc/profile
2.同步配置文件
scp -r /opt/hbase root@hp2:/opt/
scp -r /opt/hbase root@hp3:/opt/
7.2启动Hbase
在成功启动Hadoop、zookeeper之后
切换到/opt/hbase/hbase-2.1/bin
cd /opt/hbase/hbase-2.1/bin
执行启动命令
start-hbase.sh
[root@hp1 bin]# start-hbase.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
running master, logging to /opt/hbase/hbase-2.1/logs/hbase-root-master-hp1.out
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hp3: running regionserver, logging to /opt/hbase/hbase-2.1/logs/hbase-root-regionserver-hp3.out
hp2: running regionserver, logging to /opt/hbase/hbase-2.1/logs/hbase-root-regionserver-hp2.out
使用jps查看各个服务器的启动 情况
[root@hp1 bin]# jps
20480 NameNode
20832 ResourceManager
21122 QuorumPeerMain
20677 SecondaryNameNode
21400 Jps
21295 HMaster
##########################
[root@hp2 bin]# jps
18080 NodeManager
18346 HRegionServer
18268 QuorumPeerMain
17997 DataNode
18590 Jps
##########################
[root@hp3 bin]# jps
18049 NodeManager
18534 Jps
18314 HRegionServer
18236 QuorumPeerMain
17965 DataNode
通过web页面查看hbase启动情况,服务器地址+16010端口查看:

7.3停止Hbase
在/opt/hbase/hbase-2.1/bin目录下执行命令:
stop-hbase.sh
hbase安装成功!!!!!!!!!!!!
八.MySQL
8.1安装MySQL
8.1.1检查卸载自带mariadb
执行命令检查自带mariadb安装情况:
[root@hp1 /]# rpm -qa |grep mariadb
mariadb-libs-5.5.60-1.el7_5.x86_64
执行命令卸载mariadb:
rpm -e mariadb-libs-5.5.60-1.el7_5.x86_64 --nodeps
8.1.2上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/mysql目录下
tar -zxvf mysql-5.7.27-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.27-linux-glibc2.12-x86_64 /opt/mysql/mysql-5.7
8.1.3配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export MYSQL_HOME=/opt/mysql/mysql-5.7
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:${MYSQL_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
8.1.4更改配置文件
1.配置my.conf文件
在/etc目录下新建my.conf文件
vi /etc/my.conf
添加以下内容:
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
#跳过权限表校验
#skip-grant-tables
skip-name-resolve
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=/opt/mysql/mysql-5.7
# 设置mysql数据库的数据的存放目录
datadir=/opt/mysql/mysql-5.7/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
lower_case_table_names=1
max_allowed_packet=16M
2.创建数据存储目录
mysql配置文件中/opt/mysql/mysql-5.7/data目录需要手动创建
mkdir /opt/mysql/mysql-5.7/data
3.创建mysql用户,mysql用户组
[root@hp1 local]# cd /opt/mysql/mysql-5.7/
[root@hp1 mysql-5.7]# groupadd mysql
[root@hp1 mysql-5.7]# useradd -r -g mysql mysql
[root@hp1 mysql-5.7]# chown -R mysql:mysql /opt/mysql/mysql-5.7/
4.初始化mysql数据库
到/opt/mysql/mysql-5.7/bin目录下:
cd /opt/mysql/mysql-5.7/bin
执行以下命令(注意记录生成的密码):
./mysqld --initialize --user=mysql --basedir=/opt/mysql/mysql-5.7 --datadir=/opt/mysql/mysql-5.7/data

8.2启动MySQL
在/opt/mysql/mysql-5.7目录下执行以下命令:
因为不是按默认路径安装的mysql,所以必须修改/opt/mysql/mysql-5.7/support-files/mysql.server配置文件
basedir=/opt/mysql/mysql-5.7 #添加mysql的安装目录
datadir=/opt/mysql/mysql-5.7/data #添加data的目录
# Default value, in seconds, afterwhich the script should timeout waiting
# for server start.
# Value here is overriden by value in my.cnf.
# 0 means don't wait at all
# Negative numbers mean to wait indefinitely
service_startup_timeout=900
# Lock directory for RedHat / SuSE.
lockdir='/var/lock/subsys'
lock_file_path="$lockdir/mysql"
# The following variables are only set for letting mysql.server find things.
# Set some defaults
mysqld_pid_file_path=
if test -z "$basedir"
then
basedir=/usr/local/mysql
bindir=/usr/local/mysql/bin
if test -z "$datadir"
then
datadir=/usr/local/mysql/data
fi
sbindir=/usr/local/mysql/bin
libexecdir=/usr/local/mysql/bin
else
bindir="$basedir/bin"
if test -z "$datadir"
then
datadir="$basedir/data"
fi
sbindir="$basedir/sbin"
libexecdir="$basedir/libexec"
fi
复制mysql.server文件到/etc/init.d目录下,并重命名方便后面配置开机自启动
[root@hp1 mysql-5.7]# cp -a ./support-files/mysql.server /etc/init.d/mysqld
执行命令:
[root@hp1 support-files]# mysql.server start
Starting MySQL SUCCESS!
若出现报错:mysqld_safe A mysqld process already exists
执行下列命令,找到并kill掉其中的进程在执行上面的启动命令:
ps aux |grep mysqld
![]() 执行命令,进入mysql数据库:
执行命令,进入mysql数据库:
密码是上面初始化时生成的那个密码
[root@hp1 mysql]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.27
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
修改root账号的密码:
mysql> set password for 'root'@'localhost'=password('root');
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> exit;
Bye
退出后重新进入,添加数据库连接权限:
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> update user set host='%' where user='root'; #允许所有ip的主机连接mysql数据库
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; #授权远程主机允许连接mysql数据库
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges; #刷新MySQL的系统权限相关表
Query OK, 0 rows affected (0.00 sec)
8.3设置开机自启动
[root@hp1 mysql-5.7]# chkconfig --add mysqld
[root@hp1 mysql-5.7]# chkconfig mysqld on
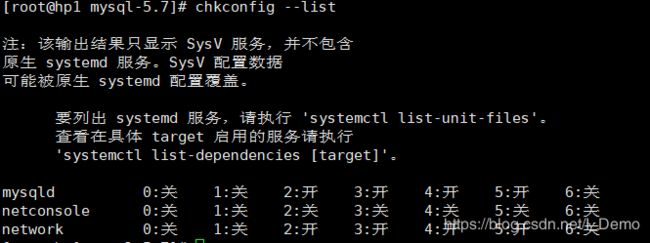 mysqld 3,4,5状态为开说明开机自启动设置成功
mysqld 3,4,5状态为开说明开机自启动设置成功
九.Hive
9.1安装Hive
9.1.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/hive目录下
tar -zxvf apache-hive-2.3.6-bin.tar.gz
mv apache-hive-2.3.6-bin /opt/hive/hive-2.3
9.1.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export HIVE_HOME=/opt/hive/hive-2.3
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:${MYSQL_HOME}/bin:${HIVE_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
9.1.3更改配置文件
1.修改hive-env.sh
若没有hive-env.sh,复制并重命名/opt/hive/hive-2.3/conf/hive-env.sh.template
cp hive-env.sh.template hive-env.sh
在hive-env.sh文件中添加以下内容:
JAVA_HOME=/opt/java/jdk1.8
HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
HIVE_HOME=/opt/hive/hive-2.3
export HIVE_CONF_DIR=$HIVE_HOME/conf
#export HIVE_AUX_JARS_PATH=$SPARK_HOME/lib/spark-assembly-1.6.0-hadoop2.6.0.jar
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$HADOOP_HOME/lib:$HIVE_HOME/lib
#export HADOOP_OPTS="-Dorg.xerial.snappy.tempdir=/tmp -Dorg.xerial.snappy.lib.name=libsnappyjava.jnilib $HADOOP_OPTS"
2.修改hive-site.xml
若没有hive-site.xml,复制并重命名hive-default.xml.template
cp hive-default.xml.template hive-site.xml
编辑hive-site.xml前,需要新建一些目录
在hdfs新建目录
[root@hp1 sbin]# hdfs dfs -mkdir -p /user/hive/warehouse
[root@hp1 sbin]# hdfs dfs -chmod -R 777 /user/hive/warehouse
[root@hp1 sbin]# hdfs dfs -mkdir -p /tmp/hive
[root@hp1 sbin]# hdfs dfs -chmod -R 777 /tmp/hive
[root@hp1 sbin]# hdfs dfs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2019-12-09 10:49 /hbase
drwxr-xr-x - root supergroup 0 2019-12-10 10:48 /tmp
drwxr-xr-x - root supergroup 0 2019-12-10 10:47 /user
[root@hp1 sbin]# hdfs dfs -ls /tmp/
Found 1 items
drwxrwxrwx - root supergroup 0 2019-12-10 10:48 /tmp/hive
[root@hp1 sbin]# hdfs dfs -ls /user/
Found 1 items
drwxr-xr-x - root supergroup 0 2019-12-10 10:47 /user/hive
[root@hp1 sbin]# hdfs dfs -ls /user/hive/
Found 1 items
drwxrwxrwx - root supergroup 0 2019-12-10 10:47 /user/hive/warehouse
创建/opt/hive/hive-2.3/tmp目录:
[root@hp1 hive-2.3]# mkdir tmp
[root@hp1 hive-2.3]# chmod -R 777 tmp
复制上穿的mysql驱动包到/opt/hive/hive-2.3/lib目录下:
cp /opt/package/mysql-connector-java-5.1.48-bin.jar /opt/hive/hive-2.3/lib/
编辑hive-site.xml文件如下:
"1.0" encoding="UTF-8" standalone="no"?>
-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<!-- 配置hive的hdfs目录 -->
hive.metastore.warehouse.dir</name>
/user/hive/warehouse</value>
location of default database for the warehouse</description>
</property>
hive.exec.scratchdir</name>
/tmp/hive</value>
HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. </description>
</property>
<!-- 配置hive的本地目录和用户名 -->
hive.exec.local.scratchdir</name>
/opt/hive/hive-2.3/tmp/root</value>
Local scratch space for Hive jobs</description>
</property>
<!-- 使用mysql存储元数据,配置mysql的信息 -->
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
Driver class name for a JDBC metastore</description>
</property>
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://hp1:3306/hive?createDatabaseIfNotExist=true&;characterEncoding=UTF-8&;useSSL=false&;</value>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
javax.jdo.option.ConnectionUserName</name>
root</value>
Username to use against metastore database</description>
</property>
javax.jdo.option.ConnectionPassword</name>
root</value>
password to use against metastore database</description>
</property>
</configuration>
9.2启动Hive
启动hive之前,必须保证hdfs和mysql启动
1.Hive数据库初始化
到/opt/hive/hive-2.3/bin目录下执行初始化命令:
[root@hp1 bin]# schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hp1:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
2.启动Hive
执行命令:
[root@hp1 bin]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hive/hive-2.3/lib/hive-common-2.3.6.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
3.测试
hive> create database user_test;
OK
Time taken: 4.32 seconds
hive> use user_test;
OK
hive> create table test_hive(id int, name string)
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 0.676 seconds
hive> show tables;
OK
test_hive
Time taken: 0.11 seconds, Fetched: 1 row(s)
hive> desc test_hive;
OK
id int
name string
Time taken: 0.084 seconds, Fetched: 2 row(s)
hive> load data local inpath '/lc/test_db.txt' into table test_hive;
Loading data to table user_test.test_hive
OK
Time taken: 1.783 seconds
hive> select * from test_hive;
1 张三
2 李四
3 王五
4 王麻子
5 张武
测试成功!!!!!!!!!
9.3停止Hive
hive> exit;
十.Flume
10.1安装Flume
10.1.1上传加压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/flume目录下
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin /opt/flume/flume-1.8
为了flume与Hadoop的交互,需要将/opt/hadoop/hadoop-2.7.7/share/hadoop/common和/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs目录下的6个jar复制到/opt/flume/flume-1.8/lib目录下:
#hadoop-common-2.7.7.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/common/hadoop-common-2.7.7.jar /opt/flume/flume-1.8/lib/
#commons-configuration-1.6.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/commons-configuration-1.6.jar /opt/flume/flume-1.8/lib/
#commons-io-2.4.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/commons-io-2.4.jar /opt/flume/flume-1.8/lib/
#hadoop-auth-2.7.7.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/hadoop-auth-2.7.7.jar /opt/flume/flume-1.8/lib/
#hadoop-hdfs-2.7.7.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/hadoop-hdfs-2.7.7.jar /opt/flume/flume-1.8/lib/
#htrace-core-3.1.0-incubating.jar
cp /opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar /opt/flume/flume-1.8/lib/
10.1.3配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export FLUME_HOME=/opt/flume/flume-1.8
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:${MYSQL_HOME}/bin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
10.1.3更改配置文件
在/opt/flume/flume-1.8/conf/目录下
1.编辑flume-env.sh
若没有flume-env.sh,复制flume-env.sh.template并重命名
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
在 flume-env.sh添加:
export JAVA_HOME=/opt/java/jdk1.8
10.2测试
将本地文件读到hdfs上
在/opt/flume目录下创建flume-file-hdfs.conf文件
[root@hp1 flume]# touch flume-file-hdfs.conf
编辑flume-file-hdfs.conf文件添加以下内容:
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
#读取的文件地址,这儿我设置的是hive的日志目录
a2.sources.r2.command = tail -F /tmp/root/hive.log
#脚本的启动目录
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
#被读取文件的上传目录
a2.sinks.k2.hdfs.path = hdfs://hp1:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
在启动Hadoop的前提下,执行以下命令:
[root@hp1 flume]# /opt/flume/flume-1.8/bin/flume-ng agent --conf /opt/flume/flume-1.8/conf/ --name a2 --conf-file /opt/flume/flume-file-hdfs.conf
执行完毕显示结果如下:
[root@hp1 flume]# /opt/flume/flume-1.8/bin/flume-ng agent --conf /opt/flume/flume-1.8/conf/ --name a2 --conf-file /opt/flume/flume-file-hdfs.conf
Info: Sourcing environment configuration script /opt/flume/flume-1.8/conf/flume-env.sh
Info: Including Hadoop libraries found via (/opt/hadoop/hadoop-2.7.7/bin/hadoop) for HDFS access
Info: Including HBASE libraries found via (/opt/hbase/hbase-2.1/bin/hbase) for HBASE access
错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty
错误: 找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty
Info: Including Hive libraries found via (/opt/hive/hive-2.3) for Hive access
+ exec /opt/java/jdk1.8/bin/java -Xmx20m -cp '/opt/flume/flume-1.8/conf:/opt/flume/flume-1.8/lib/*:/opt/hadoop/hadoop-2.7.7/etc/hadoop:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-2.7.7/contrib/capacity-scheduler/*.jar:/opt/hbase/hbase-2.1/conf:/opt/java/jdk1.8/lib/tools.jar:/opt/hbase/hbase-2.1:/opt/hbase/hbase-2.1/lib/shaded-clients/hbase-shaded-client-byo-hadoop-2.1.7.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/audience-annotations-0.5.0.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/commons-logging-1.2.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/findbugs-annotations-1.3.9-1.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/htrace-core4-4.2.0-incubating.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/log4j-1.2.17.jar:/opt/hbase/hbase-2.1/lib/client-facing-thirdparty/slf4j-api-1.7.25.jar:/opt/hadoop/hadoop-2.7.7/etc/hadoop:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/hdfs/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-2.7.7/contrib/capacity-scheduler/*.jar:/opt/hadoop/hadoop-2.7.7/etc/hadoop:/opt/hbase/hbase-2.1/conf:/opt/hive/hive-2.3/lib/*' -Djava.library.path=:/opt/hadoop/hadoop-2.7.7/lib/native org.apache.flume.node.Application --name a2 --conf-file /opt/flume/flume-file-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flume/flume-1.8/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hive/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
在开一个服务器窗口,启动hive:
[root@hp1 ~]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/hive-2.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/hive/hive-2.3/lib/hive-common-2.3.6.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
在web页面查看hdfs是否有文件存储:
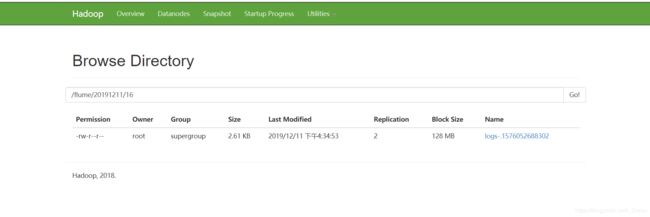 看到有文件上传,flume安装成功!!!!!
看到有文件上传,flume安装成功!!!!!
十一.Kafka
11.1安装Kafka
11.1.1上传解压安装包
将下载好的安装包上传到/opt/package目录下,并解压重命名到/opt/kafka目录下
tar -zxvf kafka_2.12-2.1.1.tgz
mv kafka_2.12-2.1.1 /opt/kafka/kafka-2.12
11.1.2配置环境变量
编辑/etc/profile文件
vi /etc/profile
添加
export KAFKA_HOME=/opt/kafka/kafka-2.12
更改
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:${MYSQL_HOME}/bin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:${KAFKA_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
11.1.3更改配置文件
到/opt/kafka/kafka-2.12/config目录下
编辑server.properties文件:
#将0更改为1,每个节点不能重复
broker.id=1
#将localhost:2181更改为如下
zookeeper.connect=hp1:2181,hp2:2181,hp3:2181
注意在发送到从节点后分别修改broker.id=2,broker.id=3
配置文件的详细解析如下:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
#broker的全局唯一编号,不能重复
broker.id=1
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
#处理网络请求的线程数量
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
#用来处理磁盘IO的线程数量
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
#请求套接字的最大缓冲区大小
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
#kafka消息存放的路径
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
#topic在当前broker上的分片个数
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#partion buffer中,消息的条数达到阈值,将触发flush到磁盘
#log.flush.interval.messages=10000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
#周期性检查文件大小的时间
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
#broker需要使用zookeeper保存meta数据
zookeeper.connect=hp1:2181,hp2:2181,hp3:2181
# Timeout in ms for connecting to zookeeper
#zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
11.1.4将主节点(hp1)的配置同步到从节点(hp2,hp3)
1.同步环境变量
scp /etc/profile root@hp2:/etc/profile
scp /etc/profile root@hp3:/etc/profile
使环境变量生效
source /etc/profile
2.同步配置文件
scp -r /opt/kafka root@hp2:/opt/
scp -r /opt/kafka root@hp3:/opt/
注意修改/opt/kafka/kafka-2.12/config/server.properties文件的broker.id
11.2启动Kafka
1.先全部启动Zookeeper
#hp1
[root@hp1 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#hp2
[root@hp2 /]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#hp3
[root@hp3 ~]# vi /opt/kafka/kafka-2.12/config/server.properties
[root@hp3 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.启动所有kafka后台运行
在/opt/kafka/kafka-2.12/目下执行命令:
./bin/kafka-server-start.sh -daemon config/server.properties &
执行完后jps命令查看
#hp1
[root@hp1 kafka-2.12]# jps
23762 NameNode
26916 Jps
26854 Kafka
24504 Application
24123 ResourceManager
23964 SecondaryNameNode
26447 QuorumPeerMain
[2]- 完成 ./bin/kafka-server-start.sh -daemon config/server.properties
#hp2
[root@hp2 kafka-2.12]# jps
23088 Jps
21031 DataNode
23067 Kafka
21132 NodeManager
22685 QuorumPeerMain
[1]+ 完成 ./bin/kafka-server-start.sh -daemon config/server.properties
#hp3
[root@hp3 kafka-2.12]# ./bin/kafka-server-start.sh -daemon config/server.properties &
[1] 22781
[root@hp3 kafka-2.12]# jps
21027 DataNode
22675 QuorumPeerMain
23053 Kafka
21134 NodeManager
23070 Jps
[1]+ 完成 ./bin/kafka-server-start.sh -daemon config/server.properties
11.3测试
1.在hp1上创建topic-test
[root@hp1 kafka-2.12]# ./bin/kafka-topics.sh --create --zookeeper hp1:2181,hp2:2181,hp3:2181 --replication-factor 3 --partitions 3 --topic test
Created topic "test"
2.在hp1,hp2,hp3上查看已创建的topic列表
[root@hp1 kafka-2.12]# ./bin/kafka-topics.sh --list --zookeeper localhost:2181
test
3.在hp1上启动生产者
[root@hp1 kafka-2.12]# ./bin/kafka-console-producer.sh --broker-list hp1:9092,hp2:9092,hp3:9092 --topic test
输入一些内容

4.在其他节点上启动控制台消费者
[root@hp2 kafka-2.12]# ./bin/kafka-console-consumer.sh --bootstrap-server hp1:9092,hp2:9092,hp3:9092 --from-beginning --topic test
hp1上输入的内容会出现

11.4停止Kafka
必须先停止Kafka再停止Zookeeper
在/opt/kafka/kafka-2.12/bin目录下执行:
kafka-server-stop.sh
Kafka安装成功!!!!!
十二.其他
参考博文:https://blog.csdn.net/qazwsxpcm/article/details/78937820
参考博文:https://blog.csdn.net/qq_40343117/article/details/100121774