快刀初试:Spark GraphX在淘宝的实践
(本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版)
对于网络科学而言,世间万物都可以抽象成点,而事物之间的关系都可以抽象成边,并根据不同的应用场景,生成不同的网络,因此整个世界都可以用一个巨大的复杂网络来代表。有关复杂网络和图算法的研究,在最近的十几年取得了巨大的进展,并在多个领域有重要的应用。
作为最大的电商平台,淘宝上数亿买家和卖家,每天产生数百亿的行为,包括浏览,收藏,购买……构成由多个巨型的行为网络,同样是复杂网络和图算法一展身手的好场景。但是尽管可以根据具体的业务场景进行相应的过滤,减少参与运算的顶点和边,最后生成的图,往往还是动辄上亿个顶点的巨型图,在其之上的计算,对于单机版的计算框架来说,是很难完成的任务。
因此,一个强大的分布式图计算框架是必不可少的工具。它既要有良好的性能,又要有丰富的功能和运算符,能够在海量的数据上,自如地运行各种复杂的图算法。在淘宝,我们在今年开始尝试使用Spark GraphX,做为分布式图计算的平台,进行了各种算法尝试和生产应用,取得了不错的效果。在此和各位分享一二。
GraphX简介
在Spark年幼的时候,0.5版本就已经带了一个Bagel小模块,提供了类似Pregel的功能,当然,这个版本还非常的原始,性能和功能都比较弱,属于实验型产品。到0.8版本的时候,鉴于业界对分布式图计算的需求日益见涨,Spark开始独立一个分支:Graphx-Branch,做为独立的图计算模块,借鉴GraphLab,开始设计开发GraphX。在0.9版本中,这个模块被正式集成到主干,虽然是alpha版本,但是已经可以开始进行试用,小面包圈Bagel告别舞台。1.0版本,GraphX正式投入生产使用。
值得留意的是,GraphX目前依然处于快速发展中,从0.8的分支,到0.9和1.0,每个版本代码都有不少的改进和重构,并根据观察,在没有改任何代码逻辑和运行环境,只是升级版本,切换接口和重新编译的情况下,每个版本能够有10-20%的性能提升。虽然和GraphLab的性能还有一定的差距,但是凭借着Spark整体的一体化流水线处理,社区热烈的活跃度以及快速改进速度,使得它具有强大的竞争力。

分布式图计算
在正式介绍GraphX之前,先看看通用的分布式图计算框架。简单来说,分布式图计算框架的目的,就是将对于巨型图的各种操作,包装为简单的接口,让分布式存储,并行计算等复杂问题对上层透明。从而使得复杂网络和图算法的工程师,可以更加聚焦在图相关的模型设计和使用上,而不用关心底层的分布式细节。为了实现该目的,需要解决两个通用的问题。
1. 图存储模式
巨型图的存储总体上有边分割和点分割两种存储方式。2013年GraphLab2.0推出,将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
-
边分割(Edge Cut)
每个顶点都存储一次,但是有的边会被打断,被分到了两台机器上。这样做的好处是节省存储空间,坏处是对于图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
-
点分割(Vertex Cut)
每个边都只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加存储开销,同时会引发数据同步的问题。好处是可以大幅减少内网通信量可以大大降低。
原本两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架,都把自己底层的存储形式变成了点分割。主要原因有2个:
-
磁盘的价格下降,存储空间不是问题了,但是内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵,这点就类似于常见的空间换时间的策略。
-
在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量非常悬殊,边分割会使得那些多邻居的点所相连的边大多数都会被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割的存储方式就被渐渐抛弃了
2. 图计算模型
目前的图计算框架,基本上都是遵循BSP计算模式。BSP全称Bulk Synchronous Parallell,由哈佛大学Leslie Valiant和牛津大学Bill McColl提出。在BSP中,一次计算过程由一系列全局超步组成,每一个超步由并发计算,通讯, 栅栏同步三个步骤组成。同步完成,标志着该一个超步的完成,以及下一个超步的开始。
BSP模式很简洁,基于BSP模式,目前有2种比较成熟的图计算模型:
-
Pregel模型——“像顶点一样思考”
2010年,Google的新的三架马车Caffeine、Pregel、Dremel发布。伴随着Pregel,BSP模型被广为人知。据说Pregel的名字是为了纪念欧拉的七桥问题,那七座桥所在的河流,就是叫Pregel。
Pregel借鉴MapReduce的思想,提出了"像顶点一样思考(Think Like A Vertex)"的图计算模式,让用户无需考虑并行分布式计算的细节,只需要实现一个顶点更新函数,让框架在遍历顶点时进行调用即可。
常见的代码模板如下所示:
void Compute(MessageIterator* msgs) {
//遍历由顶点入边传入的消息列表
for (; !msgs->Done(); msgs->Next())
doSomething()
//生成新的顶点值
*MutableVertexValue() = ...
//生成沿顶点出边发送的消息
SendMessageToAllNeighbors(...);
}
这个模型虽然简洁,但是很容易发现它的缺陷。对于邻居数很多的顶点,它需要处理的消息非常庞大,而在这个模式下,它们是无法被并发处理的。所以对于符合幂律分布的自然图,这种计算模型下,很容易发生假死或者崩溃。
-
GAS模型——邻居更新模型
相比于Pregel模型的消息通信范式,GraphLab的GAS模型更偏向共享内存风格。它允许用户的自定义函数访问当前顶点的整个邻域,可以抽象成Gather,Apply,Scatter这三个阶段,常被简称为GAS。相应用户需要实现的三个独立的函数:gather、apply和scatter。
常见的代码模板如下所示:
//从邻居点和边收集数据
Message gather(Vertex u, Edge uv, Vertex v) {
Message msg = ...
return msg
}
//汇总函数
Message sum(Message left, Message right) {
return left+right
}
//更新顶点Master
void apply(Vertex u, Message sum) {
u.value = ...
}
//更新邻边和邻居点
void scatter(Vertex u, Edge uv, Vertex v) {
uv.value = ...
if ((|u.delta|>ε) Active(v)
}
由于gather/scatter函数是以单条边为操作粒度,那么对于一个顶点的众多邻边,可以分别由相应的worker独立地调用gather/scatter函数。这一设计主要是为了适应点分割的图存储模式,从而避免Pregel模型会遇到的问题。
GraphX的框架
在GraphX设计的时候,点分割和GAS都已经成熟了,所以GraphX一开始就站在了巨人的肩膀上,并在设计和编码中,针对这些问题进行了优化,在功能和性能之间寻找最佳的平衡点。
每个Spark子模块,如同Spark本身一样,都有一个核心的抽象。GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,拥有Table和Graph两种视图,而只需要一份物理存储。而两种视图都有自己的独有的操作符,从而获得灵活操作和执行效率。

如同Spark一样,GraphX的代码依然非常简洁。核心的GraphX代码只有3千多行,而在此之上实现的Pregel模型,只要短短的二十多行。GraphX的代码结构整体如下:

整体还是很清晰明了,其中大部分的impl包的实现,都是围绕着Partition而优化和进行。这种某种程度上说明了,点分割的存储和相应的计算优化,的确是图计算框架的重点和难点。
GraphX的设计要点
GraphX的底层设计有几个关键点
-
对Graph视图的所有操作,最终都会被转换成其关联的Table视图的RDD操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列RDD的转换过程。因此,其实Graph最终是具备了的RDD的3个关键特性:Immutable,Distributed,Fault-Tolerant。其中最关键的是不可变(Immutable)性,所有图的转换和操作,逻辑上都是产生了一个新图,物理上,Graphx会有一定程度的不变顶点和边的复用优化,对用户透明。
-
两种视图底层共用的物理数据,由RDD[VertexPartition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition,在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
-
图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略(PartitionStrategy)。划分策略会将边分配到各个EdgePartition,顶点Master分配到各个VertexPartition,EdgePartition也会缓存本地边的关联点的Ghost副本。划分策略的不同会影响到所需要缓存的Ghost副本数量,以及每个EdgePartition分配的边的均衡程度,需要根据图的结构特征进行选取最佳的Strategy。目前有EdgePartition2d,EdgePartition1d,RandomVertexCut,CanonicalRandomVertexCut这4种策略。目前试验的结果,在淘宝大部分场景下,EdgePartition2d效果最好。
GraphX的图运算符
如同Spark一样,GraphX的Graph类,提供了丰富的图运算符,大致结构如下:
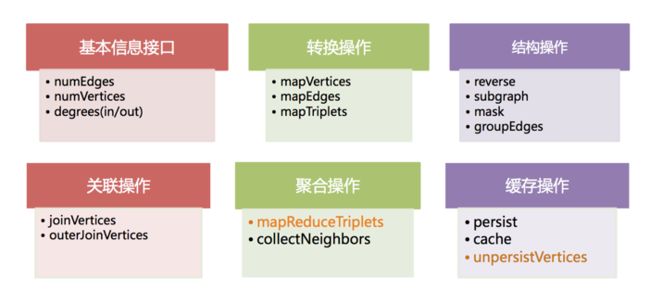
具体每个方法的说明和用法,可以在官方的GraphX Programming Guide找到每个函数的详细说明,就不一一列举。重点讲几个需要注意的方法:
图的cache
由于一个图,是由3个RDD组成的,所以会占用更多的内存。相应图的cache,unpersist和checkpoint,更需要留意使用技巧。出于最大限度的复用边的理念,GraphX的默认接口,只提供了unpersistVertices的方法,如果要释放边,需要自己调用g.edges.unpersist()方法才能释放,这个给用户带来了一定的不便,但是却给GraphX的优化,提供便利和空间。
参考Graphx的Pregel代码,对一个大图,目前最佳的实践是:
var g=...
var prevG: Graph[VD, ED] = null
while(...){
prevG = g
g = g.(………………)
g.cache()
prevG.unpersistVertices(blocking=false)
prevG.edges.unpersist(blocking=false)
}
大体之意,就是根据GraphX中graph的不变性,对g做了操作并赋回给g之后,g已经不是原来的g了,而且会在下一轮迭代使用,所以必须cache。另外,你必须先用prevG,保留住对原来的图的引用,并在新图产生之后,快速的将旧图彻底的释放掉。否则一个大图,几轮迭代下来,就会有内存泄漏的问题,很快耗光作业内存。
mrTriplet——邻边聚合
mrTriplets的全称是mapReduceTriplets,它是GraphX中最核心和强大的一个接口。Pregel也基于它而来,所以对它的优化,能很大程度上影响整个GraphX的性能。
mrTriplets运算符的简化定义是:
def mapReduceTriplets[A](
map: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
reduce: (A, A) => A)
: VertexRDD[A]
它的计算过程如下:
-
map:应用于每一个triplet上,生成一个或者多个消息, 消息以triplet关联的两个顶点中的任意一个或两个为目标顶点
-
reduce:应用于每一个Vertex上,把发送给每一个顶点的消息合并起来
mrTriplets最后返回的是一个VertexRDD[A], 它包含了每一个顶点聚合之后的消息(类型为A), 没有接收到消息的顶点不会包含在返回的VertexRDD中。
在最近的版本,GraphX针对它进行了如下几个优化,这些优化,对于Pregel以及所有上层算法工具包的性能,都有着重大的影响。其中包括:
-
Caching for Iterative mrTriplets & Incremental Updates for Iterative mrTriplets
在很多图分析算法中,不同点的收敛速度变化很大。在迭代的后期,只有很少的点会有更新。因此对于没有更新的点,下一次mrTriplets计算时EdgeRDD无需更新相应点值的本地缓存,能够大幅降低通信开销。
-
Indexing Active Edges
没有更新的顶点在下一轮迭代时就不需要向邻居重新发送消息。因此mrTriplets遍历边时,如果一条边的邻居点值在上一轮迭代时没有更新,可以直接跳过,避免了大量无用的计算和通信。
-
Join Elimination
一个triplet是由一条边和其两个邻居点组成的三元组,操作triplet的map函数常常只需访问其两个邻居点值中的一个。例如在PageRank计算中,一个点值的更新只和其源顶点的值有关,而其所指向的目的顶点的值无关。那么在mrTriplets计算中,就不需要VertexRDD和EdgeRDD的3-way join,而只需要2-way join。
所有的这些优化,都使得GraphX的性能,逐渐逼近GraphLab。虽然还有一定的差距,但是一体化的流水线服务,和丰富的编程接口,可以弥补性能的稍微差距。
进化的Pregel计算模型
Graphx中的Pregel接口,并不严格遵循Pregel的模型,它是一个参考GAS改进的Pregel模型。定义如下:
def pregel[A](initialMsg: A, maxIterations: Int, activeDirection: EdgeDirection)(
vprog: (VertexID, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexID,A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
这种基于mrTrilets方法的Pregel模型,和标准的Pregel的最大区别是,它的第2段参数体,接受的是3个函数参数,而不接受messageList。它不会在单个顶点上进行消息遍历,而是会将顶点的多个ghost副本收到的消息聚合后,发送给master副本,再使用vprog函数来更新点值。消息的接收和发送,都是被自动并行化处理的,无需担心超级节点的问题。
常见的代码模板如下所示:
//更新顶点
vprog(vid: Long, vert: Vertex, msg: Double): Vertex = {
v.score = msg + (1 - ALPHA) * v.weight
}
//发送消息
sendMsg(edgeTriplet: EdgeTriplet[…]): Iterator[(Long, Double)]
(destId, ALPHA * edgeTriplet.srcAttr.score * edgeTriplet.attr.weight)
}
//合并消息
mergeMsg(v1: Double, v2: Double): Double = {
v1+v2
}
可以看到,GraphX设计这个模型的用意。它综合了Pregel和GAS两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算。另外值得注意的是,官方的Pregel版本是最简单的一个版本,对于复杂的业务场景,根据这个版本扩展一个定制的Pregel,是很常见的做法。
图算法工具包
GraphX也提供了一套图算法,方便用户对图进行分析。目前最新版本,已经支持PageRank,数三角形,最大连通图,最短路径等6种经典的图算法,这些算法的代码实现,目的和重点在于通用性。如果要获得最佳性能,可以参考其实现,进行修改和扩展,可以满足业务需求。另外研读这些代码,也是理解GraphX编程的Best Practice的好方法,建议有兴趣深入研究分布式图算法开发的同学都通读一遍。
GraphX在淘宝
1. 图谱体检平台
基本上,所有的关系,都可以从图的角度来看待和处理,但是到底一个关系的价值多大?健康与否?适合用于什么场景?很多时候是靠运营和产品凭感觉来判断和评估。如何将各种图的指标精细化,规范化,对于产品和运营的构思进行数据上的预研指导,提供科学决策的依据,是图谱体检平台设计的初衷和出发点。
基于这样的出发点,借助GraphX丰富的接口和工具包,针对淘宝内部林林总总的图业务需求, 我们开发一个图谱体检平台。目前主要进行下列指标的检查:
-
度分布
度分布是一个图最基础的指标,也是非常重要的一个指标。度分布检测的目的,主要是了解图中"超级节点"的个数和规模,以及所有节点度的分布曲线。超级节点的存在,对各种传播算法,都会有重大的影响,不论是正面助力还是反面的阻力,所以要预先对于这些数据量有个预估。借助GraphX的最基本的图信息接口:degrees: VertexRDD[Int],包括inDegrees和outDegrees,这个指标可以轻松地计算出来,并进行各种各样的统计。
-
二跳邻居数
对于大部分社交关系来说,只获得一跳的度分布是远远不够的,另一个重要的指标是二跳邻居数。例如秘密App中,好友的好友的秘密,传播的范围更广,信息量更丰富。因此二跳邻居数的统计,是图谱体检中很重要的一个指标。二跳邻居的计算GraphX没有给出现成的接口,需要自己设计和开发。目前使用的方法是:
-
第一次遍历,所有点往邻居点传播一个带自身Id,生命值为2的消息
-
第二次遍历,所有点将收到的消息,往邻居点再转发一次,生命值为1
-
最终统计所有点上,接收到的生命值为1的Id,并进行分组汇总,得到所有点的二跳邻居
值得注意的是,进行这个计算之前,需要借助度分布,将图中的超级节点去掉,不纳入二跳邻居数的计算。否则这些超级节点一来会出现在第一轮传播后,收到过多的消息而爆掉,二来它们参与计算,会影响和它们有一跳邻居关系的顶点,导致它们不能得到真正有效的二跳邻居数。所以必须先筛选掉。
-
连通图
检测连通图的目的,是弄清一个图有几个连通部分,以及每个连通部分有多少顶点。这样可以将一个大图分割为多个小图,并去掉零碎的连通部分,从而可以在多个小子图上,进行更加精细的操作。目前GraphX提供了ConnectedComponents和StronglyConnectedComponents算法,使用它们可以快速的计算出相应的连通图。
连通图可以进一步演化,变成社区发现算法,而该算法优劣的评判标准之一,是计算模块的Q值,来查看所谓的modularity情况。但是GraphX中还是没有对于Q值计算的函数,我们已经实现了一个,后续会将这个实现提交到社区。
更多的指标,例如Triangle Count和K-Core,无论是借助GraphX已有的函数,还是自己从头开发,都陆续在进行中。目前这个图谱体检平台已经初具规模,通过平台的建立和推广,图相关的产品和业务,逐渐走上“无数据,不讨论,用指标来预估效果”的数据化运营之路,有效提高沟通效率,为各种图相关的业务开发走上科学化和系统化之路做好准备。
2. 多图合并工具
在图谱体检平台的基础上,我们可以了解到各种各样关系的特点。不同的关系,都会有自己的强项和弱项,例如有些关系图谱连通性好些,而有些关系图谱的社交性好些,所以往往我们需要使用关系A来丰富关系B。为此,在图谱体检平台之上,借助GraphX,我们开发了一个多图合并工具,提供类似于图的并集的概念,可以快速的对指定的2个不同关系图谱,进行合并,产生一个新的关系图谱。
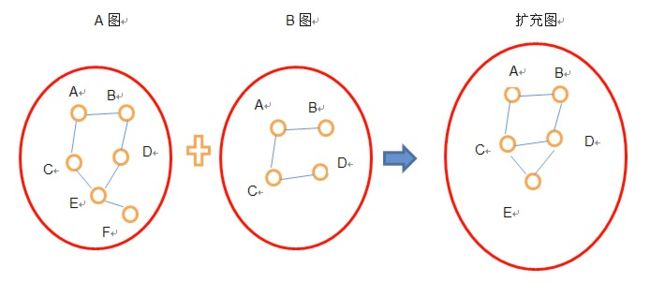
以用基于A关系的图来扩充基于B关系的图,生成扩充图C为例,融合算法基本思路如下:
-
若图B中某边的两个顶点都在图A中,则将该边加入C图(如BD边)
-
若图B中某边的一个顶点在图A中,另外一个顶点不在,则将该边和另一顶点都加上(如CE边和E点)
-
若图A中某边的两个顶点都不在图B中,则舍弃这条边和顶点(如EF边)
使用GraphX的outerJoinVertices等图运算符,可以很简单地完成上述的操作。另外,在考虑图合并的时候,也可以考虑给不同的图的边加上不同的权重,综合考虑点之间的不同关系的重要性。新产生的图,会再进行一轮图谱体检,通过前后三个图各个体检指标的对比,可以对于业务上线之后效果有个预估和判断。如果不符合期望,可以尝试重新选择扩充方案。
3. 能量传播模型
加权网络上的能量传播是经典的图模型之一, 可用于用户信誉度预测。模型的思路是:物以类聚,人以群分。常和信誉度高的用户进行交易的,信誉度自然较高,常和信誉度差的用户有业务来往的,信誉度自然较低。模型不复杂,但淘宝全网有上亿的用户点和几十亿关系边,要对如此规模的巨型图进行能量传播,并对边的权重进行精细的调节,对图计算框架的性能和功能都是巨大的考验。借助GraphX,我们在这两点之间取得了平衡,成功实现了该模型。
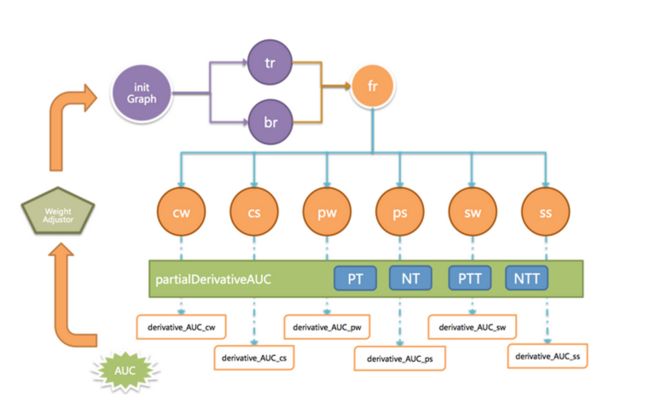
流程如图4,先生成以用户为点、买卖关系为边的巨型图initGraph,对选出种子用户,分别赋予相同的初始正负能量值(TrustRank & BadRank),然后进行两轮随机游走,一轮好种子传播正能量(tr),一轮坏种子传播负能量(br),然后正负能量相减得到finalRank,根据finalRank判断用户的好坏。边的初始传播强度是0.85,这时AUC很低,需要再给每条边,带上一个由多个特征(交易次数,金额……)组成的组合权重。每个特征,都有不同的独立权重和偏移量。通过使用partialDerivativeAUC方法,在训练集上计算AUC,然后对AUC求偏导,得到每个关系维度的独立权重和偏移量,生成新的权重调节器(WeightAdjustor),对图上所有边上的权重更新,然后再进行新一轮大迭代,这样一直到AUC稳定时,终止计算。
在接近全量的数据上进行3轮大迭代,每轮2+6次Pregel,每次Pregel大约30次小迭代后,最终的AUC从0.6提升到0.9,达到了不错的用户预测准确率。训练时长在6个小时左右,无论在性能还是准确率上,都超越业务方的期望。
未来图计算的前景
经过半年多的尝试,对于GraphX可以胜任的图计算的规模和性能,目前我们都已经心中有数。之前一些想做,但因为没有足够的计算能力而不能实现的图模型,现已经不是问题。我们将会进一步将越来越多的图模型,在GraphX上实现。
这些模型应用于用户网络的社区发现、用户影响力、能量传播、标签传播等,可以提升用户粘性和活跃度;而应用到推荐领域的标签推理,人群划分、年龄段预测、商品交易时序跳转,则可以提升推荐的丰富度和准确性。复杂网络和图计算的天地广阔无垠,有更多的未知等待我们去探索和实践,借助Spark GraphX,未来我们可以迎接更大挑战。