物体检测模型RFBNet——一个非常好用的模型。
RFBNet,是一篇没有公式,通俗易懂,图文并茂,格式优雅的好文,文中提出了RFB,是一个可以集成至其他检测算法的模块,从论文的fig2、3、4、5中也很容易理解,就是受启发于人类视觉感知系统,提出的RFBNet基于SSD的backbone,结合了Inception、虫洞卷积的思想,来尽量模拟人类的视觉感知,最终实验结果也非常好。
训练也没有特别的tricks,占用资源不大,但效果就是好,源码也看着很舒服,跑起来很容易,速度快,自己的数据集也方便训练测试,实验结果非常work,并通过实验结果证明RFB性能的优秀;如果硬是要找缺点的话,就是效果好,但不知道为什么效果好,解释不了,文中也未给出性能好的原因,只是结合人类视觉认知的观点。。。
名词定义:
1 RFB:Receptive Field Block,本文提出的轻量级、并可集成至各类检测算法的模块,结合了Inception、虫洞卷积的思想,可以参照论文的fig2、3、4、5理解;
Abstract
1 现有主流的目标检测器一般两条路子:
1.1 使用强有力的主干网(如ResNet-101、Inception)提取高判别性的特征,但计算开销大,运行速度慢;
1.2 使用轻量级的主干网(如MobileNet),运行速度快,但性能就弱一点;
2 本文提出RFB,并将RFB集成至SSD,形成RFBNet;通过设计的RFB模块,即使在轻量级主干网上也能提取到高判别性特征,最终RFBNet速度快,性能好;
3 RFB受启发于人类视觉的Receptive Fields结构,将RFs的尺度、离心率(size and eccentricity of RFs)纳入考虑范围,最终提升了特征的判别性与鲁棒性;
4 RFBNet在Pacal VOC、COCO上性能很好,Pacal VOC上map超过80%,但因为主干网轻量级(MobileNet、VGG16轻量级网络),速度也很快;---- 因此整体上是一个很实用的网络结构;
1 Introduction
主流的2-stage目标检测算法,如RCNN、Fast RCNN、Faster RCNN在Pascal VOC、MS COCO上性能棒棒哒,一般包含两阶段:
1st stage:提类别无关、不可知(category-agnostic)的region proposals;
2nd stage:基于proposals的CNN特征,作进一步bbox cls与reg;
以上方案中,提取proposals特征的CNN主干网占据着重要角色,我们希望提取到的目标特征,不仅判别性强,而且具有鲁棒的位置平移不变性;
现有sota目标检测算法也都证明了以上观点:一般都基于强有力的主干网,如ResNet-101、Inception;FPN使用自顶而下的方式构建特征金字塔,结合了高低层feature map上的特征,Mask RCNN使用RoIAlign生成更精确的regional features,都使用到了性能强悍的主干网提取到的高判别性特征,弊端就是计算量过大,导致前向预测耗时也很大;
为了提升模型检测的速度,1-stage的目标检测算法应运而生,直接省略了region proposals生成的阶段,如YOLO、SSD,尽管可以达到实时的运行速度了,但对比sota的2-stage方法,却损失了10% ~ 40%的精度;更新的1-stage检测算法,如DSSD、RetinaNet提升了检测精度,性能上完全不输2-stage检测算法,但依旧使用强大的主干网(如ResNet-101),耗时又增大了;
那如果我们想检测器性能佳、速度快,怎么办?作者给了个方向:使用轻量级的主干网,但增加一些人工设计机制(hand-crafted mechanisms),使得提取到的特征表达能力更强,这比无脑的加layer、加conv显得更加优雅;神经学发现,在人类视觉皮层中,群体感受野(population RF,pRF)的尺度是其视网膜图(retinotopic maps)偏心度的函数,虽然各个感受野之间有差异,但其尺度都是随着视网膜图的偏心度而增加的,如fig 1;这一发现揭示了目标区域要尽量靠近感受野中心的重要性,有助于提升模型对小尺度空间位移的鲁棒性;一些传统的浅层特征描述子,如hsog、derf受启发于以上方案,在局部图像匹配上取得了很不错的性能;

从fig 1中能说明几个问题:
(A):1. 群体感受野的尺度是其视网膜图偏心度的函数,其尺度与视网膜图的偏心度正相关;
2. 不同视网膜图上群体感受野的尺度不一样;
(B):基于(a)中参数的pRFs的空间矩阵,图中每个圆的半径为合适离心率下RF的尺度;
除模型本身的替换上,还可以使用同等尺度的FRs对feature map上各个位置点上操作(set RFs at the same size with a regular sampling grid,其实就是单个feature map上常规的conv操作),但可能造成特征判别性、鲁棒性的损失,如fig 3;
Inception:通过连接多个分支的conv操作(各个分支上最终得到的卷积核尺度不一,可能堆叠多个conv),最终获得了多个尺度的RFs,Inception V1 ~ V3在目标检测、图像分类上性能棒棒哒,但所有的卷积核是在同样的conv center上做的操作(all kernels in Inception are sampled at the same center,常规的conv操作就是在同样的center上操作的(与center的距离相等),我的理解就是都使用了相同尺度的卷积核,尽管最终各个分支上达到了不同的感受野,但是通过堆叠相同尺度的conv操作达到的);
ASPP:Atrous Spatial Pyramid Pooling,利用到了多尺度信息,上、下层feature map间连接多个并行的dilated conv分支,每个分支上使用不同的atrous rate,最终得到了对center的不同距离;但虫洞卷积在前一个feature map上,使用了基于相同尺度的conv kernel,提取到的特征判别性还是不够;
Deformable CNN:根据目标的尺度、外形自适应地调整RFs的空间分布,尽管其sampling grid是可变的,但却未考虑到RFs离心率的影响,也即RFs内所有pixel对输出响应的贡献率相同,未使用到fig 1中的结论;
受启发于人类视觉的Receptive Fields结构,本文提出RFB,将RFs的尺度、离心率纳入考虑范围,使用轻量级主干网也能提取到高判别性特征,使得检测器速度快、精度高;具体地,RFB基于RFs的不同尺度,使用不同的卷积核,设计了多分支的conv、pooling操作(makes use of multi-branch pooling with varying kernels),并通过虫洞卷积(dilated conv)来控制感受野的离心率,最后一步reshape操作后,形成生成的特征,如fig 2所示:

从fig 2中可知,RFB也concate了多个conv分支,与Inception结构类似,每个分支上使用不同尺度的常规卷积 + 虫洞卷积,通过常规卷积的不同卷积核尺度来模拟pRFs中的不同感受野,各个分支上通过各自dilated conv所得到的离心率,来模拟pRF的尺度与离心率的比例;
最终通过concate + 1 x 1 conv减少feature map通道数,得到feature map上spatial array of RF就与fig 1中人类视觉体系中的hV4比较类似了;---- 读到这里就明白了,RFB各种操作的良苦用心,就是为了模拟人类的视觉感知模式,最终得到的结果与fig 1的hV4比较类似;
本文进一步将RFB集成至SSD,形成1-stage的RFBNet,RFBNet精度可以与sota的2-stage检测算法相媲美,且不使用ResNet-101这种主干网,仅用轻量级主干网,速度很快;此外,实验中将RFB模块集成至MobileNet中,性能也很好,这充分表明了RFB本身的高泛化能力、和小强般的可适应性;
本文spotlight如下:
1. 提出RFB模块,RFB受启发于人类视觉的Receptive Fields结构,将RFs的尺度、离心率纳入考虑范围,即使通过轻量级的网络结构,也能提取到高判别性的特征;
2 提出将RFB集成至SSD(直接使用RFB替换SSD的top conv层即可),形成RFBNet,速度快,性能好;
3. RFBNet在Pacal VOC、COCO上性能很好,Pacal VOC上map超过80%,但因为主干网轻量级(MobileNet、VGG16轻量级网络),速度也很快,实时;
2 Related Work
Two-stage detector
提到了RCNN、Fast RCNN、Faster RCNN、R-FCN、FPN、Mask RCNN,模型性能逐步提升;
One-stage detector
有代表性的YOLO、SSD,直接在整个feature map上预测多个目标的cls score、bbox loc,都使用了轻量级的主干网以提升模型检测速度,但精度就弱于2-stage的方法了;
DSSD、RetinaNet将轻量级主干网替换为ResNet-101,再使用到如de-conv、focal loss等微操,性能接近、甚至优于2-stage的目标检测算法,但牺牲了检测速度;
Receptive field
本文目标:提升1-stage目标检测算法的性能,却不引入大量的计算开销;因此本文未使用直接替换高计算量主干网的无脑做法,而是受启发于人类视觉系统的RFs机制,引入RFB,在轻量级主干网上也能提取到高判别性的特征;
RFs也已被深入研究,如Inception、ASPP、Deformable CNN,如fig 3:

Inception:通过连接多个分支的conv操作(各个分支上最终得到的卷积核尺度不一,可能堆叠多个conv),最终获得了多个尺度的RFs;但所有的卷积核是在同样的conv center上做的操作,需要更大的卷积核才能生成相同的采样覆盖率(这个我不是很懂),可能丢失目标的重要信息;
ASPP:利用到了多尺度信息,上、下层feature map间连接多个并行的dilated conv分支,每个分支上使用不同的atrous rate,最终得到了对center的不同距离;但虫洞卷积在前一个feature map上,使用了基于相同尺度的conv kernel,认为featre map上每个位置对目标的贡献率相同,可能混淆目标本身和context,提取到的特征判别性还是不够,;
Deformable CNN:根据目标的尺度、外形自适应地调整RFs的空间分布,尽管其sampling grid是可变的,但却未考虑到RFs离心率的影响,也即RFs内所有pixel对输出响应的贡献率相同,未使用到fig 1中的结论;
RFB:强调了类似fig1 hV4的daisy-shape中,RF尺度与离心率间的关联度,距离conv center比较近的位置,通过更小的kernel获取赋予更大的权重(bigger weights are assigned to the positions nearer to the center by smaller kernels),使得靠近center位置的特征更加被强调出来,距离center越远,其对对中特征的贡献率越低;
当前,Inception、ASPP并未在1-stage检测器中取得很好的性能,但RFB结合了二者的优点后,取得了不错的性能提升;
3 Method
本节介绍视觉感知皮层、RFB各个模块,RFB模拟视觉感知的方法,RFBNet的结构,训练 / 测试方案等;
3.1 Visual Cortex Revisit
核磁共振技术(fMRI)可以毫米级精度地检测到人脑活动,感受野建模也成为衡量人脑活动的重要感知方式,pRF模型:神经元的集合反应区域(pooled responses of neurons),基于fMRI + pRF,就可以进一步探索人脑视觉皮层内各区域间的关系,在视觉皮层中,研究人员发现了pRF尺度与偏心率呈正相关,且在不同感visual field maps中,其相关系数还不同;---- 不是很懂,但可结合fig 1理解;
3.2 Receptive Field Block
RFB是一个多分支的conv block,内部结构包含两部分:
1 不同卷积核尺度的多分支conv,于Inception结构等价,用于模拟多尺度的pRFs;
2 虫洞卷积操作,用于模拟人类视觉感知中pRF尺度与离心率间的关系;
RFB模块的可视化结果如fig 2所示;
Multi-branch convolution layer
Inception结构证明:使用多个分支的不同conv kernels,来获取多尺度RFs,性能优于固定conv kernel的方案,RFB使用了最新的Inception结构:Inception V4、Inception-ResNet V2;
具体地:先1 × 1 conv降低feature map通道数,在每个分支上形成bottleneck结构,再接常规n × n conv;并替换5×5 conv为两个堆叠的3×3 conv,不仅降低了参数量,也增加了模型的非线性能力,并进一步使用1 × n + n × 1 conv替换原始n × n conv,并还有一个如ResNet的shortcut设计,如fig 4;

Dilated pooling or convolution layer
结合fig 4,就是增加了虫洞卷积,核心思想:在保持相同数量参数,生成更大分辨率feature map的前提下,增加各层feature map的感受野,使之获取更多的上下文信息;虫洞卷积在SSD、R-FCN上性能很好,RFBNet使用虫洞卷积来模拟人类视觉感知中pRFs离心率的作用;
结合fig 4就很好理解了,每个分支的常规conv操作后,连接一个dilates conv层(即conv,ratio),可以注意到,常规conv的kernel size与dilate conv的ratio刚好是对应的,作者认为就可以模拟pRFs的尺度与离心率;---- 虽然我并不懂这个原理;
最后各个分支concate后再接1 x 1 conv,再与shortcut做element-wise sum,可视化结果就如fig 1、2所示了;
3.3 RFB Net Detection Architecture
RFBNet基于multi-scale + 1-stage的SSD, 将RFB模块直接接到SSD的top conv层即可,速度快,效果好,还可以复用SSD的很多参数;
Lightweight backbone
复用了SSD的backbone VGG16,在ILSVRC CLS-LOC上做pre-train,将fc6、fc7全连接层参数做sub-sampling后变为conv layer,pool5改2×2-s2为3×3-s1(feature map尺度未降),并新增dilated conv以扩大感受野,忽略fc8和所有的dropout层;
RFB on multi-scale feature maps

SSD使用特征金字塔的多分支检测目标,feature map尺度逐步减少,感受野逐步增大,RFBNet继承SSD的结构,在高分辨率的conv4-3上接RFB-s模块,模拟人类视网膜中的小尺度pRFs;最顶两层未使用RFB模块,作者说主要是feature map尺度太小了,没法使用类似5 x 5尺度的卷积核;
3.4 Training Settings
RFBNet实现基于ssd.pytorch,训练策略与SSD一致:数据增强、OHEM、default box的尺度、长宽比设置,损失函数(loc:smooth L1 loss;cls:softmax loss),仅修改了 lr 的设置方式,新增卷积层使用MSRA的方法,对应代码里面的kaiming_normal;
4 Experiments
RFBNet在Pascal VOC 2007(20类)、MS COCO(80类)上测试,Pascal VOC计算mAP的gt bbox与pred bbox的IoU阈值为0.5;COCO屌一点,COCO-style的AP评估标准为IoU阈值从[0.5,0.95]区间,stride = 0.05,可以更全方位地评估检测器性能;
4.1 Pascal VOC 2007
使用trainval_2007 + trainval_2012(二者因为数据有重复,所以取交集数据)训练RFBNet,共训练250个epochs;如果直接复用SSD中lr = 10-3训练,会导致RFBNet训练时loss剧烈波动,不易收敛,实验中采用的 “warmup” 策略:前5个epochs,将 lr 从10−6逐步提升至4×10−3,再用常规训练策略,在150 / 200 epochs上分别将 lr 减少10倍;
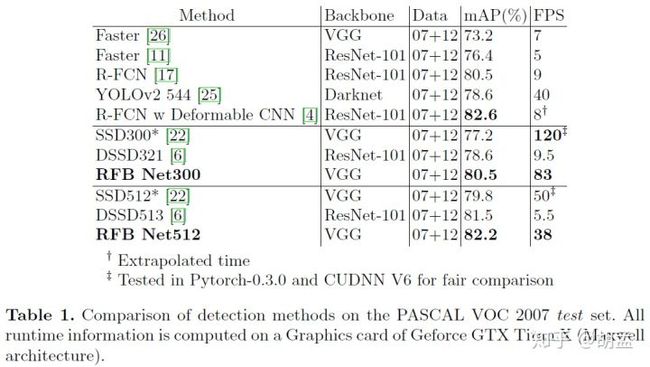
table 1为RFBNet性能,SSD300* / SSD512*通过数据增强生成更多的小尺度样本图片用于模型训练,RFBNet512的mAP:82.2%,与2-stage的R-FCN很接近,而R-FCN基于ResNet-101的主干网,速度却慢很多;
4.2 Ablation Study
来一波消融实验,结果如table2、3:
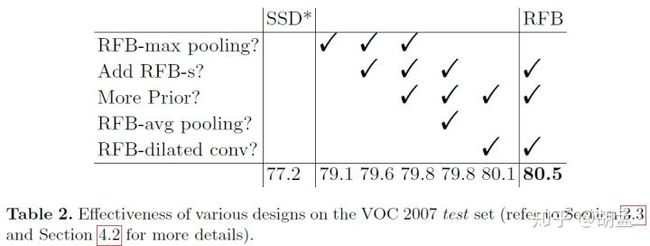
RFB module
baseline:SSD300*(全新的数据增强方法),mAP:77.2%,替换最后的conv层至RFB-max pooling,就可以79.1%,说明RFB模块的性能不错;
Cortex map simulation
增加RFB-s:修改RFB参数来模拟cortex maps中pRFs尺度与离心率的比例,从table 2中可知mAP:79.1% -> 79.6%(RFB max-pooling),80.1% -> 80.5%(RFB-dilated conv);
More prior anchors
原版SSD在conv4_3、conv10_2、conv11 2上设置4个default boxes,其他层设置6个default boxes,但HR、S3FD认为检测小尺度目标的低层feature map上(如conv4_3),若设置更多anchor,可以更方便召回小尺度目标;
于是在SSD、RFBNet的conv4_3上也都设置了6个default boxes,实验结果发现对SSD没性能提升,但对RFBNet确有性能提升(79.6% -> 79.8%);
Dilated convolutional layer
table 2中对比了RFB-max pooling、RFB-avg pooling、RFB-dilated conv三种方案,发现RFB-dilated conv性能最好(79.8% -> 80.5%),原因:前两种方案(dilated pooling)虽然避免了新增额外的参数,却限制了多尺度RFs的特征融合;
Comparison with other architectures

Inception-L:修改该模块内参数,使之与RFB有相同尺度的RF;
ASPP-S:原版ASPP中参数训练于图像风格数据,对目标检测而言,其RFs过大,实验中也做了调整,使之RFs尺度与RFB保持一致;
消融实验也很容易做,在fig 5中把最顶层换成table 3中各个模块,其他训练流程、参数保持一致,可以发现RFB还是最牛逼的,且作者认为RFB有更大尺度的RF,会带来更精准的目标定位;
4.3 Microsoft COCO
COCO上来一波:训练集trainval35k(train + val 35k set),复用SSD在COCO中减少default box尺度的策略(因COCO上目标尺度远小于Pascal VOC),仍使用Pascal VOC类似的 “warmup” 策略,总共训练120个epochs;

从table 4中可知,RFBNet性能很好,比baseline的SSD300*性能好,比基于ResNet-101主干网的R-FCN快(输入600 × 1000 pix图像),RFBNet512与RetinaNet500性能比较接近,但RetinaNet500使用ResNet-101-FPN主干网 + focal loss,RFBNet512仅基于轻量级的VGG16模型,速度快很多;
RetinaNet800虽然性能最好,但基于800 pix短边图像输入,耗时就更长了;
RFBNet512-E使用两种方案进一步提升模型性能(mAP:34.4%,耗时却只增加3ms):
1 与FPN类似,在使用RFB-s前,将conv7 fc的feature map上采样(RFBNet是全卷积,所以conv7 fc也是4-d tensor),再与conv4_3做concate;
2 在所有RFB模块中增加一个7 x 7卷积核的分支;---- 对应到RFB_Net_E_vgg.py代码中,分为1 x 7的conv、7 x 1的conv、dilation = 7的虫洞卷积等;
5 Discussion
Inference speed comparison
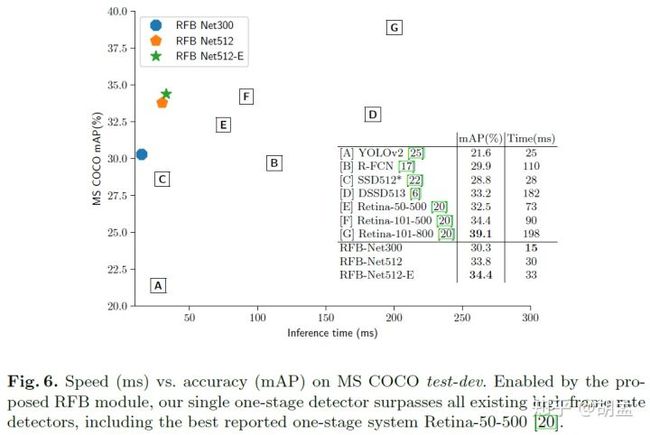
结合table 1、fig 6,RFBNet真腻害,速度快,实时,效果好,都集中在图像左上角;
Other lightweight backbone

table 5,在MobileNet-SSD上添加RFB模块,train + val35k上训练,minival5k上测试,可以进一步提升性能,充分证明了RFB本身强大的泛化能力;
Training from scratch
现在训练检测器一般都是基于在ImageNet上已训练好的分类模型,以该分类模型为backbone,再在检测数据集上继续训练(相当于复用分类模型的参数,因为分类模型也有很强的特征提取能力);如果检测器参数也从零训练,一般效果都不怎么好;
DSOD:无需预训练模型,直接使用轻量级结构在VOC 2007上从零训练, test set上mAP:77.7%,但若使用pre-trained模型训练,性能竟没有进一步提升;---- 炼丹啊,毫无道理可言;
RFN模块竟然也有从零训练的能力,作者将RFBNet-300也在VOC 07+12 trainval上training from scratch,在test set上mAP:77.6%,与DSOD旗鼓相当,但如果增加了轻量级VGG16作为pre-trained backbone,mAP就到了80.5%,真是神奇啊~~~
6 Conclusion
1 本文提出RFB,受启发于人类视觉的Receptive Fields结构,不使用计算量大、层数深的主干网,通过轻量级主干网结构,结合RPB模块,也能提取到高判别性的特征;
2 RFB度量了RFs的尺度、离心率间的关系,可以生成更有判别性、更鲁棒的特征;
3 将RFB集成至SSD(轻量级的VGG16做主干网),形成RFBNet,RFBNet在Pacal VOC、COCO上性能很好,Pacal VOC上map超过80%,与sota的2-stage检测算法(使用高计算量的主干网,如ResNet-101)性能相当,且因为RFBNet主干网轻量级,运行速度很快;