Spark快速入门系列(2) | Spark 运行模式之Local本地模式
大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是Spark 运行模式之Local本地模式。

目录
- 一. 解压 Spark 安装包
- 二. 运行官方求PI的案例
- 2.1 `spark-submit`语法
- 2.2 关于 `Master URL` 的说明
- 2.3 结果展示
- 2.4 另一种方法
- 三. 使用 `Spark-shell`
- 3.1 创建 2 个文本文件
- 3.2 打开 Spark-shell
- 3.3 查看进程和通过 web 查看应用程序运行情况
- 3.4 运行 `wordcount` 程序
- 3.5 登录hadoop102:4040查看程序运行
- 四. 提交流程
- 五. wordcount 数据流程分析

Local 模式就是指的只在一台计算机上来运行 Spark.
通常用于测试的目的来使用 Local 模式, 实际的生产环境中不会使用 Local 模式.
一. 解压 Spark 安装包
- 1. 把安装包上传到
/opt/software/
- 2. 把安装包上传到
/opt/module/
[bigdata@hadoop002 software]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module

- 3. 重命名为spark-local(为了方便复制一个并重新命名)
[bigdata@hadoop002 module]$ cp -r spark-2.1.1-bin-hadoop2.7 spark-local

- 4. 注意
如果有权限问题,可以修改为root,方便学习时操作,实际中使用运维分配的用户和权限即可。
chown -R root /opt/module/spark-local
chgrp -R root /opt/module/spark-local
- 5. 解压目录说明
bin 可执行脚本
conf 配置文件
data 示例程序使用数据
examples 示例程序
jars 依赖 jar 包
python pythonAPI
R R 语言 API
sbin 集群管理命令
yarn 整合yarn需要的文件
二. 运行官方求PI的案例
[bigdata@hadoop002 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
注意:
如果你的shell是使用的zsh, 则需要把local[2]加上引号:'local[2]'
说明:
使用spark-submit来发布应用程序.
2.1 spark-submit语法
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
- –
master指定master的地址,默认为local. 表示在本机运行. - –
class你的应用的启动类 (如org.apache.spark.examples.SparkPi) - –
deploy-mode是否发布你的驱动到worker节点(cluster模式) 或者作为一个本地客户端 (client模式) (default: client) - –
conf: 任意的 Spark 配置属性, 格式key=value. 如果值包含空格,可以加引号"key=value" application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,
如果是file:// path, 那么所有的节点的path都包含同样的jarapplication-arguments: 传给main()方法的参数- –
executor-memory 1G指定每个executor可用内存为1G - –
total-executor-cores 6指定所有executor使用的cpu核数为6个 - –
executor-cores表示每个executor使用的cpu的核数
2.2 关于 Master URL 的说明
| Master URL | Meaning |
|---|---|
local |
Run Spark locally with one worker thread (i.e. no parallelism at all). |
local[K] |
Run Spark locally with K worker threads (ideally, set this to the number of cores on your machine). |
local[*] |
Run Spark locally with as many worker threads as logical cores on your machine. |
spark://HOST:PORT |
Connect to the given Spark standalone cluster master. The port must be whichever one your master is configured to use, which is 7077 by default. |
mesos://HOST:PORT |
Connect to the given Mesos cluster. The port must be whichever one your is configured to use, which is 5050 by default. Or, for a Mesos cluster using ZooKeeper, use mesos://zk://… To submit with --deploy-mode cluster, the HOST:PORT should be configured to connect to the MesosClusterDispatcher. |
yarn |
Connect to a YARNcluster in client or cluster mode depending on the value of --deploy-mode. The cluster location will be found based on the HADOOP_CONF_DIR or YARN_CONF_DIR variable. |
2.3 结果展示

2.4 另一种方法
也可以使用run-examples来运行
[bigdata@hadoop002 spark-local]$bin/run-example SparkPi 100
三. 使用 Spark-shell
Spark-shell 是 Spark 给我们提供的交互式命令窗口(类似于 Scala 的 REPL)
本案例在 Spark-shell 中使用 Spark 来统计文件中各个单词的数量.
3.1 创建 2 个文本文件
mkdir input
cd input
touch 1.txt
touch 2.txt


3.2 打开 Spark-shell
[bigdata@hadoop002 spark-local]$ bin/spark-shell
3.3 查看进程和通过 web 查看应用程序运行情况

- 地址: http://hadoop002:4040


3.4 运行 wordcount 程序
scala> sc.textFile("./input").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect

3.5 登录hadoop102:4040查看程序运行
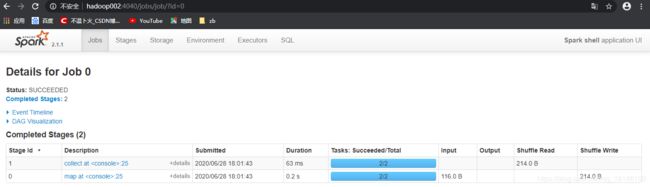
四. 提交流程
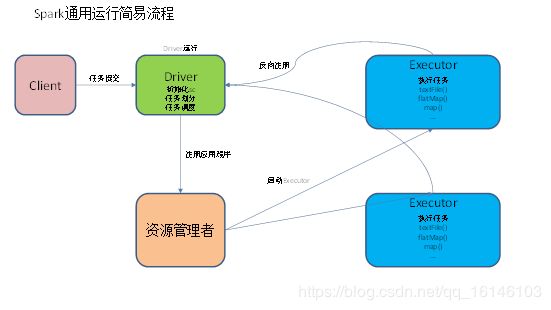

五. wordcount 数据流程分析
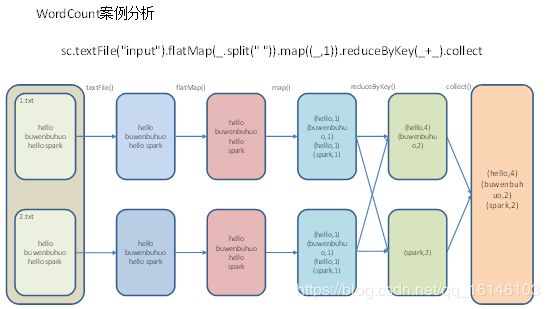

textFile("input"):读取本地文件input文件夹数据;flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;map((_,1)):对每一个元素操作,将单词映射为元组;reduceByKey(_+_):按照key将值进行聚合,相加;collect:将数据收集到Driver端展示。
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

