vmware14+centos7+hadoop2.9+jdk8 搭建记录
1 vmware三个虚拟机创建,设置ip
创建虚拟机没什么可说的,放个图,安装包官网都有

成功后,centos7默认不联网,以centos1为例设置
vi /etc/sysconfig/network-scripts/ifcfg-ens33其中有一项,设置为yes
ONBOOT=yes完成后点击esc,然后输入:wq保存
重启network
service network restartip addr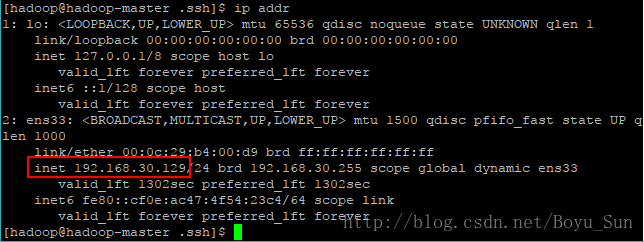
这里是虚拟机的ip地址
2 jdk安装,hadoop安装(三个虚拟机分别执行)
获得了三个虚拟机的ip之后,winSCP链接(用什么链接工具都可以,反正放弃vmware自带的shell界面,太坑了)
opt下创建了两个文件夹,back和softwares,back放安装包,softwares是安装目录
把jdk和hadoop的压缩包分别传入三个虚拟机里
进入/opt/softwares,执行
tar -zxvf /opt/softwares/jdk-8u151-linux-x64.tar.gz
tar -zxvf /opt/softwares/hadoop-2.9.0.tar.gz
3 环境设置(三个虚拟机分别执行)
3.1配置jdk和hadoop环境变量
vi /etc/profile
#Java
export JAVA_HOME=/opt/softwares/jdk1.8.0_151
export PATH=$PATH:$JAVA_HOME/bin
#Hadoop
export HADOOP_HOME=/opt/softwares/hadoop-2.9.0
export PATH=$PATH:$HADOOP_HOME/binalias tohd='cd /opt/softwares/hadoop-2.9.0/'
使配置生效
source /etc/profile
java -version
hadoop version3.2设置hosts
vi /etc/hosts
192.168.30.129 master
192.168.30.130 server1
192.168.30.131 server2
3.3设置防火墙
取消master的防火墙,或者把所有hadoop用到的端口开放,我是直接取消防火墙了
3.4创建hadoop用户
useradd hadoop
passwd 123456如果提示密码太简单,则再输入一回密码就好了
chown -R hadoop.hadoop /opt
3.5 设置主机名
hostnamectl set-hostname 主机名我三台虚拟机设置的分别是master(namenode的机器,管理机),server1,server2
4 ssh免密设置
master作为管理服务器,需要连接server1和server2时候做到无密码连接,所有需要公钥认证。在master上生成公钥私钥,
然后把公钥放在server1和server2上,并且放在授权列表里,就可以实现无密码登录。
此处操作全部使用hadoop用户
4.1 master服务器操作
生成秘钥
cd /home
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsassh-keygen 生成秘钥
-t rsa 设置秘钥类型为rsa秘钥
-P 无密码
-f 生成的密钥文件
执行命令后一路回车就行,/home/hadoop/.ssh目录下会生成id_rsa.pub(公钥)和id_rsa(私钥)两个文件。
加入信任列表
cd hadoop/.ssh
cat id_rsa.pub >> authorized_keysauthorized_keys这个文件就是ssh信任的公钥文件。
设置.ssh文件夹权限和authorized_keys文件权限
chmod 700 .ssh
chmod 600 .ssh/authorized_keys4.2 server1和server2进行设置(以server1为例,server2同样操作)
master服务器上,/home/hadoop/.ssh下执行命令
把id_rsa.pub文件放入server1中
scp id_rsa.pub hadoop@server1:/home/hadoop进入server1服务器,/home/hadoop下 ,创建.ssh文件夹
ssh hadoop@server1
cd /home/hadoop
mkdir .ssh
cd .ssh把id_rsa.pub公钥放入hadoop用户信任列表
cat id_rsa.pub >> .ssh/authorized_keyschmod 700 ../.ssh
chmod 600 authorized_keys
ssh server1
ssh server2如果不需要输入密码,那就证明成功了
5.设置hadoop配置文件
首先进入master服务器/opt/softwares/hadoop-2.9.0w/etc/hadoop/位置
需要修改的文件有以下几个
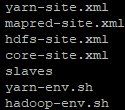
伪分布模式的话只需要修改hadoop-env.sh,core-site.xml,hdfs-site.xml,我没有试过,直接采用完全分布
5.1 hadoop-env.sh
配置JAVA_HOME指向jdk安装路径

5.2yarn-env.sh
同样配置JAVA_HOME
![]()
5.3slaves
写入两个node节点的名字

5.4core-site.xml
hadoop.tmp.dir
file:/opt/softwares/hadoop-2.9.0/temp
hadoop的运行临时文件的主目录
fs.default.name
hdfs://master:9000
HDFS的访问路径
dfs.replication
1
文件block的副本数
dfs.http.address
master:50070
dfs.namenode.secondary.http-address
master:50090
dfs.namenode.name.dir
file:/opt/softwares/hadoop-2.9.0/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/softwares/hadoop-2.9.0/tmp/dfs/data
mapred.job.tracker
master:9001
mapred.map.tasks
20
mapred.reduce.tasks
4
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
5.7 yarn-site.xml
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.webapp.address
master:8088
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
此时所在目录为/opt/softwares/hadoop-2.9.0/etc/hadoop,执行命令
scp * hadoop@server1:/opt/softwares/hadoop-2.9.0/etc/hadoop
scp * hadoop@server2:/opt/softwares/hadoop-2.9.0/etc/hadoop6.验证(在master上执行)
进入hadoop根目录,执行命令,格式化namenode,无报错代表执行成功
bin/hdfs namenode -format
sbin/start-dfs.sh
启动yarn
sbin/start-yarn.sh
查看集群状态
bin/hdfs dfsadmin –report