HashMap源码分析、及HashMap的容量为什么是2的n次幂?
JDK1.7中多线程操作hashMap的ReHash的时候,会出现HashMap Infinite Loop(死循环)问题。具体问题分析参考: HashMap死循环问题解析。
JDK1.8的HashMap的数据结构如下图 :
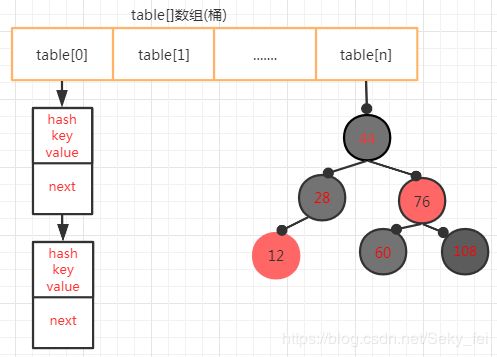
HashMap结构主要具有以下特点:
-
(1)HashMap通常会用一个指针数组(桶table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个
-
(2)如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么hash碰撞非常频繁,链表就会变长,于是由一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷。在JDK1.8中引入了红黑树优化过长的链表的缺陷。
-
(3)在于 JDK 1.8 中引入了红黑树,底层数据结构是 数组+链表 变为了 数组+链表+红黑树 的组合。同一个桶table[i]上链表的长度决定了是否转为红黑树结构。
1.hashMap的push过程
- (1)hashMap初始化后调用push添加值时,如果初始化没有指定的initialCapacity(初始容量)在push方法里会调用resize()方法进行初始化table[],初始容量默认大小是16。
- (2)key的hash计算:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hashMap是通过key的hashCode的高16位和低16位异或后,再跟 桶的数量取模 得到索引位置,即key.hashcode()^(hashcode>>>16)%length, 当length是2^n时,h&(length-1)运算等价于h%length,
而&操作比%效率更高。hash采用高16位和低16位进行异或,也可以让所有的位数都参与越算,使得在length做到尽量的散列。在扩容的时候,如果length每次是2^n,那么重新计算出来的桶位置只有两种情况,
一种是old索引+16,另一种是索引不变,所以就不需要每次都重新计算索引。
#说明: 寻找桶的index位置 key.hash&(length-1)运算等价于key.hash%length。- (3)push或get时计算桶table[]的位置: table[key.hash & (length-1)]取key的哈希值与桶的长度进行取模%运算,找到对应数组的下标。hashMap允许key为null,但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap使用第0个桶存放键为 null 的键值对。
#注意: push操作找到table[]桶的位置index后,会遍历该位置上的链表将新加元素加入到链表最后。- (4)自动扩容: 当桶table[]的size达到threshold(阈值)时,会调用resize()方法进行自动扩容。HashMap按当前桶数组长度的2倍进行扩容,阈值也变为原来的2倍,扩容之后,要重新计算key键值对的位置,并把所有的node移动到合适的位置上去。
#阈值的计算方式是:threshold(阈值) = capacity(容量) * loadFactor(负载因子)
1.容量capacity默认是16
2.负载因子loadFactor默认是0.75
#注意:桶table[]使用2次幂的扩展(指长度扩为原来2倍),原因是减少链表上元素的移动代价。因为按二次幂进行扩展,链表上元素的位置要么是在桶的原位置,要么在桶原位置再移动2次幂的位置。- (5)在JDK1.8中如果一个桶里链表长度到达阀值8,且tab.length>=64时,就会将链表转换成红黑二叉树。
在桶里链表长度到达8阀值时会调用treeifyBin()方法转红黑树, 但时在treeifyBin()方法中会判断table的长度是否大于64, 大于才转红黑树,小于64时就resize()扩容)
- (6)rehash问题
Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算、移动一遍,这个成本相当的大。
2.HashMap容量为什么是2的n次幂?
-
1.减少hash碰撞,避免形成链表的结构,使得查询效率降低.
-
2.减少链表上元素移动代价。因为按二次幂进行扩展,链表上元素的位置要么是在桶的原位置,要么在原索引+oldCap位置上, 这个和扩容机制有关。
(1)减少hash碰撞
HashMap的容量为什么是2的n次幂,这个和HashMap的index计算有着千丝万缕的关系。HashMap采用hash&(length- 1) 的计算方法来代替 hash%length取模运算,符号&是按位与的计算,这是位运算,计算机能直接运算,特别高效,按位与&的计算方法是,只有当对应位置的数据都为1时,运算结果也为1。当HashMap的容量是2的n次幂时,(length-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
#巧妙的思路: hash&(length- 1) 取代 hash%length取模运算,这种取代运算有个前提是HashMap的容量是2的n次幂
hash%length取模的值永远是最后一位十进制数, 一个十进数制换算成二进制永远在[00000 - 01111]之间,当HashMap的容量是2的n次幂时,(length-1)的2进制后四位永远是1111,在和hash进行&运算得到数据换算成十进制时, 最后一位就是hash本身最后一位。当HashMap的容量是16时,它的二进制是10000,(length-1)的二进制是01111,与不同的hash值得计算结果如下:

#上面四种情况我们可以看出,不同的hash值和(length-1)进行位运算后,能够得出不同的值,使得添加的元素能够均匀分布在集合中不同的位置上,避免hash碰撞。接下来就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(length-1)的二进制是01001 向里面添加同样的元素,结果为:

可以看出,当容量不是2的n次幂, 有三个不同的元素进过&运算得出了同样的结果,严重的hash碰撞了。
总结:
- (1)HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;另外HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成长链表的结构,使得查询效率降低。
- (2)因为2的幂减1都是11111结尾的,所以碰撞几率小。
(2)减少链表上元素移动代价
JDK.8中HashMap的扩容机制按2次幂的扩展(每次扩容为原来2倍),会出现原来链表上元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置(原索引+oldCap)。如下图,扩容前的key1和key2确定的索引位置 和 图扩容后key1和key2确定索引位置,可以看出扩容后只有key2的索引位置发生变化, 且变为原索引+oldCap。

如上图,扩容前和扩容后index的位置只需要判断新增的bit位(第5位)是否为0,就可以知道扩容后index的值是否变化,计算方式:(e.hash & oldCap)==0 ,其中oldCap是16,即(01 0000)&oldCap==0。JKD1.8中在扩容后不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit位 和 元素hash值 & 操作判断是否需要移动,如果需要移动的话索引变成 “原索引+oldCap”。
3.源码分析
(1)JKD1.8的resize()源码
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else {
//开始移动j桶里的链表
//loHead和loTail分别指向不需要移动元素组成链表的头和尾
Node loHead = null, loTail = null;
//hiHead和hiTail分别指向需要移动元素组成链表的头和尾
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
//通过新增的那个bit位判断是否需要移动元素
if ((e.hash & oldCap) == 0) {
//不需要移动元素组装成链表,loHead和loTail指向头和尾
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}else {
//需要移动元素组装成链表,hiHead和hiTail指向头和尾
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//不需要移动的元素桶位置不变:原来桶j位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//需要移动的元素桶的位置变为:原来桶j位置 + oldCap
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
} 2次幂设计很巧妙,既省去了重新计算hash值的时间,而且同时减少了移动代价。这一块就是JDK1.8新增的优化点。
注意区别:
(1)JDK1.7中rehash的时候,需要重新计算hash值。
(2)旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但JDK1.8不会倒置。
JDK1.8中hashMap容量由16扩充为32的resize示意图

(2)链表转换为红黑树
链表转换为红黑树的最终目的,是为了解决一个桶table[index]上的链表过长,导致读写效率降低的问题。在添加元素源码的putVal方法中,有关链表转红黑树结构化的代码为:
//此处遍历链表
for (int binCount = 0; ; ++binCount) {
//遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//链表转红黑树逻辑
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
注意:触发链表转红黑树的条件: 一个桶里链表长度到达阀值8 且 tab.length>=64(table桶的长度大于64)。
(3)红黑树转换为链表
基本思想是当红黑树中的元素减少并小于一定数量时,会切换回链表。而元素减少有两种情况:
- (1)调用map的remove方法删除元素:通过判断红黑树根节点及其子节点是否为空来确定是否转链表。
- (2)resize时对红黑树进行拆分:当红黑树节点元素小于等于UNTREEIFY_THRESHOLD(默认值6)时,才调用untreeify方法转换回链表。
#(1)remove()方法删除元素:判断是否要解除红黑树的条件
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
#(2)resize时对红黑树进行拆分:红黑树节点元素小于等于UNTREEIFY_THRESHOLD(默认值6)时,转链表。
//在这之前的逻辑是将红黑树每个节点的hash和一个bit进行&运算,
//根据运算结果将树划分为两棵红黑树,lc、hc表示其中一棵树的节点数
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}(4)HashMap遍历原理
对于HashMap遍历,我们一般都会用下面两种方式:
#(1)key集合遍历
for(Object key : map.keySet()) {
// do something
}
#使用HashMap的 key 集合行遍历时,上面代码片段中用 foreach 遍历 keySet 方法产生的集合,在编译时会转换成用迭代器遍历,等价于如下代码:
Set keys = map.keySet();
Iterator ite = keys.iterator();
while (ite.hasNext()) {
Object key = ite.next();
// do something
}
#(2)Entry集合遍历
for(HashMap.Entry entry : map.entrySet()) {
// do something
}
#使用HashMap的 Entry 集合进行遍历时,上面代码片段中用 foreach 遍历 Entry 方法产生的集合,在编译时会转换成用迭代器遍历,等价于如下代码:
Set entries = map.entrySet();
Iterator iterator = entries.iterator();
while (iterator.hasNext()){
//do something
}
#总结遍历原理:keySet()和entrySet()实际返回的是一个迭代器,在遍历的时候才会调用自己的iterator()方法。 对 HashMap 进行遍历时,遍历结果的顺序 和 插入的顺序一般都是不一致的。产生上述行为的原因主要是keySet() 和 entrySet()方法中对迭代器的iterator()方法实现原因. 下面以keySet()为例:
//1.keySet()方法源码:首次初始keySet使用new KeySet()
public Set keySet() {
Set ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
//2.在keySet类中迭代器的实现
public final Iterator iterator() { return new KeyIterator(); }
//3.KeyIterator迭代器:
final class KeyIterator extends HashIterator implements Iterator {
public final K next() { return nextNode().key; }
}
//4.new一个对象的时候,找到table[]桶里第一个不为null的位置, 是在父类HashIterator构造器里实现的
abstract class HashIterator {
Node next; // next entry to return
Node current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) {
//寻找第一个包含链表节点引用的桶
do {} while (index < t.length && (next = t[index++]) == null);
}
}
//寻找下一个桶位置和遍历桶里的链表操作
final Node nextNode() {
Node[] t;
Node e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//遍历当前桶(current)里的链表
if ((next = (current = e).next) == null && (t = table) != null) {
//寻找下一个包含链表节点引用的桶位置
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
//其他代码
}
//总结: 调用方法keySet(),entrySet()或values()时,实际返回的都是迭代器,实际的操作是对迭代器进行的. 如上面的源码,遍历所有的键时,首先要获取键集合KeySet对象,然后再通过 KeySet 的迭代器KeyIterator进行遍历。KeyIterator 类继承自 HashIterator 类,核心逻辑也封装在 HashIterator 类中。在初始化时,HashIterator 先从桶数组中找到包含链表节点引用的桶, 然后对这个桶指向的链表进行遍历。遍历完成后,再继续寻找下一个包含链表节点引用的桶,找到继续遍历。找不到,则结束遍历。
举个例子,我们向map添加如下的数据
//测试代码如下: JDK1.8 桶位置 key%length
@Test
public void testLinkedHashMap(){
HashMap map = new HashMap<>();
map.put(7, "");
map.put(11, "");
map.put(43, "");
map.put(59, "");
map.put(19, "");
map.put(3, "");
map.put(35, "");
System.out.println(map.keySet());
}
//输出
[19, 3, 35, 7, 11, 43, 59]
//HashMap是无序的,插入元素的顺序和遍历访问的顺序不一样。 数据添加完后, 得到如下的HashMap结构, 需要遍历下图的结构:
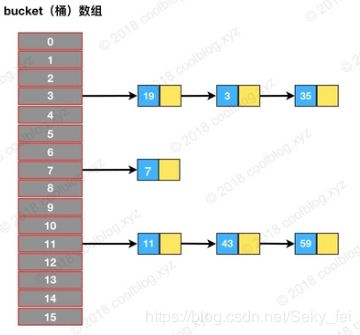
HashIterator 在初始化时,会先遍历桶数组,找到包含链表节点引用的桶,对应图中就是3号桶。随后由 nextNode 方法遍历该桶所指向的链表。遍历完3号桶后,nextNode 方法继续寻找下一个不为空的桶,对应图中的7号桶。之后流程和上面类似,直至遍历完最后一个桶。以上就是 HashIterator 的核心逻辑的流程,对应下图:

注意:上面例子的输出是在预计范围内的, table[]中每个桶的链表长度没有超过8,链表不会变成红黑树。在 JDK 1.8 版本中,为了避免过长的链表对 HashMap 性能的影响,特地引入了红黑树优化性能。当链表的长度大于8时链表就会转红黑树,遍历就会按红黑树相关逻辑遍历. 如下代码:
@Test
public void testHashMap(){
HashMap map = new HashMap<>();
map.put(7, "");
map.put(11, "");
map.put(43, "");
map.put(59, "");
map.put(19, "");
map.put(3, "");
map.put(35, "");
map.put(67, "");
map.put(83, "");
map.put(102, "");
map.put(118, "");
map.put(134, "");
map.put(150, "");
System.out.println(map.keySet());
}
#输出:
遍历结果:
[3,35,67,102,134,7,11,43,19,83,118,150,59]
#注意: table[3]桶位置元素有 3, 19, 35, 67, 83, 102, 118, 134, 150 触发该桶转链表转红黑树方法treeifyBin(),但实际是没有进行红黑树转换的,因为treeifyBin()方法中会判断table.length是否大于64.
#1).table.length < 64: resize()扩容
#2).table.length >= 64: 链表转红黑树 4.HashMap多线程问题
public class TestStream extends Thread{
private static Map map = new HashMap();
private static AtomicInteger at = new AtomicInteger(0);
@Override
public void run() {
while(at.get() < 1000000){
map.put(at.get(), at.get());
at.incrementAndGet();
}
}
public static void main(String[] args) {
for(int i=0;i<20;i++){
Thread thread = new TestStream();
thread.start();
}
}
}
#注意:
#(1)jdk1.7版本中多线程同时对HashMap扩容时,会引起链表死循环,尽管jdk1.8修复了该问题,但是同样在jdk1.8版本中多线程操作hashMap时仍然会引起死循环,只是原因不一样, jdk1.8再进行TreeNode操作时无法退出for循环。
#(2)在多线程下不要使用HashMap,至少jdk8及其以下不要使用,之上版本也建议不要使用。 上面代码多线程操作hashMap时, 会出现死循环问题,导致CPU使用率较高。使用jstack查看线程的堆栈信息发现Thread-0一直处于RUNNABLE无法退出, 一直在执行hashMap的resize操作。

JDK1.8和1.7中HashMap的变化 :
- (1)最大的区别在于JDK1.8中hashMap加入了红黑树。
- (2)jdk1.7版本中多线程同时对HashMap扩容时,会引起链表死循环,尽管jdk1.8修复了该问题,但是同样在jdk1.8版本中多线程操作hashMap时仍然会引起死循环,只是原因不一样,jdk1.8再进行TreeNode操作时无法退出for循环。
- (3)扩容时,jdk1.8不需要再计算hash值,只需要根据扩容后的最高bit为进行判断;jdk1.7中会进行rehash操作,且旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但JDK1.8不会倒置。
2020年07月02日 早 于北京记