漫谈分布式系统(11) -- 达成共识就是一致
这是《漫谈分布式系统》系列的第 11 篇,预计会写 30 篇左右。每篇文末有为懒人准备的 TL;DR,还有给勤奋者的关联阅读。扫描文末二维码,关注公众号,听我娓娓道来。也欢迎转发朋友圈分享给更多人。
共识
上一篇,我们大致介绍了 2PC、3PC 等分布式事务的实现。这些算法基本能提供强一致性,但对于网络分区却无能为力。
这篇,我们就一起看下,有没有具备分区容忍性(Partition Tolerance)的算法。
当出现网络分区后,要防止出现一致性问题,从 CAP 定理可知,只能放弃可用性。
当网络发生分区后,各分区内都可以独立运转,并且都会继续处理外部请求。
为了尽可能地保留整体可用性,两害相权取其轻,应该放弃掉节点数较少的分区。
每个分区都不知道其他分区的情况,为了保证整体最大可用性,获胜的分区需要多于整体一半的节点数。
同时,从解决数据冲突的角度看,只有当至少有一个节点能同时接收到相互冲突的数据时,才有可能发现冲突。数学告诉我们,必须覆盖超过一半的节点。
以上推导,就得到了具备分区容忍性的强一致性算法。
反过来,再总结下这类算法的共性:
节点总数必须是奇数 n。
数据成功发送给至少 (n/2 + 1) 个节点后,认为提交成功。
发生网络分区后,节点数多余 (n/2 + 1) 的分区(可以没有,则整个系统暂停)继续工作,其他分区暂停服务。
到这里,我们要引出一个新的概念 -- 共识(Consensus)。
所谓共识,顾名思义,就是指多个节点都认同某件事。比如集群内所有节点都把一个变量的值从 3 改为 5。
广义来说,上一篇讲的 2PC、3PC 也算是共识算法,包括比特币等虚拟货币也使用了共识算法。狭义来说,这篇文章下面要讲的 Paxos、Raft 等是更典型的共识算法。
思考一个问题,共识和数据一致性有什么区别?
二者很像,很多场合甚至可以互换,但我们可也以体会到细微的区别:
数据一致性,更像结果和目标,是系统理想的状态,但不定义怎么达到这个状态。
共识,也是结果和目标,但还包含了达到一致这个状态的通用方法,也就是投票表决(2PC 相当于全票通过,Paxos 相当于少数服从多数)。
共识算法的应用场景非常广泛,当我们从引出的数据一致性的数据复制这个场景跳脱出来,站在投票表决这个共识算法的视角去看,共识无处不在:
leader 选举
分布式锁
成员判活
原子广播
......
当然,共识算法也不是万能的,常见的共识算法都选择不去解决所谓拜占庭将军问题(Byzantine Generals Problem),也就是有节点作弊的情况。由于共识算法通常应用于内部独立系统,这个前提通常也是可以接受的。
下面,我们就一起看下典型的共识算法。
Paxos
基本知识
首先是 Paxos,由 Leslie Lamport 在 1989 年提出,并于 1998 年正式发布。
Mike Burrows,Goolge 版 Paxos 实现 Chubby 的作者曾经说过:
There is only one consensus protocol, and that’s Paxos. All other approaches are just broken versions of Paxos.但 Paxos 却因其复杂性和难以理解被广为诟病,甚至作者本人后来都被问的不厌其烦,专门另写了篇《Paxos Made Simple》来介绍。
这里,我也不深入展开,感兴趣的可以去找原版论文查看细节。我们只看重点。
Paxos 通过对共识的本质分析,定义了几种角色,对它们的行为提出了一些约束条件,并逐渐分析和加强约束(P1 -> P1a; P2 -> P2a -> P2b -> P2c),得到了一个理论上可行的共识算法。
定义的 核心角色(其他辅助角色略去)是:
Proposer,发起提议。
Acceptor,对提议投票。
最终的 约束 是(看不懂先放过):
P1a:当且仅当 acceptor 没有回应过编号大于 n 的 prepare 请求时,acceptor 接受编号为 n 的提案。
P2c:如果一个编号为 n 的提案具有值 v,那么存在一个多数派,要么他们中所有人都没有接受编号小于 n 的任何提案,要么他们已经接受的所有编号小于 n 的提案中编号最大的那个提案具有值 v。
算法分为 两个阶段:
Phase 1
(a) Prepare 阶段,proposer 向 acceptors 发起 proposal(n, v),n 为全局唯一并(至少局部)递增的整数。
(b) Promise 阶段,acceptor 接收到 proposal 后,检查发现 n > 自己之前接受过的 proposal 编号,则接受当前 proposal 并在回复里带上上一次接受的 proposal 的信息,同时承诺不会再接受 < n 的任何 proposal。否则可以忽略这个请求。
Phase 2
(a) Accept 阶段,proposer 在接收到超过半数的肯定回复后,向 acceptors 发送请求 accept(n, v),其中 v 为准备阶段收到的回复中编号最大的值,如果没有,则使用自己第一阶段提议的值。
(b) Accepted 阶段,acceptor 接受请求后,检查 n,在不违背第一阶段承诺的前提,接受提交过来的新值。
典型过程
恐怕还是不好理解,我们看一个典型的例子就明白了(只做原理示例,并不和实际实现完全一致)。
设想 2 个 proposer 同时向 3 个 acceptor 发起 proposal 的情况。
第一阶段开始,A1、A2 和 A3 都保存有一个值为 1 的变量。
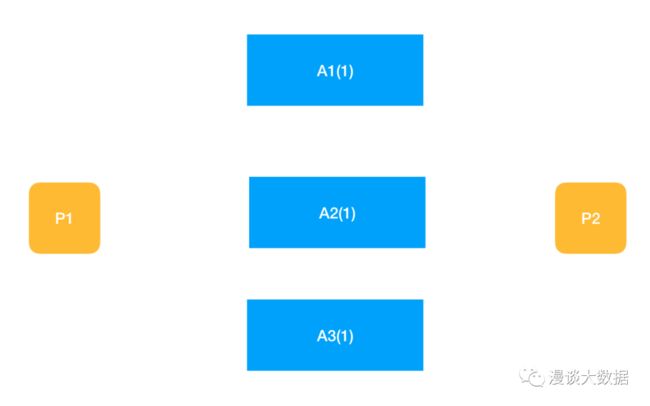
这个时候,P1 和 P2 都尝试修改这个变量的值。P1 获取了 n=1(希望设置值为 6),并向所有(或超半数) acceptor 广播。P2(希望设置值为 8)同时广播 n=2 出去。但由于网络传输的差异,P1 的请求率先到达了 A1 和 A2,P2 的请求率先到达了 A3,其余请求仍在途中。

按照约束,在这轮操作中,各 acceptor 都还没有接受过请求,于是 A1 和 A2 接受了prepare(n=1),A3 接受了 prepare(n=2)。这里的接受只是投票表决,并没有生效,所以变量的值仍是 1。
然后,各 acceptor 回复 proposer 的请求,应答内容为 (当前 n,此前接受过的最大 n,此前接受过的最大 n 对应的 v)。

P2 收到 A3 的 promise,不够一半数,只能继续等待。P1 收到 A1 和 A2 的 promise,超过半数,于是进入第二阶段。P1 向 A1 和 A2 发送 accept 请求,要求对方将变量值设置为 6。
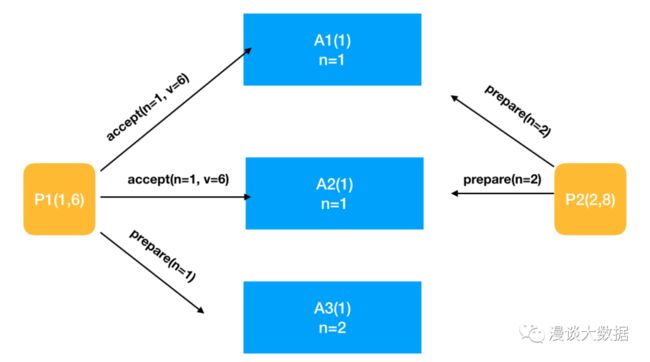
A1 和 A2 接到 accept 请求后,最约束检查,发现自己没有同意过任何请求,于是接受这个提议,将变量值设为 6,并返回 accepted 请求给 A1。
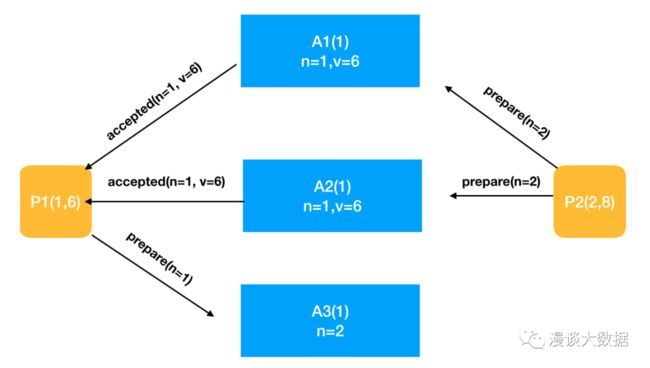
过了一段时间,在途中的 3 个请求终于到站。各 acceptor 仍然按照约束对比接收到的 n 和自己此前接受过的最大的 n。前者比后者大则接受,否则拒绝。
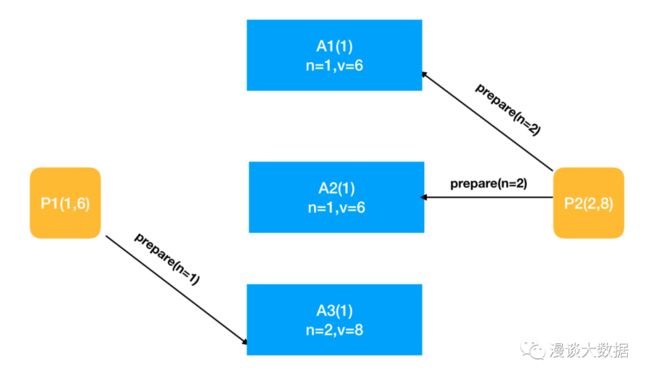
于是 A1 和 A2 返回 promise 给 P2,并告诉 P2 自己之前接受过其他请求,其中编号最大的是 (1, 6)。而 A3 拒绝了 P1 的请求(也可以直接忽略,P1 会认为请求丢失)。

P2 这时就收到 3 个 acceptor 的 promise 了,可以进入第二阶段。按照约束,发现 acceptor 已经接受过其他 proposer 的值的,于是采用这个值 6 ,而丢弃自己最初预想的值 8(这里其实可以考虑只给 A3 发请求,以提升性能)。
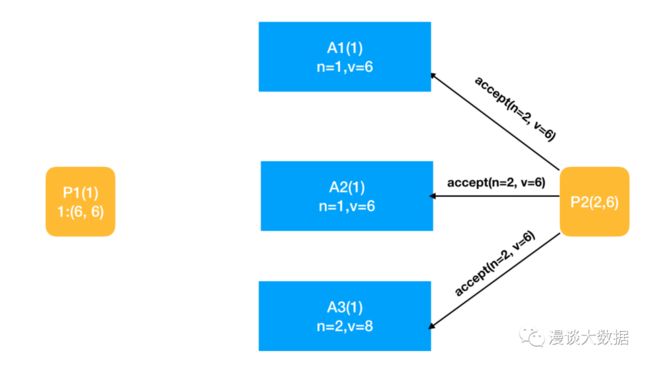
各 acceptor 收到 P2 的 accept 请求后,做约束判断,将自己的编号和值更新为 (2, 6)。
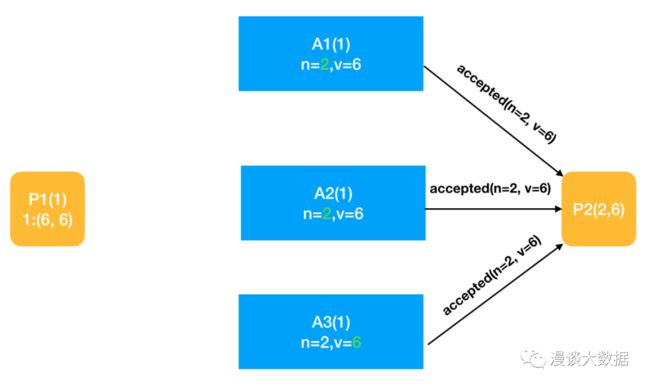
到这里,整个流程就结束了。
一些思考
一个值得注意的点是,按照 Paxos 约束的规定,P2 在得到了大多数投票后,并没有使用自己最初的值,而是使用了已经被大多数接受的 P1 的的值。
这是因为在 P2 准备发起表决的时候,P1 的值已经得到了更多的投票,直接用这个值有助于系统更快收敛以达成共识。这也是共识算法在哲学层面的优点:不要自私,要顾全大局,尽快向大多数人靠拢。
可以看到,第一阶段,只是决定了谁的提议会被接受(只是 prososer 还不知道),而具体提议是什么,是不确定的。到了第二阶段,才会正式提议。
过程中,可能有多个提议在同时表决,而决定谁的提议会最终达成共识的,不是谁的提议编号更大(虽然编号大小对各个约束起了很大作用),而是谁的提议更快被超过半数的节点接受。
另外,细心的朋友可能已经发现,Paxos 也是分成两个阶段,和 2PC 很像啊。那它们俩有什么区别?为什么 2PC 不能处理网络分区,而 Paxos 就可以?
关键在于几点:
Paxos 只需要超过半数的节点表决,而 2PC 需要所有节点表决。而网络分区发生时,是一定凑不齐所有节点的。
Paxos 支持有多个 proposer,而 2PC 只能有一个 Coordinator。一旦发生关键节点宕机,Paxos 可以正常运转,而 2PC 由于存在单点故障就阻塞了。
当然,前面也提过,Paxos 支持网络分区下的强一致性,也是付出了代价的 -- 丢失了部分可用性,依然逃不过 CAP 的约束。
Raft
Paxos 虽然实现了分布式共识,但不够完美,至少不够好用。
比如:
外部系统需要提供连续的输入,一轮轮去投票。
多个 proposer 可能同时发起表决,导致收敛变慢,还有可能发生所谓活锁一直阻塞的可能。
诸如此类的原因,再加上 Paxos 本身在理解和实现上的繁琐,有了很多改进和模仿者。
这其中有 Multi-Paxos、Fast Paxos、Raft、ZAB 等,我们以 Raft 为例介绍。
Raft 也做了其他改进算法大都采用的优化。其中,最重要的优化是:
定义新的角色 leader 和 follower 来区分 proposer,只有 leader 能发起 proposal,leader 故障后自动选举新的 leader。
这样一来,正常情况下,Paxos 协议的第一阶段可以直接省略,第二阶段由于只有一个 proposal,也会很快达成共识,整体性能就大大提升了。
下面我们也不详细介绍 Raft 的完整功能和流程,只以典型例子说明我们关心的典型场景。
leader election
Raft 节点通过心跳传递信息和探活。任何节点,如果心跳时间内,没有收到 leader 发过来的新的心跳,就可以发起投票尝试成为新的 leader。
典型的选举过程比较简单,就不赘述了。我们看看当出现竞争的情况会怎样。
如下图,很巧,Node A 和 D 同时向其他 3 个节点发起了投票,希望能成为新的 leader,而 Node 3 和 4 还在上一轮心跳中,没有触发选举。

如果 A 得到 B 的投票,而 D 得到 C 的投票,这个时候,算上自己的投票,A 和 D 就都手握两票,没有超过一半,也就都不能成为 leader。
但所有节点都已经投过票了,这轮选举已经结束,没有选不出 leader。
为了避免这种「活锁」的情况,每个 Candidate(Follower 发起选举后转换为这个角色)在发起新提议前都 随机 等待一小段时间。
随机性保证了同时发起投票的可能性足够低。这样,就算某一轮运气不好,碰到了上面的情况,也能很快重新选出新的 leader。

(所有 Raft 动图版权归属原作者,详细请点击文末阅读原文,查看完整的 Raft 流程介绍)
如上图,A 和 D 都没有获得超过半数,于是继续等待超时直至下一轮。但 B 却率先等完心跳进入了下一轮,然后发起投票,后面虽然 D 也苏醒过来,但 B 早已拿到超过半数投票,成为了新的 leader。
log replication
选举出 leader 后,就可以对外提供数据读写服务。
Raft 把这个过程称为 log replication。实际上也是通过心跳传输数据,然后投票。
常规的传输数据过程很简单,也不赘述,我们重点看下我们最关心的,发生网络分区时,是怎么达成共识的。
如下图所示,网络分成了两个分区:
A 和 B 在一个分区,其中 B 是分区发生前的 leader。
C、D 和 E 在另一个分区,C 得到 C、D、E 三票后,也被选举为 leader。

这是典型的网络分区 + 脑裂的情况。
然后,两个客户端分别向两个 leader 发出了请求。
上面的分区收到 SET 8 的请求,3 票到手,设置成功。这个分区具有完整的功能。
下面的分区收到 SET 3 的请求,只拿到 2 票,设置无法成功,相当于这个分区没了可用性。
这个状态会持续下去,所有发送到上面分区的请求都会成功,发到下面的都会失败。
直到网络分区被解决,两个分区融合。
如下图所示,B 很快通过 Term 知道自己已经 Out 了,于是退位成 Follower,然后唯一的 leader C 很快把 SET 8 同步给 A 和 B,让它们追上已经达成的共识。而之前的 SET 3 因为本就没有达成共识,就被丢弃了(客户端可以再重试)。
Term,或者在其他系统里叫 Epoch,是全局递增的整数,表示 leader 的任期。每轮新的选举都会导致 Term 加 1 。
可以看到,正式因为 Term 的存在,使得脑裂问题得到了妥善的解决。而 Term + 超过半数投票就很好的解决了网络分区下的数据一致性问题。
本质上来说,Raft 是降低了 Paxos 第一阶段的频率,在选举出 leader 后,任期内都直接进入第二阶段。只有任期结束的时候,才会执行完整的共识流程(包括一二阶段)选举出新的 leader。
再加上强制 follower 及时同步数据、只能投票给数据比自己新的 candicate 等更强的安全性(safety)保证,以及良好的 API 设计等,使得 Raft 得到了 etcd 等系统的广泛的使用。
和 Raft 类似,ZooKeeper 也实现了自己的共识协议 ZAB(ZooKeeper Aotomic Broadcast Protocol),被 HDFS、YARN、HBase、Kafka 等众多大数据组件采用。
限于篇幅,就不再赘述这些和主题关系不紧密的内容了。
TL;DR
共识算法,是数据强一致性的另一类通用算法,能提供分区容忍性支持
Paxos 是共识算法的始祖,核心思想是超过半数表决
但 Paxos 过于复杂和低效,于是产生了很多优化后的变种
Raft 作为典型的 Paxos 后代,通过新角色 leader 大大简化了达成共识的过程
这篇文章,引出了共识的概念,介绍了以 Paxos 和 Raft 为典型的共识算法,总算实现了我们期望的具备分区容忍性的强一致性。
但也可以看到,无论是上篇提到的 2PC,还是这篇提到的 Raft,作为预防型的强一致性算法,由于涉及多个节点间的协商,都一定程度上牺牲了性能。
同时,无论是 2PC 还是 Raft,也都不同程度地为了追求一致性,而丢失了可用性。
下篇文章开始,我们就一起了解下预防性强一致性算法之外的可能,看看先污染后治理的弱一致性算法,能不能解决性能和可用性问题,又能不能满足我们对数据一致性的追求。
关联阅读
漫谈分布式系统(9) -- 初探数据一致性
漫谈分布式系统(10) -- 初探分布式事务
原创不易
关注/分享/赞赏
给我坚持的动力
