1.为毛我要写这个?
效果图

蓝色字体都是通过正则判断出来的
公司要求作出这样的效果,过去真心没有接触过。最后通过正则判断出了要去高亮的文字,但是没办法一下子去删除#话题#,或者@李小龙,中国石油(111100)这样的特定的文字。最后没有通过正则的方式,但是很庆幸,UITextView中使用正则,确实帮我们判断出了那些文字要去高亮,并且他可以在微博列表页中大显身手.
2.什么是正则?
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。例如,我如何判断用户输入的手机号是不是正确?如何确定用户输入的邮箱是不是正确?
作用大概是两个:1.判断字符串是不是符合规则 2.过滤数据
3.基本概念
1.a-z a-z 26个小写字母
2.A-Z A-Z 26个大写字母
3.0-9 0-9之间的10个数字
4..(小数点) 匹配除了换行符以外的任意字符
5.\w 匹配除了字母或数字,下划线或者汉子
6.\s 匹配任意的空白符(包括空格,制表符(Tab),换行符,中文全角空格等)
7.\d 匹配数字
8.\b 匹配单词的开始或者结束
9.^ 匹配字符串的开始
10.$ 匹配字符串的结束
11.+ 重复一次或多次(量词)
12.? 重复零次或者一次(量词)
13.* 重复零次或者多次 (量词)
14.[],表示对一个数据进行匹配的内容(筛选范围)写在这里
4.写几个简单的正则
- 只能匹配
a5正则[a][5],[a]表示这一位置只能是a,[5],这一位置只能是5.如果第一位可以是abcd中任意一个那?[a-d]或者[abcd],前者是省略写法,后者是详细写法,所以a-z表示26个字母,就不难理解了.
/**
* 匹配 a5
*/
void test(){
NSString *str = @"e6";
NSString *pattern = @"a5"; //或者 [a][5],[a]5,a[5],如果这一位数据是确定的,那么我们就给他一个确定值就好,不用[]
//NSRegularExpression 正则的对象,他需要一个pattern(规则),NSRegularExpressionCaseInsensitive 是一个大小写敏感的意思(枚举)
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern
options:NSRegularExpressionCaseInsensitive
error:nil];
//NSMatchingReportCompletion 完全匹配,该方法是获取所有匹配成功的结果,是一个数组,所以判断count == 0,就知道了是不是匹配成功
/**
匹配出第一个符合正则的结果
*/
NSTextCheckingResult *r = [regex firstMatchInString:str
options:NSMatchingReportCompletion
range:NSMakeRange(0, str.length)];
/**
匹配符合正则的数量
*/
NSInteger count = [regex numberOfMatchesInString:str
options:NSMatchingReportCompletion
range:NSMakeRange(0, str.length)];
/**
匹配符合正则的数量,包括所有的NSTextCheckingResult 结果,一般使用第三个
*/
NSArray *results = [regex matchesInString:str
options:NSMatchingReportCompletion
range:NSMakeRange(0, str.length)];
if (results.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in results){
// NSLog(@"%@",NSStringFromRange(result.range));
NSLog(@"%@",[str substringWithRange:result.range]);
}
}else{
NSLog(@"匹配失败");
}
- 只能匹配
aH8(第一位大小写字母都行,第二位是大写,第三位是0-9) ..一定要注意,就是\d是转义字符(有特定的含义),其中\ 斜杠在正则中有特定的含义,所以在项目中(OC)中写,\\\ 才能得到一个\,所以你看到别人写的时候,可能为了给你看起来方便,很多地方只有一个 \,但是当你写oc代码的时候,还是要有\\\,否则无效,本文全都是\\\,避免带你走入误区.
/**
* aH8(第一位大小写字母都行,第二位是大写,第三位是0-9)
*/
void test(){
NSString *str = @"aH8";
NSString *pattern = @"[a-zA-Z][A-Z][0-9]"; //正则 `[a-zA-Z][A-Z][0-9]`或者`[a-zA-Z][A-Z]\\d`,后者`\d`表示是0-9.
//NSRegularExpression 正则的对象,他需要一个pattern(规则),NSRegularExpressionCaseInsensitive 是一个大小写敏感的意思(枚举)
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
//NSMatchingReportCompletion 完全匹配,该方法是获取所有匹配成功的结果,是一个数组,所以判断count == 0,就知道了是不是匹配成功
NSArray *results = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (results.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in results){
NSLog(@"%@",NSStringFromRange(result.range));
}
}else{
NSLog(@"匹配失败");
}
}
- 匹配
adc5,或者T8,或者uy1正则[a-zA-Z]+\\d, 这个[a-zA-Z]+的含义就是至少有一个,可以是多个英文字母,最后一位是数字
/**
* `adc5`,或者`T8`,或者`uy1`
*/
void test(){
NSString *str = @"uy1";
NSString *pattern = @"[a-zA-Z]+\\d";
//NSRegularExpression 正则的对象,他需要一个pattern(规则),NSRegularExpressionCaseInsensitive 是一个大小写敏感的意思(枚举)
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
//NSMatchingReportCompletion 完全匹配,该方法是获取所有匹配成功的结果,是一个数组,所以判断count == 0,就知道了是不是匹配成功
NSArray *results = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (results.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in results){
NSLog(@"%@",NSStringFromRange(result.range));
}
}else{
NSLog(@"匹配失败");
}
}
- 匹配一手机号 (第一位是1,第二位只能是356其中一个,后边随意)
正则1[356]\\\d{9}$.target13788889999
/**
* (第一位是1,第二位只能是356其中一个,后边随意)
1代表着这只能是1(并不是所有的这个位置都是[],如果使用了方括号,表示是个范围,没有范围,就直接写出来就行),
`[356]`表示只能是其中一个,
`\\d{9}`,表示0-9中的数字,必须有9位,如果是`{4}`,表示有4位.
单纯的`1[356]\\\d{9}`匹配`13788889999`是没有问题的,而且匹配`158999944443333`也是没有问题的(但这个不是一个手机号)
为什么?因为你没有指定目标文本(158999944443333)的匹配范围。
`1[356]\\\d{9}`表示,只要包含这个格式就行
^和$就是指定范围的,前者表示**匹配字符串的开始**. 后者表示**匹配字符串的结束**,
也就是说,当我们使用 `^1[356]\\\d{9}`匹配`158999944443333`是成功的,他从1开始匹配,只要前边匹配成功就好,后边的不管了,职匹配前边11位,
当我们使用 `1[356]\\\d{9}$`匹配`158999944443333`从后边11位开始匹配,结果肯定是错误的。这样就可以匹配出正确的手机号了
*/
void test(){
NSString *str = @"13788889999";
NSString *pattern = @"1[356]\\d{9}$“
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
NSArray *results = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (results.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in results){
NSLog(@"%@",NSStringFromRange(result.range));
}
}else{
NSLog(@"匹配失败");
}
}
- 从一个句子
@"his name is wangxin,hi,I am history"里匹配出一个单词hi(his不算)
void testHi(){
NSString *str = @"his name is wangxin,hi,I am history";
NSString *parttern = @"\\bhi\\b";
/**
* \b 是一个单词的钱或者是后,所以匹配一个单词 ,@"\\bhi\\b"; 两个斜杠,表示为了搞出一个\
*/
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:parttern options:NSRegularExpressionCaseInsensitive error:nil];
NSArray *matchArr = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (matchArr.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in matchArr){
NSLog(@"range %@",NSStringFromRange(result.range));
}
}else{
NSLog(@"匹配失败");
}
}
- 匹配一个qq号码,(5-12位)
void testQQ(){
NSString *str = @"1512424789712129";
/**
NSString *str = @"1594393897987987890923";
* @"\\d{5,7}",代表着对字符串截取,“1594393”,@“8979879” @“878909”,三个段位,776格式的
* 如果是@"\\d{4,5}",那么@“15943”,@“93897”,@“98798”,@“78909”,后三位不符合,直接放弃
* 如果是@"^\\d{2,9}"(重开头获取,只一次) 159439389,其他的符合也不要
* 如果是@"\\d{2,9}$"(冲后边可是去,只一次)987890923 其他的符合也不要
* 如果是@"^\\d{2,9}$";意思,重头到尾,至少是2<=x<=9那么都不符合,失败
*/
NSString *pattern = @"^\\d{5,12}$";
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
NSArray *results = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (results.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in results){
// NSLog(@"%@",NSStringFromRange(result.range));
NSLog(@"%@",[str substringWithRange:result.range]);
}
}else{
NSLog(@"匹配失败");
}
}
- 匹配
$a大打4 (234675)$
/**
* $a大打4 (234675)$,
"a大打4" 这个至少以为,最多4位,可以是汉子,a-z,A-Z,后边的数字是6位
"4" 和 "("之间有空格!!
*/
void testMu(){
NSString *str = @"$a213 123456$";
/**
* 1.$过去是匹配结尾,但是现在要去使用它,取消任何转义字符的时候,给他一个\就好,但是\也是一个转义字符,需要\\才行 \\$ 是 $的含义
2.\u4e00-\u9fa5 是所有汉字的区间,但是为了更有用,前边再给他一个\ 。\\u4e00-\\u9fa5
3.\\d 同理
4.空格符 给他一个空格代替
5.\\d{6} 六位数字
6.\\$同上
*/
NSString *pattern = @"\\$[a-zA-Z\\u4e00-\\u9fa5\\d]{1,4}空格符\\d{6}\\$";
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
NSArray *matchArr = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (matchArr.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in matchArr){
NSLog(@"range %@",NSStringFromRange(result.range));
}
}else{
NSLog(@"匹配失败");
}
}
*匹配句子中的[af个]
/**
* 1.实际开发中,我们经常要把[哈哈]提取出来,替换成我们的表情图片,然后通过富文本替换,我么现在就去提取出来
2.[ 是特殊转义字符,我们想把他匹配出来,使用\\[
3.[a-zA-Z0-9\\u4e00-\\u9fa5]+ 这个位置可能使用的东西3种,至少是一个
4.] 转义字符 \\]
*/
void testbiaqing(){
NSString *str = @"$aaaasz123456$[魏霞]regularExpress[1234]ionW[抚松]ith[23jkadfv懂]Pattern";
NSString *pattern = @"\\[[a-zA-Z0-9\\u4e00-\\u9fa5]+\\]";
NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:nil];
NSArray *matchArr = [regex matchesInString:str options:NSMatchingReportCompletion range:NSMakeRange(0, str.length)];
if (matchArr.count) {
NSLog(@"匹配成功");
for(NSTextCheckingResult *result in matchArr){
NSLog(@"%@",[str substringWithRange:result.range]);
}
}else{
NSLog(@"匹配失败");
}
}
//通过[str substringWithRange:result.range] 这个获取出[魏霞],[23jkadfv懂]等文字
5.介绍个第三方
在这里给大家介绍一个第三方 RegexKitLite,专业正则8年哈,但是他是MRC的,所以给大家介绍一下如何集成到项目中
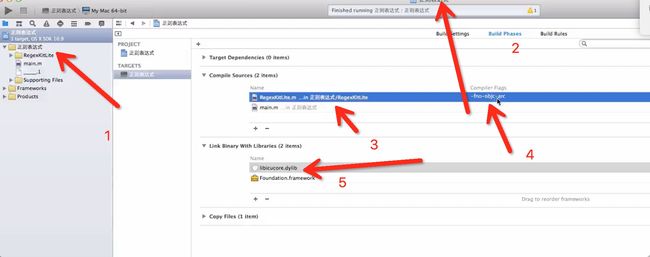
集成RegexKitLite,建议百度一下,封装的非常好,简化了很多的方法,正的,相信我,你用的到

另一种方法
6.首尾那两个字符是表示匹配 去掉表示包含意思(三张图片)
首尾那两个字符是表示匹配 去掉表示包含意思 ^adg$ 和 adg的区别
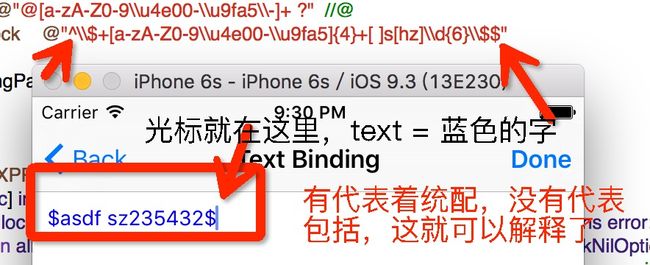
解释1

解释2
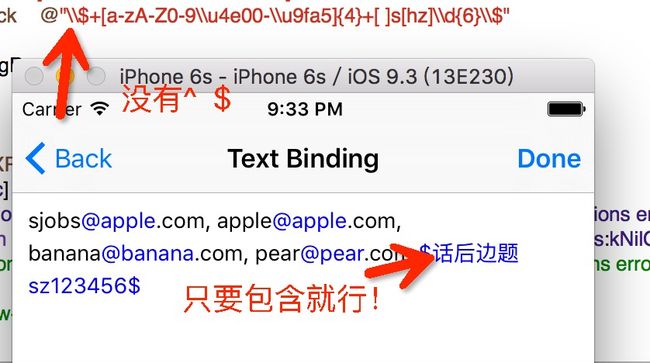
解释3
7.特别鸣谢
参考好文章