Elasticsearch:pipeline aggregation 介绍
首先,我们来假想有这样的一个表格:
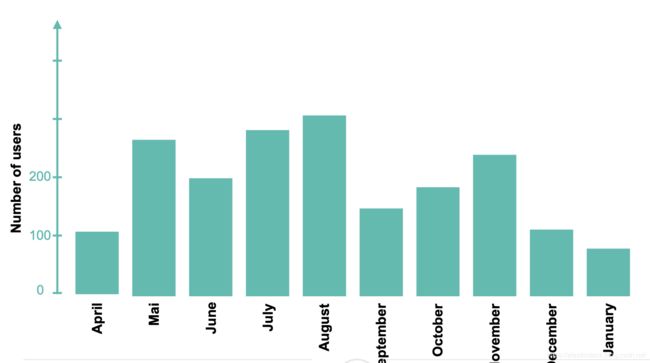
上面的表格里显示了每一个月的用户数量,但是我们如何能得到如下的信息呢:
- 哪一个月的用户数是最大的?
- 从April到January的总的用户数是多少?

- 它们的平均用户数是多少?
- 每个月变化的值是多少?

所有的这些问题,我们都可以使用Pipeline aggregation来算出来,这是因为这些数据的统计需要用到它的parent或sibling级的聚合输出。
Pipeline aggregation用中文讲就是管道聚合。它工作于其他聚合而不是文档集所产生的输出,从而将信息添加到输出树中。与metric及bucket aggregation相比,管道聚合将处理其他聚合所产生的输出,这些输出将转换它们已经计算出的值。 因此,管道聚合适用于原始文档集中不存在的中间值。 这使得管道聚合对于计算复杂的统计和数学度量(例如累计和,导数和移动平均值等)非常有用。 管道聚合有很多不同类型,每种类型都与其他聚合计算不同的信息,但是可以将这些类型分为两类:
Parent
基于父级聚合的输出提供一组管道聚合,它可以计算新的存储桶或新的聚合以添加到现有存储桶中。导数和累积总和聚合是Elasticsearch中父管道聚合的两个常见示例
Sibling
同级聚合的输出提供的管道聚合,并且能够计算与该同级聚合处于同一级别的新聚合。
管道聚合需要一种访问父级或同级聚合的方法。 他们可以通过使用buckets_path参数来指示所需的聚合,该参数指示所需度量的路径。 您需要了解此参数的特殊语法:
AGG_SEPARATOR = `>` ;
METRIC_SEPARATOR = `.` ;
AGG_NAME = ;
METRIC = ;
MULTIBUCKET_KEY = `[]`
PATH = ? (, )* ( , ) ; 例如,路径"my_bucket>my_stats.avg"将指向"my_stats"指标中的avg值,该值包含在“my_bucket”存储桶聚合中。
应该注意的是,路径是相对于管道聚合位置而言的。 这就是为什么路径无法返回到聚合树“上”的原因。 例如,下面的derivative道聚合被嵌入到date_histogram中,并引用和他相邻的the_sum的metric。
curl -X POST "localhost:9200/traffic_stats/_search" -H 'Content-Type: application/json' -d'
{
"aggs": {
"total_monthly_visits":{
"date_histogram":{
"field":"date",
"interval":"month"
},
"aggs":{
"the_sum":{
"sum":{ "field": "visits" }
},
"the_derivative":{
"derivative":{ "buckets_path": "the_sum" }
}
}
}
}
}
'sibling管道聚合也可以放置在一系列存储桶的旁边,而不是“嵌入”在它们内部。 在这种情况下,要访问所需的指标,我们需要指定一个完整的路径,包括其父聚合:
curl -X POST "localhost:9200/traffic_stats/_search?size=0&pretty" -H 'Content-Type: application/json' -d'
{
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
}
}
},
"avg_monthly_visits": {
"avg_bucket": {
"buckets_path": "visits_per_month>total_visits"
}
}
}
}
'在上面我们的buckets_path定义为一个从aggs根开始的一个完整的父聚合的路径。在上面的示例中,我们通过其名为visits_per_month的父聚合date_histogram,引用了名为total_visits的同级聚合。 因此,目标汇总的完整路径为visits_per_month> total_visits。
另外,请务必记住,管道聚合不能包含子聚合。但是,某些管道聚合(例如derivative管道聚合)可以在其buckets_path中引用其他管道聚合。这允许链接多个管道聚合。例如,我们可以将两个一阶derivative链接在一起以计算二阶derivative(导数的导数)。
您还记得,指标和存储桶聚合使用“missing”参数来处理数据中的缺口。管道聚合使用gap_policy参数来处理文档不包含必填字段或没有文档匹配一个或多个存储桶查询的情况等。此参数支持以下gap_policies:
- skip-将丢失的数据视为存储桶不存在。如果启用了该策略,则聚合将跳过空存储桶,并使用下一个可用值继续进行计算。
- insert_zeros-用零替换所有丢失的值,并且管道计算将照常进行。
教程
在这个教程里,我们将使用本地部署的Elasticsearch来实践。如果你还没有安装好自己的Elasticsearch和Kibana的话,请参阅我之前的文章“Elastic:菜鸟上手指南”。
针对这个教程,我们将创建一个名为 traffic_stats的索引。它是关于博客文章的访问的文档数据。索引的mapping包括三个字段:date,visits及max_time_spent。
首先我们启动Kibana,首先我们建立好我们索引的mapping:
PUT traffic_stats
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "dateOptionalTime"
},
"visits": {
"type": "integer"
},
"max_time_spent": {
"type": "integer"
}
}
}
}接下来,我们使用bulk API来把我们的数据导入到Elasticsearch去:
PUT _bulk
{"index":{"_index":"traffic_stats"}}
{"visits":"488", "date":"2018-10-1", "max_time_spent":"900"}
{"index":{"_index":"traffic_stats"}}
{"visits":"783", "date":"2018-10-6", "max_time_spent":"928"}
{"index":{"_index":"traffic_stats"}}
{"visits":"789", "date":"2018-10-12", "max_time_spent":"1834"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1299", "date":"2018-11-3", "max_time_spent":"592"}
{"index":{"_index":"traffic_stats"}}
{"visits":"394", "date":"2018-11-6", "max_time_spent":"1249"}
{"index":{"_index":"traffic_stats"}}
{"visits":"448", "date":"2018-11-24", "max_time_spent":"874"}
{"index":{"_index":"traffic_stats"}}
{"visits":"768", "date":"2018-12-18", "max_time_spent":"876"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1194", "date":"2018-12-24", "max_time_spent":"1249"}
{"index":{"_index":"traffic_stats"}}
{"visits":"987", "date":"2018-12-28", "max_time_spent":"1599"}
{"index":{"_index":"traffic_stats"}}
{"visits":"872", "date":"2019-01-1", "max_time_spent":"828"}
{"index":{"_index":"traffic_stats"}}
{"visits":"972", "date":"2019-01-5", "max_time_spent":"723"}
{"index":{"_index":"traffic_stats"}}
{"visits":"827", "date":"2019-02-5", "max_time_spent":"1300"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1584", "date":"2019-02-15", "max_time_spent":"1500"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1604", "date":"2019-03-2", "max_time_spent":"1488"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1499", "date":"2019-03-27", "max_time_spent":"1399"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1392", "date":"2019-04-8", "max_time_spent":"1294"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1247", "date":"2019-04-15", "max_time_spent":"1194"}
{"index":{"_index":"traffic_stats"}}
{"visits":"984", "date":"2019-05-15", "max_time_spent":"1184"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1228", "date":"2019-05-18", "max_time_spent":"1485"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1423", "date":"2019-06-14", "max_time_spent":"1452"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1238", "date":"2019-06-24", "max_time_spent":"1329"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1388", "date":"2019-07-14", "max_time_spent":"1542"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1499", "date":"2019-07-24", "max_time_spent":"1742"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1523", "date":"2019-08-13", "max_time_spent":"1552"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1443", "date":"2019-08-19", "max_time_spent":"1511"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1587", "date":"2019-09-14", "max_time_spent":"1497"}
{"index":{"_index":"traffic_stats"}}
{"visits":"1534", "date":"2019-09-27", "max_time_spent":"1434"}
太好了!我们现在有27个数据了。 已经完全准备好展示管道聚合的示例。 让我们从avg bucket聚合开始。
Avg Bucket Aggregation
Avg Bucket Aggregation道是sibling管道聚合的典型示例。它处理由另一个同级聚合计算的数值,并计算所有存储桶的平均值。对sibling聚合的两个要求是sibling聚合必须是多存储桶聚合,并且指定的指标是数字。
为了了解管道聚合的工作原理,将计算过程分为几个阶段是合理的。让我们看一下下面的查询。它将分三个步骤进行。首先,Elasticsearch将创建一个间隔为一个月的日期直方图,并将其应用于索引的“visits”字段。日期直方图将生成其中包含n个文档的n个存储桶。接下来,总和子集合将计算每个月时段的所有访问的总和。最后,平均存储桶管道将引用总和sibling聚合,并使用每个存储桶的总和来计算所有存储桶的平均每月博客访问量。因此,我们将得出每月平均博客访问量的平均值。
GET traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
}
}
},
"avg_monthly_visits": {
"avg_bucket": {
"buckets_path": "visits_per_month>total_visits"
}
}
}
}我们得到的结果是:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
}
}
]
},
"avg_monthly_visits" : {
"value" : 2582.8333333333335
}
}因此,每月平均博客访问量为2582.83。 仔细研究我们上面描述的步骤,您可以了解管道聚合的工作方式。 他们采用指标和/或存储桶聚合的中间结果,并对其进行其他计算。 当您的数据不包含中间结果时,此方法非常有用,并且中间结果应在聚合过程中隐式导出。
Derivative Aggregation
这里写Derivative就是我们数学术语里的导数。
这是父管道聚合,用于计算父直方图或日期直方图聚合中指定指标的派生。此聚合有两个要求:
- 指标必须为数字,否则将无法找到导数。
- 直方图必须将min_doc_count设置为0(这是直方图聚合的默认值)。如果min_doc_count大于0,则将省略某些存储桶,这可能导致混淆或错误的导数值。
在数学中,函数的导数用于衡量函数值(输出值)相对于其自变量(输入值)变化的敏感性。换句话说,导数根据其变量评估某些函数的变化速度。将这一概念应用于我们的数据,我们可以说微分聚合计算的是与前一时期相比数值数据的变化速度。让我们看一个真实的例子,以更好地了解我们在说什么。
首先,我们将计算一阶导数。一阶导数告诉我们函数是在增加还是在减少,以及增加或减少了多少。看下面的例子:
GET traffic_stats/_search
{
"size":0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
},
"visits_deriv": {
"derivative": {
"buckets_path": "total_visits"
}
}
}
}
}
}buckets_path指示derivative聚合将total_visits父聚合的输出用于派生(我们应使用父聚合,因为派生是父管道聚合)。
对以上查询的响应应类似于以下内容:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
},
"visits_deriv" : {
"value" : 81.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
},
"visits_deriv" : {
"value" : 808.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
},
"visits_deriv" : {
"value" : -1105.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
},
"visits_deriv" : {
"value" : 567.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
},
"visits_deriv" : {
"value" : 692.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
},
"visits_deriv" : {
"value" : -464.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
},
"visits_deriv" : {
"value" : -427.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
},
"visits_deriv" : {
"value" : 449.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
},
"visits_deriv" : {
"value" : 226.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
},
"visits_deriv" : {
"value" : 79.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
},
"visits_deriv" : {
"value" : 155.0
}
}
]
}
}如果细心的开发者可以从上面的结果中可以看出来这里的visits_deriv其实就是我们在上一个例子中的total_visits减去相邻的两个查询结果的值所得到的。如果比较两个相邻的存储桶,您会发现一阶导数就是当前存储桶和前一个存储桶的总访问量之差。 例如:
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
},
"visits_deriv" : {
"value" : 79.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
},
"visits_deriv" : {
"value" : 155.0
}
}如您所见,2018年8月的访问总次数为2966次,而2019年9月的访问次数为3121次。如果从3121次中减去2966次,我们将得出一阶导数值155.0。 就这么简单!
我们其实也可以在Kibana中来展示这个数据。为了展示数据,我们必须创建一个关于traffic_stats的index pattern。如果你还不知道如何来创建一个index pattern的话,那么请阅读我的另外一篇文章“Kibana: 如何使用Search Bar”。
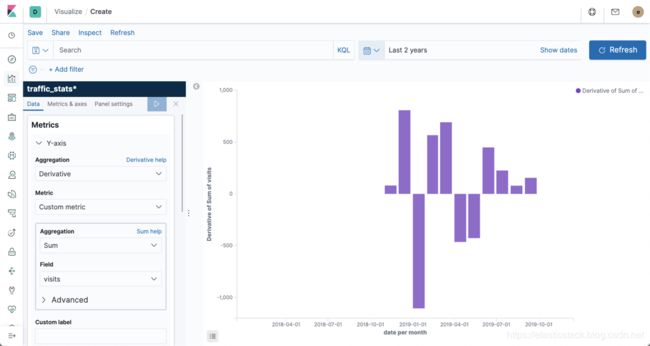
为了可视化derivative,我们需要选择derivative管道聚合和导数使用的自定义指标,即“visits”字段上的总和。 在X轴上,我们应该使用“monthly”间隔在“date”字段上定义“日期直方图”聚合。 运行可视化后,Kibana将为每个导数创建竖线。 正导数将放置在靠近图形顶部的位置,负导数将放置在靠近图形底部的位置。
二阶 Derivative
二阶导数是双导数或该导数的导数。 它测量数量变化率本身如何变化。
在Elasticsearch中,我们可以通过derivative管道聚合链接到另一个derivative管道聚合的输出上来计算二阶导数。 这样,我们首先计算一阶导数,然后根据一阶导数计算二阶导数。 让我们看下面的例子:
GET traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
},
"visits_deriv": {
"derivative": {
"buckets_path": "total_visits"
}
},
"visits_2nd_deriv": {
"derivative": {
"buckets_path": "visits_deriv"
}
}
}
}
}
}如您所见,一阶导数使用通过总和计算得出的total_visits路径,而二阶导数使用通往第一个导数管道的visits_deriv的路径。 这样,我们可以将二阶导数计算视为双管道聚合。 上面的查询应返回以下响应:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
},
"visits_deriv" : {
"value" : 81.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
},
"visits_deriv" : {
"value" : 808.0
},
"visits_2nd_deriv" : {
"value" : 727.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
},
"visits_deriv" : {
"value" : -1105.0
},
"visits_2nd_deriv" : {
"value" : -1913.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
},
"visits_deriv" : {
"value" : 567.0
},
"visits_2nd_deriv" : {
"value" : 1672.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
},
"visits_deriv" : {
"value" : 692.0
},
"visits_2nd_deriv" : {
"value" : 125.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
},
"visits_deriv" : {
"value" : -464.0
},
"visits_2nd_deriv" : {
"value" : -1156.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
},
"visits_deriv" : {
"value" : -427.0
},
"visits_2nd_deriv" : {
"value" : 37.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
},
"visits_deriv" : {
"value" : 449.0
},
"visits_2nd_deriv" : {
"value" : 876.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
},
"visits_deriv" : {
"value" : 226.0
},
"visits_2nd_deriv" : {
"value" : -223.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
},
"visits_deriv" : {
"value" : 79.0
},
"visits_2nd_deriv" : {
"value" : -147.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
},
"visits_deriv" : {
"value" : 155.0
},
"visits_2nd_deriv" : {
"value" : 76.0
}
}
]
}
}让我们仔细查看两个相邻的存储桶,看看二阶导数的真正含义是:
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
},
"visits_deriv" : {
"value" : 81.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
},
"visits_deriv" : {
"value" : 808.0
},
"visits_2nd_deriv" : {
"value" : 727.0
}
},因此,如您所见,一阶导数就是当前存储桶(例如2018-12-01存储桶)与前一个存储桶(2019-11-01)的总访问量之差。 这就是我们从前面的示例中了解到的信息。 在我们的案例中,此差异为808(2949-2141)。
什么是二阶导数? 只是两个相邻存储桶的一阶导数之间的差异。 例如,“ 2018-11-01”存储桶的一阶导数为81,而“ 2018-12-01”存储桶的一阶导数为808.0。 因此,“ 2018-12-01”存储桶的二阶导数是727.0(808-81)。 简单!
注意:前两个存储桶没有二阶导数,因为我们需要至少一阶导数的两个数据点来计算二阶导数。
Min and Max Bucket Aggregation
最大存储桶聚合是同级管道聚合,它在同级聚合中搜索具有某个度量最大值的存储桶,并同时输出存储桶的值和键值。 指标必须是数字,同级聚合必须是多桶聚合。
在以下示例中,最大存储桶聚合计算日期直方图聚合生成的所有存储桶中每月访问的最大次数。 在这种情况下,最大存储桶聚合针对的是total_visits总和聚合(即其同级聚合)的结果。
POST traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
}
}
},
"max_monthly_visits": {
"max_bucket": {
"buckets_path": "visits_per_month>total_visits"
}
}
}
}查询的结果是:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
}
}
]
},
"max_monthly_visits" : {
"value" : 3121.0,
"keys" : [
"2019-09-01T00:00:00.000Z"
]
}
}我们从上面的结果可以看出来max_monthly_visits的值是3121.0,它是所有2019-09-01的total_visits值。同样的,我们也可以通过Kibana的方式来查询这个结果:
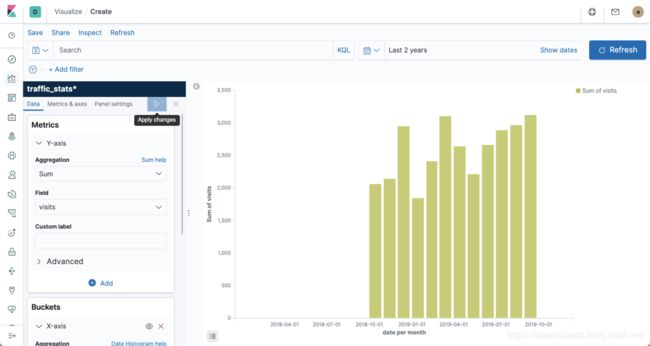
最小存储桶聚合具有相同的逻辑。 为了使其工作,我们只需要在查询中用min_bucket替换max_bucket。
POST traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
}
}
},
"min_monthly_visits": {
"min_bucket": {
"buckets_path": "visits_per_month>total_visits"
}
}
}
}结果是:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
}
}
]
},
"min_monthly_visits" : {
"value" : 1844.0,
"keys" : [
"2019-01-01T00:00:00.000Z"
]
}
}Sum 及Cumulative Sum Buckets Aggregations
在某些情况下,您需要计算通过其他某种聚合计算得出的所有存储桶值的总和。 在这种情况下,您可以使用总和存储桶聚合,这是同级管道聚合。
让我们计算所有存储桶中每月访问量的总和:
POST traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
}
}
},
"sum_monthly_visits": {
"sum_bucket": {
"buckets_path": "visits_per_month>total_visits"
}
}
}
}如您所见,此管道聚合针对的是同级total_visits聚合,该聚合代表每月的总访问量。 响应应如下所示:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
}
}
]
},
"sum_monthly_visits" : {
"value" : 30994.0
}
}因此,我们的总管道聚合简单地计算了每个存储桶每月访问的总和,其本身就是兄弟总和聚合所计算的每月所有访问的总和。
累积总和采用不同的方法。 通常,累积和是给定序列的部分和的序列。 例如,序列{a,b,c,...}的累积和为a,a + b,a + b + c,...
Cumulative sun aggregation是父管道聚合,用于计算父直方图(或date_histogram)聚合中指定指标的累积总和。 与其他父管道聚合一样,指定的指标必须为数字,并且封闭的直方图必须将min_doc_count设置为0(直方图聚合的默认设置)。
POST traffic_stats/_search
{
"size": 0,
"aggs": {
"visits_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_visits": {
"sum": {
"field": "visits"
}
},
"cumulative_visits": {
"cumulative_sum": {
"buckets_path": "total_visits"
}
}
}
}
}
}我们也可以通过Kibana来操作展示这个数据:
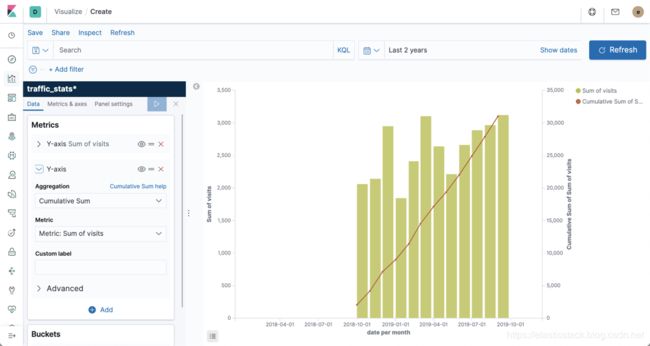
相应数据为:
"aggregations" : {
"visits_per_month" : {
"buckets" : [
{
"key_as_string" : "2018-10-01T00:00:00.000Z",
"key" : 1538352000000,
"doc_count" : 3,
"total_visits" : {
"value" : 2060.0
},
"cumulative_visits" : {
"value" : 2060.0
}
},
{
"key_as_string" : "2018-11-01T00:00:00.000Z",
"key" : 1541030400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2141.0
},
"cumulative_visits" : {
"value" : 4201.0
}
},
{
"key_as_string" : "2018-12-01T00:00:00.000Z",
"key" : 1543622400000,
"doc_count" : 3,
"total_visits" : {
"value" : 2949.0
},
"cumulative_visits" : {
"value" : 7150.0
}
},
{
"key_as_string" : "2019-01-01T00:00:00.000Z",
"key" : 1546300800000,
"doc_count" : 2,
"total_visits" : {
"value" : 1844.0
},
"cumulative_visits" : {
"value" : 8994.0
}
},
{
"key_as_string" : "2019-02-01T00:00:00.000Z",
"key" : 1548979200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2411.0
},
"cumulative_visits" : {
"value" : 11405.0
}
},
{
"key_as_string" : "2019-03-01T00:00:00.000Z",
"key" : 1551398400000,
"doc_count" : 2,
"total_visits" : {
"value" : 3103.0
},
"cumulative_visits" : {
"value" : 14508.0
}
},
{
"key_as_string" : "2019-04-01T00:00:00.000Z",
"key" : 1554076800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2639.0
},
"cumulative_visits" : {
"value" : 17147.0
}
},
{
"key_as_string" : "2019-05-01T00:00:00.000Z",
"key" : 1556668800000,
"doc_count" : 2,
"total_visits" : {
"value" : 2212.0
},
"cumulative_visits" : {
"value" : 19359.0
}
},
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2661.0
},
"cumulative_visits" : {
"value" : 22020.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"total_visits" : {
"value" : 2887.0
},
"cumulative_visits" : {
"value" : 24907.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"total_visits" : {
"value" : 2966.0
},
"cumulative_visits" : {
"value" : 27873.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 2,
"total_visits" : {
"value" : 3121.0
},
"cumulative_visits" : {
"value" : 30994.0
}
}
]
}
}如您所见,聚合首先计算两个存储桶的总和,然后将结果加到下一个存储桶的值,依此类推。 这样,它将累加序列中所有存储桶的总和。
总结:
而已! 如我们所见,管道聚合有助于实现涉及中间值和其他聚合产生的存储桶的复杂计算。 这允许提取复杂的度量,例如导数,移动平均值,二阶导数和其他在数据中不直接可用的度量,并且涉及要计算的多个中间步骤。
参考:
【1】https://www.elastic.co/guide/en/elasticsearch/reference/7.5/search-aggregations-pipeline.html#buckets-path-syntax
【2】https://qbox.io/blog/comprehensive-guide-to-elasticsearch-pipeline-aggregations-part-i