Python爬虫+ pyqt5(从零开始到爬取教务处新闻,课程表,成绩)
前言:
刚开始以为Python爬虫很高深,其实,当你模仿其他人的代码,敲了一遍之后,你8成就可以理解Python的基本爬虫了。
无论是学习什么事情,刚开始就要准备好利器工具,那样我们才能开始我们的旅程。工欲善其事,必先利其器麻!
Python的安装:点击打开链接 我下载的是3.5 你也可以下载其他版本的
Pycharm(是IDE)安装:点击打开链接
pyqt5 安装:点击打开链接
另外最好用火狐浏览器,查看 调试好点。
(一)好啦,准备好了,就让我们写一个最基本爬虫,爬取一个网页的图片。
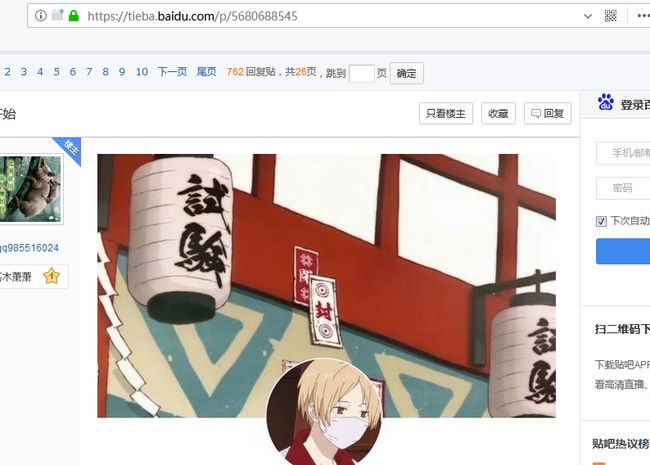
我们就爬这个网页的所有图片
先按F12,再按F5查看,如下图
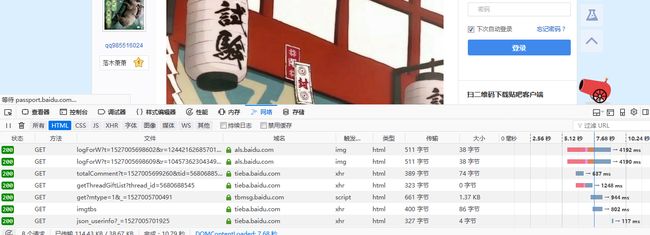
再点击对应的网页
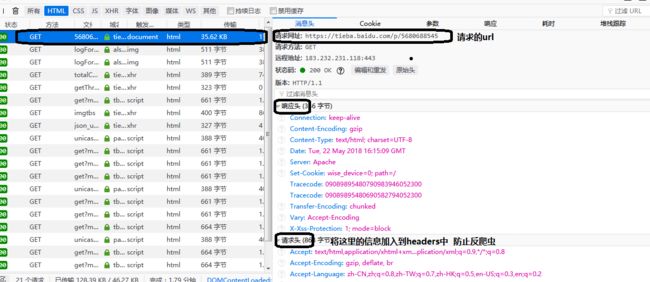
这样我们获取网页的基本信息已经都做完了,就可以敲代码了。注意:代码要对齐,不然pycharm会报错。
#导入正则模块 用于匹配
import re
#导入请求模块 向网页请求的
import urllib.request
#通过url获取网页 def 这是一个函数定义头 getHtml函数名 url函数参数
def getHtml(url):
"""
通过url获取html地址 #函数说明
:param url:
:return: html
"""
#headers 网页的请求头 防止反爬虫(骗服务器,是浏览器在请求,而不是机器人在请求) 在对应的网页 按F12调试查看
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0',
}
#请求 返回req
req = urllib.request.Request(url, headers =headers)
#打开req返回一个网页
html = urllib.request.urlopen(req).read()
return html
#通过正则表达式来获取图片地址,并下载到本地
def getImg(html):
"""
根据reg获取图片,并下载到本地
:param html:
:return: imglist
"""
# 定义图片正则 规则
reg = r'src="(.+?\.jpg)"'
#匹配
imgre = re.compile(reg)
#找到图片列表
imglist = re.findall(imgre, html)
#x图片编号
x = 1
for imgurl in imglist:
print(imgurl)
#通过urlretrieve函数把数据下载到本地的D:\\images,所以你需要创建目录
urllib.request.urlretrieve(imgurl, './images/'+'%s.jpg'%x)
x = x + 1
return imglist
def get():
html = getHtml("https://tieba.baidu.com/p/5680688545")
#记得加上这句 不然会乱码 编码格式看网页源代码 大部分 utf-8 gbk json
html = html.decode('utf-8')
print(html)
print(getImg(html))
if __name__ == "__main__":
get()里面加了好多注释,代码是很短的,实际代码也只有十几行。另外我忘了加入Sleep函数了,加上的话会变慢,不过这样能够保证持续爬取,如果过快爬取的话,服务器会认为你频繁访问而暂停你的请求。
会爬一个网页的图片就可以爬多个网页了。
其实很简单,只需要加工for循环 不断 改变gethtml里面的url的地址,不同的url对应不同的网页,就可以实现爬取不同网页的图片了。
下面我举个栗子,你们自己再试着去模仿下哈:
import re
import urllib.request
import urllib.error
from urllib.request import urlopen
import os
import operator
import time
#通过url获取网页
def getHtml(url):
"""
通过url获取html地址
:param url:
:return: html
"""
# 用于模拟http头的User-agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0',
}
req = urllib.request.Request(url, headers =headers)
try:
page = urlopen(req)
except urllib.error as e:
print(e)
print(222)
html = page.read().decode('utf-8')
return html
#通过正则表达式来获取图片地址,并下载到本地
def getImg(html):
"""
根据reg获取图片,并下载到本地
:param html:
:return: imglist
"""
reg = r'src="(.+?\.jpg)"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x=1 #图片编号
for imgurl in imglist:
print(imgurl)
#通过urlretrieve函数把数据下载到本地的D:\\images,所以你需要创建目录
while os.path.exists('./images/'+'%s.jpg'%x):
x = x + 1
if (operator.eq(imgurl,'https://ws1.sinaimg.cn/large/7e8b4ac8ly1fqdb6j1r9jj208202ijs9.jpg') !=1 ) & (operator.eq(imgurl,'https://ws1.sinaimg.cn/large/7e8b4ac8ly1fqdb6j9jfij208202ijs8.jpg')!=1):
urllib.request.urlretrieve(imgurl, './images/'+'%s.jpg'%x)
x = x + 1
return imglist
def geturl(dir):
y = 1
while y >= 1:
if y == 1:
try:
html = getHtml("http://aladd.net/archives/" + str(dir) + ".html")
except:
y = y + 1
continue
imglist = getImg(html)
print("http://aladd.net/archives/" + str(dir) + ".html")
else:
try:
html = getHtml("http://aladd.net/archives/" + str(dir + y-1) + ".html")
except:
y = y + 1
continue
imglist = getImg(html)
print("http://aladd.net/archives/" + str(dir + y-1) + ".html")
y = y + 1
def get():
global x
dir =32400 #第几个网页号
while dir>=1:
aaa=geturl(dir)
print(aaa)
dir = dir +1
if __name__ == "__main__":
get()代码写得很乱,代码就没注释了,第一个栗子基本都有解释了。
这两个简单的例子就让我对python产生了浓厚的兴趣,于是我就想到一件有趣的事情,就是爬取我们学校教务处的信息。
(二)爬取教务处信息
(1)爬取教务处的新闻
1.到教务处页面上
先按F12在按F5,点击一个类别的新闻。
查看消息头,看到对应的请求网址。
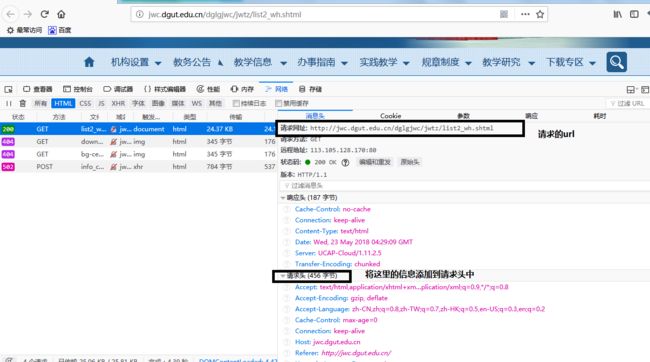

接着我们按下一页,观察请求网址,我可以发现是有规律变化的。
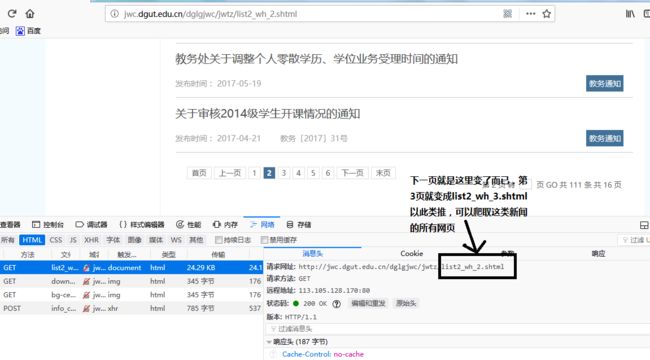
然后我们就可以开始爬取新闻了。
sessions = requests.session() #这个设为全局的sessioins,下面我们讲的模拟登录也用的是同一个sessions
i = 1 #对应第1页信息
page = '_' + str(i)
if i == 1:
newsMainUrl = 'http://jwc.dgut.edu.cn/dglgjwc/jwtz/list2_wh.shtml'
elif i != 1:
newsMainUrl = 'http://jwc.dgut.edu.cn/dglgjwc/jwtz/list2_wh' + page + '.shtml'
newsMainHeader = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate',
'Cache-Control': 'max-age=0',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Host': 'cas.dgut.edu.cn',
'Referer': 'http://jwc.dgut.edu.cn/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
#get 请求
rsp = sessions.get(newsMainUrl, headers=newsMainHeader)
#获取网页
content = rsp.content.decode('utf-8')
#soup用来解析网页的
soup = BeautifulSoup(content, 'html.parser')
#获取所有dvi 并且calss为con-right fr"的标签
dvs = soup.find_all('div', class_="con-right fr")
for dv in dvs:
#获取div中所有的a标签
items = dv.find_all('a')
tds = dv.find_all('td', width="22%")
for item in items:
print(item.contents)
for td in tds:
print(td.text)上面我们获取了一个类别的所有新闻之后,就可以爬取不同类别的新闻了,这跟爬取一个网址的所有图片和爬取多个网址的图片是相同的道理的。
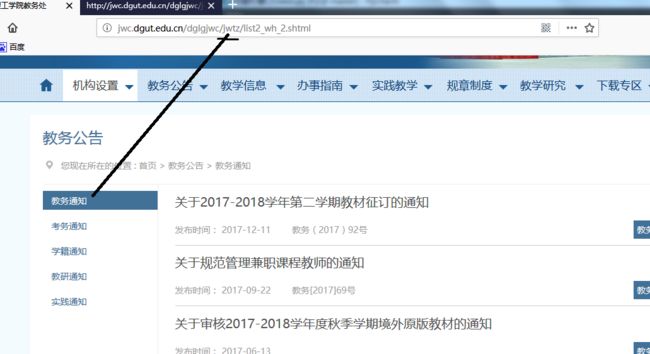
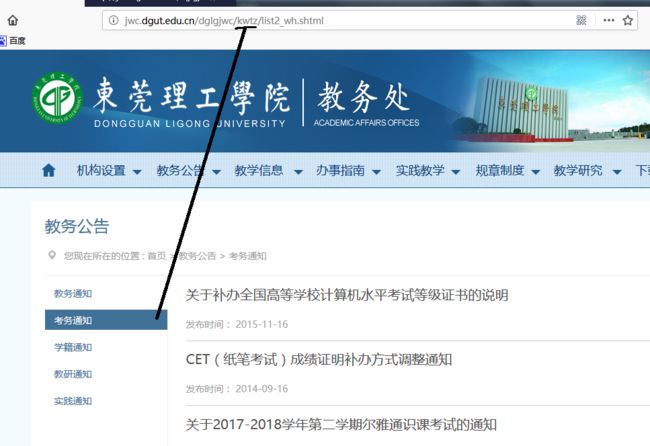
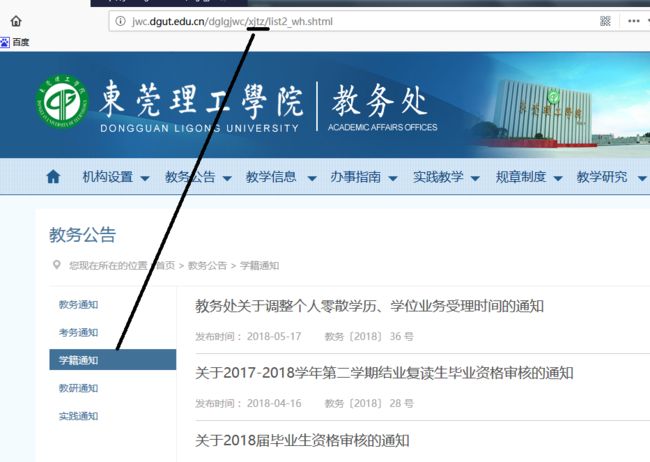
发现没,每个类别的网址只有一处地方不同。
我们可以用一个列表来存储不同之处
type = ['jwtz', 'kwtz', 'xjtz', 'jytz', 'sjtz']每个类别的第1页是这样的 ,newstype:0对应就是教务通知(jwtz),1就是考务通知(kwtz)
newsMainUrl = 'http://jwc.dgut.edu.cn/dglgjwc/' + str(type[newsType]) + '/list2_wh.shtml'
第2页起是这样的
newsMainUrl = 'http://jwc.dgut.edu.cn/dglgjwc/' + str(type[newsType]) + '/list2_wh' + page + '.shtml'具体实现你们可以自己去动手试试,我就不展现代码了。
(2)登录教务处,爬取课表,成绩表
1.用request模拟登录教务处
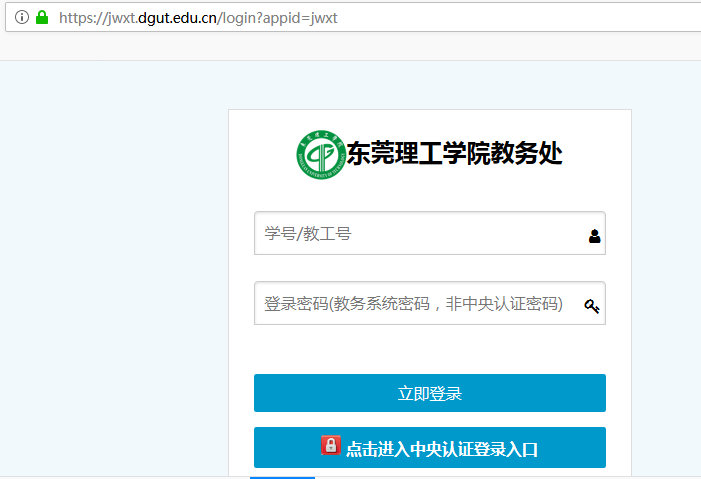
我们学校有两个登录页面,第一个登录页面是真正的提交表单的界面,第二登录界面就把表单提交到第一个登录页面。
先打开第一个登录页面
这是第二个登录页面
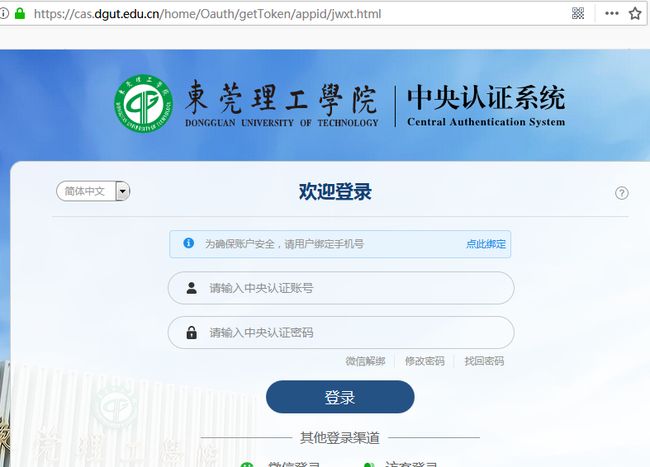
要先按F12,再按F5进入调试模式,再把学号,密码填入,点击登录
查找Post的网页,不过我这里找不到Post的页面,因为它提交的真正的登录页之后就不见了。
我找了好几天,偶然在网速慢的时候,看到了那个post网页,才发现那是第一个登录网页的网址,额,找了那么久,竟然就在眼前。
这个找到的真正的登录页面
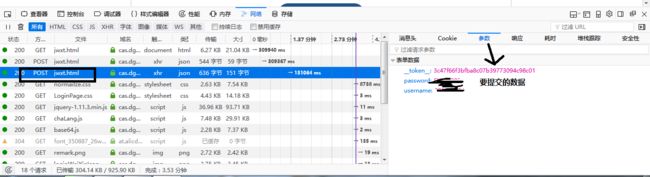
这是登录头,和请求头
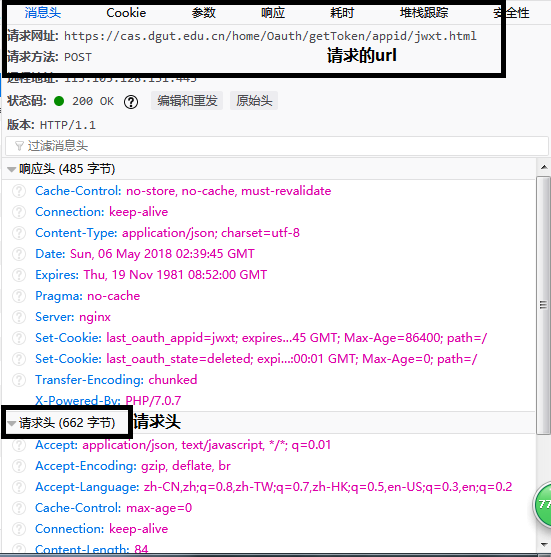
def loginHtml(USER, PWD):
#登录真正的网址 这个要按登录按钮后 查看表单提交到哪 (这个我是找了好久的,原因是表单不是提交到当前的登录页面)
loginUrl = 'https://cas.dgut.edu.cn/home/Oauth/getToken/appid/jwxt.html'
#登录头
loginHeader = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate,br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'cas.dgut.edu.cn',
'Referer': 'https://jwxt.dgut.edu.cn/login?appid=jwxt',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
#表单
dat = {'username': USER, 'password': PWD, '_token_': '3c47f66f3bfba8c07b39773094c98c01'}
#提交数据的 用post
rsp = sessions.post(loginUrl, headers=loginHeader, data=dat)
print(rsp.json()['code']) #用这个判断是否登录成功 返回1成功 返回4失败这样就模拟登录成功了,其实就是将数据提交真正的url,这就要你学会去查找。
2.登录了之后,我们就可以爬取成绩表了。
我们上面用的是request的sessions,这个携带了登录的信息(以后我不论是get还是post都用同一个sessions)。
点击对应的成绩页面。
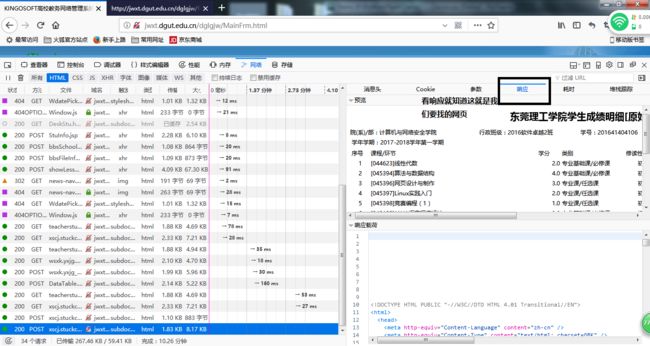
在点击消息头
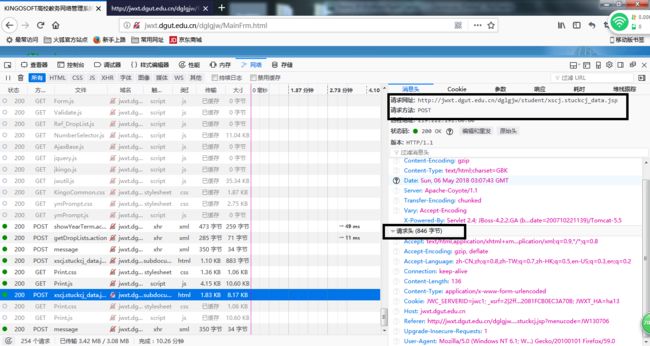
接着点击参数
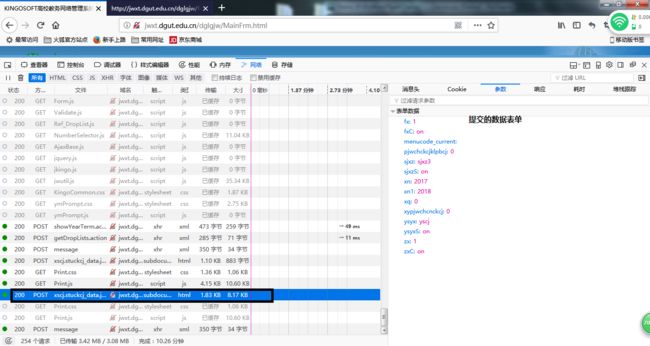
好了至此,我们已经把数据都准备好了。
开始我们的爬虫时间。
import requests
from bs4 import BeautifulSoupdef getScore():
#成绩url
scoreUrl = 'http://jwxt.dgut.edu.cn/dglgjw/student/xscj.stuckcj_data.jsp'
#成绩请求头
scoreHeader = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '158',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 't_jwc_session=2|1:0|10:1526973050|13:t_jwc_session|16:MjAxNjQxNDA0MTA2|941e8dcc1b909a4634a529d225f016e7adc134714b50997332dad4e4c8420a22; _xsrf=2|131f13d9|35f809a60aa929ed7069f856a1854f99|1526973050; JWC_SERVERID=jwc1; JSESSIONID=60B287A3AD7A501C71462CD64F1F7392; JWXT_HA=ha15',
'Host': 'cas.dgut.edu.cn',
'Referer': 'http://jwxt.dgut.edu.cn/dglgjw/student/xscj.stuckcj.jsp?menucode=JW130706',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
}
#成绩数据表单
scoreData = {
'fx': '1',
'fxC': 'on',
'menucode_current': '',
'pjwchckcjklpbcj': '0',
'sjxz': 'sjxz3',
'sjxzS': 'on',
'xn': str(year1.value()),
'xn1': str(year1.value()+1),
'xq': str(term.currentIndex()),
'xypjwchcnckcj': '0',
'ysyx': 'yscj',
'ysyxS': 'on',
'zx': '1',
'zxC': 'on'
}
#提交表单
rsp = sessions.post(scoreUrl, headers=scoreHeader, data=scoreData)
#得到成绩网址得内容
content = rsp.content.decode('gbk')
#用soup解析html,相当于筛选你要的数据
soup = BeautifulSoup(content, 'html.parser')
#按列 获取成绩表格的内容
for tr in soup.findAll('tr'): #成绩在tr td 标签中
tds = tr.findAll('td')
print(tds)
好了,这样成绩表的基本信息已经实现了。
3.下面我们可以模仿上面爬取成绩表的方式爬取课程表。
不过获取课程表的方式是get,不用提交数据, 是查询字符串的方式
点击课程表的网页看它的消息头
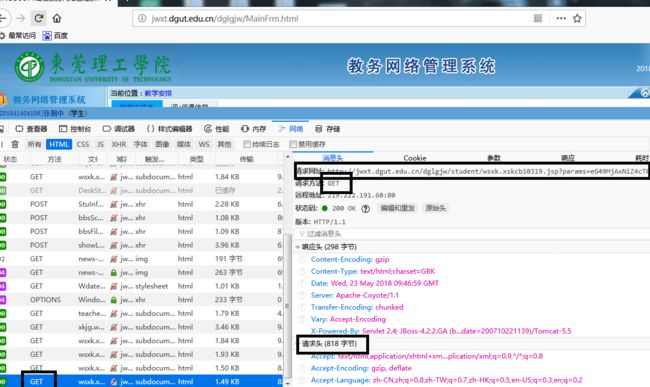
再看它的查询字符串
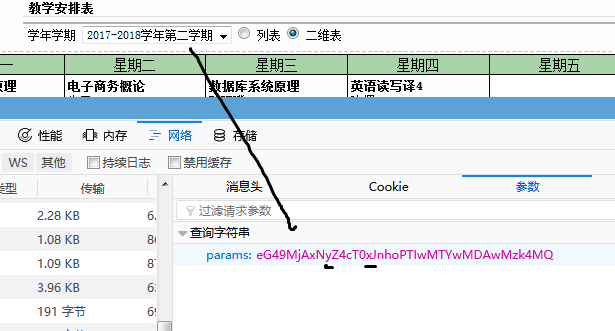
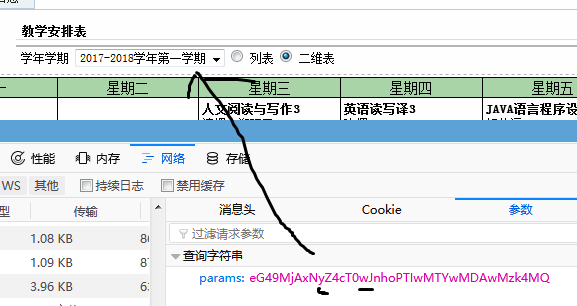
在点击17-18第一学期
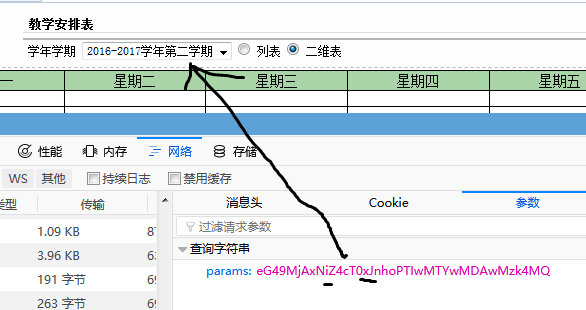
16-17第二学期
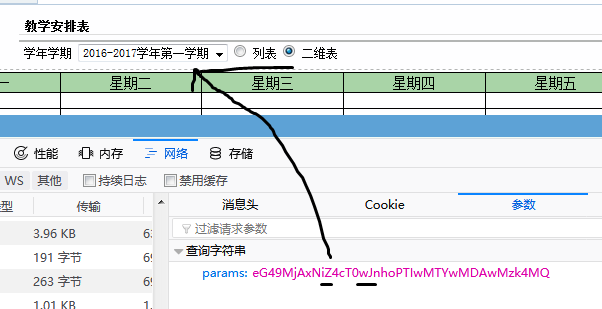
从上面我们可以看出规律
17-18学年 用y代表 w为上学期(即第一学期) x为下学期
16-17学年 用i代表 w为上学期(即第一学期) x为下学期
紧接着我们查看它的响应源代码(即课程表的源代码)。找到你要爬取的信息的标签。
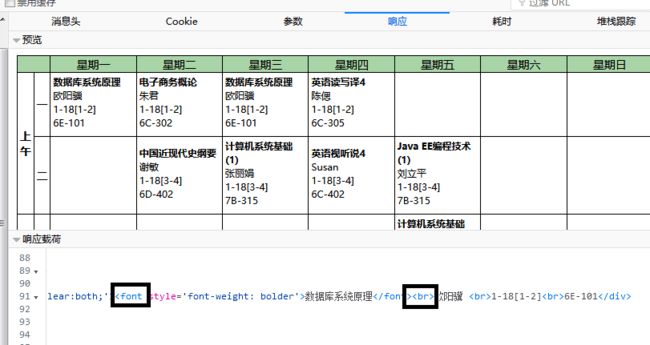
那么,准备工作已经做完了,我们就开始我们的表演吧。
#yearTmp是 上面对应 'y' 或 'i' ,或者其他(具体看网页的源代码) #termTmp是学期 值为'w' 或者 'x' courseUrl = 'http://jwxt.dgut.edu.cn/dglgjw/student/wsxk.xskcb10319.jsp?params=eG49MjAxN' + yearTmp + 'Z4cT0' + termTmp + 'JnhoPTIwMTYwMDAwMzk4MQ=='
courseHeader = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 't_jwc_session=2|1:0|10:1527066371|13:t_jwc_session|16:MjAxNjQxNDA0MTA2|63f0b2477c712ec247910d86933fae49a2413b6609d7863d75473268b6b94d43; _xsrf=2|cd61f852|b2a45a7624b0f21a67f08c3b347d6550|1527066371; JWC_SERVERID=jwc1; JSESSIONID=F147E34F9039F4F1920D8406C5973E0F; JWXT_HA=ha14',
'Host': 'cas.dgut.edu.cn',
'Referer': 'http://jwxt.dgut.edu.cn/dglgjw/student/xkjg.wdkb.jsp?menucode=JW130501',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
rsp = sessions.get(courseUrl, headers=courseHeader)
content = rsp.content.decode('gbk')
soup = BeautifulSoup(content, 'html.parser') #获取课程名
labels = soup.findAll('font')
for i in range(len(labels)): # lables保存所有font里面的内容
print(labels[i].contents[0])
labels = soup.findAll('div', class_='div_nokb')
for j in range(len(labels)):
print(labels[j].get('id'))
ct = soup.find_all('div', style='padding-bottom:5px;clear:both;')
for k in range(len(ct)):
print(ct[k].contents[1])另外我先说下re爬取正则的的简单使用。
用(.*?)替换你要爬取的信息
比如

pa = re.compile(r'font-weight: bolder\'>(.*?)) #注意'用改为 \' 这是转义字符
courseName = re.findall(pa, content) #content是对应的html
这样就可以获取课程名称了
(三)用pyqt5将上面爬取的数据展现出来
爬取了数据,想着pyqt5还可以做成界面(当然之前我是学了点基本的qt知识),于是我就开始用pyqt5了
由于代码比较乱,所以这里只能给出效果图了:
以上就是我学了10几天Python的一些收获,欢迎大家一起学习。(V●ᴥ●V)
目前爬取成绩和课表的存在一个问题,那就是每次都要在headers中添加Cookie的值,这就要去网页上手动复制Cookie到代码中(如果没添加就会出错)。我不知道为什么会这样,因为我已经用了登录的sessions了,为什么还是获取不了成绩!?
希望有大神能够指点指点。