jQuery
jQuery.extend({
abc:function(){}
});
那么。就可以调用$.abc();
flex入门
java服务器配置
com.xxxx.ResGraphOperatorImpl
0
0
true
.
0
0
true
.
配置:
web.xml
MessageBrokerServlet flex.messaging.MessageBrokerServlet services.configuration.file /WEB-INF/flex/services-config.xml 3 MessageBrokerServlet /messagebroker/*
flex.messaging.HttpFlexSession
services-config.xml
FlexSpringFactory.java
public class FlexSpringFactory implements FlexFactory {String id, ConfigMap configMap ) {
SpringFactoryInstance.java
public class SpringFactoryInstance extends FactoryInstance {
spring 回顾
@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
RequestMapping注解有六个属性,下面我们把她分成三类进行说明。
1、 value, method;
value: 指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
method: 指定请求的method类型, GET、POST、PUT、DELETE等;
2、 consumes,produces;
consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html;
produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;
3、 params,headers;
params: 指定request中必须包含某些参数值是,才让该方法处理。
headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求
统计在线人数:
HttpSessionBindingListener(接口)
package com.zxrc.ibatisTest.controller;
import java.util.Date;
import javax.servlet.http.HttpSessionBindingEvent;
import javax.servlet.http.HttpSessionBindingListener;
public class UserStat implements HttpSessionBindingListener{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void valueBound(HttpSessionBindingEvent arg0) {
// TODO Auto-generated method stub
System.out.println(name+"登录了"+new Date());
}
public void valueUnbound(HttpSessionBindingEvent arg0) {
// TODO Auto-generated method stub
System.out.println(name+"离开了"+new Date());
}
}
ApplicationContext ctx = new ClassPathXmlApplicationContext("context.xml" , Boot.class );
FooService fooService = (FooService) ctx.getBean("fooService" );
jquery autocomplete
自动补全
http://blog.csdn.net/daicj88/article/details/6822410
http://www.open-open.com/lib/view/open1340957775905.html
dhtmlx技术使用总结与介绍中文手册
http://blog.csdn.net/lylovejava0/article/details/8814164
http://blog.itblood.com/dhtmlx-technology-use-summary.html#more-1047
dhtmlxGrid
myGrid.setImagePath(dhtmlxGridImagePath)
myGrid.setHeader(headLabels.join(','));
myGrid.attachHeader(headDetailLable.join(','));
myGrid.setInitWidths(headWidths.join(','));
myGrid.setColAlign(headColAlign.join(','));
myGrid.setColTypes(headColTypes.join(','));
myGrid.setColumnsVisibility(headColumnsVisibility.join(','));
myGrid.setColumnIds(headColumnIds.join(','));
myGrid.setColumnMinWidth(headMinWidths.join(','));
myGrid.enableMultiselect(false);
myGrid.enableMultiline(true);
myGrid.enableRowspan();
myGrid.enableColSpan(true);
myGrid.init();
myGrid.enableSmartRendering(true,20);
myGrid.parse(data,"json");
JdbcTemplate
int rowCount = this .jdbcTemplate.queryForObject("select count(*) from t_actor" , Integer.class );
T
queryForObject (String sql, Class requiredType)
Execute a query for a result object, given static SQL.
int countOfActorsNamedJoe = this .jdbcTemplate.queryForObject(
"select count(*) from t_actor where first_name = ?" , Integer.class , "Joe" );
T
queryForObject (String sql, Class requiredType, Object... args)
Query given SQL to create a prepared statement from SQL and a list of arguments to bind to the query, expecting a result object.
Querying for a String:
String lastName = this .jdbcTemplate.queryForObject(
"select last_name from t_actor where id = ?" ,
new Object[]{1212L }, String.class );
T
queryForObject (String sql, Object[] args, Class requiredType)
Query given SQL to create a prepared statement from SQL and a list of arguments to bind to the query, expecting a result object.
Querying and populating a single
Actor actor = this .jdbcTemplate.queryForObject(
"select first_name, last_name from t_actor where id = ?" ,
new Object[]{1212L },
new RowMapper() {
public Actor mapRow(ResultSet rs, int rowNum) throws SQLException {
Actor actor = new Actor();
actor.setFirstName(rs.getString("first_name" ));
actor.setLastName(rs.getString("last_name" ));
return actor;
}
});
T
queryForObject (String sql, Object[] args, RowMapper rowMapper)
Query given SQL to create a prepared statement from SQL and a list of arguments to bind to the query, mapping a single result row to a Java object via a RowMapper.
List actors = this .jdbcTemplate.query(
"select first_name, last_name from t_actor" ,
new RowMapper() {
public Actor mapRow(ResultSet rs, int rowNum) throws SQLException {
Actor actor = new Actor();
actor.setFirstName(rs.getString("first_name" ));
actor.setLastName(rs.getString("last_name" ));
return actor;
}
});
T
queryForObject (String sql, RowMapper rowMapper)
Execute a query given static SQL, mapping a single result row to a Java object via a RowMapper.
this .jdbcTemplate.update(
"insert into t_actor (first_name, last_name) values (?, ?)" ,
"Leonor" , "Watling" );你可以使用execute执行任何SQL语句 this .jdbcTemplate.execute("create table mytable (id integer, name varchar(100))" );this .jdbcTemplate.update(
"call SUPPORT.REFRESH_ACTORS_SUMMARY(?)" ,
Long.valueOf(unionId)); NamedParameterJdbcTemplate(类似first_name = :first_name )
String sql = "select count(*) from T_ACTOR where first_name = :first_name" ;
SqlParameterSource namedParameters = new MapSqlParameterSource("first_name" , firstName);
this .namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class );
String sql = "select count(*) from T_ACTOR where first_name = :first_name" ;
Map namedParameters = Collections.singletonMap("first_name" , firstName);
this .namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class );
public int countOfActors(Actor exampleActor) {//用bean
String sql = "select count(*) from T_ACTOR where first_name = :firstName and last_name = :lastName" ;
SqlParameterSource namedParameters = new BeanPropertySqlParameterSource(exampleActor);
return this .namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class );
} this .jdbcTemplate.queryForList("select * from mytable" );
[{name=Bob, id=1}, {name=Mary, id=2}]
获取自动生成的键:
final String INSERT_SQL = "insert into my_test (name) values(?)" ;
final String name = "Rob" ;
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(
new PreparedStatementCreator() {
public PreparedStatement createPreparedStatement(Connection connection) throws SQLException {
PreparedStatement ps = connection.prepareStatement(INSERT_SQL, new String[] {"id" });
ps.setString(1 , name);
return ps;
}
},
keyHolder);// keyHolder.getKey() now contains the generated key
batch operations批量操作
使用
JdbcTemplate
批量操作通过实现接口,
BatchPreparedStatementSetter
使用 getBatchSize
public int [] batchUpdate(final List actors) {
int [] updateCounts = jdbcTemplate.batchUpdate("update t_actor set first_name = ?, " +
"last_name = ? where id = ?" ,
new BatchPreparedStatementSetter() {
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1 , actors.get(i).getFirstName());
ps.setString(2 , actors.get(i).getLastName());
ps.setLong(3 , actors.get(i).getId().longValue());
}
public int getBatchSize() {
return actors.size();
}
});
return updateCounts;
}
使用SqlParameterSource.createBatch 方法创建这个数组,通过一个javabean数组或数组包含参数值的映射(NamedParameterJdbcTemplate 的批量操作 )
public int [] batchUpdate(final List actors) {
SqlParameterSource[] batch = SqlParameterSourceUtils.createBatch(actors.toArray());
int [] updateCounts = namedParameterJdbcTemplate.batchUpdate(
"update t_actor set first_name = :firstName, last_name = :lastName where id = :id" ,
batch);
return updateCounts;
}
public int [] batchUpdate(final List actors) {
List batch = new ArrayList();
for (Actor actor : actors) {
Object[] values = new Object[] {
actor.getFirstName(),
actor.getLastName(),
actor.getId()};
batch.add(values);
}
int [] updateCounts = jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?" ,
batch);
return updateCounts;
}
多个批次批处理操作
上次例子批量更新的涉及批次,太大了,你想把他们分成几个较小的批次。(提高性能,)
public int [][] batchUpdate(final Collection actors) {
int [][] updateCounts = jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?" ,
actors,
100 ,//更新为每一批的数量
new ParameterizedPreparedStatementSetter() {
public void setValues(PreparedStatement ps, Actor argument) throws SQLException {
ps.setString(1 , argument.getFirstName());
ps.setString(2 , argument.getLastName());
ps.setLong(3 , argument.getId().longValue());
}
});
return updateCounts;
}
SimpleJdbc
Map parameters = new HashMap(3 );
parameters.put("id" , actor.getId());
parameters.put("first_name" , actor.getFirstName());
parameters.put("last_name" , actor.getLastName());
this .simpleJdbcInsert.withTableName( "t_actor" ). execute(parameters) ;}
获取主键
Map parameters = new HashMap(2 );
parameters.put("first_name" , actor.getFirstName());
parameters.put("last_name" , actor.getLastName());
Number newId = this.simpleJdbcInsert .withTableName( "t_actor" ) .usingGeneratedKeyColumns( "id" ) .executeAndReturnKey(parameters);
列
Map parameters = new HashMap(2 );
parameters.put("first_name" , actor.getFirstName());
parameters.put("last_name" , actor.getLastName());
Number newId = this .simpleJdbcInsert .withTableName( "t_actor" )
.usingColumns("first_name" , "last_name" ) .usingGeneratedKeyColumns( "id" ) .executeAndReturnKey(parameters);
BeanPropertySqlParameterSource 会抽取getter
public void add(Actor actor) {
SqlParameterSource parameters = new BeanPropertySqlParameterSource(actor);
Number newId = this .simpleJdbcInsert(dataSource)
.withTableName("t_actor" )
.usingGeneratedKeyColumns("id" ) .executeAndReturnKey(parameters); actor.setId(newId.longValue()); }
MapSqlParameterSource 使用addValue 添加一个值到map
public void add(Actor actor) {
SqlParameterSource parameters = new MapSqlParameterSource()
.addValue("first_name" , actor.getFirstName())
.addValue("last_name" , actor.getLastName());
Number newId = this"t_actor" )
.usingGeneratedKeyColumns("id" ) .executeAndReturnKey(parameters); actor.setId(newId.longValue()); }
SimpleJdbcCall存储过程
CREATE PROCEDURE read_actor (
IN in_id INTEGER ,
OUT out_first_name VARCHAR (100 ),
OUT out_last_name VARCHAR (100 ),
OUT out_birth_date DATE )
BEGIN
SELECT first_name, last_name, birth_date
INTO out_first_name, out_last_name, out_birth_date
FROM t_actor where id = in_id;
END ; public Actor readActor(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id" , id);
Map out = this .simpleJdbcCall .withProcedureName( "read_actor" )
.execute(in);
Actor actor = new Actor();
actor.setId(id);
actor.setFirstName((String) out.get("out_first_name" ));
actor.setLastName((String) out.get("out_last_name" ));
actor.setBirthDate((Date) out.get("out_birth_date" ));
return actor;
}
不区分大小写
setResultsMapCaseInsensitive
设为true
jdbcTemplate.setResultsMapCaseInsensitive(true);
SimpleJdbcCall procReadActor = new S impleJdbcCall(jdbcTemplate)
.withProcedureName( "read_actor" );
}
显式声明(为了绕过所有的处理元数据查找潜在的参数和只使用声明的参数withoutProcedureColumnMetaDataAccess )
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this .procReadActor = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_actor" )
.withoutProcedureColumnMetaDataAccess()
.useInParameterNames("in_id" )
.declareParameters(
new SqlParameter("in_id" , Types.NUMERIC),
new SqlOutParameter("out_first_name" , Types.VARCHAR),
new SqlOutParameter("out_last_name" , Types.VARCHAR),
new SqlOutParameter("out_birth_date" , Types.DATE)
);
}
SqlInOutParameter --》InOut
使用SimpleJdbcCall调用一个存储函数
CREATE FUNCTION get_actor_name (in_id INTEGER )
RETURNS VARCHAR (200 ) READS SQL DATA
BEGIN
DECLARE out_name VARCHAR (200 );
SELECT concat(first_name, ' ' , last_name)
INTO out_name
FROM t_actor where id = in_id;
RETURN out_name;
END ; private JdbcTemplate jdbcTemplate;
private SimpleJdbcCall funcGetActorName;
public void setDataSource(DataSource dataSource) {
this .jdbcTemplate = new JdbcTemplate(dataSource);
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this .funcGetActorName = new SimpleJdbcCall(jdbcTemplate)
.withFunctionName("get_actor_name" );
}
public String getActorName(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id" , id);
String name = funcGetActorName.executeFunction(String.class , in);
return name;
}
游标
CREATE PROCEDURE read_all_actors()
BEGIN
SELECT a .id, a .first_name, a .last_name, a .birth_date FROM t_actor a ;
END ; private SimpleJdbcCall procReadAllActors;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this .procReadAllActors = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_all_actors" )
.returningResultSet("actors" ,
BeanPropertyRowMapper.newInstance(Actor.class ));
}
public List getActorsList() {
Map m = procReadAllActors.execute(new HashMap(0 ));
return (List) m.get("actors" );
}
处理BLOB和CLOB对象
LobCreator/LobHandler
BLOB
byte[] — getBlobAsBytes and setBlobAsBytesInputStream — getBlobAsBinaryStream and setBlobAsBinaryStream
CLOB
String — getClobAsString and setClobAsStringInputStream — getClobAsAsciiStream and setClobAsAsciiStreamReader — getClobAsCharacterStream and setClobAsCharacterStream
final File blobIn = new File("spring2004.jpg" );
final InputStream blobIs = new FileInputStream(blobIn);
final File clobIn = new File("large.txt" );
final InputStream clobIs = new FileInputStream(clobIn);
final InputStreamReader clobReader = new InputStreamReader(clobIs);
jdbcTemplate.execute(
"INSERT INTO lob_table (id, a_clob, a_blob) VALUES (?, ?, ?)" ,
new AbstractLobCreatingPreparedStatementCallback(lobHandler) { //传lobHandler
protected void setValues(PreparedStatement ps, LobCreator lobCreator) throws SQLException {
ps.setLong(1 , 1L );
lobCreator.setClobAsCharacterStream(ps, 2 , clobReader, (int )clobIn.length());
lobCreator.setBlobAsBinaryStream(ps, 3 , blobIs, (int )blobIn.length());
}
}
);
blobIs.close();
clobReader.close();List> l = jdbcTemplate.query("select id, a_clob, a_blob from lob_table" ,
new RowMapper>() {
public Map mapRow(ResultSet rs, int i) throws SQLException {
Map results = new HashMap();
String clobText = lobHandler.getClobAsString(rs, "a_clob" );
results.put("CLOB" , clobText); byte [] blobBytes = lobHandler.getBlobAsBytes(rs, "a_blob" );
results.put("BLOB" , blobBytes); return results; } });
mybatis
xml version = "1.0" encoding = "UTF-8" ?>
namespace = "org.mybatis.example.BlogMapper" >
id = "selectBlog" resultType = "Blog" >
select * from Blog where id = #{id}
settings
这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。下表描述了设置中各项的意图、默认值等。
设置参数
描述
有效值
默认值
cacheEnabled
该配置影响的所有映射器中配置的缓存的全局开关。
true | false
true
lazyLoadingEnabled
延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置fetchType 属性来覆盖该项的开关状态。
true | false
false
aggressiveLazyLoading
当启用时,对任意延迟属性的调用会使带有延迟加载属性的对象完整加载;反之,每种属性将会按需加载。
true | false
true
multipleResultSetsEnabled
是否允许单一语句返回多结果集(需要兼容驱动)。
true | false
true
useColumnLabel
使用列标签代替列名。不同的驱动在这方面会有不同的表现, 具体可参考相关驱动文档或通过测试这两种不同的模式来观察所用驱动的结果。
true | false
true
useGeneratedKeys
允许 JDBC 支持自动生成主键,需要驱动兼容。 如果设置为 true 则这个设置强制使用自动生成主键,尽管一些驱动不能兼容但仍可正常工作(比如 Derby)。
true | false
False
autoMappingBehavior
指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)。
NONE, PARTIAL, FULL
PARTIAL
defaultExecutorType
配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。
SIMPLE REUSE BATCH
SIMPLE
defaultStatementTimeout
设置超时时间,它决定驱动等待数据库响应的秒数。
Any positive integer
Not Set (null)
safeRowBoundsEnabled
允许在嵌套语句中使用分页(RowBounds)。
true | false
False
mapUnderscoreToCamelCase
是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。
true | false
False
localCacheScope
MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据。
SESSION | STATEMENT
SESSION
jdbcTypeForNull
当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。
JdbcType enumeration. Most common are: NULL, VARCHAR and OTHER
OTHER
lazyLoadTriggerMethods
指定哪个对象的方法触发一次延迟加载。
A method name list separated by commas
equals,clone,hashCode,toString
defaultScriptingLanguage
指定动态 SQL 生成的默认语言。
A type alias or fully qualified class name.
org.apache.ibatis.scripting.xmltags.XMLDynamicLanguageDriver
callSettersOnNulls
指定当结果集中值为 null 的时候是否调用映射对象的 setter(map 对象时为 put)方法,这对于有 Map.keySet() 依赖或 null 值初始化的时候是有用的。注意基本类型(int、boolean等)是不能设置成 null 的。
true | false
false
logPrefix
指定 MyBatis 增加到日志名称的前缀。
Any String
Not set
logImpl
指定 MyBatis 所用日志的具体实现,未指定时将自动查找。
SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING
Not set
proxyFactory
指定 Mybatis 创建具有延迟加载能力的对象所用到的代理工具。
CGLIB | JAVASSIST
CGLIB
一个配置完整的 settings 元素的示例如下:
name = "cacheEnabled" value = "true" />
name = "lazyLoadingEnabled" value = "true" />
name = "multipleResultSetsEnabled" value = "true" />
name = "useColumnLabel" value = "true" />
name = "useGeneratedKeys" value = "false" />
name = "autoMappingBehavior" value = "PARTIAL" />
name = "defaultExecutorType" value = "SIMPLE" />
name = "defaultStatementTimeout" value = "25" />
name = "safeRowBoundsEnabled" value = "false" />
name = "mapUnderscoreToCamelCase" value = "false" />
name = "localCacheScope" value = "SESSION" />
name = "jdbcTypeForNull" value = "OTHER" />
name = "lazyLoadTriggerMethods" value = "equals,clone,hashCode,toString" />
Mapper XML 文件
MyBatis 的真正强大在于它的映射语句,也是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 就是针对 SQL 构建的,并且比普通的方法做的更好。
SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
cache – 给定命名空间的缓存配置。cache-ref – 其他命名空间缓存配置的引用。resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。 parameterMap – 已废弃!老式风格的参数映射。内联参数是首选,这个元素可能在将来被移除,这里不会记录。sql – 可被其他语句引用的可重用语句块。insert – 映射插入语句update – 映射更新语句delete – 映射删除语句select – 映射查询语句
下一部分将从语句本身开始来描述每个元素的细节。
select
查询语句是 MyBatis 中最常用的元素之一,光能把数据存到数据库中价值并不大,如果还能重新取出来才有用,多数应用也都是查询比修改要频繁。对每个插入、更新或删除操作,通常对应多个查询操作。这是 MyBatis 的基本原则之一,也是将焦点和努力放到查询和结果映射的原因。简单查询的 select 元素是非常简单的。比如:
id = "selectPerson" parameterType = "int" resultType = "hashmap" >
SELECT * FROM PERSON WHERE ID = #{id}
这个语句被称作 selectPerson,接受一个 int(或 Integer)类型的参数,并返回一个 HashMap 类型的对象,其中的键是列名,值便是结果行中的对应值。
注意参数符号:
这就告诉 MyBatis 创建一个预处理语句参数,通过 JDBC,这样的一个参数在 SQL 中会由一个“?”来标识,并被传递到一个新的预处理语句中,就像这样:
// Similar JDBC code, NOT MyBatis…
String selectPerson = "SELECT * FROM PERSON WHERE ID=?" ;
PreparedStatement ps = conn . prepareStatement ( selectPerson );
ps . setInt ( 1 , id );
当然,这需要很多单独的 JDBC 的代码来提取结果并将它们映射到对象实例中,这就是 MyBatis 节省你时间的地方。我们需要深入了解参数和结果映射,细节部分我们下面来了解。
select 元素有很多属性允许你配置,来决定每条语句的作用细节。
id = "selectPerson"
parameterType = "int"
parameterMap = "deprecated"
resultType = "hashmap"
resultMap = "personResultMap"
flushCache = "false"
useCache = "true"
timeout = "10000"
fetchSize = "256"
statementType = "PREPARED"
resultSetType = "FORWARD_ONLY" >
Select Attributes
属性
描述
id
在命名空间中唯一的标识符,可以被用来引用这条语句。
parameterType
将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。
parameterMap
这是引用外部 parameterMap 的已经被废弃的方法。使用内联参数映射和 parameterType 属性。
resultType
从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用 resultType 或 resultMap,但不能同时使用。
resultMap
外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。使用 resultMap 或 resultType,但不能同时使用。
flushCache
将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false。
useCache
将其设置为 true,将会导致本条语句的结果被二级缓存,默认值:对 select 元素为 true。
timeout
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。
fetchSize
这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为 unset(依赖驱动)。
statementType
STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。
resultSetType
FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)。
databaseId
如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。
resultOrdered
这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false 。
resultSets
这个设置仅对多结果集的情况适用,它将列出语句执行后返回的结果集并每个结果集给一个名称,名称是逗号分隔的。
insert, update 和 delete
数据变更语句 insert,update 和 delete 的实现非常接近:
id = "insertAuthor"
parameterType = "domain.blog.Author"
flushCache = "true"
statementType = "PREPARED"
keyProperty = ""
keyColumn = ""
useGeneratedKeys = ""
timeout = "20" >
id = "updateAuthor"
parameterType = "domain.blog.Author"
flushCache = "true"
statementType = "PREPARED"
timeout = "20" >
id = "deleteAuthor"
parameterType = "domain.blog.Author"
flushCache = "true"
statementType = "PREPARED"
timeout = "20" >
Insert, Update 和 Delete 的属性
属性
描述
id
命名空间中的唯一标识符,可被用来代表这条语句。
parameterType
将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。
parameterMap
这是引用外部 parameterMap 的已经被废弃的方法。使用内联参数映射和 parameterType 属性。
flushCache
将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句)。
timeout
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。
statementType
STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。
useGeneratedKeys
(仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。
keyProperty
(仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset 。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
keyColumn
(仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
databaseId
如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。
下面就是 insert,update 和 delete 语句的示例:
id = "insertAuthor" >
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
id = "updateAuthor" >
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
id = "deleteAuthor" >
delete from Author where id = #{id}
如前所述,插入语句的配置规则更加丰富,在插入语句里面有一些额外的属性和子元素用来处理主键的生成,而且有多种生成方式。
首先,如果你的数据库支持自动生成主键的字段(比如 MySQL 和 SQL Server),那么你可以设置 useGeneratedKeys=”true”,然后再把 keyProperty 设置到目标属性上就OK了。例如,如果上面的 Author 表已经对 id 使用了自动生成的列类型,那么语句可以修改为:
id = "insertAuthor" useGeneratedKeys = "true"
keyProperty = "id" >
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
对于不支持自动生成类型的数据库或可能不支持自动生成主键 JDBC 驱动来说,MyBatis 有另外一种方法来生成主键。
这里有一个简单(甚至很傻)的示例,它可以生成一个随机 ID(你最好不要这么做,但这里展示了 MyBatis 处理问题的灵活性及其所关心的广度):
id = "insertAuthor" >
keyProperty = "id" resultType = "int" order = "BEFORE" >
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
insert into Author
(id, username, password, email,bio, favourite_section)
values
(#{id}, #{username}, #{password}, #{email}, #{bio}, #{favouriteSection,jdbcType=VARCHAR})
在上面的示例中,selectKey 元素将会首先运行,Author 的 id 会被设置,然后插入语句会被调用。这给你了一个和数据库中来处理自动生成的主键类似的行为,避免了使 Java 代码变得复杂。
selectKey 元素描述如下:
keyProperty = "id"
resultType = "int"
order = "BEFORE"
statementType = "PREPARED" >
selectKey 的属性
属性
描述
keyProperty
selectKey 语句结果应该被设置的目标属性。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
keyColumn
匹配属性的返回结果集中的列名称。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
resultType
结果的类型。MyBatis 通常可以推算出来,但是为了更加确定写上也不会有什么问题。MyBatis 允许任何简单类型用作主键的类型,包括字符串。如果希望作用于多个生成的列,则可以使用一个包含期望属性的 Object 或一个 Map。
order
这可以被设置为 BEFORE 或 AFTER。如果设置为 BEFORE,那么它会首先选择主键,设置 keyProperty 然后执行插入语句。如果设置为 AFTER,那么先执行插入语句,然后是 selectKey 元素 - 这和像 Oracle 的数据库相似,在插入语句内部可能有嵌入索引调用。
statementType
与前面相同,MyBatis 支持 STATEMENT,PREPARED 和 CALLABLE 语句的映射类型,分别代表 PreparedStatement 和 CallableStatement 类型。
sql
这个元素可以被用来定义可重用的 SQL 代码段,可以包含在其他语句中。It can be statically (during load phase) parametrized. Different property values can vary in include instances. 比如:
id = "userColumns" > ${alias}.id,${alias}.username,${alias}.password
这个 SQL 片段可以被包含在其他语句中,例如:
id = "selectUsers" resultType = "map" >
select
refid = "userColumns" > name = "alias" value = "t1" /> ,
refid = "userColumns" > name = "alias" value = "t2" />
from some_table t1
cross join some_table t2
Property value can be also used in include refid attribute or property values inside include clause, for example:
id = "sometable" >
${prefix}Table
id = "someinclude" >
from
refid = "${include_target}" />
id = "select" resultType = "map" >
select
field1, field2, field3
refid = "someinclude" >
name = "prefix" value = "Some" />
name = "include_target" value = "sometable" />
参数(Parameters)
前面的所有语句中你所见到的都是简单参数的例子,实际上参数是 MyBatis 非常强大的元素,对于简单的做法,大概 90% 的情况参数都很少,比如:
id = "selectUsers" resultType = "User" >
select id, username, password
from users
where id = #{id}
上面的这个示例说明了一个非常简单的命名参数映射。参数类型被设置为 int ,这样这个参数就可以被设置成任何内容。原生的类型或简单数据类型(比如整型和字符串)因为没有相关属性,它会完全用参数值来替代。然而,如果传入一个复杂的对象,行为就会有一点不同了。比如:
id = "insertUser" parameterType = "User" >
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
如果 User 类型的参数对象传递到了语句中,id、username 和 password 属性将会被查找,然后将它们的值传入预处理语句的参数中。
这点对于向语句中传参是比较好的而且又简单,不过参数映射的功能远不止于此。
首先,像 MyBatis 的其他部分一样,参数也可以指定一个特殊的数据类型。
#{property,javaType=int,jdbcType=NUMERIC}
像 MyBatis 的剩余部分一样,javaType 通常可以从参数对象中来去确定,前提是只要对象不是一个 HashMap。那么 javaType 应该被确定来保证使用正确类型处理器。
NOTE 如果 null 被当作值来传递,对于所有可能为空的列,JDBC Type 是需要的。你可以自己通过阅读预处理语句的 setNull() 方法的 JavaDocs 文档来研究这种情况。
为了以后定制类型处理方式,你也可以指定一个特殊的类型处理器类(或别名),比如:
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
尽管看起来配置变得越来越繁琐,但实际上是很少去设置它们。
对于数值类型,还有一个小数保留位数的设置,来确定小数点后保留的位数。
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
最后,mode 属性允许你指定 IN,OUT 或 INOUT 参数。如果参数为 OUT 或 INOUT,参数对象属性的真实值将会被改变,就像你在获取输出参数时所期望的那样。如果 mode 为 OUT(或 INOUT),而且 jdbcType 为 CURSOR(也就是 Oracle 的 REFCURSOR),你必须指定一个 resultMap 来映射结果集到参数类型。要注意这里的 javaType 属性是可选的,如果左边的空白是 jdbcType 的 CURSOR 类型,它会自动地被设置为结果集。
#{department, mode=OUT, jdbcType=CURSOR, javaType=ResultSet, resultMap=departmentResultMap}
MyBatis 也支持很多高级的数据类型,比如结构体,但是当注册 out 参数时你必须告诉它语句类型名称。比如(再次提示,在实际中要像这样不能换行):
#{middleInitial, mode=OUT, jdbcType=STRUCT, jdbcTypeName=MY_TYPE, resultMap=departmentResultMap}
尽管所有这些强大的选项很多时候你只简单指定属性名,其他的事情 MyBatis 会自己去推断,最多你需要为可能为空的列名指定 jdbcType 。
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
字符串替换
默认情况下,使用#{}格式的语法会导致 MyBatis 创建预处理语句属性并安全地设置值(比如?)。这样做更安全,更迅速,通常也是首选做法,不过有时你只是想直接在 SQL 语句中插入一个不改变的字符串。比如,像 ORDER BY,你可以这样来使用:
这里 MyBatis 不会修改或转义字符串。
NOTE 以这种方式接受从用户输出的内容并提供给语句中不变的字符串是不安全的,会导致潜在的 SQL 注入攻击,因此要么不允许用户输入这些字段,要么自行转义并检验。
Result Maps
resultMap 元素是 MyBatis 中最重要最强大的元素。它就是让你远离 90%的需要从结果 集中取出数据的 JDBC 代码的那个东西, 而且在一些情形下允许你做一些 JDBC 不支持的事 情。 事实上, 编写相似于对复杂语句联合映射这些等同的代码, 也许可以跨过上千行的代码。 ResultMap 的设计就是简单语句不需要明确的结果映射,而很多复杂语句确实需要描述它们 的关系。
你已经看到简单映射语句的示例了,但没有明确的 resultMap。比如:
id = "selectUsers" resultType = "map" >
select id, username, hashedPassword
from some_table
where id = #{id}
这样一个语句简单作用于所有列被自动映射到 HashMap 的键上,这由 resultType 属性 指定。这在很多情况下是有用的,但是 HashMap 不能很好描述一个领域模型。那样你的应 用程序将会使用 JavaBeans 或 POJOs(Plain Old Java Objects,普通 Java 对象)来作为领域 模型。MyBatis 对两者都支持。看看下面这个 JavaBean:
package com . someapp . model ;
public class User {
private int id ;
private String username ;
private String hashedPassword ;
public int getId () {
return id ;
}
public void setId ( int id ) {
this . id = id ;
}
public String getUsername () {
return username ;
}
public void setUsername ( String username ) {
this . username = username ;
}
public String getHashedPassword () {
return hashedPassword ;
}
public void setHashedPassword ( String hashedPassword ) {
this . hashedPassword = hashedPassword ;
}
}
基于 JavaBean 的规范,上面这个类有 3 个属性:id,username 和 hashedPassword。这些 在 select 语句中会精确匹配到列名。
这样的一个 JavaBean 可以被映射到结果集,就像映射到 HashMap 一样简单。
id = "selectUsers" resultType = "com.someapp.model.User" >
select id, username, hashedPassword
from some_table
where id = #{id}
要记住类型别名是你的伙伴。使用它们你可以不用输入类的全路径。比如:
type = "com.someapp.model.User" alias = "User" />
id = "selectUsers" resultType = "User" >
select id, username, hashedPassword
from some_table
where id = #{id}
这些情况下,MyBatis 会在幕后自动创建一个 ResultMap,基于属性名来映射列到 JavaBean 的属性上。如果列名没有精确匹配,你可以在列名上使用 select 字句的别名(一个 基本的 SQL 特性)来匹配标签。比如:
id = "selectUsers" resultType = "User" >
select
user_id as "id",
user_name as "userName",
hashed_password as "hashedPassword"
from some_table
where id = #{id}
ResultMap 最优秀的地方你已经了解了很多了,但是你还没有真正的看到一个。这些简 单的示例不需要比你看到的更多东西。 只是出于示例的原因, 让我们来看看最后一个示例中 外部的 resultMap 是什么样子的,这也是解决列名不匹配的另外一种方式。
id = "userResultMap" type = "User" >
property = "id" column = "user_id" />
property = "username" column = "username" />
property = "password" column = "password" />
引用它的语句使用 resultMap 属性就行了(注意我们去掉了 resultType 属性)。比如:
id = "selectUsers" resultMap = "userResultMap" >
select user_id, user_name, hashed_password
from some_table
where id = #{id}
如果世界总是这么简单就好了。
高级结果映射
MyBatis 创建的一个想法:数据库不用永远是你想要的或需要它们是什么样的。而我们 最喜欢的数据库最好是第三范式或 BCNF 模式,但它们有时不是。如果可能有一个单独的 数据库映射,所有应用程序都可以使用它,这是非常好的,但有时也不是。结果映射就是 MyBatis 提供处理这个问题的答案。
比如,我们如何映射下面这个语句?
id = "selectBlogDetails" resultMap = "detailedBlogResultMap" >
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio,
A.favourite_section as author_favourite_section,
P.id as post_id,
P.blog_id as post_blog_id,
P.author_id as post_author_id,
P.created_on as post_created_on,
P.section as post_section,
P.subject as post_subject,
P.draft as draft,
P.body as post_body,
C.id as comment_id,
C.post_id as comment_post_id,
C.name as comment_name,
C.comment as comment_text,
T.id as tag_id,
T.name as tag_name
from Blog B
left outer join Author A on B.author_id = A.id
left outer join Post P on B.id = P.blog_id
left outer join Comment C on P.id = C.post_id
left outer join Post_Tag PT on PT.post_id = P.id
left outer join Tag T on PT.tag_id = T.id
where B.id = #{id}
你可能想把它映射到一个智能的对象模型,包含一个作者写的博客,有很多的博文,每 篇博文有零条或多条的评论和标签。 下面是一个完整的复杂结果映射例子 (假设作者, 博客, 博文, 评论和标签都是类型的别名) 我们来看看, 。 但是不用紧张, 我们会一步一步来说明。 当天最初它看起来令人生畏,但实际上非常简单。
id = "detailedBlogResultMap" type = "Blog" >
column = "blog_id" javaType = "int" />
property = "title" column = "blog_title" />
property = "author" javaType = "Author" >
property = "id" column = "author_id" />
property = "username" column = "author_username" />
property = "password" column = "author_password" />
property = "email" column = "author_email" />
property = "bio" column = "author_bio" />
property = "favouriteSection" column = "author_favourite_section" />
property = "posts" ofType = "Post" >
property = "id" column = "post_id" />
property = "subject" column = "post_subject" />
property = "author" javaType = "Author" />
property = "comments" ofType = "Comment" >
property = "id" column = "comment_id" />
property = "tags" ofType = "Tag" >
property = "id" column = "tag_id" />
javaType = "int" column = "draft" >
value = "1" resultType = "DraftPost" />
resultMap 元素有很多子元素和一个值得讨论的结构。 下面是 resultMap 元素的概念视图
resultMap
constructor - 类在实例化时,用来注入结果到构造方法中
idArg - ID 参数;标记结果作为 ID 可以帮助提高整体效能arg - 注入到构造方法的一个普通结果 id – 一个 ID 结果;标记结果作为 ID 可以帮助提高整体效能result – 注入到字段或 JavaBean 属性的普通结果association – 一个复杂的类型关联;许多结果将包成这种类型
嵌入结果映射 – 结果映射自身的关联,或者参考一个
collection – 复杂类型的集
discriminator – 使用结果值来决定使用哪个结果映射
case – 基于某些值的结果映射
嵌入结果映射 – 这种情形结果也映射它本身,因此可以包含很多相 同的元素,或者它可以参照一个外部的结果映射。
ResultMap Attributes
Attribute
Description
id
A unique identifier in this namespace that can be used to reference this result map.
type
A fully qualified Java class name, or a type alias (see the table above for the list of built-in type aliases).
autoMapping
If present, MyBatis will enable or disable the automapping for this ResultMap. This attribute overrides the global autoMappingBehavior. Default: unset.
最佳实践 通常逐步建立结果映射。单元测试的真正帮助在这里。如果你尝试创建 一次创建一个向上面示例那样的巨大的结果映射, 那么可能会有错误而且很难去控制它 来工作。开始简单一些,一步一步的发展。而且要进行单元测试!使用该框架的缺点是 它们有时是黑盒(是否可见源代码) 。你确定你实现想要的行为的最好选择是编写单元 测试。它也可以你帮助得到提交时的错误。
下面一部分将详细说明每个元素。
id & result
property = "id" column = "post_id" />
property = "subject" column = "post_subject" />
这些是结果映射最基本内容。id 和 result 都映射一个单独列的值到简单数据类型(字符 串,整型,双精度浮点数,日期等)的单独属性或字段。
这两者之间的唯一不同是 id 表示的结果将是当比较对象实例时用到的标识属性。这帮 助来改进整体表现,特别是缓存和嵌入结果映射(也就是联合映射) 。
每个都有一些属性:
Id and Result Attributes
属性
描述
property
映射到列结果的字段或属性。如果匹配的是存在的,和给定名称相同 的 JavaBeans 的属性,那么就会使用。否则 MyBatis 将会寻找给定名称 property 的字段。这两种情形你可以使用通常点式的复杂属性导航。比如,你 可以这样映射一些东西: “username” ,或者映射到一些复杂的东西: “address.street.number” 。
column
从数据库中得到的列名,或者是列名的重命名标签。这也是通常和会 传递给 resultSet.getString(columnName)方法参数中相同的字符串。
javaType
一个 Java 类的完全限定名,或一个类型别名(参考上面内建类型别名 的列表) 。如果你映射到一个 JavaBean,MyBatis 通常可以断定类型。 然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证所需的行为。
jdbcType
在这个表格之后的所支持的 JDBC 类型列表中的类型。JDBC 类型是仅 仅需要对插入,更新和删除操作可能为空的列进行处理。这是 JDBC jdbcType 的需要,而不是 MyBatis 的。如果你直接使用 JDBC 编程,你需要指定 这个类型-但仅仅对可能为空的值。
typeHandler
我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默 认的类型处理器。这个属性值是类的完全限定名或者是一个类型处理 器的实现,或者是类型别名。
支持的 JDBC 类型
为了未来的参考,MyBatis 通过包含的 jdbcType 枚举型,支持下面的 JDBC 类型。
BIT
FLOAT
CHAR
TIMESTAMP
OTHER
UNDEFINED
TINYINT
REAL
VARCHAR
BINARY
BLOG
NVARCHAR
SMALLINT
DOUBLE
LONGVARCHAR
VARBINARY
CLOB
NCHAR
INTEGER
NUMERIC
DATE
LONGVARBINARY
BOOLEAN
NCLOB
BIGINT
DECIMAL
TIME
NULL
CURSOR
ARRAY
构造方法
column = "id" javaType = "int" />
column = "username" javaType = "String" />
对于大多数数据传输对象(Data Transfer Object,DTO)类型,属性可以起作用,而且像 你绝大多数的领域模型, 指令也许是你想使用一成不变的类的地方。 通常包含引用或查询数 据的表很少或基本不变的话对一成不变的类来说是合适的。 构造方法注入允许你在初始化时 为类设置属性的值,而不用暴露出公有方法。MyBatis 也支持私有属性和私有 JavaBeans 属 性来达到这个目的,但是一些人更青睐构造方法注入。构造方法元素支持这个。
看看下面这个构造方法:
public class User {
//...
public User ( int id , String username ) {
//...
}
//...
}
为了向这个构造方法中注入结果,MyBatis 需要通过它的参数的类型来标识构造方法。 Java 没有自查(反射)参数名的方法。所以当创建一个构造方法元素时,保证参数是按顺序 排列的,而且数据类型也是确定的。
column = "id" javaType = "int" />
column = "username" javaType = "String" />
剩余的属性和规则和固定的 id 和 result 元素是相同的。
属性
描述
column
来自数据库的类名,或重命名的列标签。这和通常传递给 resultSet.getString(columnName)方法的字符串是相同的。
javaType
一个 Java 类的完全限定名,或一个类型别名(参考上面内建类型别名的列表)。 如果你映射到一个 JavaBean,MyBatis 通常可以断定类型。然而,如 果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证所需的 行为。
jdbcType
在这个表格之前的所支持的 JDBC 类型列表中的类型。JDBC 类型是仅仅 需要对插入, 更新和删除操作可能为空的列进行处理。这是 JDBC 的需要, jdbcType 而不是 MyBatis 的。如果你直接使用 JDBC 编程,你需要指定这个类型-但 仅仅对可能为空的值。
typeHandler
我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的 类型处理器。 这个属性值是类的完全限定名或者是一个类型处理器的实现, 或者是类型别名。
select
The ID of another mapped statement that will load the complex type required by this property mapping. The values retrieved from columns specified in the column attribute will be passed to the target select statement as parameters. See the Association element for more.
resultMap
This is the ID of a ResultMap that can map the nested results of this argument into an appropriate object graph. This is an alternative to using a call to another select statement. It allows you to join multiple tables together into a single ResultSet . Such a ResultSet will contain duplicated, repeating groups of data that needs to be decomposed and mapped properly to a nested object graph. To facilitate this, MyBatis lets you "chain" result maps together, to deal with the nested results. See the Association element below for more.
关联
property = "author" column = "blog_author_id" javaType = "Author" >
property = "id" column = "author_id" />
property = "username" column = "author_username" />
关联元素处理“有一个”类型的关系。比如,在我们的示例中,一个博客有一个用户。 关联映射就工作于这种结果之上。你指定了目标属性,来获取值的列,属性的 java 类型(很 多情况下 MyBatis 可以自己算出来) ,如果需要的话还有 jdbc 类型,如果你想覆盖或获取的 结果值还需要类型控制器。
关联中不同的是你需要告诉 MyBatis 如何加载关联。MyBatis 在这方面会有两种不同的 方式:
嵌套查询:通过执行另外一个 SQL 映射语句来返回预期的复杂类型。
嵌套结果:使用嵌套结果映射来处理重复的联合结果的子集。首先,然让我们来查看这个元素的属性。所有的你都会看到,它和普通的只由 select 和
resultMap 属性的结果映射不同。
属性
描述
property
映射到列结果的字段或属性。如果匹配的是存在的,和给定名称相同的 property JavaBeans 的属性, 那么就会使用。 否则 MyBatis 将会寻找给定名称的字段。 这两种情形你可以使用通常点式的复杂属性导航。比如,你可以这样映射 一 些 东 西 :“ username ”, 或 者 映 射 到 一 些 复 杂 的 东 西 : “address.street.number” 。
javaType
一个 Java 类的完全限定名,或一个类型别名(参考上面内建类型别名的列 表) 。如果你映射到一个 JavaBean,MyBatis 通常可以断定类型。然而,如 javaType 果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证所需的 行为。
jdbcType
在这个表格之前的所支持的 JDBC 类型列表中的类型。JDBC 类型是仅仅 需要对插入, 更新和删除操作可能为空的列进行处理。这是 JDBC 的需要, jdbcType 而不是 MyBatis 的。如果你直接使用 JDBC 编程,你需要指定这个类型-但 仅仅对可能为空的值。
typeHandler
我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的 typeHandler 类型处理器。 这个属性值是类的完全限定名或者是一个类型处理器的实现, 或者是类型别名。
关联的嵌套查询
属性
描述
column
来自数据库的类名,或重命名的列标签。这和通常传递给 resultSet.getString(columnName)方法的字符串是相同的。 column 注 意 : 要 处 理 复 合 主 键 , 你 可 以 指 定 多 个 列 名 通 过 column= ” {prop1=col1,prop2=col2} ” 这种语法来传递给嵌套查询语 句。这会引起 prop1 和 prop2 以参数对象形式来设置给目标嵌套查询语句。
select
另外一个映射语句的 ID,可以加载这个属性映射需要的复杂类型。获取的 在列属性中指定的列的值将被传递给目标 select 语句作为参数。表格后面 有一个详细的示例。 select 注 意 : 要 处 理 复 合 主 键 , 你 可 以 指 定 多 个 列 名 通 过 column= ” {prop1=col1,prop2=col2} ” 这种语法来传递给嵌套查询语 句。这会引起 prop1 和 prop2 以参数对象形式来设置给目标嵌套查询语句。
fetchType
Optional. Valid values are lazy and eager . If present, it supersedes the global configuration parameter lazyLoadingEnabled for this mapping.
示例:
id = "blogResult" type = "Blog" >
property = "author" column = "author_id" javaType = "Author" select = "selectAuthor" />
id = "selectBlog" resultMap = "blogResult" >
SELECT * FROM BLOG WHERE ID = #{id}
id = "selectAuthor" resultType = "Author" >
SELECT * FROM AUTHOR WHERE ID = #{id}
我们有两个查询语句:一个来加载博客,另外一个来加载作者,而且博客的结果映射描 述了“selectAuthor”语句应该被用来加载它的 author 属性。
其他所有的属性将会被自动加载,假设它们的列和属性名相匹配。
这种方式很简单, 但是对于大型数据集合和列表将不会表现很好。 问题就是我们熟知的 “N+1 查询问题”。概括地讲,N+1 查询问题可以是这样引起的:
你执行了一个单独的 SQL 语句来获取结果列表(就是“+1”)。
对返回的每条记录,你执行了一个查询语句来为每个加载细节(就是“N”)。
这个问题会导致成百上千的 SQL 语句被执行。这通常不是期望的。
MyBatis 能延迟加载这样的查询就是一个好处,因此你可以分散这些语句同时运行的消 耗。然而,如果你加载一个列表,之后迅速迭代来访问嵌套的数据,你会调用所有的延迟加 载,这样的行为可能是很糟糕的。
所以还有另外一种方法。
关联的嵌套结果
属性
描述
resultMap
这是结果映射的 ID,可以映射关联的嵌套结果到一个合适的对象图中。这 是一种替代方法来调用另外一个查询语句。这允许你联合多个表来合成到 resultMap 一个单独的结果集。这样的结果集可能包含重复,数据的重复组需要被分 解,合理映射到一个嵌套的对象图。为了使它变得容易,MyBatis 让你“链 接”结果映射,来处理嵌套结果。一个例子会很容易来仿照,这个表格后 面也有一个示例。
columnPrefix
When joining multiple tables, you would have to use column alias to avoid duplicated column names in the ResultSet. Specifying columnPrefix allows you to map such columns to an external resultMap. Please see the example explained later in this section.
notNullColumn
By default a child object is created only if at least one of the columns mapped to the child's properties is non null. With this attribute you can change this behaviour by specifiying which columns must have a value so MyBatis will create a child object only if any of those columns is not null. Multiple column names can be specified using a comma as a separator. Default value: unset.
autoMapping
If present, MyBatis will enable or disable auto-mapping when mapping the result to this property. This attribute overrides the global autoMappingBehavior. Note that it has no effect on an external resultMap, so it is pointless to use it with select or resultMap attribute. Default value: unset.
在上面你已经看到了一个非常复杂的嵌套关联的示例。 下面这个是一个非常简单的示例 来说明它如何工作。代替了执行一个分离的语句,我们联合博客表和作者表在一起,就像:
id = "selectBlog" resultMap = "blogResult" >
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio
from Blog B left outer join Author A on B.author_id = A.id
where B.id = #{id}
注意这个联合查询, 以及采取保护来确保所有结果被唯一而且清晰的名字来重命名。 这使得映射非常简单。现在我们可以映射这个结果:
id = "blogResult" type = "Blog" >
property = "id" column = "blog_id" />
property = "title" column = "blog_title" />
property = "author" column = "blog_author_id" javaType = "Author" resultMap = "authorResult" />
id = "authorResult" type = "Author" >
property = "id" column = "author_id" />
property = "username" column = "author_username" />
property = "password" column = "author_password" />
property = "email" column = "author_email" />
property = "bio" column = "author_bio" />
在上面的示例中你可以看到博客的作者关联代表着“authorResult”结果映射来加载作 者实例。
非常重要 : 在嵌套据诶过映射中 id 元素扮演了非常重要的角色。应应该通常指定一个 或多个属性,它们可以用来唯一标识结果。实际上就是如果你离开她了,但是有一个严重的 性能问题时 MyBatis 仍然可以工作。选择的属性越少越好,它们可以唯一地标识结果。主键 就是一个显而易见的选择(尽管是联合主键)。
现在,上面的示例用了外部的结果映射元素来映射关联。这使得 Author 结果映射可以 重用。然而,如果你不需要重用它的话,或者你仅仅引用你所有的结果映射合到一个单独描 述的结果映射中。你可以嵌套结果映射。这里给出使用这种方式的相同示例:
id = "blogResult" type = "Blog" >
property = "id" column = "blog_id" />
property = "title" column = "blog_title" />
property = "author" javaType = "Author" >
property = "id" column = "author_id" />
property = "username" column = "author_username" />
property = "password" column = "author_password" />
property = "email" column = "author_email" />
property = "bio" column = "author_bio" />
What if the blog has a co-author? The select statement would look like:
id = "selectBlog" resultMap = "blogResult" >
select
B.id as blog_id,
B.title as blog_title,
A.id as author_id,
A.username as author_username,
A.password as author_password,
A.email as author_email,
A.bio as author_bio,
CA.id as co_author_id,
CA.username as co_author_username,
CA.password as co_author_password,
CA.email as co_author_email,
CA.bio as co_author_bio
from Blog B
left outer join Author A on B.author_id = A.id
left outer join Author CA on B.co_author_id = CA.id
where B.id = #{id}
Recall that the resultMap for Author is defined as follows.
id = "authorResult" type = "Author" >
property = "id" column = "author_id" />
property = "username" column = "author_username" />
property = "password" column = "author_password" />
property = "email" column = "author_email" />
property = "bio" column = "author_bio" />
Because the column names in the results differ from the columns defined in the resultMap, you need to specify columnPrefix to reuse the resultMap for mapping co-author results.
id = "blogResult" type = "Blog" >
property = "id" column = "blog_id" />
property = "title" column = "blog_title" />
property = "author"
resultMap = "authorResult" />
property = "coAuthor"
resultMap = "authorResult"
columnPrefix = "co_" />
上面你已经看到了如何处理“有一个”类型关联。但是“有很多个”是怎样的?下面这 个部分就是来讨论这个主题的。
集合
property = "posts" ofType = "domain.blog.Post" >
property = "id" column = "post_id" />
property = "subject" column = "post_subject" />
property = "body" column = "post_body" />
集合元素的作用几乎和关联是相同的。实际上,它们也很相似,文档的异同是多余的。 所以我们更多关注于它们的不同。
我们来继续上面的示例,一个博客只有一个作者。但是博客有很多文章。在博客类中, 这可以由下面这样的写法来表示:
private List < Post > posts ;
要映射嵌套结果集合到 List 中,我们使用集合元素。就像关联元素一样,我们可以从 连接中使用嵌套查询,或者嵌套结果。
集合的嵌套查询
首先,让我们看看使用嵌套查询来为博客加载文章。
id = "blogResult" type = "Blog" >
property = "posts" javaType = "ArrayList" column = "id" ofType = "Post" select = "selectPostsForBlog" />
id = "selectBlog" resultMap = "blogResult" >
SELECT * FROM BLOG WHERE ID = #{id}
id = "selectPostsForBlog" resultType = "Blog" >
SELECT * FROM POST WHERE BLOG_ID = #{id}
这里你应该注意很多东西,但大部分代码和上面的关联元素是非常相似的。首先,你应 该注意我们使用的是集合元素。然后要注意那个新的“ofType”属性。这个属性用来区分 JavaBean(或字段)属性类型和集合包含的类型来说是很重要的。所以你可以读出下面这个 映射:
property = "posts" javaType = "ArrayList" column = "id" ofType = "Post" select = "selectPostsForBlog" />
读作 : “在 Post 类型的 ArrayList 中的 posts 的集合。”
javaType 属性是不需要的,因为 MyBatis 在很多情况下会为你算出来。所以你可以缩短 写法:
property = "posts" column = "id" ofType = "Post" select = "selectPostsForBlog" />
集合的嵌套结果
至此,你可以猜测集合的嵌套结果是如何来工作的,因为它和关联完全相同,除了它应 用了一个“ofType”属性
First, let's look at the SQL:
id = "selectBlog" resultMap = "blogResult" >
select
B.id as blog_id,
B.title as blog_title,
B.author_id as blog_author_id,
P.id as post_id,
P.subject as post_subject,
P.body as post_body,
from Blog B
left outer join Post P on B.id = P.blog_id
where B.id = #{id}
我们又一次联合了博客表和文章表,而且关注于保证特性,结果列标签的简单映射。现 在用文章映射集合映射博客,可以简单写为:
id = "blogResult" type = "Blog" >
property = "id" column = "blog_id" />
property = "title" column = "blog_title" />
property = "posts" ofType = "Post" >
property = "id" column = "post_id" />
property = "subject" column = "post_subject" />
property = "body" column = "post_body" />
同样,要记得 id 元素的重要性,如果你不记得了,请阅读上面的关联部分。
同样, 如果你引用更长的形式允许你的结果映射的更多重用, 你可以使用下面这个替代 的映射:
id = "blogResult" type = "Blog" >
property = "id" column = "blog_id" />
property = "title" column = "blog_title" />
property = "posts" ofType = "Post" resultMap = "blogPostResult" columnPrefix = "post_" />
id = "blogPostResult" type = "Post" >
property = "id" column = "id" />
property = "subject" column = "subject" />
property = "body" column = "body" />
注意 这个对你所映射的内容没有深度,广度或关联和集合相联合的限制。当映射它们 时你应该在大脑中保留它们的表现。 你的应用在找到最佳方法前要一直进行的单元测试和性 能测试。好在 myBatis 让你后来可以改变想法,而不对你的代码造成很小(或任何)影响。
高级关联和集合映射是一个深度的主题。文档只能给你介绍到这了。加上一点联系,你 会很快清楚它们的用法。
鉴别器
javaType = "int" column = "draft" >
value = "1" resultType = "DraftPost" />
有时一个单独的数据库查询也许返回很多不同 (但是希望有些关联) 数据类型的结果集。 鉴别器元素就是被设计来处理这个情况的, 还有包括类的继承层次结构。 鉴别器非常容易理 解,因为它的表现很像 Java 语言中的 switch 语句。
定义鉴别器指定了 column 和 javaType 属性。 列是 MyBatis 查找比较值的地方。 JavaType 是需要被用来保证等价测试的合适类型(尽管字符串在很多情形下都会有用)。比如:
id = "vehicleResult" type = "Vehicle" >
property = "id" column = "id" />
property = "vin" column = "vin" />
property = "year" column = "year" />
property = "make" column = "make" />
property = "model" column = "model" />
property = "color" column = "color" />
javaType = "int" column = "vehicle_type" >
value = "1" resultMap = "carResult" />
value = "2" resultMap = "truckResult" />
value = "3" resultMap = "vanResult" />
value = "4" resultMap = "suvResult" />
在这个示例中, MyBatis 会从结果集中得到每条记录, 然后比较它的 vehicle 类型的值。 如果它匹配任何一个鉴别器的实例,那么就使用这个实例指定的结果映射。换句话说,这样 做完全是剩余的结果映射被忽略(除非它被扩展,这在第二个示例中讨论) 。如果没有任何 一个实例相匹配,那么 MyBatis 仅仅使用鉴别器块外定义的结果映射。所以,如果 carResult 按如下声明:
id = "carResult" type = "Car" >
property = "doorCount" column = "door_count" />
那么只有 doorCount 属性会被加载。这步完成后完整地允许鉴别器实例的独立组,尽管 和父结果映射可能没有什么关系。这种情况下,我们当然知道 cars 和 vehicles 之间有关系, 如 Car 是一个 Vehicle 实例。因此,我们想要剩余的属性也被加载。我们设置的结果映射的 简单改变如下。
id = "carResult" type = "Car" extends = "vehicleResult" >
property = "doorCount" column = "door_count" />
现在 vehicleResult 和 carResult 的属性都会被加载了。
尽管曾经有些人会发现这个外部映射定义会多少有一些令人厌烦之处。 因此还有另外一 种语法来做简洁的映射风格。比如:
id = "vehicleResult" type = "Vehicle" >
property = "id" column = "id" />
property = "vin" column = "vin" />
property = "year" column = "year" />
property = "make" column = "make" />
property = "model" column = "model" />
property = "color" column = "color" />
javaType = "int" column = "vehicle_type" >
value = "1" resultType = "carResult" >
property = "doorCount" column = "door_count" />
value = "2" resultType = "truckResult" >
property = "boxSize" column = "box_size" />
property = "extendedCab" column = "extended_cab" />
value = "3" resultType = "vanResult" >
property = "powerSlidingDoor" column = "power_sliding_door" />
value = "4" resultType = "suvResult" >
property = "allWheelDrive" column = "all_wheel_drive" />
要记得 这些都是结果映射, 如果你不指定任何结果, 那么 MyBatis 将会为你自动匹配列 和属性。所以这些例子中的大部分是很冗长的,而其实是不需要的。也就是说,很多数据库 是很复杂的,我们不太可能对所有示例都能依靠它。
自动映射
正如你在前面一节看到的,在简单的场景下,MyBatis可以替你自动映射查询结果。 如果遇到复杂的场景,你需要构建一个result map。 但是在本节你将看到,你也可以混合使用这两种策略。 让我们到深一点的层面上看看自动映射是怎样工作的。
当自动映射查询结果时,MyBatis会获取sql返回的列名并在java类中查找相同名字的属性(忽略大小写)。 这意味着如果Mybatis发现了ID 列和id 属性,Mybatis会将ID 的值赋给id 。
通常数据库列使用大写单词命名,单词间用下划线分隔;而java属性一般遵循驼峰命名法。 为了在这两种命名方式之间启用自动映射,需要将 mapUnderscoreToCamelCase 设置为true。
自动映射甚至在特定的result map下也能工作。在这种情况下,对于每一个result map,所有的ResultSet提供的列, 如果没有被手工映射,则将被自动映射。自动映射处理完毕后手工映射才会被处理。 在接下来的例子中, id 和 userName 列将被自动映射, hashed_password 列将根据配置映射。
id = "selectUsers" resultMap = "userResultMap" >
select
user_id as "id",
user_name as "userName",
hashed_password
from some_table
where id = #{id}
id = "userResultMap" type = "User" >
property = "password" column = "hashed_password" />
There are three auto-mapping levels:
NONE - disables auto-mapping. Only manually mapped properties will be set.PARTIAL - will auto-map results except those that have nested result mappings defined inside (joins).FULL - auto-maps everything.
The default value is PARTIAL , and it is so for a reason. When FULL is used auto-mapping will be performed when processing join results and joins retrieve data of several different entities in the same row hence this may result in undesired mappings. To understand the risk have a look at the following sample:
id = "selectBlog" resultMap = "blogResult" >
select
B.id,
B.title,
A.username,
from Blog B left outer join Author A on B.author_id = A.id
where B.id = #{id}
id = "blogResult" type = "Blog" >
property = "author" resultMap = "authorResult" />
id = "authorResult" type = "Author" >
property = "username" column = "author_username" />
With this result map both Blog and Author will be auto-mapped. But note that Author has an id property and there is a column named id in the ResultSet so Author's id will be filled with Blog's id, and that is not what you were expecting. So use the FULL option with caution.
Regardless of the auto-mapping level configured you can enable or disable the automapping for an specific ResultMap by adding the attribute autoMapping to it:
id = "userResultMap" type = "User" autoMapping = "false" >
property = "password" column = "hashed_password" />
缓存
MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制。MyBatis 3 中的缓存实现的很多改进都已经实现了,使得它更加强大而且易于配置。
默认情况下是没有开启缓存的,除了局部的 session 缓存,可以增强变现而且处理循环 依赖也是必须的。要开启二级缓存,你需要在你的 SQL 映射文件中添加一行:
字面上看就是这样。这个简单语句的效果如下:
映射语句文件中的所有 select 语句将会被缓存。
映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。比如:
eviction = "FIFO"
flushInterval = "60000"
size = "512"
readOnly = "true" />
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会 导致冲突。
可用的收回策略有:
LRU – 最近最少使用的:移除最长时间不被使用的对象。FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒 形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的 可用内存资源数目。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓 存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存 会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
使用自定义缓存
除了这些自定义缓存的方式, 你也可以通过实现你自己的缓存或为其他第三方缓存方案 创建适配器来完全覆盖缓存行为。
type = "com.domain.something.MyCustomCache" />
这个示 例展 示了 如何 使用 一个 自定义 的缓 存实 现。type 属 性指 定的 类必 须实现 org.mybatis.cache.Cache 接口。这个接口是 MyBatis 框架中很多复杂的接口之一,但是简单 给定它做什么就行。
public interface Cache {
String getId ();
int getSize ();
void putObject ( Object key , Object value );
Object getObject ( Object key );
boolean hasKey ( Object key );
Object removeObject ( Object key );
void clear ();
}
要配置你的缓存, 简单和公有的 JavaBeans 属性来配置你的缓存实现, 而且是通过 cache 元素来传递属性, 比如, 下面代码会在你的缓存实现中调用一个称为 “setCacheFile(String file)” 的方法:
type = "com.domain.something.MyCustomCache" >
name = "cacheFile" value = "/tmp/my-custom-cache.tmp" />
你可以使用所有简单类型作为 JavaBeans 的属性,MyBatis 会进行转换。
记得缓存配置和缓存实例是绑定在 SQL 映射文件的命名空间是很重要的。因此,所有 在相同命名空间的语句正如绑定的缓存一样。 语句可以修改和缓存交互的方式, 或在语句的 语句的基础上使用两种简单的属性来完全排除它们。默认情况下,语句可以这样来配置:
... flushCache = "false" useCache = "true" />
... flushCache = "true" />
... flushCache = "true" />
... flushCache = "true" />
因为那些是默认的,你明显不能明确地以这种方式来配置一条语句。相反,如果你想改 变默认的行为,只能设置 flushCache 和 useCache 属性。比如,在一些情况下你也许想排除 从缓存中查询特定语句结果,或者你也许想要一个查询语句来刷新缓存。相似地,你也许有 一些更新语句依靠执行而不需要刷新缓存。
参照缓存
回想一下上一节内容, 这个特殊命名空间的唯一缓存会被使用或者刷新相同命名空间内 的语句。也许将来的某个时候,你会想在命名空间中共享相同的缓存配置和实例。在这样的 情况下你可以使用 cache-ref 元素来引用另外一个缓存。
namespace = "com.someone.application.data.SomeMapper" />
动态 SQL
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其他类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句有多么痛苦。拼接的时候要确保不能忘了必要的空格,还要注意省掉列名列表最后的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
通常使用动态 SQL 不可能是独立的一部分,MyBatis 当然使用一种强大的动态 SQL 语言来改进这种情形,这种语言可以被用在任意的 SQL 映射语句中。
动态 SQL 元素和使用 JSTL 或其他类似基于 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多的元素需要来了解。MyBatis 3 大大提升了它们,现在用不到原先一半的元素就可以了。MyBatis 采用功能强大的基于 OGNL 的表达式来消除其他元素。
if
choose (when, otherwise)
trim (where, set)
foreach
if
动态 SQL 通常要做的事情是有条件地包含 where 子句的一部分。比如:
id = "findActiveBlogWithTitleLike"
resultType = "Blog" >
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
test = "title != null" >
AND title like #{title}
这条语句提供了一个可选的文本查找类型的功能。如果没有传入“title”,那么所有处于“ACTIVE”状态的BLOG都会返回;反之若传入了“title”,那么就会把模糊查找“title”内容的BLOG结果返回(就这个例子而言,细心的读者会发现其中的参数值是可以包含一些掩码或通配符的)。
如果想可选地通过“title”和“author”两个条件搜索该怎么办呢?首先,改变语句的名称让它更具实际意义;然后只要加入另一个条件即可。
id = "findActiveBlogLike"
resultType = "Blog" >
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
test = "title != null" >
AND title like #{title}
test = "author != null and author.name != null" >
AND author_name like #{author.name}
choose, when, otherwise
有些时候,我们不想用到所有的条件语句,而只想从中择其一二。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
还是上面的例子,但是这次变为提供了“title”就按“title”查找,提供了“author”就按“author”查找,若两者都没有提供,就返回所有符合条件的BLOG(实际情况可能是由管理员按一定策略选出BLOG列表,而不是返回大量无意义的随机结果)。
id = "findActiveBlogLike"
resultType = "Blog" >
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
test = "title != null" >
AND title like #{title}
test = "author != null and author.name != null" >
AND author_name like #{author.name}
AND featured = 1
trim, where, set
前面几个例子已经合宜地解决了一个臭名昭著的动态 SQL 问题。现在考虑回到“if”示例,这次我们将“ACTIVE = 1”也设置成动态的条件,看看会发生什么。
id = "findActiveBlogLike"
resultType = "Blog" >
SELECT * FROM BLOG
WHERE
test = "state != null" >
state = #{state}
test = "title != null" >
AND title like #{title}
test = "author != null and author.name != null" >
AND author_name like #{author.name}
如果这些条件没有一个能匹配上将会怎样?最终这条 SQL 会变成这样:
这会导致查询失败。如果仅仅第二个条件匹配又会怎样?这条 SQL 最终会是这样:
SELECT * FROM BLOG
WHERE
AND title like ‘ someTitle ’
这个查询也会失败。这个问题不能简单的用条件句式来解决,如果你也曾经被迫这样写过,那么你很可能从此以后都不想再这样去写了。
MyBatis 有一个简单的处理,这在90%的情况下都会有用。而在不能使用的地方,你可以自定义处理方式来令其正常工作。一处简单的修改就能得到想要的效果:
id = "findActiveBlogLike"
resultType = "Blog" >
SELECT * FROM BLOG
test = "state != null" >
state = #{state}
test = "title != null" >
AND title like #{title}
test = "author != null and author.name != null" >
AND author_name like #{author.name}
where 元素知道只有在一个以上的if条件有值的情况下才去插入“WHERE”子句。而且,若最后的内容是“AND”或“OR”开头的,where 元素也知道如何将他们去除。
如果 where 元素没有按正常套路出牌,我们还是可以通过自定义 trim 元素来定制我们想要的功能。比如,和 where 元素等价的自定义 trim 元素为:
prefix = "WHERE" prefixOverrides = "AND |OR " >
...
prefixOverrides 属性会忽略通过管道分隔的文本序列(注意此例中的空格也是必要的)。它带来的结果就是所有在 prefixOverrides 属性中指定的内容将被移除,并且插入 prefix 属性中指定的内容。
类似的用于动态更新语句的解决方案叫做 set。set 元素可以被用于动态包含需要更新的列,而舍去其他的。比如:
id = "updateAuthorIfNecessary" >
update Author
test = "username != null" > username=#{username},
test = "password != null" > password=#{password},
test = "email != null" > email=#{email},
test = "bio != null" > bio=#{bio}
where id=#{id}
这里,set 元素会动态前置 SET 关键字,同时也会消除无关的逗号,因为用了条件语句之后很可能就会在生成的赋值语句的后面留下这些逗号。
若你对等价的自定义 trim 元素的样子感兴趣,那这就应该是它的真面目:
prefix = "SET" suffixOverrides = "," >
...
注意这里我们忽略的是后缀中的值,而又一次附加了前缀中的值。
foreach
动态 SQL 的另外一个常用的必要操作是需要对一个集合进行遍历,通常是在构建 IN 条件语句的时候。比如:
id = "selectPostIn" resultType = "domain.blog.Post" >
SELECT *
FROM POST P
WHERE ID in
item = "item" index = "index" collection = "list"
open = "(" separator = "," close = ")" >
#{item}
foreach 元素的功能是非常强大的,它允许你指定一个集合,声明可以用在元素体内的集合项和索引变量。它也允许你指定开闭匹配的字符串以及在迭代中间放置分隔符。这个元素是很智能的,因此它不会偶然地附加多余的分隔符。
注意 你可以将一个 List 实例或者数组作为参数对象传给 MyBatis,当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中并以名称为键。List 实例将会以“list”作为键,而数组实例的键将是“array”。
到此我们已经完成了涉及 XML 配置文件和 XML 映射文件的讨论。下一部分将详细探讨 Java API,这样才能从已创建的映射中获取最大利益。
bind
bind 元素可以从 OGNL 表达式中创建一个变量并将其绑定到上下文。比如:
id = "selectBlogsLike" resultType = "Blog" >
name = "pattern" value = "'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
Multi-db vendor support
一个配置了“_databaseId”变量的 databaseIdProvider 对于动态代码来说是可用的,这样就可以根据不同的数据库厂商构建特定的语句。比如下面的例子:
id = "insert" >
keyProperty = "id" resultType = "int" order = "BEFORE" >
test = "_databaseId == 'oracle'" >
select seq_users.nextval from dual
test = "_databaseId == 'db2'" >
select nextval for seq_users from sysibm.sysdummy1"
insert into users values (#{id}, #{name})
动态 SQL 中可插拔的脚本语言
MyBatis 从 3.2 开始支持可插拔的脚本语言,因此你可以在插入一种语言的驱动(language driver)之后来写基于这种语言的动态 SQL 查询。
可以通过实现下面接口的方式来插入一种语言:
public interface LanguageDriver {
ParameterHandler createParameterHandler ( MappedStatement mappedStatement , Object parameterObject , BoundSql boundSql );
SqlSource createSqlSource ( Configuration configuration , XNode script , Class parameterType );
SqlSource createSqlSource ( Configuration configuration , String script , Class parameterType );
}
一旦有了自定义的语言驱动,你就可以在 mybatis-config.xml 文件中将它设置为默认语言:
type = "org.sample.MyLanguageDriver" alias = "myLanguage" />
name = "defaultScriptingLanguage" value = "myLanguage" />
除了设置默认语言,你也可以针对特殊的语句指定特定语言,这可以通过如下的 lang 属性来完成:
id = "selectBlog" lang = "myLanguage" >
SELECT * FROM BLOG
或者在你正在使用的映射中加上注解 @Lang 来完成:
public interface Mapper {
@Lang ( MyLanguageDriver . class )
@Select ( "SELECT * FROM BLOG" )
List < Blog > selectBlog ();
}
注意 可以将 Apache Velocity 作为动态语言来使用,更多细节请参考 MyBatis-Velocity 项目。
你前面看到的所有 xml 标签都是默认 MyBatis 语言提供的,它是由别名为 xml 语言驱动器 org.apache.ibatis.scripting.xmltags.XmlLanguageDriver 驱动的。
映射器注解
因为最初设计时,MyBatis 是一个 XML 驱动的框架。配置信息是基于 XML 的,而且 映射语句也是定义在 XML 中的。而到了 MyBatis 3,有新的可用的选择了。MyBatis 3 构建 在基于全面而且强大的 Java 配置 API 之上。这个配置 API 是基于 XML 的 MyBatis 配置的 基础,也是新的基于注解配置的基础。注解提供了一种简单的方式来实现简单映射语句,而 不会引入大量的开销。
注意 不幸的是,Java 注解限制了它们的表现和灵活。尽管很多时间都花调查,设计和 实验上,最强大的 MyBatis 映射不能用注解来构建,那并不可笑。C#属性(做示例)就没 有这些限制,因此 MyBatis.NET 将会比 XML 有更丰富的选择。也就是说,基于 Java 注解 的配置离不开它的特性。
注解有下面这些:
注解
目标
相对应的 XML
描述
@CacheNamespace
类
为给定的命名空间 (比如类) 配置缓存。 属性:implemetation,eviction, flushInterval,size 和 readWrite。
@CacheNamespaceRef
类
参照另外一个命名空间的缓存来使用。 属性:value,应该是一个名空间的字 符串值(也就是类的完全限定名) 。
@ConstructorArgs
Method
收集一组结果传递给一个劫夺对象的 构造方法。属性:value,是形式参数 的数组。
@Arg
方法
单 独 的 构 造 方 法 参 数 , 是 ConstructorArgs 集合的一部分。属性: id,column,javaType,typeHandler。 id 属性是布尔值, 来标识用于比较的属 性,和XML 元素相似。
@TypeDiscriminator
方法
一组实例值被用来决定结果映射的表 现。 属性: column, javaType, jdbcType, typeHandler,cases。cases 属性就是实 例的数组。
@Case
方法
单独实例的值和它对应的映射。属性: value,type,results。Results 属性是结 果数组,因此这个注解和实际的 ResultMap 很相似,由下面的 Results 注解指定。
@Results
方法
结果映射的列表, 包含了一个特别结果 列如何被映射到属性或字段的详情。 属 性:value,是 Result 注解的数组。
@Result
方法
在列和属性或字段之间的单独结果映 射。属 性:id,column, property, javaType ,jdbcType ,type Handler, one,many。id 属性是一个布尔值,表 示了应该被用于比较(和在 XML 映射 中的相似)的属性。one 属性是单 独 的 联 系, 和 相 似 , 而 many 属 性 是 对 集 合 而 言 的 , 和 相似。 它们这样命名是为了 避免名称冲突。
@One
方法
复杂类型的单独属性值映射。属性: select,已映射语句(也就是映射器方 法)的完全限定名,它可以加载合适类 型的实例。注意:联合映射在注解 API 中是不支持的。这是因为 Java 注解的 限制,不允许循环引用。fetchType , which supersedes the global configuration parameter lazyLoadingEnabled for this mapping.
@Many
方法
A mapping to a collection property of a complex type. Attributes: select , which is the fully qualified name of a mapped statement (i.e. mapper method) that can load a collection of instances of the appropriate types, fetchType , which supersedes the global configuration parameterlazyLoadingEnabled for this mapping. NOTE You will notice that join mapping is not supported via the Annotations API. This is due to the limitation in Java Annotations that does not allow for circular references.
@MapKey
方法
复 杂 类 型 的 集合 属 性 映射 。 属 性 : select,是映射语句(也就是映射器方 法)的完全限定名,它可以加载合适类 型的一组实例。注意:联合映射在 Java 注解中是不支持的。这是因为 Java 注 解的限制,不允许循环引用。
@Options
方法
映射语句的属性
这个注解提供访问交换和配置选项的 宽广范围, 它们通常在映射语句上作为 属性出现。 而不是将每条语句注解变复 杂,Options 注解提供连贯清晰的方式 来访问它们。属性:useCache=true , flushCache=false , resultSetType=FORWARD_ONLY , statementType=PREPARED , fetchSize=-1 , , timeout=-1 useGeneratedKeys=false , keyProperty=”id”。 理解 Java 注解是很 重要的,因为没有办法来指定“null” 作为值。因此,一旦你使用了 Options 注解,语句就受所有默认值的支配。要 注意什么样的默认值来避免不期望的 行为。
@Insert @Update @Delete @Select
方法
这些注解中的每一个代表了执行的真 实 SQL。 它们每一个都使用字符串数组 (或单独的字符串)。如果传递的是字 符串数组, 它们由每个分隔它们的单独 空间串联起来。这就当用 Java 代码构 建 SQL 时避免了“丢失空间”的问题。 然而,如果你喜欢,也欢迎你串联单独 的字符串。属性:value,这是字符串 数组用来组成单独的 SQL 语句。
@InsertProvider @UpdateProvider @DeleteProvider @SelectProvider
方法
这些可选的 SQL 注解允许你指定一个 类名和一个方法在执行时来返回运行 允许创建动态 的 SQL。 基于执行的映射语句, MyBatis 会实例化这个类,然后执行由 provider 指定的方法. 这个方法可以选择性的接 受参数对象作为它的唯一参数, 但是必 须只指定该参数或者没有参数。属性: type,method。type 属性是类的完全限 定名。method 是该类中的那个方法名。 注意: 这节之后是对 SelectBuilder 类的 讨论,它可以帮助你以干净,容于阅读 的方式来构建动态 SQL。
@Param
Parameter
N/A
如果你的映射器的方法需要多个参数, 这个注解可以被应用于映射器的方法 参数来给每个参数一个名字。否则,多 参数将会以它们的顺序位置来被命名 (不包括任何 RowBounds 参数) 比如。 #{param1} , #{param2} 等 , 这 是 默 认 的 。 使 用 @Param(“person”),参数应该被命名为 #{person}。
@SelectKey
Method
This annotation duplicates the @Insert ,@InsertProvider , @Update or @UpdateProvider . It is ignored for other methods. If you specify a@SelectKey annotation, then MyBatis will ignore any generated key properties set via the @Options annotation, or configuration properties. Attributes: statement an array of strings which is the SQL statement to execute, keyProperty which is the property of the parameter object that will be updated with the new value, before which must be either true or false to denote if the SQL statement should be executed before or after the insert, resultType which is the Java type of the keyProperty , andstatementType=PREPARED .
@ResultMap
Method
N/A
This annotation is used to provide the id of a @Select or@SelectProvider annotation. This allows annotated selects to reuse resultmaps that are defined in XML. This annotation will override any @Results or @ConstructorArgs annotation if both are specified on an annotated select.
@ResultType
Method
N/A
This annotation is used when using a result handler. In that case, the return type is void so MyBatis must have a way to determine the type of object to construct for each row. If there is an XML result map, use the @ResultMap annotation. If the result type is specified in XML on the
映射申明样例
这个例子展示了如何使用 @SelectKey 注解来在插入前读取数据库序列的值:
@Insert ( "insert into table3 (id, name) values(#{nameId}, #{name})" )
@SelectKey ( statement = "call next value for TestSequence" , keyProperty = "nameId" , before = true , resultType = int . class )
int insertTable3 ( Name name );
这个例子展示了如何使用 @SelectKey 注解来在插入后读取数据库识别列的值:
@Insert ( "insert into table2 (name) values(#{name})" )
@SelectKey ( statement = "call identity()" , keyProperty = "nameId" , before = false , resultType = int . class )
int insertTable2 ( Name name );
只要在应用的classpath中创建一个名称为log4j.properties 的文件, 文件的具体内容如下:
# Global logging configuration
log4j . rootLogger = ERROR , stdout
# MyBatis logging configuration...
log4j . logger . org . mybatis . example . BlogMapper = TRACE
# Console output...
log4j . appender . stdout = org . apache . log4j . ConsoleAppender
log4j . appender . stdout . layout = org . apache . log4j . PatternLayout
log4j . appender . stdout . layout . ConversionPattern =% 5p [% t ] - % m % n
添加以上配置后,Log4J就会把 org.mybatis.example.BlogMapper 的详细执行日志记录下来,对于应用中的其它类则仅仅记录错误信息。
也可以将日志从整个mapper接口级别调整到到语句级别,从而实现更细粒度的控制。如下配置只记录 selectBlog 语句的日志:
log4j . logger . org . mybatis . example . BlogMapper . selectBlog = TRACE
与此相对,可以对一组mapper接口记录日志,只要对mapper接口所在的包开启日志功能即可:
log4j . logger . org . mybatis . example = TRACE
某些查询可能会返回大量的数据,只想记录其执行的SQL语句该怎么办?为此,Mybatis中SQL语 句的日志级别被设为DEBUG(JDK Logging中为FINE),结果日志的级别为TRACE(JDK Logging中为FINER)。所以,只要将日志级别调整为DEBUG即可达到目的:
log4j . logger . org . mybatis . example = DEBUG
要记录日志的是类似下面的mapper文件而不是mapper接口又该怎么呢?
xml version = "1.0" encoding = "UTF-8" ?>
namespace = "org.mybatis.example.BlogMapper" >
id = "selectBlog" resultType = "Blog" >
select * from Blog where id = #{id}
对这个文件记录日志,只要对命名空间增加日志记录功能即可:
log4j . logger . org . mybatis . example . BlogMapper = TRACE
进一步,要记录具体语句的日志可以这样做:
log4j . logger . org . mybatis . example . BlogMapper . selectBlog = TRACE
看到了吧,两种配置没差别!
配置文件log4j.properties 的余下内容是针对日志格式的,这一内容已经超出本 文档范围。关于Log4J的更多内容,可以参考Log4J的网站。不过,可以简单试一下看看,不同的配置 会产生什么不一样的效果。
http://mybatis.github.io/mybatis-3/zh/configuration.html
Quartz
http://yangpanwww.iteye.com/blog/797563
一个Quartz的CronTrigger表达式分为七项子表达式,其中每一项以空格隔开,从左到右分别是:秒,分,时,月的某天,月,星期的某天,年;其中年不是必须的,也就是说任何一个表达式最少需要六项。
先看示列:"0 0/30 8-10 5,20 * ?" 表示“每个月的5日和20日的8:00,8:30,9:00,9:30,10:00,10:30” 字符解释: , :与,表式","两边的值都是需要执行的时间,如上例"5,20",每个月的5日与20日。 - :表示值的范围,如上例"8-10",从8点开始到10结束,包括8点与10点。 * :表式任意可合法的值,如上例"*"是处于月份的字段,所以代表1-12中的任意值,所以上例是指“每个月”。 / :增量,如上例是指从0分开始,每过30分钟取一次值。如果换成"5/8"就是从第5钟开始每过8分钟取一次值:8:05,8:13,8:21,8:29等等 ? :不指定值,就是“我也不知道”的意思,只能出现在“月的某天,星期的某天”项中。在什么情况下用呢?如上例如果指定值为星期一,那么可能会出现如4月5日不是星期一,这里就是不对应,有冲突,所以指定为"?",也就是说我也不知道是星期几,只要是5日与20日就行了,至于是星期几我才不管呢! L :最后的,last的意思,只能出现在“月的某天,星期的某天”项中。表示当前月或当前星期的最后一天,注意的是星期的最后一天为星期六。 W :月中最接近指定日期的普通日(星期一到星期五),只能出现在“月的某天”,如"15W"就是说当前月最接近15日的普通日,如果当月的15是星期三就是星期三,如果当月的15是星期六那么就是昨天也就是星期五,如果当月的15是星期天则为第二天也就是星期一。 # :当前月的第N个星期X日,只能出现在“星期的某天”项中。如"6#3"就是说当前月的第三个星期五,注意"1-7",1=星期天,2=星期一 等等。
来自:http://blog.csdn.net/dengsilinming/article/details/8259752
http://www.cnblogs.com/obullxl/archive/2011/07/10/spring-quartz-cron-integration.html
execute
1. Class.getResourceAsStream(String path) : path 不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从
ClassPath根下获取。其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。
2. Class.getClassLoader.getResourceAsStream(String path) :默认则是从ClassPath根下获取,path不能以’/'开头,最终是由
ClassLoader获取资源。
3. ServletContext. getResourceAsStream(String path):默认从WebAPP根目录下取资源,Tomcat下path是否以’/'开头无所谓,
当然这和具体的容器实现有关。
ClassLoader
Bootstrap ClassLoader是启动类加载器,它是用 C++编写的,从 %jre%/lib目录中加载类,或者运行时用 -Xbootclasspath指定目录来加载。
Extension ClassLoader是扩展类加载器,从 %jre%/lib/ext目录加载类,或者运行时用 -Djava.ext.dirs制定目录来加载。
System ClassLoader,系统类加载器,它会从系统环境变量配置的 classpath来查找路径,环境变量里的 .表示当前目录,是通过运行时 -classpath或 -Djava.class.path指定的目录来加载类。
Properties
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
InputStream in = classLoader.getResourceAsStream("test.properties");
Properties prop = new Properties();
String testString = prop.getProperty("TEST_URL");message
classpath:conf/message/messages
public class MessageTest {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("messages.xml");
Object[] arg = new Object[] { "Erica", Calendar.getInstance().getTime() };
String msg = ctx.getMessage("userinfo", arg,Locale.CHINA);
System.out.println("Message is ===> " + msg);
}
} 或者注入
JAVA_OPTS -server -Xms1024m -Xmx2048m -XX:PermSize=256m -XX:MaxPermSize=512m
嵌套类和静态嵌套类区别。
嵌套类可以访问private、public、protect、package所有资源
静态嵌套类相当于另外一个类。受影响
ArrayList、LinkList、HashSet、HashMap(可以存放null)非同步
大数据:
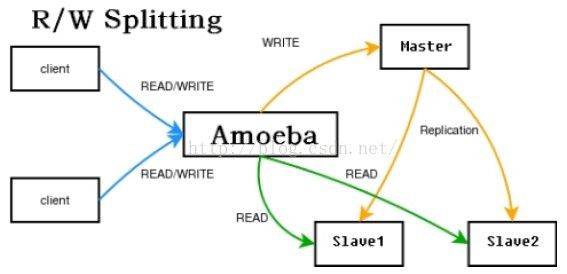
分库分表:Taobao(基于ibatis和Spring的的分布式数据访问层),Alibaba(变形虫”(Amoeba)),Tencent,它们大都实现了自己的分布式数据访问层(DDAL)
以实现方式和实现 的层次来划分,大概分为两个层次(Java应用为例):JDBC层的封装,ORM框架层的实现
Sharding-分片
比如日志文章(article)表:article_id,user_id,title,content
根据user_id 分表DBn
按号段分:
Master上的数据怎样和集群中其他的Slave 机器保持数据的同步和一致呢?MySql的Proxy机制可以帮助我们做到这点,
一个完整的mysql读写分离环境包括以下几个部分:
· 应用程序client
· databaseproxy
· database集群
一.搭建mysql的master-slave环境
1)分别在host1(xxxx)和host2(xxxxx)上安装mysql(5.0.45),具体安装方法可见官方文档
2)配置master
首先编辑/etc/my.cnf,添加以下配置:
log-bin=mysql-bin#slave会基于此log-bin来做replication
然后添加专门用于replication的用户:
mysql> GRANTREPLICATION SLAVE ON *.* TO xxx@xxxxxIDENTIFIED BY 'xxx';
重启mysql,使得配置生效:
/etc/init.d/mysqldrestart
最后查看master状态:
3)配置slave
首先编辑/etc/my.cnf,添加以下配置:
server-id=2 #slave的标示
配置生效后,配置与master的连接:
mysql> CHANGEMASTER TO
其中MASTER_HOST是master机的ip,MASTER_USER和MASTER_PASSWORD就是我们刚才在master上添加的用户,MASTER_LOG_FILE和MASTER_LOG_POS对应与master status里的信息
最后启动slave:
mysql> startslave;
4)验证master-slave搭建生效
通过查看slave机的log(/var/log/mysqld.log):
xxxx:xx[Note] Slave I/O thread: connected to master 'xxxx@xxxx:3306', replication started in log 'mysql-bin.000003' at position 161261
如看到以上信息则证明搭建成功,如果有问题也可通过此log找原因
二.搭建database proxy
此次实战中database proxy采用amoeba ,它的相关信息可以查阅官方文档,不在此详述
1)安装amoeba
下载amoeba(1.2.0-GA)后解压到本地(D:\openSource\amoeba-mysql-1.2.0-GA),即完成安装
2)配置amoeba
先配置proxy连接和与各后端mysql服务器连接信息(D:\openSource\amoeba-mysql-1.2.0-GA\conf\amoeba.xml):
1.
2.
3. name ="port" > 8066
4.
5.
6.
9.
10. name ="readThreadPoolSize" > 20
11.
12.
13. name ="clientSideThreadPoolSize" > 30
14.
15.
16. name ="serverSideThreadPoolSize" > 30
17.
18.
19. name ="netBufferSize" > 128
20.
21.
22. name ="tcpNoDelay" > true
23.
24.
25. name ="user" > root
26.
27.
28. name ="password" > root
29.
以上是proxy提供给client的连接配置
1.
2. name ="server1" >
3.
4. class ="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory" >
5. name ="manager" > defaultManager
6.
7.
8. name ="port" > 3306
9.
10.
11. name ="ipAddress" > xxxxx
12. name ="schema" > amoeba_study
13.
14.
15. name ="user" > root
16.
17.
18. name ="password" >
19.
20.
21.
22.
23. class ="com.meidusa.amoeba.net.poolable.PoolableObjectPool" >
24. name ="maxActive" > 200
25. name ="maxIdle" > 200
26. name ="minIdle" > 10
27. name ="minEvictableIdleTimeMillis" > 600000
28. name ="timeBetweenEvictionRunsMillis" > 600000
29. name ="testOnBorrow" > true
30. name ="testWhileIdle" > true
31.
32.
33. name ="server2" >
34.
35.
36. class ="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory" >
37. name ="manager" > defaultManager
38.
39.
40. name ="port" > 3306
41.
42.
43. name ="ipAddress" > xxxxx
44. name ="schema" > amoeba_study
45.
46.
47. name ="user" > root
48.
49.
50. name ="password" >
51.
52.
53.
54.
55. class ="com.meidusa.amoeba.net.poolable.PoolableObjectPool" >
56. name ="maxActive" > 200
57. name ="maxIdle" > 200
58. name ="minIdle" > 10
59. name ="minEvictableIdleTimeMillis" > 600000
60. name ="timeBetweenEvictionRunsMillis" > 600000
61. name ="testOnBorrow" > true
62. name ="testWhileIdle" > true
63.
64.
65.
以上是proxy与后端各mysql数据库服务器配置信息,具体配置见注释很明白了
最后配置读写分离策略:
1. class ="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter" >
2. name ="LRUMapSize" > 1500
3. name ="defaultPool" > server1
4. name ="writePool" > server1
5. name ="readPool" > server2
6. name ="needParse" > true
7.
从以上配置不然发现,写操作路由到server1(master),读操作路由到server2(slave)
3)启动amoeba
在命令行里运行D:\openSource\amoeba-mysql-1.2.0-GA\amoeba.bat即可:
log4j:WARN log4jconfig load completed from file:D:\openSource\amoeba-mysql-1.2.0-GA\conf\log4j.xml
1)编写client调用程序
具体程序细节就不详述了,只是一个最普通的基于mysql driver的jdbc的数据库操作程序
2)配置数据库连接
本client基于c3p0,具体数据源配置如下:
1. id ="dataSource" class ="com.mchange.v2.c3p0.ComboPooledDataSource"
2. destroy-method ="close" >
3. name ="driverClass" value ="com.mysql.jdbc.Driver" />
4. name ="jdbcUrl" value ="jdbc:mysql://localhost:8066/amoeba_study" />
5. name ="user" value ="root" />
6. name ="password" value ="root" />
7. name ="minPoolSize" value ="1" />
8. name ="maxPoolSize" value ="1" />
9. name ="maxIdleTime" value ="1800" />
10. name ="acquireIncrement" value ="1" />
11. name ="maxStatements" value ="0" />
12. name ="initialPoolSize" value ="1" />
13. name ="idleConnectionTestPeriod" value ="1800" />
14. name ="acquireRetryAttempts" value ="6" />
15. name ="acquireRetryDelay" value ="1000" />
16. name ="breakAfterAcquireFailure" value ="false" />
17. name ="testConnectionOnCheckout" value ="true" />
18. name ="testConnectionOnCheckin" value ="false" />
19.
值得注意是,client端只需连到proxy,与实际的数据库没有任何关系,因此jdbcUrl、user、password配置都对应于amoeba暴露出来的配置信息
3)调用与测试
首先插入一条数据:insert into zone_by_id(id,name) values(20003,'name_20003')
通过查看master机上的日志/var/lib/mysql/mysql_log.log:
10070311:58:42 1Query set names latin1
得知写操作发生在master机上
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
10070311:58:42 2Query insert into zone_by_id(id,name)values(20003,'name_20003')
得知slave同步执行了这条语句
然后查一条数据:select t.name from zone_by_id t where t.id = 20003
通过查看slave机上的日志/var/lib/mysql/mysql_log.log:
10070312:02:00 33Query set names latin1
得知读操作发生在slave机上
并且通过查看slave机上的日志/var/lib/mysql/mysql_log.log发现这条语句没在master上执行
通过以上验证得知简单的master-slave搭建和实战得以生效
amoeba缺点:不支持事务、存储过程
oracle(负载高点可能考虑使用相关的Replication机制来提高读写的吞吐和性能, 这可能已经可以满足很多需求,但这套机制自身的缺陷还是比较显而易见的。首先它的有效很依赖于读操作的比例,Master往往会成为瓶颈所在,写操作需要 顺序排队来执行,过载的话Master首先扛不住,Slaves的数据同步的延迟也可能比较大,而且会大大耗费CPU的计算能力,因为write操作在 Master上执行以后还是需要在每台slave机器上都跑一次。这时候 Sharding可能会成为鸡肋了。)
一.为什么要POI
众所周知,java在处理数据量比较大的时候,加载到内存必然会导致内存溢出,而在一些数据处理中我们不得不去处理海量数据,在做数据处理中,我们常见的手段是分解,压缩,并行,临时文件等方法;
例如,我们要将数据库(不论是什么数据库)的数据导出到一个文件,一般是Excel 或文本格式的CSV;对于Excel来讲,对于POI和JXL的接口,你很多时候没有办法去控制内存什么时候向磁盘写入,很恶心,而且这些API在内存构 造的对象大小将比数据原有的大小要大很多倍数,所以你不得不去拆分Excel,还好,POI开始意识到这个问题,在3.8.4的版本后,开始提供 cache的行数,提供了SXSSFWorkbook的接口,可以设置在内存中的行数,不过可惜的是,他当你超过这个行数,每添加一行,它就将相对行数前面的一行写入磁盘(如你设置2000行的话,当你写第20001行的时候,他会将第一行写入磁盘),其实这个时候他些的临时文件,以至于不消耗内存,不过这样你会发现,刷磁盘的频率会非常高,我们的确不想这样,因为我们想让他达到一个范围一次性将数据刷如磁盘,比如一次刷1M之类的做法,可惜现在还没有这种API,很痛苦,我自己做过测试,通过写小的Excel比使用目前提供刷磁盘的API来写大文件,效率要高一些,而且这样如果访问的人稍微多一些磁盘 IO可能会扛不住,因为IO资源是非常有限的,所以还是拆文件才是上策;而当我们写CSV,也就是文本类型的文件,我们很多时候是可以自己控制的,不过你不要用CSV自己提供的API,也是不太可控的,CSV本身就是文本文件,你按照文本格式写入即可被CSV识别出来;如何写入呢?下面来说说。。。
在处理数据层面,如从数据库中读取数据,生成本地文件,写代码为了方便,我们未必要 1M怎么来处理,这个交给底层的驱动程序去拆分,对于我们的程序来讲我们认为它是连续写即可;我们比如想将一个1000W数据的数据库表,导出到文件;此 时,你要么进行分页,oracle当然用三层包装即可,mysql用limit,不过分页每次都会新的查询,而且随着翻页,会越来越慢,其实我们想拿到一个句柄,然后向下游动,编译一部分数据(如10000行)将写文件一次(写文件细节不多说了,这个是最基本的),需要注意的时候每次buffer的数据, 在用outputstream写入的时候,最好flush一下,将缓冲区清空下;接下来,执行一个没有where条件的SQL,会不会将内存撑爆?是的,这个问题我们值得去思考下,通过API发现可以对SQL进行一些操作,例如,通过:PreparedStatement statement= connection.prepareStatement(sql),这是默认得到的预编译,还可以通过设置:PreparedStatementstatement = connection.prepareStatement(sql , ResultSet.TYPE_FORWARD_ONLY ,ResultSet.CONCUR_READ_ONLY);
来设置游标的方式,以至于游标不是将数据直接cache到本地内存,然后通过设置statement.setFetchSize(200);设置游标每次遍历的大小;OK,这个其实我用过,oracle用了和没用没区别,因为oracle的jdbc API默认就是不会将数据cache到java的内存中的,而mysql里头设置根本无效,我上面说了一堆废话,呵呵,我只是想说,java提供的标准API也未必有效,很多时候要看厂商的实现机制,还有这个设置是很多网上说有效的,但是这纯属抄袭;对于oracle上面 说了不用关心,他本身就不是cache到内存,所以java内存不会导致什么问题,如果是mysql,首先必须使用5以上的版本,然后在连接参数上加上 useCursorFetch=true这个参数,至于游标大小可以通过连接参数上加上:defaultFetchSize=1000来设置,例如:
jdbc:mysql://xxx.xxx.xxx.xxx:3306/abc?zeroDateTimeBehavior=convertToNull&useCursorFetch=true&defaultFetchSize=1000
上次被这个问题纠结了很久(mysql的数据老导致程序内存膨胀,并行2个直接系统 就宕了),还去看了很多源码才发现奇迹竟然在这里,最后经过mysql文档的确认,然后进行测试,并行多个,而且数据量都是500W以上的,都不会导致内存膨胀,GC一切正常,这个问题终于完结了。
我们再聊聊其他的,数据拆分和合并,当数据文件多的时候我们想合并,当文件太大想要拆分,合并和拆分的过程也会遇到类似的问题,还好,这个在我们可控制的范围内,如果文件中的数据最终是可以组织的,那么在拆分和合并的时候,此时就不要按 照数据逻辑行数来做了,因为行数最终你需要解释数据本身来判定,但是只是做拆分是没有必要的,你需要的是做二进制处理,在这个二进制处理过程,你要注意了,和平时read文件不要使用一样的方式,平时大多对一个文件读取只是用一次read操作,如果对于大文件内存肯定直接挂掉了,不用多说,你此时因该每次读取一个可控范围的数据,read方法提供了重载的offset和length的范围,这个在循环过程中自己可以计算出来,写入大文件和上面一样,不要 读取到一定程序就要通过写入流flush到磁盘;其实对于小数据量的处理在现代的NIO技术的中也有用到,例如多个终端同时请求一个大文件下载,例如视频下载吧,在常规的情况下,如果用java的容器来处理,一般会发生两种情况:
其一为内存溢出,因为每个请求都要加载一个文件大小的内存甚至于更多,因为java 包装的时候会产生很多其他的内存开销,如果使用二进制会产生得少一些,而且在经过输入输出流的过程中还会经历几次内存拷贝,当然如果有你类似nginx之 类的中间件,那么你可以通过send_file模式发送出去,但是如果你要用程序来处理的时候,内存除非你足够大,但是java内存再大也会有GC的时 候,如果你内存真的很大,GC的时候死定了,当然这个地方也可以考虑自己通过直接内存的调用和释放来实现,不过要求剩余的物理内存也足够大才行,那么足够 大是多大呢?这个不好说,要看文件本身的大小和访问的频率;
其二为假如内存足够大,无限制大,那么此时的限制就是线程,传统的IO模型是线程是 一个请求一个线程,这个线程从主线程从线程池中分配后,就开始工作,经过你的Context包装、Filter、拦截器、业务代码各个层次和业务逻辑、访 问数据库、访问文件、渲染结果等等,其实整个过程线程都是被挂住的,所以这部分资源非常有限,而且如果是大文件操作是属于IO密集型的操作,大量的CPU 时间是空余的,方法最直接当然是增加线程数来控制,当然内存足够大也有足够的空间来申请线程池,不过一般来讲一个进程的线程池一般会受到限制也不建议太多的,而在有限的系统资源下,要提高性能,我们开始有了new IO技术,也就是NIO技术,新版的里面又有了AIO技术,NIO只能算是异步IO,但是在中间读写过程仍然是阻塞的(也就是在真正的读写过程,但是不会去关心中途的响应),还未做到真正的异步IO,在监听connect的时候他是不需要很多线程参与的,有单独的线程去处理,连接也又传统的socket变 成了selector,对于不需要进行数据处理的是无需分配线程处理的;而AIO通过了一种所谓的回调注册来完成,当然还需要OS的支持,当会掉的时候会去分配线程,目前还不是很成熟,性能最多和NIO吃平,不过随着技术发展,AIO必然会超越NIO,目前谷歌V8虚拟机引擎所驱动的node.js就是类似的模式,有关这种技术不是本文的说明重点;
将上面两者结合起来就是要解决大文件,还要并行度,最土的方法是将文件每次请求的大小降低到一定程度,如8K(这个大小是经过测试后网络传输较为适宜的大小,本地读取文件并不需要这么小),如果再做深入一些,可以做一定程度的 cache,将多个请求的一样的文件,cache在内存或分布式缓存中,你不用将整个文件cache在内存中,将近期使用的cache几秒左右即可,或你 可以采用一些热点的算法来配合;类似迅雷下载的断点传送中(不过迅雷的网络协议不太一样),它在处理下载数据的时候未必是连续的,只要最终能合并即可,在服务器端可以反过来,谁正好需要这块的数据,就给它就可以;才用NIO后,可以支持很大的连接和并发,本地通过NIO做socket连接测试,100个终端同时请求一个线程的服务器,正常的WEB应用是第一个文件没有发送完成,第二个请求要么等待,要么超时,要么直接拒绝得不到连接,改成NIO后此时 100个请求都能连接上服务器端,服务端只需要1个线程来处理数据就可以,将很多数据传递给这些连接请求资源,每次读取一部分数据传递出去,不过可以计算 的是,在总体长连接传输过程中总体效率并不会提升,只是相对相应和所开销的内存得到量化控制,这就是技术的魅力,也许不要太多的算法,不过你得懂他。
类似的数据处理还有很多,有些时候还会将就效率问题,比如在HBase的文件拆分和 合并过程中,要不影响线上业务是比较难的事情,很多问题值得我们去研究场景,因为不同的场景有不同的方法去解决,但是大同小异,明白思想和方法,明白内存和体系架构,明白你所面临的是什么的场景,只是细节上改变可以带来惊人的效果。
二.POI计算
1.设置对应的EXCEL路径。
//获取规则记录的计算文件名
String excelPath =XXXHelper.getRuleExcelPath(rule.getXXX(), rule.getXXX(), rule.getXXX(),rule.getXXX());
2.设置对应的传入参数区域
//Excel传入参数区域
List inCellNames = newArrayList();
setCell(rule.getXXXCell(),inCellNames);
setCell(rule.getXXXCell(),inCellNames);
...
setCell(rule.getXXXCell(), inCellNames);
//Excel传入值区域
Map practiceMap = newHashMap();
setCellValue(practiceMap, rule.getXXXCell(),req.getXXX());
setCellValue(practiceMap, rule.getXXXCell(),req.getXXX());
setCellValue(practiceMap, rule.getXXCell(),req.getXXX());
3.分批计算
//分批计算
if(count % fbCount== 0) {
batchCalc();
}
4.复制对应EXCEL源
this.excelVer =ExcelVersion.get(suffix);//获取当前EXCEL版本
operationPath =excelName + "_temp_" + (count++) + suffix;
inputStream = newFileInputStream(excelPath);
outputStream = newFileOutputStream(operationPath);
Workbook wb =WorkbookFactory.create(inputStream);
wb.write(outputStream);
5.读取当前操作的EXCEL页
inputStream = newFileInputStream(operationPath);
workbook =WorkbookFactory.create(inputStream);
6.操作目标的EXCEL页,读取结果
FormulaEvaluatorevaluator = workbook.getCreationHelper().createFormulaEvaluator();
Object resultVal =getCellValue(evaluator, cell);
7.删除临时的EXCEL
file.delete();
ByteBuffer
http://blog.csdn.net/maosijunzi/article/details/14127481
http://my.oschina.net/flashsword/blog/159613
NIO
http://www.blogjava.net/19851985lili/articles/93524.html
http://weixiaolu.iteye.com/blog/1479656
tomcat 热部署
http://blog.csdn.net/mhmyqn/article/details/24742195
一、 什么是HTTPS
在说HTTPS之前先说说什么是HTTP,HTTP就是我们平时浏览网页时候使用的一种协议。HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全。为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。SSL目前的版本是3.0,被IETF(Internet Engineering Task Force)定义在RFC 6101中,之后IETF对SSL 3.0进行了升级,于是出现了TLS(Transport Layer Security) 1.0,定义在RFC 2246。实际上我们现在的HTTPS都是用的TLS协议,但是由于SSL出现的时间比较早,并且依旧被现在浏览器所支持,因此SSL依然是HTTPS的代名词,但无论是TLS还是SSL都是上个世纪的事情,SSL最后一个版本是3.0,今后TLS将会继承SSL优良血统继续为我们进行加密服务。目前TLS的版本是1.2,定义在RFC 5246中,暂时还没有被广泛的使用。
二、 Https的工作原理
HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的简单描述如下:
1.浏览器将自己支持的一套加密规则发送给网站。
2.网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
3.获得网站证书之后浏览器要做以下工作:
a) 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。
b) 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。
c) 使用约定好的HASH计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。
4.网站接收浏览器发来的数据之后要做以下的操作:
a) 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。
b) 使用密码加密一段握手消息,发送给浏览器。
5.浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
这里浏览器与网站互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。另外,HTTPS一般使用的加密与HASH算法如下:
非对称加密算法:RSA,DSA/DSS
对称加密算法:AES,RC4,3DES
HASH算法:MD5,SHA1,SHA256
其中非对称加密算法用于在握手过程中加密生成的密码,对称加密算法用于对真正传输的数据进行加密,而HASH算法用于验证数据的完整性。由于浏览器生成的密码是整个数据加密的关键,因此在传输的时候使用了非对称加密算法对其加密。非对称加密算法会生成公钥和私钥,公钥只能用于加密数据,因此可以随意传输,而网站的私钥用于对数据进行解密,所以网站都会非常小心的保管自己的私钥,防止泄漏。
TLS握手过程中如果有任何错误,都会使加密连接断开,从而阻止了隐私信息的传输。
方法/步骤
1
为服务器生成证书
“运行”控制台,进入%JAVA_HOME%/bin目录,使用如下命令进入目录:
cd “c:\Program Files\Java\jdk1.6.0_11\bin”
使用keytool为Tomcat生成证书,假定目标机器的域名是“localhost”,keystore文件存放在“D:\home\tomcat.keystore”,口令为“password”,使用如下命令生成:
keytool -genkey -v -alias tomcat -keyalg RSA -keystore D:\home\tomcat.keystore -validity 36500 (参数简要说明:“D:\home\tomcat.keystore”含义是将证书文件的保存路径,证书文件名称是tomcat.keystore ;“-validity 36500”含义是证书有效期,36500表示100年,默认值是90天 “tomcat”为自定义证书名称)。
在命令行填写必要参数:
A、 输入keystore密码:此处需要输入大于6个字符的字符串。
B、 “您的名字与姓氏是什么?”这是必填项,并且必须是TOMCAT部署主机的域名或者IP[如:gbcom.com 或者 10.1.25.251](就是你将来要在浏览器中输入的访问地址),否则浏览器会弹出警告窗口,提示用户证书与所在域不匹配。在本地做开发测试时,应填入“localhost”。
C、 你的组织单位名称是什么?”、“您的组织名称是什么?”、“您所在城市或区域名称是什么?”、“您所在的州或者省份名称是什么?”、“该单位的两字母国家代码是什么?”可以按照需要填写也可以不填写直接回车,在系统询问“正确吗?”时,对照输入信息,如果符合要求则使用键盘输入字母“y”,否则输入“n”重新填写上面的信息。
D、 输入的主密码,这项较为重要,会在tomcat配置文件中使用,建议输入与keystore的密码一致,设置其它密码也可以,完成上述输入后,直接回车则在你在第二步中定义的位置找到生成的文件。
2
为客户端生成证书
为浏览器生成证书,以便让服务器来验证它。为了能将证书顺利导入至IE和Firefox,证书格式应该是PKCS12,因此,使用如下命令生成:
keytool -genkey -v -alias mykey -keyalg RSA -storetype PKCS12 -keystore D:\home\mykey.p12 (mykey为自定义)。
对应的证书库存放在“D:\home\mykey.p12”,客户端的CN可以是任意值。双击mykey.p12文件,即可将证书导入至浏览器(客户端)。
3
让服务器信任客户端证书
由于是双向SSL认证,服务器必须要信任客户端证书,因此,必须把客户端证书添加为服务器的信任认证。由于不能直接将PKCS12格式的证书库导入,必须先把客户端证书导出为一个单独的CER文件,使用如下命令:
keytool -export -alias mykey -keystore D:\home\mykey.p12 -storetype PKCS12 -storepass password -rfc -file D:\home\mykey.cer
(mykey为自定义与客户端定义的mykey要一致,password是你设置的密码)。通过以上命令,客户端证书就被我们导出到“D:\home\mykey.cer”文件了。
下一步,是将该文件导入到服务器的证书库,添加为一个信任证书使用命令如下:
keytool -import -v -file D:\home\mykey.cer -keystore D:\home\tomcat.keystore
通过list命令查看服务器的证书库,可以看到两个证书,一个是服务器证书,一个是受信任的客户端证书:
keytool -list -keystore D:\home\tomcat.keystore (tomcat为你设置服务器端的证书名)。
4
让客户端信任服务器证书
由于是双向SSL认证,客户端也要验证服务器证书,因此,必须把服务器证书添加到浏览的“受信任的根证书颁发机构”。由于不能直接将keystore格式的证书库导入,必须先把服务器证书导出为一个单独的CER文件,使用如下命令:
keytool -keystore D:\home\tomcat.keystore -export -alias tomcat -file D:\home\tomcat.cer (tomcat为你设置服务器端的证书名)。
通过以上命令,服务器证书就被我们导出到“D:\home\tomcat.cer”文件了。双击tomcat.cer文件,按照提示安装证书,将证书填入到“受信任的根证书颁发机构”。
5
配置Tomcat服务器
打开Tomcat根目录下的/conf/server.xml,找到Connector port="8443"配置段,修改为如下:
SSLEnabled="true" maxThreads="150" scheme="https"
secure="true" clientAuth="true" sslProtocol="TLS"
keystoreFile="D:\\home\\tomcat.keystore" keystorePass="123456"
truststoreFile="D:\\home\\tomcat.keystore" truststorePass="123456" />
(tomcat要与生成的服务端证书名一致)
属性说明:
clientAuth:设置是否双向验证,默认为false,设置为true代表双向验证
keystoreFile:服务器证书文件路径
keystorePass:服务器证书密码
truststoreFile:用来验证客户端证书的根证书,此例中就是服务器证书
truststorePass:根证书密码
6
测试
在浏览器中输入:https://localhost:8443/,会弹出选择客户端证书界面,点击“确定”,会进入tomcat主页,地址栏后会有“锁”图标,表示本次会话已经通过HTTPS双向验证,接下来的会话过程中所传输的信息都已经过SSL信息加密。
另外:http://lixor.iteye.com/blog/1532655
23种设计模式:
1.策略模式
1,什么是策略模式?
策略模式,又叫算法簇模式,就是定义了不同的算法族,并且之间可以互相替换,此模式让算法的变化独立于使用算法的客户。
2,策略模式有什么好处?
策略模式的好处在于你可以动态的改变对象的行为。
3,设计原则
4 ,策略模式中有三个对象:
5,应用场景举例:
刘备要到江东娶老婆了,走之前诸葛亮给赵云(伴郎)三个锦囊妙计,说是按天机拆开能解决棘手问题,嘿,还别说,真解决了大问题,搞到最后是周瑜陪了夫人又折兵,那咱们先看看这个场景是什么样子的。
先说说这个场景中的要素:三个妙计,一个锦囊,一个赵云,妙计是亮哥给的,妙计放在锦囊里,俗称就是锦囊妙计嘛,那赵云就是一个干活的人,从锦囊取出妙计,执行,然后获胜。用java程序怎么表现这些呢?
那我们先来看看图?
三个妙计是同一类型的东西,那咱就写个接口:
package com.yangguangfu.strategy;
public interface IStrategy {
public void operate();
}
然后再写三个实现类,有三个妙计嘛:
妙计一:初到吴国:
package com.yangguangfu.strategy;
public class BackDoor implements IStrategy {
@Override
public void operate() {
System.out.println("找乔国老帮忙,让吴国太给孙权施加压力,使孙权不能杀刘备..." );
}
}
妙计二:求吴国太开个绿灯,放行:
package com.yangguangfu.strategy;
public class GivenGreenLight implements IStrategy {
@Override
public void operate() {
System.out.println("求吴国太开个绿灯,放行!" );
}
}
妙计三:孙夫人断后,挡住追兵:
package com.yangguangfu.strategy;
public class BlackEnemy implements IStrategy {
@Override
public void operate() {
System.out.println("孙夫人断后,挡住追兵..." );
}
}
好了,大家看看,三个妙计是有了,那需要有个地方放妙计啊,放锦囊里:
package com.yangguangfu.strategy;
public class Context {
private IStrategy strategy;
public Context(IStrategy strategy){
this .strategy = strategy;
}
public void operate(){
this .strategy.operate();
}
}
然后就是赵云雄赳赳的揣着三个锦囊,拉着已步入老年行列,还想着娶纯情少女的,色咪咪的刘备老爷子去入赘了,嗨,还别说,亮哥的三个妙计还真不错,瞧瞧:
package com.yangguangfu.strategy;
public class ZhaoYun {
public static void main(String[] args) {
Context context;
System.out.println("----------刚刚到吴国的时候拆开第一个---------------" );
context = new Context(new BackDoor());
context.operate();
System.out.println("\n\n\n\n\n\n\n\n\n\n\n\n\n" );
System.out.println("----------刘备乐不思蜀,拆第二个了---------------" );
context = new Context(new GivenGreenLight());
context.operate();
System.out.println("\n\n\n\n\n\n\n\n\n\n\n\n\n" );
System.out.println("----------孙权的小追兵了,咋办?拆开第三个锦囊---------------" );
context = new Context(new BlackEnemy());
context.operate();
System.out.println("\n\n\n\n\n\n\n\n\n\n\n\n\n" );
}
}
来自:http://yangguangfu.iteye.com/blog/815107
SOA(面向服务的体系结构)
面向服务架构,它可以根据需求通过网络对松散耦合的粗粒度应用组件进行分布式部署、组合和使用。服务层是SOA的基础,可以直接被应用调用,从而有效控制系统中与软件代理交互的人为依赖性。
SOA是一种粗粒度、松耦合服务架构,服务之间通过简单、精确定义接口进行通讯,不涉及底层编程接口和通讯模型。SOA可以看作是B/S模型、 XML( 标准通用标记语言的子集)/Web Service技术之后的自然延伸。
SOA将能够帮助软件工程师们站在一个新的高度理解企业级架构中的各种组件的开发、部署形式,它将帮助企业系统架构者以更迅速、更可靠、更具重用性架构整个业务系统。较之以往,以SOA架构的系统能够更加从容地面对业务的急剧变化。
SOA
凭借其松耦合的特性,使得企业可以按照模块化的方式来添加新服务或更新现有服务,以解决新的业务需要,而其对外提供服务的主要方式之一就是我们今天所要介绍的
webservice
。
目前来讲比较有名的
webservice
框架大致有四种
JWS
,
Axis,XFire
以及
CXF
。
1. JWS-WebService.JWS 是 java 语言实现的一种 webservice ,用来开发和发布服务,它是一个轻量级的 WS 框架,实现起来也非常的简单,下面通过一个小 demo 来看一下 JWS 是如何实现的:
(1) 定义接口,并将接口发布成webservice:
package org.zttc.service;
import javax.jws.WebParam;
import javax.jws.WebResult;
import javax.jws.WebService;
import javax.jws.soap.SOAPBinding;
@WebService
@SOAPBinding (style = SOAPBinding.Style.RPC)
public interface IMyService {
@WebResult (name= "addResult" )
public int add( @WebParam (name= "a" ) int a, @WebParam (name= "b" ) int b);
@WebResult (name= "loginUser" )
public User login( @WebParam (name= "username" )String username, @WebParam (name= "password" )String password);
}
(2).定义接口实现:
package org.zttc.service;
import javax.jws.WebParam;
import javax.jws.WebResult;
import javax.jws.WebService;
@WebService (endpointInterface= "org.zttc.service.IMyService" )
public class MyServiceImpl implements IMyService {
@Override
public int add( int a, int b) {
System.out.println(a + "+" + b + "=" + (a + b));
return a+b;
}
@Override
public User login( @WebParam (name = "username" ) String username,
@WebParam (name = "password" ) String password) {
System.out.println(username + " is logging" );
User user = new User();
user.setId("1" );
user.setUsername(username);
user.setPassword(password);
return user;
}
}
(3).发布服务:
package org.zttc.service;
import javax.xml.ws.Endpoint;
public class MyServer {
public static void main(String[] args){
String address = "http://localhost:8888/ns" ;
Endpoint.publish(address, new MyServiceImpl());
}
}
(4).编写测试类代码:
package org.zttc.service;
import java.net.MalformedURLException;
import java.net.URL;
import javax.xml.namespace.QName;
import javax.xml.ws.Service;
public class TestClient {
public static void main(String[] args){
try {
URL url = new URL( "http://localhost:8888/ns?wsdl" );
QName sname= new QName( "http://service.zttc.org/" , "MyServiceImplService" );
Service service = Service.create(url,sname);
IMyService ms =service.getPort(IMyService.class );
System.out.println(ms.add(12 , 33 ));
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
}
通过上面的代码我们可以看出在调用webservice的同时我们仍然需要知道对应的java类(接口),但调用webservice的情况往往两发生在个不同系统之间的,事先无法获取对应的接口,这时我们因该怎样解决这个问题呢?很简单,我们可以通过jdk,使用导出命令,将wsdl中的接口描述来生成这个接口以及实现类,然后将生成的接口和实现类应用在我们自己的java程序中就可以了,具体的生成命令是: Wsimport -d E:/我的酷盘/我的工程/java项目/webservice/01/ -keep -verbose http://localhost:6666/ns?wsdl .
来自:http://blog.csdn.net/a1314517love/article/details/24849759
spring+jws :
1、编写需要发布的JavaBean
package com.*.wtms.business.service.ws;
import java.util.Date;
import java.util.List;
import javax.annotation.Resource;
import javax.jws.WebMethod;
import javax.jws.WebService;
import javax.jws.soap.SOAPBinding;
import javax.jws.soap.SOAPBinding.ParameterStyle;
import org.springframework.stereotype.Service;
import com.*.wtms.business.dao.DeepLigthologyDao;
import com.*.wtms.business.dao.DrillingCollectionDao;
import com.*.wtms.business.dao.DrillingTaskDao;
import com.*.wtms.business.dao.QualityCollectionDao;
import com.*.wtms.business.dao.QualityTaskDao;
import com.*.wtms.business.entity.DeepLigthology;
import com.*.wtms.business.entity.DrillingCollection;
import com.*.wtms.business.entity.DrillingTask;
import com.*.wtms.business.entity.QualityCollection;
import com.*.wtms.business.entity.QualityTask;
import com.*.wtms.utils.Log;
@Service
@WebService (serviceName = "mobilewebservice" )
@SOAPBinding (parameterStyle=ParameterStyle.WRAPPED)
public class Mobilews
{
@Resource
private DrillingCollectionDao drillingCollectionDao;
@Resource
private DeepLigthologyDao deepLigthologyDao;
@Resource
private QualityCollectionDao qualityCollectionDao;
@Resource
private DrillingTaskDao drillingTaskDao;
@Resource
private QualityTaskDao qualityTaskDao;
@WebMethod
public boolean addDrillCollection( long projectId, long taskId, String measureNo, String wellsNo, String deviceCode, String wellsName, String wellsLocation, double RagEndDeep, int lithology, int deviceType, Date selfCheckDate, double selfCheckDeep, String operator, int note)
{
DrillingCollection drillingCollection = new DrillingCollection(projectId, taskId, measureNo, wellsNo, deviceCode, wellsName, wellsLocation, RagEndDeep, lithology, selfCheckDeep, selfCheckDate, operator, note);
try
{
drillingCollectionDao.save(drillingCollection);
return true ;
} catch (Exception e)
{
Log.getLogger(getClass()).error("call webservice to save DrillingCollection error:" + e.getMessage());
}
return false ;
}
@WebMethod
public boolean addDeepLithologyItem( long taskId, double deepFrom, double deepTo, int ligthologyType)
{
DeepLigthology deepLigthology = new DeepLigthology(taskId, deepFrom, deepTo, ligthologyType);
try
{
deepLigthologyDao.save(deepLigthology);
return true ;
} catch (Exception e)
{
Log.getLogger(getClass()).error("call webservice to save DeepLigthology error:" + e.getMessage());
}
return false ;
}
@WebMethod
public boolean addQualityCollection( long projectId, long taskId, String measureNo, String wellsNo, String deviceCode, int mechineType, int hasmark, double wellsLocation, double wellsDeep, double waterDeep, int lithology, int measureHandle, int saftyEnviroment, int isOk, String checker, String note)
{
QualityCollection qualityCollection = new QualityCollection(projectId, taskId, measureNo, wellsNo, deviceCode, mechineType, hasmark, wellsLocation, wellsDeep, waterDeep, lithology, checker, measureHandle, saftyEnviroment, isOk, 0 , note);
try
{
qualityCollectionDao.save(qualityCollection);
return true ;
} catch (Exception e)
{
Log.getLogger(getClass()).error("call webservice to save QualityCollection error:" + e.getMessage());
}
return false ;
}
@WebMethod
public List getDrillingTasks(String measureNo, String wellsNo, int processStatus)
{
return drillingTaskDao.getDrillingTasks(measureNo, wellsNo, processStatus);
}
@WebMethod
public List getQualityTasks(String measureNo, String wellsNo, int processStatus)
{
return qualityTaskDao.getQualityTasks(measureNo, wellsNo, processStatus);
}
@WebMethod
public List getDrillingTasksByLocal(String deviceCode)
{
return drillingTaskDao.getDrillingTasksByLocal(deviceCode);
}
@WebMethod
public List getQualityTasksByLocal(String deviceCode)
{
return qualityTaskDao.getQualityTasksByLocal(deviceCode);
}
}
2、配置Spring applicationContext.xml
< bean class = "org.springframework.remoting.jaxws.SimpleJaxWsServiceExporter" >
< property name = "baseAddress" value = "http://localhost:8088/" />
bean >
< bean id = "mobilewebservice" class = "com.scengine.wtms.business.service.ws.Mobilews" />
3、说明及注意
(1)、通过http://localhost:8080/mobilewebservice?wsdl访问webservice部署描述符, 还有自动生成的xsd:http://localhost:8080/mobilewebservice ?xsd=1 。 (2)、@SOAPBinding(parameterStyle=ParameterStyle.WRAPPED)必须添加,否则会报错;另外,如果发布的方法只有一个参数可以使用@SOAPBinding(parameterStyle=ParameterStyle. BARE )。
(3)、@WebService(serviceName = "mobilewebservice") 服务名称与Spring配置的bean一致。
参考地址:http://wodar.iteye.com/blog/230162,http://m.blog.csdn.net/blog/jadyer/9002553
(4)、webservice的端口设置不要与服务器一样,这一点非常重要否则服务器应用与webservice服务冲突会产生HTTP404错误。
4、结果截图
服务地址:
wsdl地址:
来自:http://blog.csdn.net/boonya/article/details/17577521
要了解WebService,光能写代码不行啊,这说说WebService最基本的概念。
首先 WebService 要知道几个最基本的概念:
1、XML以及XML Schema
XML 是Web Service表示数据的基本格式。XML是一套通用的数据表示格式,与平台无关,这就使不同语言构建的系统之间相互传递数据成为可能。
XML Schema-XSD 拥有一套标准的、可扩展的数据类型系统,Web Service即是用XSD来作为数据类型系统的。由于不同语言之间数据类型也不尽相同,因此,数据传输过程中,必须将其转化为一种通用的数据类型,即XSD的数据类型。
2、SOAP
SOAP(Simple Object Access Protocol),简单对象访问协议,它是基于XML格式的消息交换协议。SOAP定义了一个envelope对象,使用envelope来包装要传递的消息,而消息本身可以采用自身特定的词汇,使用namespace来区分彼此。简单的说,在WebService中传递的东西是一封信,SOAP就是信的通用格式,他定义了一封信应该有信封,信封里装着信的内容,信封(envlope)的格式是固定的,而信的内容(要传递的数据)你可以自己定义。
3、WSDL
WSDL(Web Service Description Language),Web Service描述语言,使用XML语言对Web Service及其函数、参数、返回值、数据类型等信息进行描述。因为是基于XML的,所以WSDL既是机器可阅读的,又是人可阅读的。
4、UDDI
UDDI(Universal Description Discovery and Integration),统一描述、发现和集成协议。UDDI 是一种目录服务,企业可以使用它对 Web services 进行注册和搜索。UDDI是一个分布式的互联网服务注册机制,他实现了一组可公开访问的接 口,通过这些接口,网络服务可以向服务信息库注册其服务信息、服务需求者可以找到分散在世界各地的网络服务。UDDI 并不像 WSDL 和 SOAP 一样深入人心,因为很多时候,使用者知道 Web 服务的位置(通常位于公司的企业内部网中)。
5、远程过程调用(RPC)与消息传递
Web service本身实际是在实现应用程序间的通信,实现通信的方式有两种:远程过程调用(RPC)和消息传递(DOCUMENT)。使用RPC的时候,客户端的概念是调用服务器上的远程过程,通常方式为实例化一个远程对象并调用其方法和属性。消息传递的概念是,客户端向服务器发送消息,然后等待服务器的回应。消息传递系统强调的是消息的发送和回应,而不是远程对象的界面。他们最大不同就是RPC不能通过Schema 来校验,而Document 类型是可以的。因此document 类型webservice成为主流 ,Document也是JAX-WS默认的实现方式。
有一种说法是,Web Service = SOAP + WSDL + HTTP。其中,SOAP协议是web service的主体,它通过HTTP或者SMTP等应用层协议进行通讯,自身使用XML文件来描述程序的函数方法和参数信息,从而完成不同主机的异构系统间的服务处理。这里的WSDL(Web Services Description Language)web 服务描述语言也是一个XML文档,它通过HTTP向公众发布,公告客户端程序关于某个具体的 Web service服务的URL信息、方法的命名,参数,返回值等。
SOAP协议简介
上面说了,SOAP是一种基于XML的消息通讯格式,用于网络上,不同平台,不同语言的应用程序间的通讯。一条 SOAP 消息就是一个普通的 XML 文档,包含下列元素:
xml version ="1.0" encoding ="UTF-8" ?>
< soap:Envelope xmlns:soap ="http://schemas.xmlsoap.org/soap/envelope/" >
< soap:Header >
...
soap:Header >
< soap:Body >
...
< soap:Fault >
...
soap:Fault >
soap:Body >
soap:Envelope >
soap:Envelope是SOAP中根元素元素。Envelope元素中可以包含多个可选的Header元素,必须同时包含一个Body元素。Header元素必须是Envelope元素的直接子元素,并且要位于Body元素之前。
soap:Header与HTTP请求中的Headers类似,用于传送一些基础的通用的数据,例如安全、事务等方面的信息。Header不是SOAP消息中的必需元素,但他是扩展SOAP协议的一个功能非常强大的功能。Header有两个非常重要的属性
soap:Body是SOAP消息中必需的元素,用于传送实际的业务数据或错误信息。
soap:Fault是soap:Body的子元素,用于传送错误信息,当有错误发生时才需要次标签。
可参考:http://askcuix.iteye.com/blog/211005
WSDL简介
WSDL是WebService的描述语言,也是使用xml编写,用于描述、也可定位WebService,还不属于W3C标准。WSDL主要包含以下几个元素:
definitions WSDL的根节点,主要包括:name属性,WebService服务名,可通过@WebService注解的serviceName 更改;targetNamespace属性,命名空间,可通过@WebService注解的targetNamespace更改。
types web service 使用的数据类型,他是独立与机器和语言的类型定义,这些类型被message标签所引用。
message web service 使用的消息,他定义了WebService函数的参数。在WSDL中,输入输出参数要分开定义,使用 不同的message标签体标识。message定义的输入输出参数被portType标签所引用。
portType web service 执行的操作。引用message标签定义的内容来描述函数信息(函数名,输入输出参数等)。
service 这个元素的name 属性指定服务名称(这里与根元素的name 属性相同),子元素port的name 属性指定port 名称,子元素address的location 属性指定Web 服务的地址。
WSDL的基本结构是:
< definitions >
< types >
...
types >
< message >
...
message >
< portType >
...
portType >
< binding >
...
binding >
< service >
...
service >
definitions >
可参考:http://www.w3school.com.cn/wsdl/index.asp
2 . 基于 Axis2 框架的webservice。相对于JWS来说Axis2是一个重量级的webservice框架,准确说它是一个Web Services / SOAP / WSDL的引擎,它不但能制作和发布WebService,而且可以生成Java和其他语言版WebService客户端和服务端代码。也正是由于Axis2做了非常优秀的封装,使得我们在使用Axis2-WS的时候非常的简单,下面通过一个小例子跟大家介绍一下Axis2的应用。
(1).
首先我们要做的是下载axis.war,并将这个war包发布到我们的tomcat的webapps下。启动tomcat,访问: http://localhost:8080/axis2/,如果界面显示如下则说明发布成功:
(2). 编写我们的java类。注意我们所建立的java类不要放在任何包中,直接放在src下即可,代码如下:
public class MyService {
public String sayHello(String name, boolean isMan) {
if (isMan) {
return "Hello,Mr " +name+ "! Welcome to Webservice" ;
} else {
return "Hello,Miss " +name+ "! Welcome to Webservice" ;
}
}
}
(3).
将我们建好的class类放到%tomcat%\webapps\axis2\WEB-INF\pojo文件夹下(如果没有该文件夹请新建一个并以pojo命名)。做完这一步之后启动tomcat,访问 http://localhost:8080/axis2/services/listServices,如果出现如下界面则说明发布成功:
(4). 发布好之后我们就可以编写客户端尝试调用webservice,客户端代码如下:
package com.unimas.datacollection.webservices.client;
import org.apache.axis2.addressing.EndpointReference;
import org.apache.axis2.client.Options;
import org.apache.axis2.rpc.client.RPCServiceClient;
import javax.xml.namespace.QName;
public class Client {
public static void main(String[] args) throws Exception {
RPCServiceClient serviceClient = new RPCServiceClient();
Options options = serviceClient.getOptions();
EndpointReference er = new EndpointReference(
"http://localhost:8080/axis2/services/MyService" );
options.setTo(er);
Object[] opAddArgs = new Object[] { "张三" , false };
Class[] classs = new Class[] { String. class };
QName qname = new QName( "http://ws.apache.org/axis2" , "sayHello" );
System.out.println(serviceClient.invokeBlocking(qname, opAddArgs,
classs)[0 ]);
}
}
至此Axis2-WS发布完成,执行客户端代码即可在控制台输出调用结果。
以上是对JWS和Axis2具体应用的简单介绍,对比这两种应用可以发现使用JWS比较灵活,我们可以随意的增加服务而不需要一次次的重新部署,但是我们所要做的工作量是比较大的。而使用Axis2对于开发webservice来讲相当的简单,我们唯一需要做的就是开发一个普通的java类,然后放到tomcat的对应文件夹下即可,可以说小有小的好处,大有大的优势。
axis2+spring集成
1、新建一个web project项目,最终工程目录如下:
注意:本文只注重webservice服务器端的开发,因此com.ljq.client和com.ljq.test忽略不计
2、添加所需jar
3、接口HelloWorld
package
com.ljq.service;
public
interface
HelloWorld {
public
String greeting(String name);
public
String print();
}
4、接口实现类HelloWorldBean
package
com.ljq.service;
public
class
HelloWorldBean
implements
HelloWorld {
public
String greeting(String name) {
return
"
你好
"
+
name;
}
public
String print() {
return
"
我叫林计钦
"
;
}
}
5、webservice类HelloWorldWebService
package
com.ljq.service;
import
org.apache.axis2.AxisFault;
import
org.apache.axis2.ServiceObjectSupplier;
import
org.apache.axis2.description.AxisService;
import
org.apache.axis2.description.Parameter;
import
org.apache.axis2.i18n.Messages;
import
org.springframework.beans.BeansException;
import
org.springframework.context.ApplicationContext;
import
org.springframework.context.ApplicationContextAware;
/**
* 可能出现Axis2 spring bean not found 或者 Spring applicationContext not found。
*
* 解决办法:构建自己的ServiceObjectSupplier,实现接口ServiceObjectSupplier,同时也实现Spring的ApplicationContextAware接口
*
*
*
@author
Administrator
*
*/
public
class
HelloWorldWebService
implements
ServiceObjectSupplier,
ApplicationContextAware {
private
static
ApplicationContext ctx;
public
Object getServiceObject(AxisService axisService)
throws
AxisFault {
Parameter springBeanName
=
axisService.getParameter(
"
SpringBeanName
"
);
String beanName
=
((String) springBeanName.getValue()).trim();
if
(beanName
!=
null
) {
if
(ctx
==
null
)
throw
new
AxisFault(
"
applicationContext is NULL!
"
);
if
(ctx.getBean(beanName)
==
null
)
throw
new
AxisFault(
"
Axis2 Can't find Spring Bean:
"
+
beanName);
return
ctx.getBean(beanName);
}
else
{
throw
new
AxisFault(Messages.getMessage(
"
paramIsNotSpecified
"
,
"
SERVICE_SPRING_BEANNAME
"
));
}
}
public
void
setApplicationContext(ApplicationContext ctx)
throws
BeansException {
this
.ctx
=
ctx;
}
}
6、配置web.xml文件
xml version="1.0" encoding="UTF-8"
?>
<
web-app
version
="2.5"
xmlns
="http://java.sun.com/xml/ns/javaee"
xmlns:xsi
="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation
="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
>
<
listener
>
<
listener-class
>
org.springframework.web.context.ContextLoaderListener
listener-class
>
listener
>
<
context-param
>
<
param-name
>
contextConfigLocation
param-name
>
<
param-value
>
/WEB-INF/applicationContext.xml
param-value
>
context-param
>
<
servlet
>
<
servlet-name
>
AxisServlet
servlet-name
>
<
servlet-class
>
org.apache.axis2.transport.http.AxisServlet
servlet-class
>
<
load-on-startup
>
1
load-on-startup
>
servlet
>
<
servlet-mapping
>
<
servlet-name
>
AxisServlet
servlet-name
>
<
url-pattern
>
/services/*
url-pattern
>
servlet-mapping
>
<
welcome-file-list
>
<
welcome-file
>
index.jsp
welcome-file
>
welcome-file-list
>
web-app
>
7、在WEB-INF目录下配置applicationContext.xml(不存在则自己创建)
xml version="1.0" encoding="UTF-8"
?>
DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd"
>
<
beans
>
<
bean
id
="applicationContext"
class
="org.apache.axis2.extensions.spring.receivers.ApplicationContextHolder"
/>
<
bean
id
="helloWorld"
class
="com.ljq.service.HelloWorldBean"
>
bean
>
beans
>
8、在WEB-INF\services\axis\META-INF\目录下配置services.xml(不存在则自己创建)
xml version="1.0" encoding="UTF-8"
?>
<
service
name
="hwWebService"
>
<
description
>
axis2与spring集成案例
description
>
<
parameter
name
="ServiceObjectSupplier"
>
org.apache.axis2.extensions.spring.receivers.SpringAppContextAwareObjectSupplier
parameter
>
<
parameter
name
="SpringBeanName"
>
helloWorld
parameter
>
<
messageReceivers
>
<
messageReceiver
mep
="http://www.w3.org/2004/08/wsdl/in-only"
class
="org.apache.axis2.rpc.receivers.RPCInOnlyMessageReceiver"
/>
<
messageReceiver
mep
="http://www.w3.org/2004/08/wsdl/in-out"
class
="org.apache.axis2.rpc.receivers.RPCMessageReceiver"
/>
messageReceivers
>
service
>
axis2+spring集成到此已经开发完成,接下把工程部署到tomcat,
然后通过http://localhost:8083/axis2spring/services/hwWebService?wsdl访问
XFire
客户端开发参考:http://www.blogjava.net/fastzch/archive/2008/01/03/172535.html
CXF
这边我是用Spring的jar包是Spring官方提供的,并没有使用CXF中的Spring的jar文件。
添加这么多文件后,首先在web.xml中添加如下配置:
< listener > < listener-class > org.springframework.web.context.ContextLoaderListenerlistener-class >
listener > < context-param > < param-name > contextConfigLocationparam-name >
< param-value > classpath*:applicationContext-server.xmlparam-value >
context-param >
< listener > < listener-class > org.springframework.web.util.IntrospectorCleanupListenerlistener-class >
listener >
< servlet > < servlet-name > CXFServiceservlet-name >
< servlet-class > org.apache.cxf.transport.servlet.CXFServletservlet-class >
servlet >
< servlet-mapping > < servlet-name > CXFServiceservlet-name >
< url-pattern > /*url-pattern >
servlet-mapping >
然后在src目录中,新建一个applicationContext-server.xml文件,文件内容如下:
xml version ="1.0" encoding ="UTF-8" ?> < beans xmlns ="http://www.springframework.org/schema/beans" xmlns:context ="http://www.springframework.org/schema/context"
xmlns:jaxws ="http://cxf.apache.org/jaxws"
xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation ="http://www.springframework.org/schema/beans >
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://cxf.apache.org/jaxws
http://cxf.apache.org/schemas/jaxws.xsd
注意上面的带下划线加粗部分,这个很重要的哦!不能写错或是遗漏了。
添加完这个文件后,还需要在这个文件中导入这么几个文件。文件内容如下:
< import resource ="classpath:META-INF/cxf/cxf.xml" /> < import resource ="classpath:META-INF/cxf/cxf-extension-soap.xml" /> < import resource ="classpath:META-INF/cxf/cxf-servlet.xml" />
下面开始写服务器端代码,首先定制服务器端的接口,代码如下:
package com.hoo.service;
import javax.jws.WebParam;import javax.jws.WebService;import javax.jws.soap.SOAPBinding;import javax.jws.soap.SOAPBinding.Style;import com.hoo.entity.User;import com.hoo.entity.Users;
/** * function: 定制客户端请求WebService所需要的接口 * @author hoojo * @createDate 2011-3-18 上午08:22:55 * @file ComplexUserService.java * @package com.hoo.service * @project CXFWebService