
凌云时刻 · 技术


导读:上一篇笔记主要介绍了NumPy,Matplotlib和Scikit Learn中Datasets三个库的用法,以及基于欧拉定理的kNN算法的基本实现。这一篇笔记的主要内容是通过PyCharm封装kNN算法并且在Jupyter Notebook中调用,以及计算器算法的封装规范,kNN的k值如何计算,如何使用Scikit Learn中的kNN算法。
作者 | 计缘
来源 | 凌云时刻(微信号:linuxpk)
封装kNN算法

上一篇笔记中我们对kNN算法在Jupyter Notebook中进行了实现,但是想要复用这个算法就很不方便,所以我们来看看如何在PyCharm中封装算法,并且在Jupyter Notebook中进行调用。
PyCharm的配置这里我就不再累赘,如图所示,我们创建了一个Python文件kNN.py,然后定义了kNNClassify方法,该方法有4个参数,分别是kNN算法的k值,训练样本特征数据集XTrain,训练样本类别数据集yTrain,预测特征数据集x。该方法中的实现和在Jupyter Notebook中实现的一模一样,只不过加了三个断言,让方法的健壮性更好一点。我们给出N维欧拉定理:
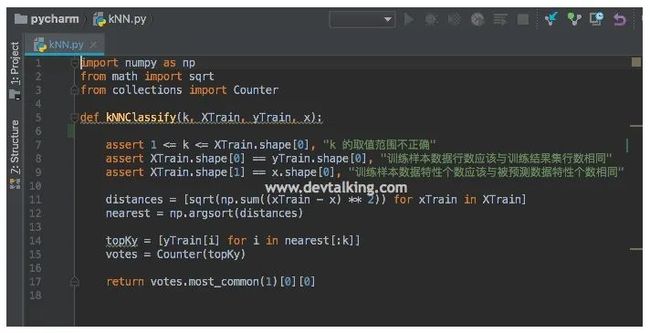
# kNN.py
import numpy as np
from math import sqrt
from collections import Counter
def kNNClassify(k, XTrain, yTrain, x):
assert 1 <= k <= XTrain.shape[0], "k 的取值范围不正确"
assert XTrain.shape[0] == yTrain.shape[0], "训练样本数据行数应该与训练结果集行数相同"
assert XTrain.shape[1] == x.shape[0], "训练样本数据特性个数应该与被预测数据特性个数相同"
distances = [sqrt(np.sum((xTrain - x) ** 2)) for xTrain in XTrain]
nearest = np.argsort(distances)
topKy = [yTrain[i] for i in nearest[:k]]
votes = Counter(topKy)
return votes.most_common(1)[0][0]
|
这样我们就在PyCharm中封装好了kNN算法的方法,我们再来看看如何在Jupyter Notebook中调用封装好的方法呢,这就需要使用%run这个
import numpy as np
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
XTrain = np.array(raw_data_X)
yTrain = np.array(raw_data_y)
x = np.array([8.093607318, 3.365731514])
# 使用%run命令可以引入Python文件,并可使用该Python文件中定义的属性和方法
%run ../pycharm/kNN.py
predicty = kNNClassify(6, XTrain, yTrain, x)
predicty
# 结果
1
|
机器学习流程
这一小节我们来看看机器学习的大概流程是怎样的,如下图所示:

监督学习算法首先需要的是训练数据集,然后通过一个机器学习算法生成一个模型,最后就可以用这个模型来预测新的数据得到结果。通常,我们将使用机器学习生成模型的过程用fit来表示,使用模型预测新的数据的过程用predict来表示。这就是机器学习最基本的一个流程。
在第一篇笔记中,介绍了线性回归的概念,我们最后得到了一个二元线性回归的公式:
这个公式其实就是通过线性回归算法得到的模型,通过fit过程,训练模型得到a,b,然后通过predict过程预测新的样例数据得到结果。
但是我们发现kNN算法不存在训练模型的过程,因为新的样例数据其实是需要通过训练数据集来进行预测的,所以换个角度来看,kNN算法的模型就是它的训练数据集,在上图中模型阶段其实就是把训练数据集复制了一份作为模型来使用,那么对于fit和predict过程而言,kNN算法的predict过程其实是核心,而fit过程非常简单。
使用Scikit Learn中的kNN算法
这一节我们来看看如何使用Scikit Learn中封装的kNN算法:
# 导入Scikit Learn中的kNN算法的类库
from sklearn.neighbors import KNeighborsClassifier
# 初始化kNN算法分类器的实例,参数n_neighbors就是k值
kNNClassifier = KNeighborsClassifier(n_neighbors=6)
# 训练,拟合模型
kNNClassifier.fit(XTrain, yTrain)
# 预测新的样例数据,该方法接受的参数类型为二维数组,如果只有一行也需要转换为一行的二维数组
kNNClassifier.predict(x.reshape(1, -1))
# 结果
array([1])
|
从示例代码中可以看出,Scikit Learn中封装的kNN算法严格遵从了上一节介绍的机器学习的基本流程,其实不止是kNN算法,Scikit Learn中的所有机器学习算法都遵从这个基本流程。
重新封装kNN算法
所以我们可以优化一下我们之前封装的kNN算法的方法,将其封装为类似Scikit Learn中的方式:

class KNNClassifier:
# 初始化kNN分类器
def __init__(self, k):
assert k >= 1, "k 值不能小于1"
self.k = k
self._XTrain = None
self._yTrain = None
# 根据训练数据集XTrain和yTrain训练kNN分类器,在kNN中这一步就是复制训练数据集
def fit(self, XTrain, yTrain):
assert XTrain.shape[0] == yTrain.shape[0], \
"训练样本特征数据集的行数要与训练样本分类结果数据集的行数相同"
assert XTrain.shape[0] >= self.k, \
"训练样本特征数据集的行数,既样本点的数量要大于等于k值"
self._XTrain = XTrain
self._yTrain = yTrain
return self
# 输入样本数据,根据模型进行预测
def predict(self, XPredict):
assert self._XTrain is not None and self._yTrain is not None, \
"在执行predict方法前必须先执行fit方法"
assert XPredict.shape[1] == self._XTrain.shape[1], \
"被预测数据集的特征数,既列数必须与模型数据集中的特征数相同"
ypredict = [self._predict(x) for x in XPredict]
return np.array(ypredict)
# 实现私有的预测方法,kNN算法的核心代码
def _predict(self, x):
assert x.shape[0] == self._XTrain.shape[1], \
"输入的样本数据的特征数量必须等于模型数据,既训练样本数据的特征数量"
distance = [sqrt(np.sum((xTrain - x) ** 2)) for xTrain in self._XTrain]
nearest = np.argsort(distance)
topK = [self._yTrain[i] for i in nearest[:self.k]]
votes = Counter(topK)
return votes.most_common(1)[0][0]
def __repr__(self):
return "kNN(k=%d)" % self.k
|
上面的代码清晰的定义了fit和predict方法,至于_predict这个私有方法可以随意,可以将逻辑直接写在predict方法里,也可以拆分出来。然后我们在Jupyter Notebook中再来使用一下我们封装的kNN算法:
%run ../pycharm/kNN/kNN.py
myKNNClassifier = KNNClassifier(6)
myKNNClassifier.fit(XTrain, yTrain)
# 结果
kNN(k=6)
xTrain = x.reshape(1, -1)
myKNNClassifier.predict(xTrain)
# 结果
array([1])
|
判断机器学习算法的性能
现在大家应该知道机器算法的目的主要是训练出模型,然后输入样本,通过模型来预测结果,可见这个模型是非常关键的,模型的好坏直接影响预测结果的准确性,继而对实际运用会产生巨大的影响。模型的训练除了机器学习算法以外,对它影响比较大的还有训练样本数据,我们在实现kNN算法时,是将所有的样本数据用于训练模型,那么模型训练出来后就已经没有数据供我们验证模型的好坏了,只能直接投入真实环境使用,这样的风险是很大的。
所以为了避免上述这种情况,最简单的做法是将所有训练样本数据进行切分,将大部分数据用于训练模型,而另外一小部分数据用来测试训练出的模型,这样如果我们用测试数据发现这个模型不够好,那么我们就有机会在将模型投入真实环境使用之前改进算法,训练出更好的模型。
我们来看看如何封装拆分训练数据的方法:
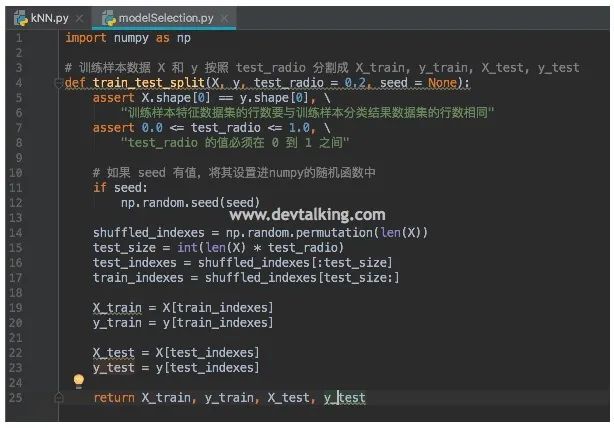
import numpy as np
# 训练样本数据 X 和 y 按照 test_radio 分割成 X_train, y_train, X_test, y_test
def train_test_split(X, y, test_radio = 0.2, seed = None):
assert X.shape[0] == y.shape[0], \
"训练样本特征数据集的行数要与训练样本分类结果数据集的行数相同"
assert 0.0 <= test_radio <= 1.0, \
"test_radio 的值必须在 0 到 1 之间"
# 如果 seed 有值,将其设置进numpy的随机函数中
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_radio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, y_train, X_test, y_test
|
我们来解读一下上面的代码:
首先train_test_split函数有四个参数,两个必填参数,两个非必填有默认值的参数。X是训练样本特征数据集,y是训练样本分类结果数据集,test_radio是设置训练数据和测试数据的比例,seed就很好理解了,就是NumPy的随机函数提供的随机种子机制。
上面代码中有一个方法大家之前应该没见过,那就是permutation(x),该方法表示返回一个乱序的一维向量,元素从0到x,所以shuffled_indexes是一个乱序的一维向量数组,它的元素总数为训练样本数据的总数,既训练样本数据矩阵的行数,元素的范围从0到训练样本数据的总数。
根据test_radio计算出需要分割出的测试数据数量test_size。
根据test_size从shuffled_indexes中取出test_indexes和train_indexes,这两个数组中存的元素就是作为索引来用的。
根据test_indexes和train_indexes从X和y中得到X_train、y_train、X_test、y_test。
之前在Jupyter Notebook中我们使用%run命令使用我们封装的代码 ,这一节我们来看看如何使用import的方式使用我们自己封装的代码。其实这和Jupyter Notebook没多大关系,我们需要做的只是给Python设置一个搜索包的路径而已,这里这会对MacOS,以及安装了Anaconda的环境作以说明,Windows系统大同小异。
首先找到路径/anaconda3/lib/python3.6/site-packages,在该路径下创建一个文件XXX.pth,该文件的扩展名必须为pth,文件名称可以随意。然后在该文件中输入你希望Python搜索包的绝对路径即可。
设置完搜索路径后,我们需要修改一下PyCharm中的目录结构:

我新建了一个目录名为myML,kNN.py是我们之前封装的kNN算法相关的方法,modelSelection.py里就是我们刚才封装好的拆分训练和测试数据的方法,另外还增加了一个__init__.py的文件,因为有了这个文件,myML就变为了一个包。__init__.py的作用这里不做过多解释。
这样我们就可以在Jupyter Notebook中用import的方式导入我们封装的模块了:
from myML.modelSelection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y)
X_train.shape
# 结果
(120, 4)
y_train.shape
# 结果
(120,)
X_test.shape
# 结果
(30, 4)
y_test.shape
# 结果
(30,)
|
这样就可以很方便的使用我们封装的模块了,下面我们来看看怎么判断我们封装的kNN算法的好坏程度:
# 先用训练数据训练模型,然后输入测试样本特征数据,得到预测结果
from myML.kNN import KNNClassifier
my_knn_classifier = KNNClassifier(6)
my_knn_classifier.fit(X_train, y_train)
my_y_test = my_knn_classifier.predict(X_test)
my_y_test
# 结果
array([1, 0, 1, 1, 0, 1, 2, 2, 0, 1, 0, 1, 2, 1, 2, 1, 0, 1, 2, 2, 1, 1, 1,
1, 0, 1, 2, 1, 1, 2])
# 用预测出的结果和测试样本分类结果数据做对比,得出准确率
y_test
# 结果
array([1, 0, 1, 1, 0, 1, 2, 2, 0, 1, 0, 1, 2, 1, 2, 1, 0, 1, 2, 2, 1, 1, 1,
1, 0, 1, 1, 1, 1, 2])
sum(my_y_test == y_test) / len(y_test)
# 结果,准确率为96.67%
0.96666666666666667
|
这样我们就得出了一个算法的好坏程度。
END

往期精彩文章回顾

机器学习笔记(三):NumPy、Matplotlib、kNN算法
机器学习笔记(二):矩阵、环境搭建、NumPy
机器学习笔记(一):机器的学习定义、导数和最小二乘
Kafka从上手到实践 - 实践真知:搭建Kafka相关的UI工具
Kafka从上手到实践 - Kafka集群:启动Kafka集群
Kafka从上手到实践 - Kafka集群:Kafka Listeners
Kafka从上手到实践 - Kafka集群:配置Broker
Kafka从上手到实践:搭建Zookeeper集群
Kafka从上手到实践-Zookeeper CLI:CRUD zNode
Kafka从上手到实践 - 初步认知:Zookeeper

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见