XML使用小结
1.XML的学习
1)XML的基本概念
- XML的设计宗旨是传输数据和存储数据,而不是显示数据,与之相对应的是HTML,它被设计来显示数据。
- XML的解析:常见的解析方式有:DOM,DOM4J,SAX
其中:DOM和DOM4J是一次将要解析的XML文件读取到内存中,然后解析,而SAX是边读边解析,适用于解析大的XML文件。
2.使用DOM4J解析XML的过程:
XML的结构:
根据DOM规定,XML文档中每个成分都是一个节点
DOM是这样规定的:
- 整个文档是一个文档节点
- 每个XML标签是一个元素节点
- 包含在XML元素中文本是文本节点
- 每一个XML属性是一个属性节点
- 注释属于注释节点
DOM4J定义了几个Java类,以下是最常见的类:
- Document - 表示整个XML文档。文档Document对象是通常称为DOM树。
- Element - 表示一个XML元素。Element对象有方法来操作其子元素,它的文本,属性和名称空间。
- Attribute - 表示元素的属性。属性有方法来获取和设置属性的值。它有父节点和属性类型。
- Node - 代表元素,属性或处理指令。
当使用DOM4J,经常用到下面的几种方法:
- SAXReader.read(xmlSource) - 构建XML源的DOM4J文档
- Document.getRootElement() - 得到的XML的根元素
- Element.node(index) - 获得在元素特定索引XML节点
- Element.attributes() - 获取一个元素的所有属性
- Node valueOf(@Name) - 得到元件给定名称的属性的值
第一步:创建解析器
SAXReader reader = new SAXReader();
第二步:通过解析器read()方法获取Document对象
Document doc = reader.read("student.xml");
第三步:获取xml根节点
Element root = doc.getRootElement();
第四步:遍历解析子节点
第五步:再进行一次遍历,获取每个元素
示例:
吴飞
Java学院
623546666
男,1982,硕士,北京邮电
李雪
C++学院
62358888
男,1987,硕士,中国农业
Java
PHP学院
6666666
澳洲
在上面的XML中,根节点是
解析的代码:
public class Dom4jTest {
public static void main(String[] args){
try {
//第一步创建解析器
SAXReader reader = new SAXReader();
//通过解析器都read方法将配置文件读取到内存中,生成一个Document[org.dom4j]对象树
Document document = reader.read("Conf/students.xml");
//获取根节点
Element root = document.getRootElement();
//开始遍历根节点
Iterator rootIter = root.elementIterator();
while(rootIter.hasNext()){
Element studentElt = rootIter.next();
Iterator iterator = studentElt.elementIterator();
while(iterator.hasNext()){
Element innerElt = iterator.next();
String innerValue = innerElt.getStringValue();
System.out.println(innerValue);
}
System.out.println("-------------");
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} 输出:
吴飞
Java学院
623546666
男,1982,硕士,北京邮电
---------------
李雪
C++学院
62358888
男,1987,硕士,中国农业
---------------
Java
PHP学院
6666666
澳洲
---------------3.使用SAX解析方式
SAX解析的步骤:
1)创建解析工厂——通过newInstance()方法获取
SAXParserFactory saxParserFactory =SAXParserFactory.newInstance();
2)通过解析工厂创建解析器
SAXParser saxParse =saxParserFactory.newSAXParser();
3)执行parser方法,传入两个参数:xml文件路径和事件处理器
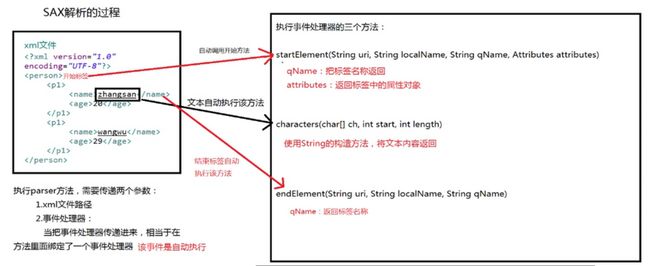
Sax采用事件驱动方式解析文档,在Sax的解析过程中,读取到文档开头、结尾、元素的开头和结尾都会触发一些回调方法,我们可以在这些回调方法中进行相应事件的处理,这四个方法是:startDocument()、endDocument()、startElement()、endElement()。此外光读到节点处是不够的,还需要characters()方法仔细处理元素内包含的内容。从Main方法中读取文档,却在触发器中处理文档,这就是所谓的事件驱动解析方法。

解析的步骤:
新建一个类继承DefaultHandler,并重写父类的五个方法,startDocument()方法会在开始XML解析的时候调用,startElement()方法会在开始解析某个节点的时候调用,characters()方法会在获取结点中内容的时候调用,endElement()方法会在完成解析某个节点的时候调用,endDocument()方法会在完整整个XML解析的时候调用。
建立一个简单的xml数据:
小明
20
吴飞
29
测试代码:
class MyHandler extends DefaultHandler{
private String nodeName;
private StringBuilder name;
private StringBuilder age;
//接收文档开始时的通知
public void startDocument() throws SAXException{
name = new StringBuilder(); //对name和age节点分别定义一个StringBuiler对象
age = new StringBuilder();
}
//接收元素开始的通知
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
nodeName = qName; //qName参数 记录着当前结点的名字
}
//接收元素中字符数据的通知 //解析结点具体内容时调用characters()方法
public void characters(char[] ch, int start, int length) throws SAXException {
if("name".equals(nodeName)){ //nodeName 可能为name或age
name.append(ch,start,length);
}
else if("age".equals(nodeName)){
age.append(ch,start,length);
}
}
//接收元素结束的通知
public void endElement(String uri, String localName, String qName) throws SAXException {
if("per".equals(qName)){
System.out.println("name: "+name.toString().trim()); //因为可能含有换行符或者回车
System.out.println("age: "+age.toString().trim());
name.setLength(0); //清空StringBuilder
age.setLength(0);
}
}
}结果输出
name: 小明
age: 20
name: 吴飞
age: 29
说明:trim()函数的用法,因为解析过程中一些换行符页被当做内容解析出来。
参考文献:
https://www.cnblogs.com/nerxious/archive/2013/05/03/3056588.html
http://www.runoob.com/xml/xml-tree.html
https://blog.csdn.net/junoohoome/article/details/74622531
https://blog.csdn.net/yyywyr/article/details/38359049