Hadoop的高可用集群搭建
Hadoop的高可用集群搭建
- 搭建规划:
hadoop 高可用集群的搭建依赖于 zookeeper,所以选取三台当做 zookeeper 集群 ,这里总共准备了八台主机(可按实际规划,不一定要这么多台),分别是 hadoop01,hadoop02,hadoop03,hadoop04, hadoop05,zk01,zk02,zk03。其中 hadoop01 和 hadoop02 做 namenode 的主备切换,hadoop03 和 hadoop04 做 resourcemanager 的主备切换。zk01,zk02,zk03是zookeeper。具体安排可参加下表:
|
|
hadoop01 |
hadoop02 |
hadoop03 |
hadoop04 |
hadoop05 |
zk01 |
zk02 |
zk03 |
| Nam NameNode |
√ |
√ |
|
|
|
|
|
|
| datandatanode |
|
|
√ |
√ |
√ |
|
|
|
| resou resourceManager |
|
|
|
√ |
√ |
|
|
|
| nodemanager |
√ |
√ |
√ |
√ |
√ |
|
|
|
| zookeeper |
|
|
|
|
|
√ |
√ |
√ |
| journalnode |
√ |
√ |
√ |
|
|
|
|
|
| zkfc |
√ |
√ |
|
|
|
|
|
|
- 搭建服务器前准备:
- 修改主机名称,将主机名改成表中hadoop01—hadoop05
- 增加主机名和ip的映射
- 添加普通用户 eastcom 用户并配置 visudo配置sudo 权限
- 安装jdk,并设置环境变量,这里装的是1.8版本
- 配置ssh免密登陆:
利用ssh-keygen生成密钥,再copy到其他机器上,这样就可以ssh免密登陆
ssh-copy-id -i /home/eastcom/.ssh/id_rsa.pub eastcom@172.16.100.122
- 安装zookeeper集群,这个可以参考网络教程:
https://www.cnblogs.com/wrong5566/p/6056788.html
这里主要介绍hadoop集群部署。
- 安装hadoop集群:
1.官网下载安装包:
建议不要下载source源码包,不然要自己编译。可以直接下载binary的,下完解压即可。本文档安装的版本为2.8.5
地址:https://hadoop.apache.org/releases.html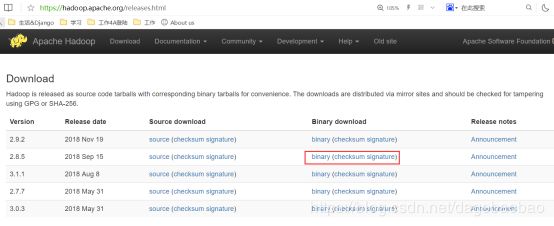
下载完,上传到服务器指定的目录解压即可,注意这里你只要先上传到hadoop01服务器即可,无需先将压缩包传到其他四台上!
2.修改配置文件(重点):
配置文件目录:/home/eastcom/hadoop-2.8.5/etc/hadoop
- 修改hadoop-env.sh
这个主要修改JAVA_HOME,把设置的JAVA_HOME加进去即可如图25行左右的位置:

(2)修改core-site.xml,详情如下
(3) 修改hdfs-site.xml,详情如下
sshfence
shell(/bin/true)
(4) 修改mapred-site.xml,先
cp mapred-site.xml.template mapred-site.xml
再修改mapred-site.xml内容,详情如下
(5)修改yarn-site.xml 详情如下
(6) 修改slaves(即加入datanode服务器)
hadoop03
hadoop04
hadoop05
3. 将hadoop安装包分发到其他集群节点
重点: 所有hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致!!!
scp -r ./hadoop-2.8.5 hadoop2:$PWD
scp -r ./hadoop-2.8.5 hadoop02:$PWD
scp -r ./hadoop-2.8.5 hadoop03:$PWD
scp -r ./hadoop-2.8.5 hadoop04:$PWD
scp -r ./hadoop-2.8.5 hadoop05:$PWD
4. 配置hadoop环境变量:
如下增加部分:
[eastcom@hadoop01 ~]$ cat .bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=
# User specific aliases and functions
export JAVA_HOME=/home/eastcom/jdk1.8.0_66
export PATH=:$JAVA_HOME/bin:$PATH
export CLASS_PATH=.:$JAVA_HOME/lib
export HADOOP_HOME=/home/eastcom/hadoop-2.8.5/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
记得使环境变量生效source .bashrc
生效后就可以利用hadoop version查看hadoop的版本了,如下

- Hadoop高可用集群初始化
按照以下步骤逐步进行操作:
1. 先启动已经安装的zookeeper:zkServer.sh start,
可以在hadoop上执行telnet zk01 2181测试一下保证你部署的三台zookeeper是”通的”:
2.在各个journalnode节点上启动该进程:
hadoop-daemon.sh start journalnode

3.格式化namenode
先选其中的hadoop01节点进行格式化
hadoop namenode –format
执行后会看到这一句关键字说明成功了.这个就是hadoop1生成的元数据
Storage directory /home/eastcom/data/hadoopdata/dfs/name has been successfully formatted.
4.把hadoop01节点上生成的元数据给复制到另一个namenode(hadoop02)上
cd data/
scp -r hadoopdata/ hadoop02:$PWD
就是这四个文件可以检查一下:
-rw-rw-r-- 1 eastcom eastcom 323 Jan 3 09:42 fsimage_0000000000000000000
-rw-rw-r-- 1 eastcom eastcom 62 Jan 3 09:42 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 eastcom eastcom 2 Jan 3 09:42 seen_txid
-rw-rw-r-- 1 eastcom eastcom 218 Jan 3 09:42 VERSION
5.格式化zkfc(只能在namenode节点进行)
hdfs zkfc –formatZK
执行后可以看到关键句说明格式化成功:
Successfully created /hadoop-ha/myha01 in ZK
- 启动集群
- 启动HDFS
start-dfs.sh
启动完可以用jps查看进程在不在也可以用以下命令验证节点的状态: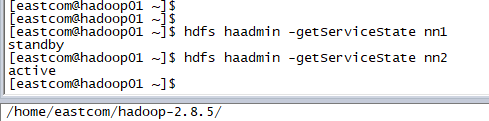
2.启动YARN
在主备 resourcemanager 中随便选择一台进行启动,若备用节点的 resourcemanager 没有启动起来,则手动启动起来
yarn-daemon.sh start resourcemanager然后查看一下YARN的状态:
- 启动mapreduce任务历史服务器:
mr-jobhistory-daemon.sh start historyserver
4.用web页面进行查看:
验证HDFS:
hadloop01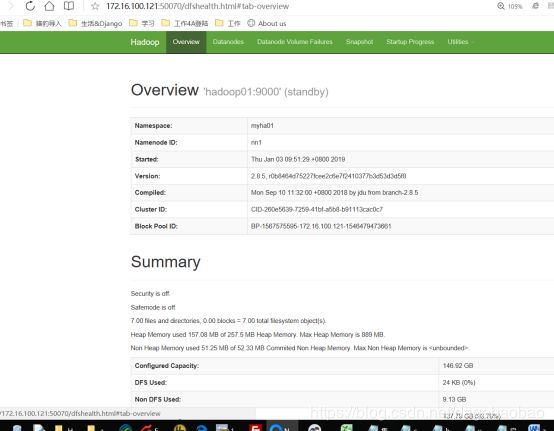
Hadloop2
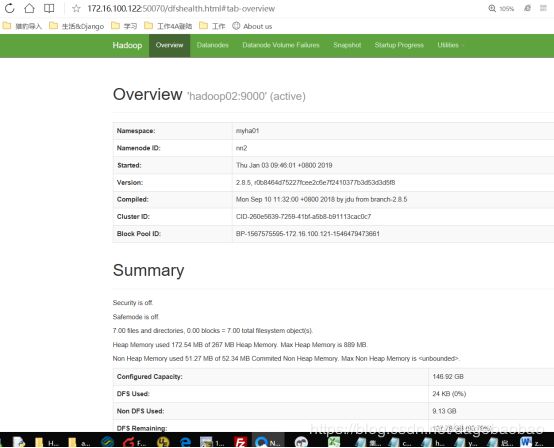
Datanode信息:
YARN验证
standby节点会自动跳到avtive节点
在浏览器172.16.100.125:8088自动跳到http://hadoop04:8088/因为我本机没有配hosts跳的页面打不开正常。所以可以输入ip172.16.100.124:8088来看。
这个过程能跳说明就ok的!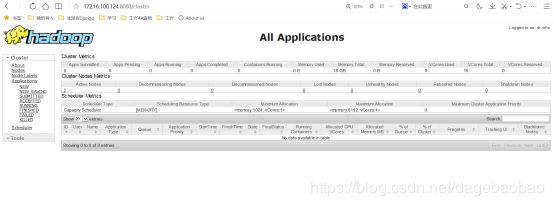
关于hadoop集群搭建过程差不多就这样。由于水平有限,请多指正!