Python自动化运维实战:从Linux系统中收集数据
使用Linux命令可以查看当前系统状态和运行状况的相关数据。然而,单个Linux命令和应用程序只能获取某一方面的系统数据。我们需要利用Python模块将这些详细信息反馈给管理员,同时生成一份有用的系统报告。
我们将报告分为两部分。第一部分是使用platform模块获取的一般系统信息,第二部分是硬件资源,如CPU和内存等。
首先从导入platform模块开始,它是一个内置的Python库。platform模块中有很多方法,它们可用来获取当前运行Python命令的操作系统的详细信息。
import platform
system = platform.system()
print(system)上述代码的运行结果如下。
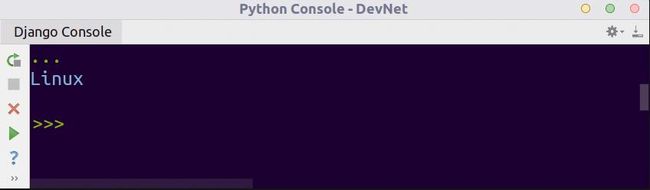
该脚本返回当前系统的类型,同样的脚本在Windows系统上运行会得到不同的结果。当它在Windows系统上运行时,输出结果就变成Windows。

常用的函数uname()和Linux命令(uname -a)的功能一样:获取机器的主机名、体系结构和内核信息,但是uname()采用了结构化格式,以便通过序号来引用相应的值。
import platform
from pprint import pprint
uname = platform.uname()
pprint(uname)上述代码的运行结果如下。
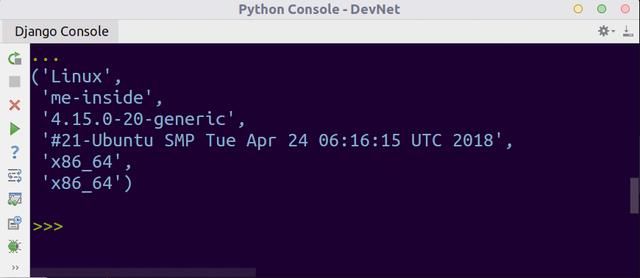
system()方法获得的第一个值是系统类型,第二个是当前机器的主机名。
使用PyCharm中的自动补全功能可以浏览并列出platform模块中的所有可用函数,按Ctrl + Q组合键就可以查看每个函数的文档(见下图)。

然后,使用Linux文件提供的信息列出Linux机器中的硬件配置。这里需要记住,在/proc/目录下可以访问CPU、内存以及网络等相关信息;我们将读取这些信息并在Python中使用标准的open()函数访问它们。查看/proc/目录可以获取更多信息。
下面给出具体的脚本。
首先,导入platform模块,它仅在当前任务中使用。
#!/usr/bin/python
__author__ = "Bassim Aly"
__EMAIL__ = "[email protected]"
import platform然后,定义函数。以下代码包含了本次练习中需要的两个函数——check_feature()和get_value_from_string()。
def check_feature(feature,string):
if feature in string.lower():
return True
else:
return False
def get_value_from_string(key,string):
value = "NONE"
for line in string.split("\n"):
if key in line:
value = line.split(":")[1].strip()
return value最后是Python脚本的主要部分,其中包括用来获取所需信息的Python代码。
cpu_features = []
with open('/proc/cpuinfo') as cpus:
cpu_data = cpus.read()
num_of_cpus = cpu_data.count("processor")
cpu_features.append("Number of Processors: {0}".format(num_of_cpus))
one_processor_data = cpu_data.split("processor")[1]
print one_processor_data
if check_feature("vmx",one_processor_data):
cpu_features.append("CPU Virtualization: enabled")
if check_feature("cpu_meltdown",one_processor_data):
cpu_features.append("Known Bugs: CPU Metldown ")
model_name = get_value_from_string("model name ",one_processor_data)
cpu_features.append("Model Name: {0}".format(model_name))
cpu_mhz = get_value_from_string("cpu MHz",one_processor_data)
cpu_features.append("CPU MHz: {0}".format((cpu_mhz)))
memory_features = []
with open('/proc/meminfo') as memory:
memory_data = memory.read()
total_memory = get_value_from_string("MemTotal",memory_data).replace("kB","")
free_memory = get_value_from_string("MemFree",memory_data).replace("kB","")
swap_memory = get_value_from_string("SwapTotal",memory_data).replace("kB","")
total_memory_in_gb = "Total Memory in GB:
{0}".format(int(total_memory)/1024)
free_memory_in_gb = "Free Memory in GB:
{0}".format(int(free_memory)/1024)
swap_memory_in_gb = "SWAP Memory in GB:
{0}".format(int(swap_memory)/1024)
memory_features =
[total_memory_in_gb,free_memory_in_gb,swap_memory_in_gb]这部分代码用来输出从上一节的代码中获取的信息。
print("============System Information============")
print("""
System Type: {0}
Hostname: {1}
Kernel Version: {2}
System Version: {3}
Machine Architecture: {4}
Python version: {5}
""".format(platform.system(),
platform.uname()[1],
platform.uname()[2],
platform.version(),
platform.machine(),
platform.python_version()))
print("============CPU Information============")
print("\n".join(cpu_features))
print("============Memory Information============")
print("\n".join(memory_features))在上面的例子中我们完成了以下任务。
(1)打开/proc/cpuinfo并读取其内容,然后将结果存储在cpu_data中。
(2)使用字符串函数count()统计文件中关键字processor的数量,从而得知机器上有多少个处理器。
(3)获取每个处理器支持的选项和功能,我们只需要读取其中一个处理器的信息(因为通常所有处理器的属性都一样)并传递给check_feature()函数。该方法的一个参数是我们期望处理器支持的功能,另一个参数是处理器的属性信息。如果处理器的属性支持第一个参数指定的功能,该方法返回True。
(4)由于处理器的属性数据以键值对的方式呈现,因此我们设计了get_value_from_string()方法。该方法根据输入的键名通过迭代处理器属性数据来搜索对应的值,然后根据冒号拆分返回的键值对,以获取其中的值。
(5)使用append()方法将所有值添加到cpu_feature列表中。
(6)对内存信息重复相同的操作,获得总内存、空闲内存和交换内存的大小。
(7)使用platform的内置方法(如system()、uname()和python_version())来获取系统的相关信息。
(8)输出包含上述信息的报告。
脚本输出如下图所示。
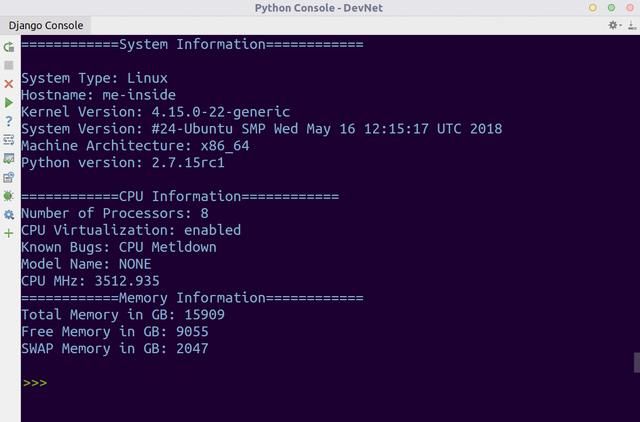
另一种呈现数据的方式是利用第5章中介绍的Matplotlib库,可视化随时间变化的数据。
11.1.1 通过邮件发送收集的数据
从上一节生成的报告中可以看到系统中当前的资源。在本节中,我们调整脚本,增强其功能,比如,将这些信息通过电子邮件发送出去。对于网络操作中心(Network Operation Center,NOC)团队来说,这个功能非常有用。当某个特殊事件(如HDD故障、高CPU或丢包)发生时,他们希望被监控系统能够自动给他们发送邮件。Python有一个内置库smtplib,它利用简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)从邮件服务器中发送和接收电子邮件。
使用该功能要求在计算机上安装本地电子邮件服务器,或者能够使用免费的在线电子邮件服务(如Gmail或Outlook)。在这个例子中我们将使用SMTP登录Gmail网站,将数据通过电子邮件发送出去。
接下来,开始动手修改脚本,为其添加SMTP功能。
将所需模块导入Python,这次需要导入smtplib和platform。
#!/usr/bin/python
__author__ = "Bassem Aly"
__EMAIL__ = "[email protected]"
import smtplib
imp ort platform下面是check_feature()和get_value_from_string()这两个函数的代码。
def check_feature(feature,string):
if feature in string.lower():
return True
else:
return False
def get_value_from_string(key,string):
value = "NONE"
for line in string.split("\n"):
if key in line:
value = line.split(":")[1].strip()
return value最后是Python脚本的主体,其中包含了获取所需信息的Python代码。
cpu_features = []
with open('/proc/cpuinfo') as cpus:
cpu_data = cpus.read()
num_of_cpus = cpu_data.count("processor")
cpu_features.append("Number of Processors: {0}".format(num_of_cpus))
one_processor_data = cpu_data.split("processor")[1]
if check_feature("vmx",one_processor_data):
cpu_features.append("CPU Virtualization: enabled")
if check_feature("cpu_meltdown",one_processor_data):
cpu_features.append("Known Bugs: CPU Metldown ")
model_name = get_value_from_string("model name ",one_processor_data)
cpu_features.append("Model Name: {0}".format(model_name))
cpu_mhz = get_value_from_string("cpu MHz",one_processor_data)
cpu_features.append("CPU MHz: {0}".format((cpu_mhz)))
memory_features = []
with open('/proc/meminfo') as memory:
memory_data = memory.read()
total_memory = get_value_from_string("MemTotal",memory_data).replace("kB","")
free_memory = get_value_from_string("MemFree",memory_data).replace("kB","")
swap_memory = get_value_from_string("SwapTotal",memory_data).replace("kB","")
total_memory_in_gb = "Total Memory in GB:
{0}".format(int(total_memory)/1024)
free_memory_in_gb = "Free Memory in GB:
{0}".format(int(free_memory)/1024)
swap_memory_in_gb = "SWAP Memory in GB:
{0}".format(int(swap_memory)/1024)
memory_features =
[total_memory_in_gb,free_memory_in_gb,swap_memory_in_gb]
Data_Sent_in_Email = ""
Header = """From: PythonEnterpriseAutomationBot
To: To Administrator
Subject: Monitoring System Report
"""
Data_Sent_in_Email += Header
Data_Sent_in_Email +="============System Information============"
Data_Sent_in_Email +="""
System Type: {0}
Hostname: {1}
Kernel Version: {2}
System Version: {3}
Machine Architecture: {4}
Python version: {5}
""".format(platform.system(),
platform.uname()[1],
platform.uname()[2],
platform.version(),
platform.machine(),
platform.python_version())
Data_Sent_in_Email +="============CPU Information============\n"
Data_Sent_in_Email +="\n".join(cpu_features)
Data_Sent_in_Email +="\n============Memory Information============\n"
Data_Sent_in_Email +="\n".join(memory_features) 下面给出连接到gmail服务器所需的信息。
fromaddr = '[email protected]'
toaddrs = '[email protected]'
username = '[email protected]'
password = 'xxxxxxxxxx'
server = smtplib.SMTP('smtp.gmail.com:587')
server.ehlo()
server.starttls()
server.login(username,password)
server.sendmail(fromaddr, toaddrs, Data_Sent_in_Email)
server.quit()在前面的例子中实现了以下功能。
(1)第一部分与上一个例子相同,只是没有将数据输出到终端,而是将其添加到Data_Sent_in_Email变量中。
(2)Header变量表示电子邮件标题,包括发件人地址、收件人地址和电子邮件主题。
(3)使用smtplib模块内的SMTP()类连接到公共Gmail SMTP服务器并完成TTLS连接。这也是连接Gmail服务器的默认方法。我们将SMTP连接保存在server变量中。
(4)使用login()方法登录服务器,最后使用sendmail()函数发送电子邮件。sendmail()有3个输入参数——发件人、收件人和电子邮件正文。
(5)关闭与服务器的连接。
脚本输出如下图所示。
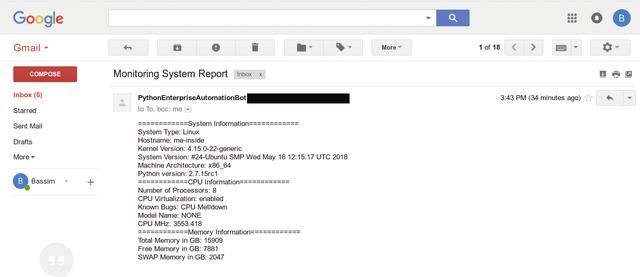
11.1.2 使用time和date模块
到目前为止,我们已经能将从服务器中生成的自定义数据通过电子邮件发送出去。但由于网络拥塞、邮件系统故障或任何其他问题,生成的数据与电子邮件的传递时间之间可能存在时间差,因此我们不能根据收到电子邮件的时间来推算实际生成数据的时间。
出于上述原因,需要使用Python中的datetime模块来获取被监控系统上的当前时间。该模块可以使用各种字段(如年、月、日、小时和分钟)来格式化时间。
除此之外,datetime模块中的datetime实例实际上是Python中独立的对象(如int、string、boolean等),因此datetime实例在Python中有自己的属性。
使用strftime()方法可以将datetime对象转换为字符串。该方法使用下表中的格式符号来格式化时间。
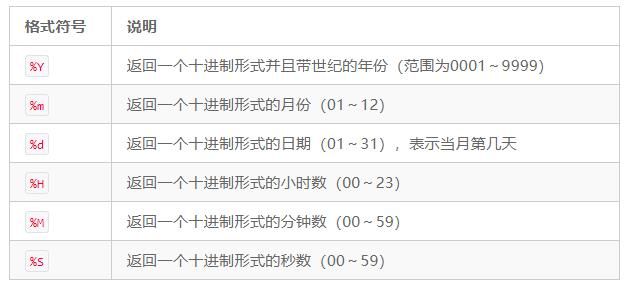
修改脚本,将下面的代码段添加到代码中。
from datetime import datetime
time_now = datetime.now()
time_now_string = time_now.strftime("%Y-%m-%d %H:%M:%S")
Data_Sent_in_Email += "====Time Now is {0}====\n".format(time_now_string)在这段代码中,首先从datetime模块中导入datetime类。然后使用datetime类和now()函数创建time_now对象,该函数返回系统的当前时间。最后使用带格式化符号的strftime()来格式化时间并将其转换为字符串,用于输出(注意,该对象包含了datetime对象)。
脚本的输出如下。

11.1.3 定期运行脚本
在脚本的最后一步,设置运行脚本的时间间隔,它可以是每天、每周、每小时或某个特定的时间。该功能使用了Linux系统上的cron服务。cron用来调度周期性的重复事件,例如,清理目录、备份数据库、转储日志或任何其他事件。
使用下面的命令可以查看当前计划中的任务。
crontab -l
编辑crontab需要使用-e选项。第一次运行cron时,系统会提示你选择自己喜欢的编辑器(nano或vi)。
典型的crontab由5颗星组成,每颗星代表一个时间项(见下表)。
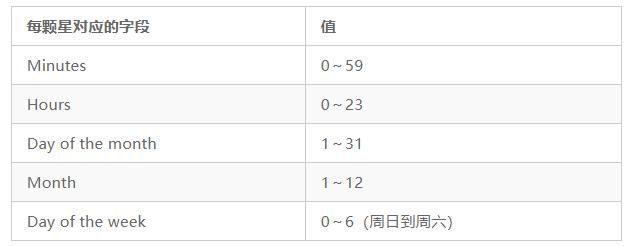
如果需要每周五晚上9点运行某个任务,可以使用下面的配置。
0 21 * * 5 /path/to/command如果需要每天0点运行某条命令(比如备份),使用这个配置。
0 0 * * * /path/to/command另外,还可以让cron以某个特定时间间隔运行。如果需要每5min运行一次命令,可以使用这个配置。
*/5 * * * * /path/to/command回到脚本,如果我们期望它每天早上7:30运行,使用这个配置。
30 7 * * * /usr/bin/python /root/Send_Email.py最后,记得在退出之前保存cron配置。
最好使用绝对路径的Linux命令,而不是相对路径,以避免出现任何潜在的问题。
本文摘自《Python自动化运维实战》

本书旨在讲述通过Python简化运维、提升运维效率的方法和实践。
本书首先介绍如何开发Python程序 、创建Python模块,然后讲述如何使用Python工具获取重要的输出信息、生成通用的配置模板、自动安装操作系统、配置大量服务器,最后讨论如何创建和管理虚拟机,如何利用OpenStack、VMware、AWS自动执行管理任务等。
通过本书,你将掌握用Python实现自动化运维的各种方法和技巧。
本书主要内容:
- Python中常用模块的用法;
- 通过Python脚本管理网络设备的方法;
- 使用Ansible和Fabric自动执行常见的Linux管理任务的方法;
- 使用Python管理VMware、OpenStack和AWS实例的方法;
- 基于Python的安全工具的用法。