kafka生产者的蓄水池机制
1.1、整体架构图
Kafka还有蓄水池?大家先别急,我们先上一张架构图。
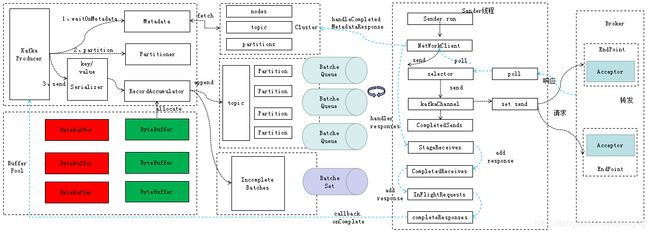
从上面的架构图可以看出,生产的流程主要就是一个producer线程和一个sender线程,它们之间通过BatchQueue来获取数据,它们的关系是一一对应的,所以kafka的生产过程都是异步过程,它的同步和异步指的是接收响应结果的模式是同步阻塞还是异步回调。同步和异步的生产者调用示例如下:
异步生产模式:
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr), new DemoCallBack(startTime, messageNo, messageStr));
同步生产模式:
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr)).get();
同步接收是依据send之后返回Future,再调用Future的get方法进行阻塞等待。下面我们就从producer和sender两个类所对应的流程来进行分析,他们分别是消息收集过程和消息发送过程。本文先介绍消息的收集过程,从上面的架构图我们可以看到这个过程的数据最终是放在BatchQueue,像是将水流入了一个蓄水池的场景,这就是本文称其为”蓄水池”的含义了。
1.2、消息收集过程
消息的收集过程主要涉及到的类有如下:
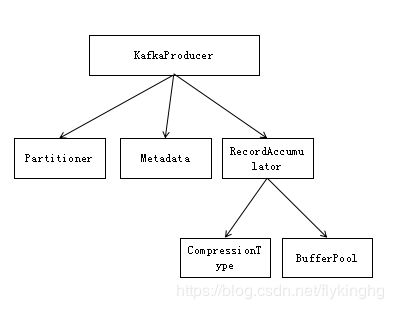
我们接下来也主要是从这几个类的功能来阐述消息收集的过程。
1.2.1、kafkaProducer字段含义及构造
kafkaProducer类包含的字段含义详见如下注释:
public class KafkaProducer implements Producer {
/** clientId 生成器,如果没有明确指定客户端 ID,则使用该字段顺序生成一个 */
private static final AtomicInteger PRODUCER_CLIENT_ID_SEQUENCE = new AtomicInteger(1);
/** 生产者唯一标识(对应 client.id 属性配置 ) */
private String clientId;
/** 分区选择器(对应 partitioner.class 属性配置),如果未明确指定分区,则基于默认的策略RR为消息选择合适的分区 */
private final Partitioner partitioner;
/** 消息的最大长度(对应 max.request.size 配置,包含消息头、序列化之后的 key 和 value) */
private final int maxRequestSize;
/** 发送单条消息的缓冲区大小(对应 buffer.memory 配置) */
private final long totalMemorySize;
/** kafka 集群元数据 */
private final Metadata metadata;
/** 消息收集器,用于收集并缓存消息,等待 Sender 线程的发送 */
private final RecordAccumulator accumulator;
/** 消息发送线程对象 */
private final Sender sender;
/** 消息发送线程,Sender由此线程启动 */
private final Thread ioThread;
/** 压缩算法(对应 compression.type 配置) */
private final CompressionType compressionType;
/** 时间戳工具 */
private final Time time;
/** key 序列化器(对应 key.serializer 配置) */
private final Serializer keySerializer;
/** value 序列化器(对应 value.serializer 配置) */
private final Serializer valueSerializer;
/** 封装配置信息 */
private final ProducerConfig producerConfig;
/** 等待更新 kafka 集群元数据的最大时长 */
private final long maxBlockTimeMs;
/** 消息发送的超时时间(从发送到收到 ACK 响应) */
private final int requestTimeoutMs;
/** 发送拦截器(对应 interceptor.classes 配置),用于待发送的消息进行拦截并修改,也可以对 ACK 响应进行拦截处理 */
private final ProducerInterceptors interceptors;
/** kafka定义的版本编号,现在为止有3个,分别为v0: kafka<0.10.0 v1:0.10.0<=kakfa<0.11.0 v2:kafka >=0.11.0 **/
private final ApiVersions apiVersions;
/** 生产者的事务管理器 **/
private final TransactionManager transactionManager;
// ... 省略方法定义
}
了解完kafkaProducer的字段含义,我们接下来看下kafkaProducer的构造过程:
KafkaProducer(ProducerConfig config,
Serializer keySerializer,
Serializer valueSerializer,
Metadata metadata,
KafkaClient kafkaClient) {
try {
//获取用户配置信息
Map userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = Time.SYSTEM;
//生产者id的生成,优先使用用户配置的id,如果没有则使用PRODUCER_CLIENT_ID_SEQUENCE递增生成一个序列号
String clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
if (clientId.length() <= 0)
clientId = "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement();
this.clientId = clientId;
//省略度量打点及日志相关信息
//获取用户配置的分区、序列化的自定义类,并实例化
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
if (keySerializer == null) {
this.keySerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = ensureExtended(keySerializer);
}
if (valueSerializer == null) {
this.valueSerializer = ensureExtended(config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class));
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = ensureExtended(valueSerializer);
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
//获取用户自定义的拦截器列表
List> interceptorList = (List) (new ProducerConfig(userProvidedConfigs, false)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
this.interceptors = new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer, valueSerializer, interceptorList, reporters);
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
//获取用户配置的消息压缩类型,默认是不做压缩
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
//省略用户的一些配置信息
//当前kafka的版本号
this.apiVersions = new ApiVersions();
//创建消息收集器,它会将为消息申请内存、消息压缩(如果需要)并压如到待发送消息缓存队列中
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time,
apiVersions,
transactionManager);
// 获取 kafka 集群主机列表
List addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
// 创建kafka元数据信息,并对它进行更新
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
true, true, clusterResourceListeners);
this.metadata.update(Cluster.bootstrap(addresses), Collections.emptySet(), time.milliseconds());
}
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
// 创建 NetworkClient 对象,NetworkClient 是 后面Sender线程和服务端进行网络I/O的核心类
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
this.metadata,
clientId,
maxInflightRequests,
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs,
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
//创建Sender发送对象
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
//新建发送线程,并将sender类加入启动
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
this.errors = this.metrics.sensor("errors");
//打印用户配置了但未使用的信息
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics);
log.debug("Kafka producer started");
} catch (Throwable t) {
//省略异常处理
}
} 从它的构造过程来看,它的核心流程主要是如下几点:
- 分区对象的创建及集群元信息的获取和更新
- 消息收集器RecordAccumulator的创建
- 网络I/O核心类NetworkClient 的创建
- Sender线程的创建及启动
前面两个就是对应着消息收集的最核心过程,后面两个是消息发送的核心过程,但是我们在介绍前面两个步骤之前还需要回到kafkaProducer来,一个消息的发送首先是kafkaProducer的创建,另外一个就是消息发送send方法了,接下来我们先介绍kafkaProducer的消息发送过程再介绍上面的两个核心流程。
1.2.2、kafkaProducer消息收集过程
kafkaProducer的send方法逻辑如下:
public Future send(ProducerRecord record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
最终是调用了doSend方法,我们来看下这个方法的主要逻辑实现:
private Future doSend(ProducerRecord record, Callback callback) {
TopicPartition tp = null;
try {
// 获取当前的集群元数据信息,如果缓存有,并且分区没有超过指定分区范围则缓存返回,否则触发更新,等待新的元数据信息
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//对消息key进行序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
//对消息value进行序列化
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
//依据分区算法进行分区,如果用户指定了则使用指定分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
//获取消息时间戳,如果未明确指定则使用当前时间戳
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// 生产者回调函数封装,当消息从服务端有返回响应,最后会被触发
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
// 将消息追加到收集器中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
//当队列中的RecordBatch超过了1个,或者最后一个RecordBatch已经满了(整体都是batchIsFull ),或者新创建了一个RecordBatch则都触发唤醒sender线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
//省略异常处理
}
} 整个流程可以归纳为如下:
1、对kafka集群元素信息的获取及更新
2、Key和value的序列化
3、如果有指定分区则采用指定分区,否则计算目标分区
4、缓存消息压入到RecordAccumulator 中
5、有条件的唤醒发送线程
这些流程里面第2步骤很简单,不做专项讲解,我们把1和3步骤放在一起作为集群信息获取及分区计算来讲解,4和5单独讲解。
1.2.3、分区计算及集群信息获取
分区计算
我们再回想下kafkaProducer的doSend过程,在消息发送前是需要计算分区信息的,我们就先介绍一下分区算法的流程。
kafkaProducer的partition方法最终会调用 partitioner.partition方法,我们来看下这个方法的实现逻辑:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取改topic下的分区信息
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
//依据可获取的分区大小进行roud-robin运算
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 没有可用的分区信息,则返回一个无效的分区序号
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 通过key的hash运算值再做round-robin
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
} 集群信息获取
集群信息的更新从上面介绍我们知道它是在消息发送的时候实施的而且是阻塞等待更新,因为信息随时可能会发生变化,我们获得的集群信息一定要是最新的,所以异步更新没有任何意义,只能采取主动等待更新。那我们先看下消息更新的一个流程图:
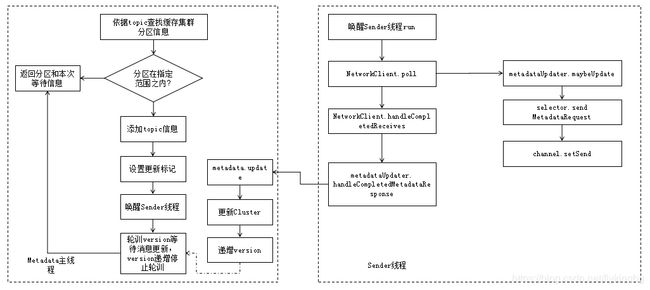
消息更新是一个标准的I/O通信过程,分为两个线程,metadata主线程等待信息获取,Sender线程进行网络I/O通信获取,并更新到metadata当中,下面我们会重点介绍metada的主线程触发更新逻辑和部分的Sender线程和metada相关的逻辑,其它Sender逻辑我们放到消息发送过程中讲解。
在讲解集群信息获取之前,我们先了解下集群对象都有些什么信息包含在里面:
public final class Cluster {
/** kafka 集群中的节点信息列表(包括 id、host、port 等信息) */
private final List nodes;
/** 未授权的 topic 集合 */
private final Set unauthorizedTopics;
/** 内部 topic 集合 */
private final Set internalTopics;
/** 记录 topic 分区与分区详细信息的映射关系 */
private final Map partitionsByTopicPartition;
/** 记录 topic 及其分区信息的映射关系 */
private final Map> partitionsByTopic;
/** 记录 topic 及其分区信息的映射关系(必须包含 leader 副本) */
private final Map> availablePartitionsByTopic;
/** 记录节点 ID 与分区信息的映射关系 */
private final Map> partitionsByNode;
/** key 是 brokerId,value 是 broker 节点信息,方便基于 brokerId 获取对应的节点信息 */
private final Map nodesById;
// ... 省略方法定义
} Metadata主线程这边的入口在kafkaProducer的waitOnMetadata方法中,具体逻辑如下:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
//添加topic到集合中,如果是新的则会设置更新集群元素标记
metadata.add(topic);
//获取缓存集群信息
Cluster cluster = metadata.fetch();
Integer partitionsCount = cluster.partitionCountForTopic(topic);
//如果分区在指定分区范围内则直接返回缓存集群信息
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
long elapsed;
//集群信息缓存没有,需要等待直到能获取到最新集群信息
do {
log.trace("Requesting metadata update for topic {}.", topic);
metadata.add(topic);
//触发更新标记needUpdate,并将当前版本信息获取,方便下面等待时候和最新的版本信息进行对比
int version = metadata.requestUpdate();
//唤醒Sender线程
sender.wakeup();
try {
//等待更新,直到version信息大于当前版本值
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
}
//获取最新的集群信息
cluster = metadata.fetch();
elapsed = time.milliseconds() - begin;
if (elapsed >= maxWaitMs)
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
if (cluster.unauthorizedTopics().contains(topic))
throw new TopicAuthorizationException(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null);
//在最新的分区信息里面,如果指定分区仍然无效,那么报异常
if (partition != null && partition >= partitionsCount) {
throw new KafkaException(
String.format("Invalid partition given with record: %d is not in the range [0...%d).", partition, partitionsCount));
}
//返回集群信息和本次等待的时间
return new ClusterAndWaitTime(cluster, elapsed);
}Sender线程主要看NetWorkClient的poll方法,它会调用metadataUpdater.maybeUpdate来发送metadataRequest请求,它的逻辑如下:
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
if (canSendRequest(nodeConnectionId)) {
this.metadataFetchInProgress = true;
//构建metadataRequest,它是客户端request的一种类型
MetadataRequest.Builder metadataRequest;
if (metadata.needMetadataForAllTopics())
metadataRequest = MetadataRequest.Builder.allTopics();
else
metadataRequest = new MetadataRequest.Builder(new ArrayList<>(metadata.topics()),
metadata.allowAutoTopicCreation());
log.debug("Sending metadata request {} to node {}", metadataRequest, node);
//调用实际的MetadataRequest发送请求
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
return requestTimeoutMs;
}
//省略一些连接等待及初始化的操作
}其中sendInternalMetadataRequest的逻辑如下:
private void sendInternalMetadataRequest(MetadataRequest.Builder builder,
String nodeConnectionId, long now) {
//将MetadataRequest包装成clientRequest
ClientRequest clientRequest = newClientRequest(nodeConnectionId, builder, now, true);
//最终调用selector的send
doSend(clientRequest, true, now);
}而响应回调主要是在NetworkClient调用poll的时候最后会handleCompletedReceives来处理接收到的信息,里面有一部分逻辑是处理MetadataResponse的,我们只贴出和它相关的逻辑如下:
if (req.isInternalRequest && body instanceof MetadataResponse)
metadataUpdater.handleCompletedMetadataResponse(req.header, now, (MetadataResponse) body);
metadataUpdater的handleCompletedMetadataResponse方法实现逻辑如下:
public void handleCompletedMetadataResponse(RequestHeader requestHeader, long now, MetadataResponse response) {
this.metadataFetchInProgress = false;
//获取响应中的集群对象信息
Cluster cluster = response.cluster();
// 错误响应码处理
Map errors = response.errors();
if (!errors.isEmpty())
log.warn("Error while fetching metadata with correlation id {} : {}", requestHeader.correlationId(), errors);
//启动metadata的更新
if (cluster.nodes().size() > 0) {
this.metadata.update(cluster, response.unavailableTopics(), now);
} else {
log.trace("Ignoring empty metadata response with correlation id {}.", requestHeader.correlationId());
this.metadata.failedUpdate(now, null);
}
}
而最终调用的metadata更新信息如下:
public synchronized void update(Cluster newCluster, Set unavailableTopics, long now) {
Objects.requireNonNull(newCluster, "cluster should not be null");
//设置更新后的指标参数,其中version递增
this.needUpdate = false;
this.lastRefreshMs = now;
this.lastSuccessfulRefreshMs = now;
this.version += 1;
if (topicExpiryEnabled) {
// 如果需要就设置topic的失效时间,默认本地缓存topic失效时间是5分钟
for (Iterator> it = topics.entrySet().iterator(); it.hasNext(); ) {
Map.Entry entry = it.next();
long expireMs = entry.getValue();
if (expireMs == TOPIC_EXPIRY_NEEDS_UPDATE)
entry.setValue(now + TOPIC_EXPIRY_MS);
else if (expireMs <= now) {
it.remove();
log.debug("Removing unused topic {} from the metadata list, expiryMs {} now {}", entry.getKey(), expireMs, now);
}
}
}
//集群信息更新后的监听器触发回调
for (Listener listener: listeners)
listener.onMetadataUpdate(newCluster, unavailableTopics);
String previousClusterId = cluster.clusterResource().clusterId();
//设置新的集群信息
if (this.needMetadataForAllTopics) {
this.needUpdate = false;
this.cluster = getClusterForCurrentTopics(newCluster);
} else {
this.cluster = newCluster;
}
// 省略部分集群资源监听信息
} 1.2.4、缓存消息收集器(RecordAccumulator )
RecordAccumulator 在消息发送中的一个重要作用可以认为是个蓄水池,我们先看一张消息缓存收集的架构图

所有消息的收集过程从这个图可以很明显的看出,每条消息先从MetaData里面获取分区信息,再申请一段buffer空间形成一个批接收空间,RecordAccumulator 会将收到的每条消息append到这个buffer中,最后将每个批次压入到队列当中,等待Sender线程来获取发送。
我们回到源码层面来分析,kafkaProducer在doSend的最后阶段会调用如下代码:
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
我们先来分析一下accumulator.append这个方法:
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// 记录下所有正在向收集器添加信息的线程,以便后续处理未完成的批次信息的时候不至于会遗漏
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
//获取当前topic分区所对应的dqueue,如果不存在则创建一个
Deque dq = getOrCreateDeque(tp);
synchronized (dq) {
// producer 已经关闭,抛出异常
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//首先尝试直接向dqueue里面的最后一个batch添加消息,并返回对应的添加结果信息
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
// 没有可使用的batch,则新申请一块buffer
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
//从bufferPool里面申请一块buffer
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 再次检查producer是否关闭,关闭了抛异常
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//再次尝试向dqueue里面追加消息
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
//追加仍然失败,那么就创建一个新的ProducerBatch进行追加
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
//对新创建的ProducerBatch进行消息追加
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
//新创建的batch添加到dqueue
dq.addLast(batch);
incomplete.add(batch);
// 这个很重要,避免释放正在使用的内存空间,这里只是将对象指针指为null,实际上之前的内存空间已经被ProducerBatch接管
buffer = null;
//返回RecordAppendResult对象
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
//释放不必要的内存,例如第二次向dqueue里面追加消息成功后,正式return之前就会先执行这段程序来释放空间
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
} 在这个过程中我们看到消息的append是这样的,两次向dqueue的最后一个batch来append,即tryAppend方法以及一次向新申请的batch追加消息的tryAppend方法,我们逐个分析:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque deque) {
//获取dqueue里面的最后一个batch
ProducerBatch last = deque.peekLast();
if (last != null) {
//如果batch不为空,则向它里面append消息,即调用batch.tryAppend
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
if (future == null)
last.closeForRecordAppends();
else
//返回消息追加结果
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
return null;
} 实际上上面的代码只是从dqueue获取最后一个ProducerBatch并调用它的tryAppend方法来追加消息,所以最终都会走到ProducerBatch的tryAppend
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
//判断是否还有可用空间
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
//调用recordsBuilder来追加消息,实际上V1版本以前的是调用了LegacyRecord来写入,后续新版本都是采用DefaultRecord的writeTo来写入,它们都是通过DataOutputStream写入,写入消息后返回其校验码
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers));
this.lastAppendTime = now;
//这个就是返回的可阻塞同步等待返回响应的对象
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
// 这里会记录下每个消息返回的future,以防batch会被拆分来发送
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}1.3、优化思考
上期讲解了reactor的模式架构分析,可以点击《kafka如何做到百万级高并发低迟延的》了解详情,并在最后提出了一个发散的问题,reactor机制里面可以优化的地方,现在我将自己在这一点上的思考:
requestChannel里面所带的队列requestQueue是全局共享,并且是加锁处理,是否会影响网络IO的处理性能呢?如果换为无锁处理是否可行?答案是可以的,但是最终的优化效果大家可以下载源码来具体修改编译试一下看,我们先给出一个结果,整体有一定的提升,但是不明显,原因是由于消息是批量发送,不是逐个发送,大大减少了网络请求的频次,所以这个的瓶颈就会显得比较弱。
