Java实现简易的词法分析器
此次也是课题需要,才写了这么一个项目,编译原理课你懂的.
由于个人比较喜欢Java,因此写了一个Java版本简易的词法分析器.(也是因为Java对数组的使用比较随意)
注意:没有出错处理,如 9int,或是 int 23等等一系列错误是检测不出来的.
但是可以检测小数和注释的错误.
错误种类太多太麻烦,就没有处理了.
实验要求如下:
实验一 词法分析程序设计
【实验要求】
对一个简单的语言的子集编制一个一遍扫描的词法分析程序。
【实验内容】
1、待分析的简单语言词法
(1)关键字
可以自由添加。如C语言的关键字:main if else int char return void while等。
(2)标识符(ID)
ID→letter(letter|digit)* Letter→a|…|z|A|…|Z digit→0|…|9
(3)常数(可以先以整形常数为例)
NUM→digit(digit)* digit→0|…|9
(4)运算符
如C语言中的运算符= + - * / < <= > >= == !=等。
(5)界符
如C语言中的; : , { } [ ] ( )等。空格由空白、制表符和换行符组成。空格一般用来分隔关键字、ID、NUM、运算符和界符。词法分析阶段空格通常被忽略。
2、各种单词类别及对应的种别编码
关键字设置为0~99,如“main”设置为0,“if”设置为1,……;
标识符设置为100;
常数设置为101~109,如整形常数设置为101,小数常数设置为102,……;
运算符设置为110~149,如“=”设置为111,“+”设置为112,……;
界符设置为150~159,如“;”设置为150,“,”设置为151,……。
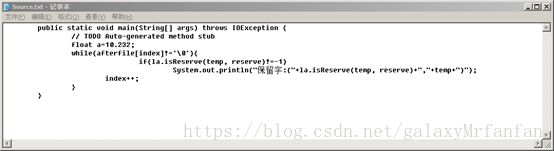
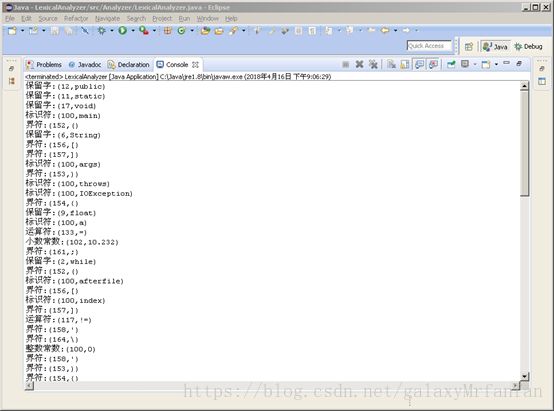
例如:对源程序int x =9; if (x>0) x=2*x+1/3; 经词法分析后输出如下序列:(3,int) (1,‘x’) (4,=) (2,9) ……
输入截图:
运行结果截图:
源代码:
package Analyzer;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
import java.io.*;
public class LexicalAnalyzer {
//将txt文件转为数组
public String txt2String(File file) throws IOException
{
StringBuilder result =new StringBuilder();
try {
BufferedReader br= new BufferedReader(new FileReader(file));
String s=null;
while((s=br.readLine())!=null){
result.append(System.lineSeparator()+s);
}
br.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return result.toString();
}
//对文本进行预处理
public char[] preTreatment(char[] sourcefile)
{
char []afterfile = new char[10000];
int index=0;
if(sourcefile.length!=0)
{
for(int i=0;i='a'&&c<='z')||(c>='A'&&c<'Z'))
{
return true;
}
else
return false;
}
//判断是否为保留字,并返回编号
public int isReserve(String s,String []reserve)
{
int index=-1;
for(int i=0;i='0'&&c<='9')
{
return true;
}
else
return false;
}
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
//保留字
String []reserve={"if","else","while","throw","this","int","String","char","double","float","this",
"static","public","private","default","switch","catch","void","try","return"};//0~99
//运算符
String []operator={"+","-","*","/","++","--","==","!=",">","<",">=",
"<=","&&","||","!","&","|","^","~","<<",">>",">>>","+=","="};//110~149
//界符
char []divide={'<','>','(',')','{','}','[',']','\'','"',',',';','?','/','\\',':','.'};//150~无穷
LexicalAnalyzer la=new LexicalAnalyzer();
//源代码的txt文件
File file=new File("D://Source.txt");
//将txt格式的源文件放入sourcefile的字符数组中
String source=la.txt2String(file);
char sourcefile[] = source.toCharArray();
//将源代码进行预处理,去掉注释和换行符
char afterfile[]=la.preTreatment(sourcefile);
//index记录源代码的字符数组扫描到的数组下标
int index=0;
//temp用于存储临时的字符串
String temp="";
//当未扫描到终结符则一直往下扫描
while(afterfile[index]!='\0'){
//当开头为字母时,可能为保留字或是标识符
if(la.isLetter(afterfile[index]))
{
temp+=afterfile[index];
//当下一个字符不为字母或数字,则停止扫描,并将扫描结果存入temp
while(la.isLetter(afterfile[index+1])||la.isDigit(afterfile[index+1]))
{
index++;
temp+=afterfile[index];
}
//将temp与保留字数组匹配,匹配成功即为保留字,否则为标识符
if(la.isReserve(temp, reserve)!=-1)
System.out.println("保留字:("+la.isReserve(temp, reserve)+","+temp+")");
else
System.out.println("标识符:("+100+","+temp+")");
}
//当开头为数字时,可能为整数或小数
else if(la.isDigit(afterfile[index]))
{
temp+=afterfile[index];
while(la.isDigit(afterfile[index+1]))
{
index++;
temp+=afterfile[index];
}
//若在数字后有小数点,继续判断
if(afterfile[index+1]=='.')
{
index++;
//小数点后无数字,检测出错
if(!la.isDigit(afterfile[index+1])){
System.out.println("此处有误,小数点后无数字");
temp="";
break;
}
//小数点后有数字,检测为小数
else
{
temp+=afterfile[index];
while(la.isDigit(afterfile[index+1]))
{
index++;
temp+=afterfile[index];
}
}
System.out.println("小数常数:("+102+","+temp+")");
}
//无小数点,检测为整数
else
{
System.out.println("整数常数:("+100+","+temp+")");
}
}
//既不是数字也不是字母也不是空格,则为界符或运算符,跳过空格
else if(afterfile[index]!=' ')
{
temp+=afterfile[index];
/*由于界符只有一个字符长度,则temp放入一个字符后直接开始匹配界符数组,
* 匹配成功则continue循环,匹配失败则继续扫描
*/
if(la.isDivide(temp, divide)!=-1)
{
System.out.println("界符:("+la.isDivide(temp, divide)+","+temp+")");
temp="";
index++;
continue;
}
//判断是否为运算符
else
{
//若下一个字符也是符号类型则加入temp
while((la.isDivide(afterfile[index+1]+"", divide)==-1)&&(la.isDigit(afterfile[index+1])==false)
&&(la.isLetter(afterfile[index+1])==false))
{
index++;
temp+=afterfile[index];
}
//与运算符数组匹配,匹配成功,则为运算符,失败,则可能出现了检测不了的字符。
if(la.isOperator(temp, operator)!=-1)
System.out.println("运算符:("+la.isOperator(temp, operator)+","+temp+")");
else
System.out.println("无法识别,可能为中文字符");
}
}
temp="";
index++;
}
}
}