spark处理mongodb数据(python版)
mongodb是一种文档型数据库,作为一个适用于敏捷开发的数据库,mongodb的数据模式可以随着应用程序的发展而灵活地更新。但是mongodb适合一次查询的需求,对于统计、分析(尤其是在需要跨表、跨库的情况下)并不是太方便,我们可以用spark来处理mongodb数据。架构图如下:
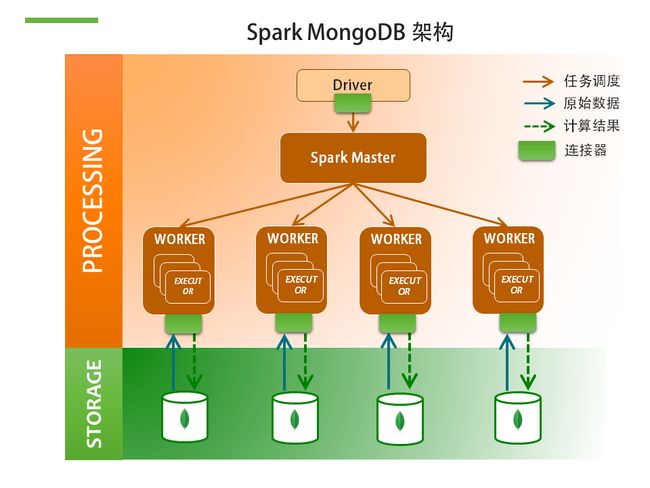
我使用的spark版本是spark-1.6.2,mongodb版本是3.2。我主要接触了以下两种连接器:
1、mongodb官方连接器
github地址:https://github.com/mongodb/mongo-spark
mongodb官方文档:https://docs.mongodb.com/spark-connector/
api文档(java版):https://www.javadoc.io/doc/org.mongodb.spark/mongo-spark-connector_2.11/2.0.0
加载mongodb数据的方式如下:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
sc = SparkContext()
ctx = SQLContext(sc)
test_collection = ctx.read.format("com.mongodb.spark.sql").options(uri="mongodb://192.168.0.1:27017", database="test_db", collection="test_collection").load()test_collection.printSchema()
test_collection.first()上面的这种方式加载时间较长,因为spark需要判断各个字段的类型,需要抽取部分数据判断(或者扫描整个表,我没有具体的研究过,总之比较慢)。而且这种方式会将所有的数据加载进来,有些字段我并不需要获取到。可以用下面的代码改进:
fields_list = "name age sex grade exp"
fields = [StructField(field_name, StringType(), True) for field_name in fields_list.split()]
schema = StructType(fields)
test_collection = job_ctx.read.schema(schema).format("com.mongodb.spark.sql").options(uri="mongodb://192.168.0.1:27017", database="test_db", collection="test_collection").load()test_collection变量是spark中的dataframe类型数据,就可以使用spark sql处理数据:
test_collection.registerTempTable("Account")
sql = "select * from Account where age > '18'"
result = ctx.sql(sql)
如果有的需求不能通过spark sql实现,也可以使用下面代码转化成rdd格式数据,然后用map、reduce等函数处理。
test_rdd = test_collection.rdd在数据通过sql或者自己写map、reduce函数处理完之后需要将数据保存到mongodb中。如果数据是dataframe格式:
result.write.format("com.mongodb.spark.sql").mode("overwrite").options(uri="mongodb://192.168.0.1:27017", database="test_db", collection="test_collection_out").load()其中的mode中填写写数据的模式,官方的连接器提供了四种模式:overwrite ignore errorifexists append,本来以为这些模式是针对行级别的,后来看了源代码发现是针对collection级别的,官方代码如下:
override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String], data: DataFrame): BaseRelation = {
val writeConfig = WriteConfig(sqlContext.sparkContext.getConf, parameters)
val mongoConnector = MongoConnector(writeConfig.asOptions)
lazy val collectionExists: Boolean = mongoConnector.withDatabaseDo(
writeConfig, { db => db.listCollectionNames().asScala.toList.contains(writeConfig.collectionName) }
)
mode match {
case Append => MongoSpark.save(data, writeConfig)
case Overwrite =>
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[Document] => collection.drop() })
MongoSpark.save(data, writeConfig)
case ErrorIfExists =>
if (collectionExists) {
throw new UnsupportedOperationException("MongoCollection already exists")
} else {
MongoSpark.save(data, writeConfig)
}
case Ignore =>
if (!collectionExists) {
MongoSpark.save(data, writeConfig)
}
}
createRelation(sqlContext, parameters ++ writeConfig.asOptions, Some(data.schema))
}代码链接:https://github.com/mongodb/mongo-spark/blob/7c76ed1821f70ef2259f8822d812b9c53b6f2b98/src/main/scala/com/mongodb/spark/sql/DefaultSource.scala
从代码中可以看出,overwrite就是先删除mongodb中指定的表,然后把数据写到这个表中;ignore就是如果mongodb中有这个表,就不写数据了,且不会报错;errorifexists就是如果mongodb中存在这个表就报错,如果不存在就正常写入;append就是不管mongodb中这个表存不存在直接往里写数据。分这么多模式其实没啥大用,如果不看代码容易理解出现偏差。
如果是rdd类型的数据就需要先转化成dataframe格式再保存到mongodb中,例如:
fields_list = "name age sex grade exp"
fields = [StructField(field_name, StringType(), True) for field_name in fields_list]
schema = StructType(fields)
df = ctx.createDataFrame(result, schema=schema)
df.write.format("com.mongodb.spark.sql").mode("overwrite").options(uri="mongodb://192.168.0.1:27017", database="test_db", collection="test_collection_out").load()2、第三方连接器
github地址:https://github.com/Stratio/Spark-MongoDB
这个连接器的使用方式基本上和官方连接器一样,获取数据的代码如下:
test_collection = ctx.read.schema(schema).format("com.stratio.datasource.mongodb").options(host="192.168.0.1:27017", database="test", collection="test_collection").load()写数据到mongodb的方法和官方连接器也差不多:
result.write.format("com.stratio.datasource.mongodb").mode("append").options(host="192.168.0.1:27017", database="test", collection="test_collection_out", updateFields='name').save()mode match{
case Append => mongodbRelation.insert(data, overwrite = false)
case Overwrite => mongodbRelation.insert(data, overwrite = true)
case ErrorIfExists => if(mongodbRelation.isEmptyCollection) mongodbRelation.insert(data, overwrite = false)
else throw new UnsupportedOperationException("Writing in a non-empty collection.")
case Ignore => if(mongodbRelation.isEmptyCollection) mongodbRelation.insert(data, overwrite = false)
}def insert(data: DataFrame, overwrite: Boolean): Unit = {
if (overwrite) {
usingMongoClient(MongodbClientFactory.getClient(config.hosts, config.credentials, config.sslOptions, config.clientOptions).clientConnection) { mongoClient =>
dbCollection(mongoClient).dropCollection()
}
}
data.saveToMongodb(config)
}def saveToMongodb(config: Config, batch: Boolean = true): Unit = {
val schema = dataFrame.schema
dataFrame.foreachPartition(it => {
val writer =
if (batch) new MongodbBatchWriter(config)
else new MongodbSimpleWriter(config)
writer.saveWithPk(
it.map(row => MongodbRowConverter.rowAsDBObject(row, schema)))
})
}private[mongodb] class MongodbBatchWriter(config: Config) extends MongodbWriter(config) {
private val IdKey = "_id"
private val bulkBatchSize = config.getOrElse[Int](MongodbConfig.BulkBatchSize, MongodbConfig.DefaultBulkBatchSize)
private val pkConfig: Option[Array[String]] = config.get[Array[String]](MongodbConfig.UpdateFields)
override def save(it: Iterator[DBObject], mongoClient: MongoClient): Unit = {
it.grouped(bulkBatchSize).foreach { group =>
val bulkOperation = dbCollection(mongoClient).initializeUnorderedBulkOperation
group.foreach { element =>
val query = getUpdateQuery(element)
if (query.isEmpty) bulkOperation.insert(element)
else bulkOperation.find(query).upsert().replaceOne(element)
}
bulkOperation.execute(writeConcern)
}
}可以看出,这四种模式的功能总体上是和官方连接器一致的,但是在写入mongodb时处理方式不同。在这里可以使用一个updateFields参数,这个参数表示以这个参数的值为key,如果查询到mongodb的表中已经有相同key的数据,会替换掉这行数据,如果没有则直接写入。在很多业务场景下,只需要在原表的基础上更新一部分数据,用这个第三方连接器就非常方便。
3、连接器的选择
在获取数据时,官方连接器的性能似乎比第三方连接器的好一点,官方连接器有一个条件下推的原则。我们知道spark的算子分为两种:Transformation和Action,只有遇到Action算子才会触发作业的提交。比如在后续的一些Transformation算子中对数据有一定的数据过滤条件,官方连接器会把过滤条件下推到MongoDB去执行,这样可以保证从MongoDB取出来、经过网络传输到Spark计算节点的数据确实都是用得着的。第三方连接器似乎会把所有数据加载到spark后再过滤(没有仔细求证)。
在写数据到mongodb时,通过上面贴出来的代码可以看出,第三方连接器的功能比官方连接器的要好一点,支持在原有表的基础上做更新。
4、连接器的使用
首先要安装spark(如果不需要把数据保存到hdfs、不需要使用yarn,可以不安装hadoop),在spark目录下的bin目录下会有一个spark-submit可执行文件。
例如把代码保存在test.py中,如果使用官方连接器,运行:
spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.10:1.1.0 test.py如果使用的是第三方连接器,运行:
spark-submit --packages com.stratio.datasource:spark-mongodb_2.10:0.11.2 test.py官方:http://download.csdn.net/detail/hellousb2010/9698375
第三方:http://download.csdn.net/detail/hellousb2010/9698372
解压后将cache、jar目录拷贝到~/.ivy2目录下即可。
参考文档:http://www.mongoing.com/tj/mongodb_shanghai_spark
文章中出现错误欢迎指正。