动手学深度学习PyTorch版-注意力机制与Seq2seq模型
注意力机制与Seq2seq模型
import math
import torch
import torch.nn as nn
import os
def file_name_walk(file_dir):
for root, dirs, files in os.walk(file_dir):
# print("root", root) # 当前目录路径
print("dirs", dirs) # 当前路径下所有子目录
print("files", files) # 当前路径下所有非目录子文件
file_name_walk("/home/kesci/input/fraeng6506")
softmax屏蔽
def SequenceMask(X, X_len,value=-1e6):
maxlen = X.size(1)
#print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] )
mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None]
#print(mask)
X[mask]=value
return X
def masked_softmax(X, valid_length):
# X: 3-D tensor, valid_length: 1-D or 2-D tensor
softmax = nn.Softmax(dim=-1)
if valid_length is None:
return softmax(X)
else:
shape = X.shape
if valid_length.dim() == 1:
try:
valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3]
except:
valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3]
else:
valid_length = valid_length.reshape((-1,))
# fill masked elements with a large negative, whose exp is 0
X = SequenceMask(X.reshape((-1, shape[-1])), valid_length)
return softmax(X).reshape(shape)
masked_softmax(torch.rand((2,2,4),dtype=torch.float), torch.FloatTensor([2,3]))
tensor([[[0.5423, 0.4577, 0.0000, 0.0000],
[0.5290, 0.4710, 0.0000, 0.0000]],
[[0.2969, 0.2966, 0.4065, 0.0000],
[0.3607, 0.2203, 0.4190, 0.0000]]])
超出二维矩阵乘法
torch.bmm(torch.ones((2,1,3), dtype = torch.float), torch.ones((2,3,2), dtype = torch.float))
点积注意力
# Save to the d2l package.
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key
scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
print("attention_weight\n",attention_weights)
return torch.bmm(attention_weights, value)
测试
atten = DotProductAttention(dropout=0)
keys = torch.ones((2,10,2),dtype=torch.float)
values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1)
atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))
多层感知机注意力
# Save to the d2l package.
class MLPAttention(nn.Module):
def __init__(self, units,ipt_dim,dropout, **kwargs):
super(MLPAttention, self).__init__(**kwargs)
# Use flatten=True to keep query's and key's 3-D shapes.
self.W_k = nn.Linear(ipt_dim, units, bias=False)
self.W_q = nn.Linear(ipt_dim, units, bias=False)
self.v = nn.Linear(units, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, valid_length):
query, key = self.W_k(query), self.W_q(key)
#print("size",query.size(),key.size())
# expand query to (batch_size, #querys, 1, units), and key to
# (batch_size, 1, #kv_pairs, units). Then plus them with broadcast.
features = query.unsqueeze(2) + key.unsqueeze(1)
#print("features:",features.size()) #--------------开启
scores = self.v(features).squeeze(-1)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
测试
atten = MLPAttention(ipt_dim=2,units = 8, dropout=0)
atten(torch.ones((2,1,2), dtype = torch.float), keys, values, torch.FloatTensor([2, 6]))
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=
引入注意力机制的Sequence to Sequence
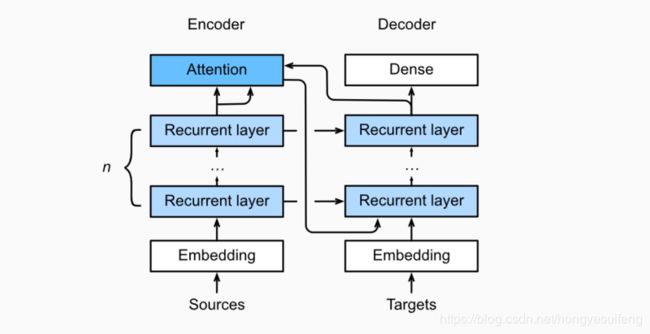
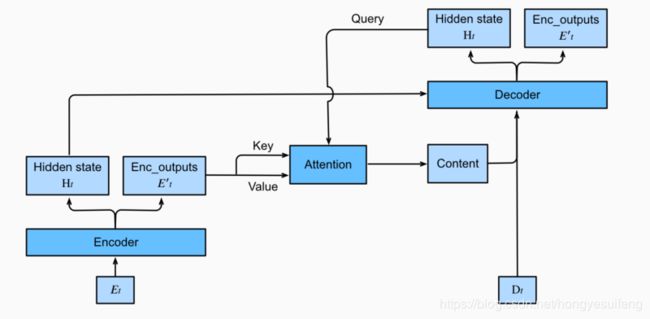
import sys
sys.path.append('/home/kesci/input/d2len9900')
import d2l
解码器
class Seq2SeqAttentionDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention_cell = MLPAttention(num_hiddens,num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size+ num_hiddens,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, enc_valid_len, *args):
outputs, hidden_state = enc_outputs
# print("first:",outputs.size(),hidden_state[0].size(),hidden_state[1].size())
# Transpose outputs to (batch_size, seq_len, hidden_size)
return (outputs.permute(1,0,-1), hidden_state, enc_valid_len)
#outputs.swapaxes(0, 1)
def forward(self, X, state):
enc_outputs, hidden_state, enc_valid_len = state
#("X.size",X.size())
X = self.embedding(X).transpose(0,1)
# print("Xembeding.size2",X.size())
outputs = []
for l, x in enumerate(X):
# print(f"\n{l}-th token")
# print("x.first.size()",x.size())
# query shape: (batch_size, 1, hidden_size)
# select hidden state of the last rnn layer as query
query = hidden_state[0][-1].unsqueeze(1) # np.expand_dims(hidden_state[0][-1], axis=1)
# context has same shape as query
# print("query enc_outputs, enc_outputs:\n",query.size(), enc_outputs.size(), enc_outputs.size())
context = self.attention_cell(query, enc_outputs, enc_outputs, enc_valid_len)
# Concatenate on the feature dimension
# print("context.size:",context.size())
x = torch.cat((context, x.unsqueeze(1)), dim=-1)
# Reshape x to (1, batch_size, embed_size+hidden_size)
# print("rnn",x.size(), len(hidden_state))
out, hidden_state = self.rnn(x.transpose(0,1), hidden_state)
outputs.append(out)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.transpose(0, 1), [enc_outputs, hidden_state,
enc_valid_len]
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8,
num_hiddens=16, num_layers=2)
# encoder.initialize()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8,
num_hiddens=16, num_layers=2)
X = torch.zeros((4, 7),dtype=torch.long)
print("batch size=4\nseq_length=7\nhidden dim=16\nnum_layers=2\n")
print('encoder output size:', encoder(X)[0].size())
print('encoder hidden size:', encoder(X)[1][0].size())
print('encoder memory size:', encoder(X)[1][1].size())
state = decoder.init_state(encoder(X), None)
out, state = decoder(X, state)
out.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
batch size=4
seq_length=7
hidden dim=16
num_layers=2
encoder output size: torch.Size([7, 4, 16])
encoder hidden size: torch.Size([2, 4, 16])
encoder memory size: torch.Size([2, 4, 16])
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([2, 4, 16]))
训练
import zipfile
import torch
import requests
from io import BytesIO
from torch.utils import data
import sys
import collections
class Vocab(object): # This class is saved in d2l.
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
# sort by frequency and token
counter = collections.Counter(tokens)
token_freqs = sorted(counter.items(), key=lambda x: x[0])
token_freqs.sort(key=lambda x: x[1], reverse=True)
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
tokens = ['', '', '', '']
else:
self.unk = 0
tokens = ['']
tokens += [token for token, freq in token_freqs if freq >= min_freq]
self.idx_to_token = []
self.token_to_idx = dict()
for token in tokens:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
else:
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
else:
return [self.idx_to_token[index] for index in indices]
def load_data_nmt(batch_size, max_len, num_examples=1000):
"""Download an NMT dataset, return its vocabulary and data iterator."""
# Download and preprocess
def preprocess_raw(text):
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
out = ''
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and text[i-1] != ' ':
out += ' '
out += char
return out
with open('/home/kesci/input/fraeng6506/fra.txt', 'r') as f:
raw_text = f.read()
text = preprocess_raw(raw_text)
# Tokenize
source, target = [], []
for i, line in enumerate(text.split('\n')):
if i >= num_examples:
break
parts = line.split('\t')
if len(parts) >= 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
# Build vocab
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return Vocab(tokens, min_freq=3, use_special_tokens=True)
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
# Convert to index arrays
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
def build_array(lines, vocab, max_len, is_source):
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines])
valid_len = (array != vocab.pad).sum(1)
return array, valid_len
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
src_array, src_valid_len = build_array(source, src_vocab, max_len, True)
tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False)
train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len)
train_iter = data.DataLoader(train_data, batch_size, shuffle=True)
return src_vocab, tgt_vocab, train_iter
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.0
batch_size, num_steps = 64, 10
lr, num_epochs, ctx = 0.005, 500, d2l.try_gpu()
src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.EncoderDecoder(encoder, decoder)
训练和预测
d2l.train_s2s_ch9(model, train_iter, lr, num_epochs, ctx)
for sentence in ['Go .', 'Good Night !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + d2l.predict_s2s_ch9(
model, sentence, src_vocab, tgt_vocab, num_steps, ctx))