Django学习笔记一---入门篇
前言
Python的WEB框架有Django、Tornado、Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM、模型绑定、模板引擎、缓存、Session等诸多功能。
正文
环境
系统 : ubuntu 17.10
python : 3.6
Django2.0
Python的虚拟环境virtualenv
为了考虑依赖性问题,将使用virtualenv来搭建对应的环境
安装:
pip install virtualenv
创建虚拟环境
cd project_name_dir
virtualenv venv #venv为虚拟环境的目录名,可以自定义
创建虚拟环境可以指定Python解释器
virtualenv -p python3
or
virtualenv -p /usr/bin/python3.6 env

要开始使用虚拟环境,需要激活
source env/bin/activate
需要退回系统默认环境或者暂停当前的虚拟环境可以使用以下的命令
deactivate
删除虚拟环境,只需要删除上面新建的目录即可。
安装Django
默认安装的是最后发布的版本
pip install Django
如果需要
指定安装的版本需要下面的命令,比如指定安装版本为2.0的Django。
pip install Django==2.0
![]()
第一个项目Helloworld
创建项目的命令:
django-admin startproject mysite1
然后会在当前目录中新建一个目录,目录结构为:
mysite1
├── manage.py
└── mysite1
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
其中的settings.py为整个Django项目的配置文件,urls.py整个项目的路由控制文件,wsgi.py项目部署使用到的文件。
项目运行流程:

具体步骤:
- 在mysite1/mysite2新建一个名为
views.py的文件,内容为
from django.http import HttpResponse
def index(request):
return HttpResponse("Hello world")
- 修改
urls.py文件,添加一项路由
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path("", views.index)
]
其中的""代表根目录,如果需要指定路径为test,可以把""修改为test/
3. 回到项目的根目录,运行项目
python3 manage.py runserver
默认是8000端口如果需要指定端口可以使用下面的命令
python3 manage.py runserver 8888
如果需要外网访问当前的项目,可以使用下面的命令
python3 manage.py runserver 0.0.0.0:8888
- 运行结果

正常的运行流程:
进来的请求转入’/’.
Django通过在ROOT_URLCONF配置来决定根URLconf.
Django在URLconf中的所有URL模式中,查找第一个匹配’/'的条目。
如果找到匹配,将调用相应的视图函数
视图函数返回一个HttpResponse
Django转换HttpResponse为一个适合的HTTP response, 以Web page显示出来
Django 自带的后台
在urls.py文件中,发现一条url匹配规则path('admin/', admin.site.urls),这条路由规则匹配的是admin后台,访问127.0.0.1/admin出现界面
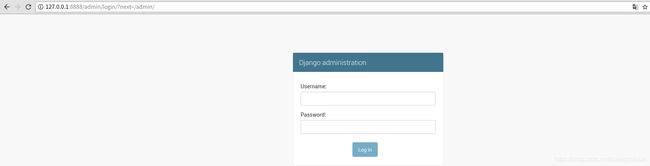
然后我们需要创建一个管理员账号,步骤如下:
- 迁移数据库–migrate
使用命令python3 manage.py help可以查看基本的命令
Type 'manage.py help ' for help on a specific subcommand.
Available subcommands:
[auth]
changepassword
createsuperuser
[contenttypes]
remove_stale_contenttypes
[django]
check
compilemessages
createcachetable
dbshell
diffsettings
dumpdata
flush
inspectdb
loaddata
makemessages
makemigrations
migrate
sendtestemail
shell
showmigrations
sqlflush
sqlmigrate
sqlsequencereset
squashmigrations
startapp
startproject
test
testserver
[sessions]
clearsessions
[staticfiles]
collectstatic
findstatic
runserver
如果没有迁移数据库直接使用命令python3 manage.py createsuperuser创建管理员用户会爆出这样的错误
django.db.utils.OperationalError: no such table: auth_user
所以需要先迁移数据库,使用以下的命令迁移数据库,Django默认使用的数据库是sqlite3,可以在settings中更换。
python3 manage.py migrate
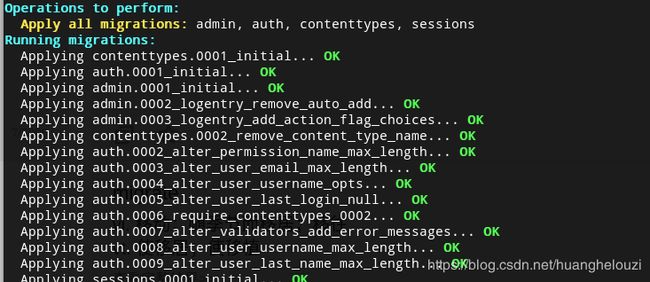
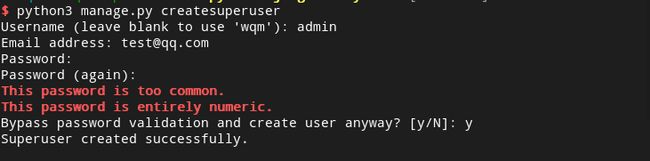
- 创建管理员账号–createsuperuser
python3 manage.py createsuperuser
然后输入对应的管理员用户名和邮箱以及密码,ok。因为我设置的密码是123456789,所以出现密码过弱的提示。
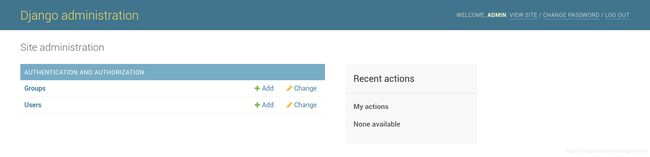
- 登录后台
使用刚刚创建的用户登录,默认的语言是英文,需要修改为中文的话在settings.py中的LANGUAGE_CODE = 'en-us'修改LANGUAGE_CODE = 'zh-hans'
需要修改的:

中文后台

小结:
启动服务使用命令runserver,迁移(同步)数据库使用命令migrate,创建管理管理员账号使用命令createsuperuser,查看帮助使用命令help。
Django 基本应用结构
创建一个新的应用(app) : python3 startapp app_name
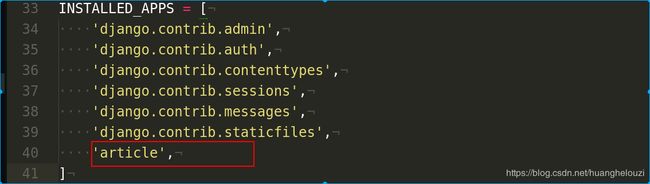
首先创建一个Django应用,名为article,创建应用之后还需要在settings.py中声明应用
python3 manage.py startapp article
声明应用,在settings中对应的列表(INSTALLED_APPS)中添加应用名
此时的目录结构变成了
├── article
│ ├── admin.py
│ ├── apps.py
│ ├── __init__.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── db.sqlite3
├── manage.py
└── mysite1
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ ├── settings.cpython-36.pyc
│ ├── urls.cpython-36.pyc
│ ├── views.cpython-36.pyc
│ └── wsgi.cpython-36.pyc
├── settings.py
├── urls.py
├── views.py
└── wsgi.py
- 其中新建应用中的article/models.py的作用类似于持久层,可在这里面声明模型类,现在修改
models.py文件为:
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(max_length=30)
content = models.TextField()
接着使用命令makemigrations制造迁移,使用命令migrate完成迁移。
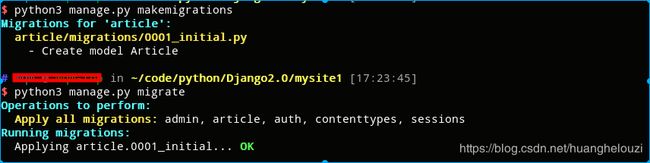
进入打开数据库,发现如果没有指定主键,Django会自动生成pkey
![]()
- article/admin.py 可以在这里面声明模型类,使其可在admin界面操作
在admin.py中引入上面创建的模型类Article.py,并注册

from django.contrib import admin
from .models import Article
# Register your models here.
admin.site.register(Article)
回到后台,刷新之后出现Article选项,
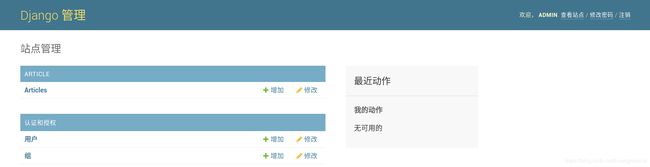
并且可以完成增删改查等等操作
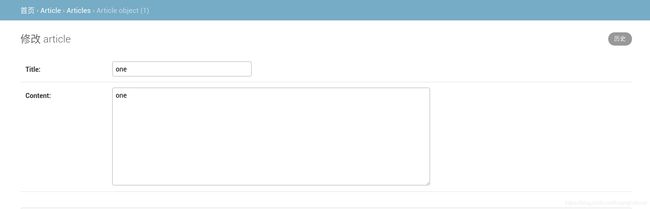
小结:
新建一个应用使用命令python3 manage.py startapp app_name,使用命令python3 manage.py makemigrations完成数据迁移的制造,之后再使用命令python3 manage.py migrate完成数据迁移,迁移的数据生成文件在应用目录下的migrations目录下。在应用中的models.py声明模型类,在admin.py文件中修改后台。
Django使用模板文件
- 首先学习在url中传递参数,比如传递文章的id
在article中的views.py文件中添加下面的内容
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def article_detail(request, article_id):
return HttpResponse("文章id为:%s"%article_id
在引入对应的方法然后添加路由

其中的

- 通过模型获取数据库内容
首先在admin后台向article中添加多条数据

把article/views.py修改为
from django.shortcuts import render
from django.http import HttpResponse
from .models import Article
# Create your views here.
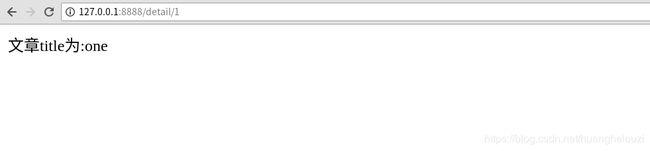
def article_detail(request, article_id):
article = Article.objects.get(id=article_id)
return HttpResponse("文章title为:%s"%article.title)
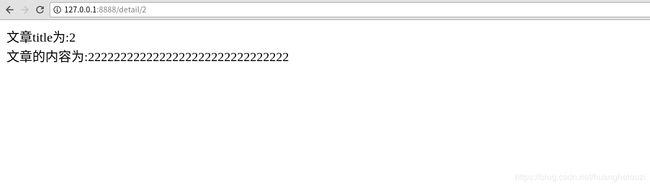
当然也可以同时显示文章标题和文章内容,article/views.py内容
from django.shortcuts import render
from django.http import HttpResponse
from .models import Article
# Create your views here.
def article_detail(request, article_id):
article = Article.objects.get(id=article_id)
return HttpResponse("文章title为:%s
文章的内容为:%s"%(article.title, article.content))
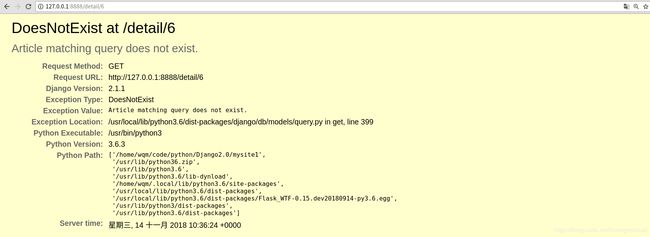
当访问的id超出数据库中id范围会返回一个DoesNotExist异常
为了程序的健壮性需要在article/views.py处理异常,一般情况下返回404
from django.shortcuts import render
from django.http import HttpResponse
from .models import Article
# Create your views here.
def article_detail(request, article_id):
try:
article = Article.objects.get(id=article_id)
except Article.DoesNotExist as e:
return HttpResponse("404")
return HttpResponse("文章title为:%s
文章的内容为:%s"%(article.title, article.content))

Django中提供了get_object_or_404方法,如果对象不为空返回对象,对象不存在返回404异常。
from django.shortcuts import get_object_or_404
...
blog = get_object_or_404(Blog,pk=blog_pk)
- 使用模板文件
上面的写法脚本和静态html完全的混淆到一起,耦合度高,Django提供一种使用模板的方法
from django.shortcuts import render
from django.http import HttpResponse
from .models import Article
# Create your views here.
def article_detail(request, article_id):
try:
article = Article.objects.get(id=article_id)
context = {}
context["article_obj"] = article
return render(request, "article_detail.html", context)
except Exception as e:
raise
并且在article应用的根目录中新建一个目录template,这个目录中存放html模板文件。例如新建一个模板文件为article_detail.html,内容为:
<html>
<head>
<title>article_detailtitle>
head>
<body>
<h3>{{article_obj.title}}h3>
<p>{{article_obj.content}}p>
body>
html>
其中的render(request, "article_detail.html", context)方法一共有三个参数,第一个为request:存放与请求相关的信息,第二个"article_detail.html"为使用的模板文件名称,第三个context则是存放模板所需要的参数字典对象。与render方法相类似的方法还有render_to_response("article_detail.html", context)主要参数只有两个模板文件名和参数字典,request对象会自动传过去。
而在模板文件中使用到脚本传过来的参数的使用方法是{{参数字典对象.参数的key}}。
而在django.shortcuts模块中还有一个非常常用的方法get_object_or_404,如果存在对象返回对象,否则返回404.可以精简代码。
精简后的article/views代码
from django.shortcuts import render, render_to_response, get_object_or_404
from django.http import HttpResponse
from .models import Article
# Create your views here.
def article_detail(request, article_id):
article = get_object_or_404(Article, id=article_id)
context = {}
context["article_obj"] = article
#return render(request, "article_detail.html", context)
return render_to_response("article_detail.html", context)
- locals()函数的妙用
locals()函数的返回值:返回字典类型的局部变量。
In [1]: def test_locals(var):
...: a = 1
...: print(locals())
...:
In [2]: test_locals(2)
{'a': 1, 'var': 2}
locals()函数的特性可以在views视图中使用
比如存在这样的一个视图方法
def current_datetime(request):
now = datetime.datetime.now()
return render_to_response('current_datetime.html', {'current_date': now})
我们可以利用locals函数进行偷懒,但是这个偷懒的方法是有代价的,在下面例子中locals()还包含request
def current_datetime(request):
current_date = datetime.datetime.now()
return render_to_response('current_datetime.html', locals())
```requestrequest
- 模板文件的for循环,类似的还用if
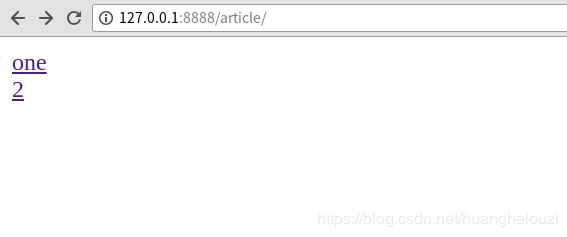
现在写一个文章列表界面,首先需要在article/views.py中添加一个方法`article_list(request)`
```python
def article_list(request):
articles = Article.objects.all()
context = {}
context["articles"] = articles
return render(request, "artilce_list.html", context)
然后修改路由配置,添加一项配置
path("article/", article_list),
然后在article/templates中新增加一个模板article_list.html
<html>
<head>
<title>article_list pagetitle>
head>
<body>
{%for article in articles%}
<a href="/article/{{article.id}}">{{article.title}}a><br>
{%endfor%}
body>
html>
其中{{article.id}}可以修改为{{article.pk}},pk即是主键的缩写,建议使用{{article.pk}}
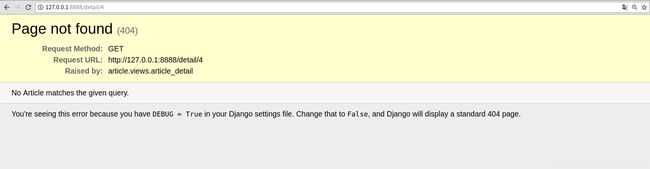
- 分路由文件–urls.py
如果整个项目的urls都配置在同一个配置文件的话,将很难维护,Django提供了一种分路的方法,可以在每一个应用中新建一个urls.py文件,在这个文件中配置好路由信息之后,再在主的路由配置文件中通过include包含子路由配置文件的内容。即是在urls.py文件中注释代码的第三种配置方法
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
详细步骤:
- 在应用目录article/下新建一个
urls.py文件
from django.urls import path
from .views import article_detail, article_list
urlpatterns = [
path("" , article_detail),
path("", article_list),
]
- 修改主的urls.py为
from django.contrib import admin
from django.urls import path, include
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path("test/", views.index),
path("article/", include("article.urls"))
]
url命名空间
在真正的Django项目中,可能有五个,十个,二十个应用程序或更多。Django如何区分它们之间的URL名称?例如,polls应用程序有一个detail 视图,因此同一项目中的应用程序可能适用于博客。如何使Django知道在使用模板标签时为url创建哪个应用视图 ?{% url %}
答案是为URLconf添加名称空间。在polls/urls.py 文件中,继续并添加一个app_name以设置应用程序命名空间:
#urls.py
from django.urls import path
from . import views
app_name = 'polls' # 命名空间
urlpatterns = [
path('', views.index, name='index'),
path('/' , views.detail, name='detail'),
path('/results/' , views.results, name='results'),
path('/vote/' , views.vote, name='vote'),
]
在模板中使用命名空间
<li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}a>li>
定制后台和修改模型
定制后台
问题描述:进入后台之后发现字段名显示的是Article object (1),更加合理的应该是显示文章的标题。

解决方法:在对应的models类中添加对应的__str__()方法并且返回对应的字段。
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(max_length=30)
content = models.TextField()
def __str__(self):
return self.title
运行结果

如果需要显示多个字段的话,则需要修改对应应用中的admin.py
from django.contrib import admin
from .models import Article
# Register your models here.
class ArticleAdmin(admin.ModelAdmin):#增加实现admin.ModelAdmin的类
list_display = ("id", "title", "content")
admin.site.register(Article, ArticleAdmin)#增加对应的admin类
运行效果(此时的id为逆序)

因为默认排序为逆序,假如需要自定义排序的方法需要在admin类中添加ording
from django.contrib import admin
from .models import Article
# Register your models here.
class ArticleAdmin(admin.ModelAdmin):
list_display = ("id", "title", "content")
ordering = ("id",) # id正序排序,注意是元祖不是括号
admin.site.register(Article, ArticleAdmin)
需要逆序的话(默认):ordering = ("-id",)
同时可以装饰器来装饰admin定制类
from django.contrib import admin
from .models import Article
# Register your models here.
@admin.register(Article) # 增加的admin装饰器,代码清晰很多了
class ArticleAdmin(admin.ModelAdmin):
list_display = ("id", "title", "content")
ordering = ("-id",)
admin.site.register(Article, ArticleAdmin)
修改模型
问题描述:在一开始模型设计时可能出现问题,或者是业务需求的改变,需要向数据库中增加一些字段,比如前面创建的article的model举例,models中只有标题和内容,现在我们需要向里面增加一个字段:创建文章的时间(create_data)
步骤:
- 修改models.py文件增加对应的字段,添加一个字段创建文章的时间
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(max_length=30)
content = models.TextField()
create_data = models.DateTimeField(auto_now__add=True) ## 新增的字段
def __str__(self):
return self.title
重新运行之后,刷新界面报错
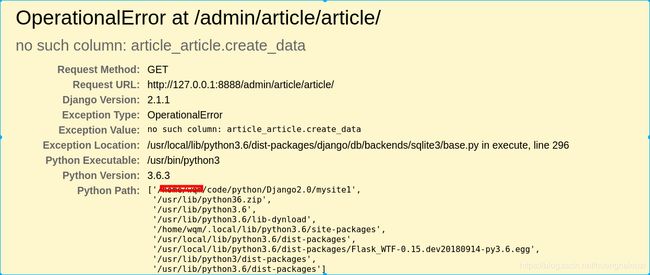
之后执行制造迁移(makemigrations),和迁移(migrate)即可,在admin.py增加显示的项目,效果

继续修改models.py文件,添加最后更新时间
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(max_length=30)
content = models.TextField()
create_date = models.DateTimeField(auto_now_add=True)
last_update_date = models.DateTimeField(auto_now=True)
def __str__(self):
return self.title
其中的DateTimeField的参数auto_now_add适合用在功能类似创建时间字段中,他的时间只会自动生成一次。而DateTimeField的参数设置为auto_now则适合在更新时间字段,每一次执行的更新数据库操作都会更新时间。

常见的还有设置外键models.ForeignKey等等
模板相关
常见的模板标签
用两个括号括起来的文字(例如{{person_name}})称为变量.此处插入指定变量的值.
用大括号和百分号包围的文字(例如{%if xxxxx%})被称为模板标签.标签(tag)定义比较明确,即: 仅通知模板系统完成某些工作的标签。模板标签一般都有结束标签比如if的结束标签是{%endif%}
- {%url name%}标签
一般最简单的设置url的方法这这样的
{% for blog in blogs%}
<h3><a href="blog/{{blog.pk}}">{{blog.title}}a>h3>
{%endfor%}
Django还提供一个url标签,首先在urls.py文件设置url时需要设置一个路由的别名
urlpatterns = [
path("", blog_list, name = "home"),
]
接着在模板文件中可以使用url标签调用对应的url
<a href="{%url 'home'%}">
结果和下面的方法一样,但是建议使用url标签
<a> href="/"a>
- {%for%}和{%empty%}标签
{%for%}标签的用法和Python中的for循环的用法类似
{%empty%}标签主要使用在当传过来的对象集合为空时输出的内容或者执行的动作,必须配合for循环使用。
{% for blog in blogs%}
<h3><a href="blog/{{blog.pk}}">{{blog.title}}a>h3>
{% empty %}
<p>暂时没有博客p>
{%endfor%}
当内容不为空时直接输出内容

进入后台把文章全部删除之后,刷新页面

给标签增加一个 reversed 使得该列表被反向迭代:
{% for athlete in athlete_list reversed %}
...
{% endfor %}
Django不支持退出循环操作。 如果我们想退出循环,可以改变正在迭代的变量,让其仅仅包含需要迭代的项目。 同理,Django也不支持continue语句,我们无法让当前迭代操作跳回到循环头部。
在每个{% for %}循环里有一个称为forloop 的模板变量。这个变量有一些提示循环进度信息的属性。
forloop.counter 总是一个表示当前循环的执行次数的整数计数器。 这个计数器是从1开始的,所以在第一次循环时 forloop.counter 将会被设置为1。
{% for item in todo_list %}
<p>{{ forloop.counter }}: {{ item }}p>
{% endfor %}
forloop.counter0 类似于 forloop.counter ,但是它是从0计数的。 第一次执行循环时这个变量会被设置为0。
forloop.revcounter 是表示循环中剩余项的整型变量。 在循环初次执行时 forloop.revcounter 将被设置为序列中项的总数。 最后一次循环执行中,这个变量将被置1。
forloop.revcounter0 类似于 forloop.revcounter ,但它以0做为结束索引。 在第一次执行循环时,该变量会被置为序列的项的个数减1。
forloop.first 是一个布尔值,如果该迭代是第一次执行,那么它被置为在下面的情形中这个变量是很有用的:
{% for object in objects %}
{% if forloop.first %}<li class="first">{% else %}<li>{% endif %}
{{ object }}
li>
{% endfor %}
forloop.last 是一个布尔值;在最后一次执行循环时被置为True。 一个常见的用法是在一系列的链接之间放置管道符(|)
{% for link in links %}{{ link }}{% if not forloop.last %} | {% endif %}{% endfor %}
结果
Link1 | Link2 | Link3 | Link4
forloop 变量仅仅能够在循环中使用。 在模板解析器碰到{% endfor %}标签后,forloop就不可访问了。
- {%if%}和{%ifequal%}标签
if标签的用法和Python中的用法类似,{% if %} 标签接受 and , or 或者 not 关键字来对多个变量做判断 ,或者对变量取反( not )。但是没有{%elif%}标签可以使用多层if标签代替。
{% if ordered_warranty %}
<p>Your warranty information will be included in the packaging.p>
{% else %}
<p>You didn't order a warranty, so you're on your own when
the products inevitably stop working.p>
{% endif %}
{% if %} 标签不允许在同一个标签中同时使用 and 和 or ,因为逻辑上可能模糊的
{% if athlete_list and coach_list or cheerleader_list %}
系统不支持用圆括号来组合比较操作。如果你确实需要用到圆括号来组合表达你的逻辑式,考虑将它移到模板之外处理,然后以模板变量的形式传入结果吧。
{% if athlete_list %}
{% if coach_list or cheerleader_list %}
We have athletes, and either coaches or cheerleaders!
{% endif %}
{% endif %}
{% ifequal %} 标签比较两个值,当他们相等时,显示在 {% ifequal %} 和 {% endifequal %} 之中所有的值。
{% ifequal user currentuser %}
<h1>Welcome!h1>
{% endifequal %}
只有模板变量,字符串,整数和小数可以作为 {% ifequal %} 标签的参数。
- {#注释#}
注释的内容不会在模板渲染时输出。用这种语法的注释不能跨越多行。 这个限制是为了提高模板解析的性能。
{#这是一个注释内容#}
常见的模板过滤器
模板过滤器是在变量被显示前修改它的值的一个简单方法。过滤器使用管道符|调用,用法和Unix及Linux的管道符类似。有些过滤器有参数。 过滤器的参数跟随冒号之后并且总是以双引号包含。
- length-统计对象的个数(长度)
第一种方法是使用Django自带的过滤器{{对象集合|length}}
例如
文章的总数为{{blogs|length}}个
另一种方法是使用.objects.all().count()方法
#文章列表
def blog_list(request):
context = {}
context["blogs"] = Blog.objects.all()
context["count"] = Blog.objects.all().count()
return render(request, "blogs.html", context)
接着模板中直接输出参数即可
文章的个数为{{count}}
- date - 时间格式化
{{ship_date|date:”Y-m-d” }} - truncatewords
{{ test|truncatewords:"30" }}
显示变量的前30个词,不可用于中文,中文的词的分界不是空格。中文可以使用过滤器slice:'70'。
-
addslashes :
添加反斜杠到任何反斜杠、单引号或者双引号前面。 这在处理包含JavaScript的文本时是非常有用的。 -
过滤器的套接
过滤管道可以被套接,既一个过滤器管道的输出又可以作为下一个管道的输入。下面的例子实现查找列表的第一个元素并将其转化为大写。
{{ my_list|first|upper }}
模板包含
利用到Django内建模板标签{% include %}.该标签允许在(模板中)包含其它的模板的内容。 标签的参数是所要包含的模板名称,可以是一个变量,也可以是用单/双引号硬编码的字符串。 每当在多个模板中出现相同的代码时,就应该考虑是否要使用 {% include %} 来减少重复。
用法
{% include 'nav.html' %}
如果{% include %}标签指定的模板没找到,Django将会在下面两个处理方法中选择一个:
- 如果 DEBUG 设置为 True ,你将会在 Django 错误信息页面看到 TemplateDoesNotExist 异常。
- 如果 DEBUG 设置为 False ,该标签不会引发错误信息,在标签位置不显示任何东西。
模板的继承
假设存在这一个模板文件blogs.html
<html lang="zh" dir="ltr">
<head>
<meta charset="utf-8">
<title>我的博客title>
head>
<body>
<h3>我的个人博客网站h3>
<br>
文章的个数为{{count}}
<hr>
{% for blog in blogs%}
<h3><a href="blog/{{blog.pk}}">{{blog.title}}a>h3>
{% empty %}
<p>暂时没有博客p>
{%endfor%}
body>
html>
以及存在这个一个显示文章详情的模板文件blog_detail.html
<html lang="zh" dir="ltr">
<head>
<meta charset="utf-8">
<title>{{blog.title}}title>
head>
<body>
<a href="{%url 'home'%}">
<h3>我的个人博客网站h3>
a>
<h3>{{blog.title}}h3>
<p>作者 {{blog.author}}p>
<p>发表日期 {{blog.create_time|date:"Y年m月d日 H:n:s"}}p>
<p>文章分类
<a href="{%url 'blogs_with_type' blog.blog_type.pk%}">{{blog.blog_type}}a>
p>
<p>{{blog.content}}p>
body>
html>
第一步分析模板文件中具有共同代码的一部分
<html lang="zh" dir="ltr">
<head>
<meta charset="utf-8">
<title>这个是模板的标题title>
head>
<body>
这个是模板的内容
body>
html>
到这里就可根据上面的共同代码部分分离出基模板base.html,需要用到{%block%}标签代替模板文件中可变部分的代码
<html lang="zh" dir="ltr">
<head>
<meta charset="utf-8">
<title>{%block title%}{%endblock%}title>
head>
<body>
{%block content%}{%endblock%}
body>
html>
接着使用模板文件继承这个基模板文件需要使用到的标签为{%extends%}和{%block%},在{%block content%}{%endblock%}这两个标签之间填写木模板文件需要的代码,例如blog_detail.html文件可以改写为
{% extends 'base.html' %}
{% block title %}
{{blog.title}}
{% endblock %}
{% block content %}
<a href="{%url 'home'%}">
<h3>我的个人博客网站h3>
a>
<h3>{{blog.title}}h3>
<p>作者 {{blog.author}}p>
<p>发表日期 {{blog.create_time|date:"Y年m月d日 H:n:s"}}p>
<p>文章分类
<a href="{%url 'blogs_with_type' blog.blog_type.pk%}">{{blog.blog_type}}a>
p>
<p>{{blog.content}}p>
{% endblock %}
blogs.html文件的代码为
{% extends 'base.html' %}
{% block title %}
我的博客
{% endblock %}
{% block content %}
<h3>我的个人博客网站h3>
<br>
文章的个数为{{count}}
<hr>
{% for blog in blogs%}
<h3><a href="blog/{{blog.pk}}">{{blog.title}}a>h3>
{% empty %}
<p>暂时没有博客p>
{%endfor%}
{% endblock %}
在上面的例子中还可在基模板base.html中的{%block title%}{%endblock%}之间定义默认内容。当子模板中没有定义{%block title%}{%endblock%}默认渲染父模板内容。
使用继承的一种常见方式是下面的三层法:
- 创建 base.html 模板,在其中定义站点的主要框架。 这些都是不常修改甚至从不修改的部分。
- 为网站的每个区域创建 base_SECTION.html 模板(例如, base_photos.html 和 base_forum.html )。这些模板对 base.html 进行拓展,并包含区域特定的风格与设计。
- 为每种类型的页面创建独立的模板,例如论坛页面或者图片库。 这些模板拓展相应的区域模板。
以下是使用模板继承的一些诀窍:
- 如果在模板中使用 {% extends %} ,必须保证其为模板中的第一个模板标记。 否则,模板继承将不起作用。
- 一般来说,基础模板中的 {% block %} 标签越多越好。 记住,子模板不必定义父模板中所有的代码块,因此你可以用合理的缺省值对一些代码块进行填充,然后只对子模板所需的代码块进行(重)定义。 俗话说,钩子越多越好。
- 如果发觉自己在多个模板之间拷贝代码,你应该考虑将该代码段放置到父模板的某个 {% block %} 中。
- 如果你需要访问父模板中的块的内容,使用 {{ block.super }}这个标签吧,这一个魔法变量将会表现出父模板中的内容。 如果只想在上级代码块基础上添加内容,而不是全部重载,该变量就显得非常有用了。
- 不允许在同一个模板中定义多个同名的 {% block %} 。 存在这样的限制是因为block 标签的工作方式是双向的。 也就是说,block 标签不仅挖了一个要填的坑,也定义了在父模板中这个坑所填充的内容。如果模板中出现了两个相同名称的 {% block %} 标签,父模板将无从得知要使用哪个块的内容。
- {% extends %} 对所传入模板名称使用的加载方法和 get_template() 相同。 也就是说,会将模板名称被添加到 TEMPLATE_DIRS 设置之后。
- 多数情况下, {% extends %} 的参数应该是字符串,但是如果直到运行时方能确定父模板名,这个参数也可以是个变量。 这使得你能够实现一些很酷的动态功能。
models相关
数据库的配置
数据库的默认配置在settings.py中,默认使用sqlite3数据库,默认配置如下
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
如果需要选择其他的数据库需要配置以下的选项
DATABASE_ENGINE = ''
DATABASE_NAME = ''
DATABASE_USER = ''
DATABASE_PASSWORD = ''
DATABASE_HOST = ''
DATABASE_PORT = ''
DATABASE_ENGINE 告诉Django使用哪个数据库引擎,支持
postgresql,postgresql_psycopg2,mysql,sqlite3,oracle等等。要注意的是无论选择使用哪个数据库服务器,都必须下载和安装对应的数据库适配器 。sqlite3只需要配置DATABASE_ENGINE和DATABASE_NAME.
DATABASE_USER 告诉 Django 用哪个用户连接数据库。
DATABASE_PASSWORD 告诉Django连接用户的密码。
DATABASE_HOST 告诉 Django 连接哪一台主机的数据库服务器。
DATABASE_PORT 端口 ,比如mysql的默认端口时3306
例如连接mysql的配置为
sudo apt install python-pymysql # mysql驱动
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'blog_db',
'USER':'root',
'PASSWORD':'123456',
'HOST':'',
'PORT':'',
}
}
定义模型
Django中推荐在app中声明models,所以需要创建一个应用
python3 manage.py startapp book
接着打开应用中的models.py文件添加models
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
每个数据模型都是 django.db.models.Model 的子类。它的父类 Model 包含了所有必要的和数据库交互的方法,并提供了一个简洁漂亮的定义数据库字段的语法。
其中的Publisher类等价于这个数据表
CREATE TABLE "books_publisher" (
"id" serial NOT NULL PRIMARY KEY,
"name" varchar(30) NOT NULL,
"address" varchar(50) NOT NULL,
"city" varchar(60) NOT NULL,
"state_province" varchar(30) NOT NULL,
"country" varchar(50) NOT NULL,
"website" varchar(200) NOT NULL
);
创建模型之后还需要注册应用,完成数据迁移等操作。
插入和更新数据
插入和更新数据参照下面的Django shell的基本使用
数据的过滤
Django提供一个filter()方法用来对数据进行过滤。下面的操作实在Django shell中进行
In [1]: from blog.views import Blog
In [2]: Blog.objects.all()
Out[2]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>, <Blog: for-26>, <Blog: for-25>, <Blog: for-24>, <Blog: for-23>, <Blog: for-22>, <Blog: for-21>, <Blog: for-20>, <Blog: for-19>, <Blog: for-18>, <Blog: for-17>, <Blog: for-16>, <Blog: for-15>, <Blog: for-14>, <Blog: for-13>, <Blog: for-12>, '...(remaining elements truncated)...']>
In [3]: Blog.objects.filter(title='test')
Out[3]: <QuerySet [<Blog: test>]>
Blog.objects.filter(title='test')的效果等价于下面的sql语句
select * from blog where title='test'
filter的条件可以有多个,可以缩小搜索范围
In [7]: Blog.objects.filter(id=4)
Out[7]: <QuerySet [<Blog: 安装Django>]>
In [8]: Blog.objects.filter(id=4, title='安装Django')
Out[8]: <QuerySet [<Blog: 安装Django>]>
默认情况filte的=是精确查找,如果需要模糊查找需要在字段名后面加上__contains,例如
In [13]: Blog.objects.filter(title__contains='4')
Out[13]: <QuerySet [<Blog: for-24>, <Blog: for-14>, <Blog: for-4>]>
与之等价的sql语句是
select * from blog where title like '%4%'
其他的一些查找类型有:icontains(大小写无关的LIKE),startswith和endswith, 还有range(SQLBETWEEN查询)
获取单个对象
获取单个对象需要用到get()方法
In [7]: Blog.objects.get(pk=3)
Out[7]: <Blog: Python的虚拟环境virtualenv>
如果查询灭有返回结果,将返回一个DoesNotExist异常。DoesNotExist是models类的一个属性,在应用中应该处理这个异常
try:
p = Publisher.objects.get(name='Apress')
except Publisher.DoesNotExist:
pass
else:
pass
最简单的方法是直接使用get_object_or_404方法,没有返回结果时自动抛出404异常。
from django.shortcuts import render, get_object_or_404
...
def blog_detail(request):
...
blog = get_object_or_404(Blog,pk=blog_pk)
...
获取全部数据
和上面的get方法类似,可以使用all()方法获取所有的数据
blogs = Blog.objects.all()
数据排序
数据排序可以使用order_by方法,比如以博客标题进行排序的python代码,当然我们可以对任意的字段进行排序。
In [8]: from blog.models import Blog
In [9]: Blog.objects.order_by("title")
Out[9]: <QuerySet [<Blog: Python的虚拟环境virtualenv>, <Blog: for-1>, <Blog: for-10>, <Blog: for-11>, <Blog: for-12>, <Blog: for-13>, <Blog: for-14>, <Blog: for-15>, <Blog: for-16>, <Blog: for-17>, <Blog: for-18>, <Blog: for-19>, <Blog: for-2>, <Blog: for-20>, <Blog: for-21>, <Blog: for-22>, <Blog: for-23>, <Blog: for-24>, <Blog: for-25>, <Blog: for-26>, '...(remaining elements truncated)...']
对应sql语句如下
select * from blog order by title
如果需要以多个字段为标准进行排序(第二个字段会在第一个字段的值相同的情况下被使用到),使用多个参数就可以了,如下:
In [13]: Blog.objects.order_by("title","id")
Out[13]: <QuerySet [<Blog: Python的虚拟环境virtualenv>, <Blog: for-1>, <Blog: for-10>, <Blog: for-11>, <Blog: for-12>, <Blog: for-13>, <Blog: for-14>, <Blog: for-15>, <Blog: for-16>, <Blog: for-17>, <Blog: for-18>, <Blog: for-19>, <Blog: for-2>, <Blog: for-20>, <Blog: for-21>, <Blog: for-22>, <Blog: for-23>, <Blog: for-24>, <Blog: for-25>, <Blog: for-26>, '...(remaining elements truncated)...']>
还可以指定逆向排序,在字段前添加一个-号
In [11]: Blog.objects.order_by("id")
Out[11]: <QuerySet [<Blog: Python的虚拟环境virtualenv>, <Blog: 安装Django>, <Blog: web test>, <Blog: shell下添加的第一篇文章>, <Blog: shell下的第二篇文章>, <Blog: for-30>, <Blog: for-1>, <Blog: for-2>, <Blog: for-3>, <Blog: for-4>, <Blog: for-5>, <Blog: for-6>, <Blog: for-7>, <Blog: for-8>, <Blog: for-9>, <Blog: for-10>, <Blog: for-11>, <Blog: for-12>, <Blog: for-13>, <Blog: for-14>, '...(remaining elements truncated)...']>
In [12]: Blog.objects.order_by("-id")
Out[12]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>, <Blog: for-26>, <Blog: for-25>, <Blog: for-24>, <Blog: for-23>, <Blog: for-22>, <Blog: for-21>, <Blog: for-20>, <Blog: for-19>, <Blog: for-18>, <Blog: for-17>, <Blog: for-16>, <Blog: for-15>, <Blog: for-14>, <Blog: for-13>, <Blog: for-12>, '...(remaining elements truncated)...']>
尽管很灵活,但是每次都要用 order_by() 显得有点啰嗦。 大多数时间你通常只会对某些 字段进行排序。 在这种情况下,Django让你可以指定模型的缺省排序方式,需要在models.py文件中的模型类中添加
class Blog(models.Model):
title = models.CharField(max_length=120)
blog_type = models.ForeignKey(BlogType, on_delete=models.DO_NOTHING)
content = RichTextUploadingField(config_name='my_config') ## 富文本编辑器
author = models.ForeignKey(User, on_delete=models.DO_NOTHING)
readed_num = models.IntegerField(default=0)
create_time = models.DateTimeField(auto_now_add=True)
last_update_time = models.DateTimeField(auto_now=True)
def __str__(self):
return self.title
# 这个是添加的排序代码
class Meta:
ordering = ['-create_time']
连锁查询
通常我们需要同时进行过滤和排序查询的操作。 因此,你可以简单地写成这种“链式”的形式:
In [19]: Blog.objects.filter(id__contains='4').order_by("id")
Out[19]: <QuerySet [<Blog: 安装Django>, <Blog: for-6>, <Blog: for-16>, <Blog: for-26>]>
In [20]: Blog.objects.filter(id__contains='4').order_by("-id")
Out[20]: <QuerySet [<Blog: for-26>, <Blog: for-16>, <Blog: for-6>, <Blog: 安装Django>]>
限制返回的数据
一个常用的需求就是取出固定数目的记录。 想象一下你有成千上万的出版商在你的数据库里, 但是你只想显示第一个。 你可以使用标准的Python列表裁剪语句:(类似python中list的切片)
In [25]: Blog.objects.all()
Out[25]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>, <Blog: for-26>, <Blog: for-25>, <Blog: for-24>, <Blog: for-23>, <Blog: for-22>, <Blog: for-21>, <Blog: for-20>, <Blog: for-19>, <Blog: for-18>, <Blog: for-17>, <Blog: for-16>, <Blog: for-15>, <Blog: for-14>, <Blog: for-13>, <Blog: for-12>, '...(remaining elements truncated)...']>
In [26]: Blog.objects.all()[0]
Out[26]: <Blog: test>
In [27]: Blog.objects.all()[1]
Out[27]: <Blog: for-30>
Blog.objects.all()[0]对应的sql语句如下
select * from blog limit 1;
如果需要返回前五个数据,参考下面的代码
In [28]: Blog.objects.all()[:5]
Out[28]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>]>
In [29]: Blog.objects.all()[0:5]
Out[29]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>]>
显然这部分的内容和python中切片类似,但是不支持负索引
In [30]: Blog.objects.all()[-3]
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last**
但是可以通过修改order_by方法完成和负索引类似的功能
In [33]: Blog.objects.all()
Out[33]: <QuerySet [<Blog: test>, <Blog: for-30>, <Blog: for-29>, <Blog: for-28>, <Blog: for-27>, <Blog: for-26>, <Blog: for-25>, <Blog: for-24>, <Blog: for-23>, <Blog: for-22>, <Blog: for-21>, <Blog: for-20>, <Blog: for-19>, <Blog: for-18>, <Blog: for-17>, <Blog: for-16>, <Blog: for-15>, <Blog: for-14>, <Blog: for-13>, <Blog: for-12>, '...(remaining elements truncated)...']>
In [34]: Blog.objects.all().order_by('-create_time')[0]
Out[34]: <Blog: test>
In [35]: Blog.objects.all().order_by('create_time')[0]
Out[35]: <Blog: Python的虚拟环境virtualenv>
更新多个对象
如果需要更新一个对象可以使用下面的方法
In [42]: Blog.objects.all().order_by('create_time')[2].title
Out[42]: 'web test'
In [43]: blog = Blog.objects.all().order_by('create_time')[2]
In [44]: blog.title = "web test update"
In [45]: blog.save()
In [47]: Blog.objects.all().order_by('create_time')[2].title
Out[47]: 'web test update'
但是更推荐使用QueueSet自带的update方法更新
In [57]: Blog.objects.filter(id=5).update(title="web test update2")
Out[57]: 1
使用update方法更新数据不会影响其他的字段的值,但是拿第一种方法更新的话会影响其他字段的值。
![]()
第一种方法效果,其中last update time 内容发生改变,原因是这个字段设置为自动更新时间
![]()
last_update_time = models.DateTimeField(auto_now=True)
删除对象
删除对象使用filter.delete方法
In [68]: p = Blog.objects.get(title="test")
In [69]: p.delete
Out[69]: <bound method Model.delete of <Blog: test>>
In [70]: p.delete()
Out[70]: (1, {'blog.Blog': 1})
In [72]: Blog.objects.filter(title="for-30").delete()
Out[72]: (2, {'blog.Blog': 2})
外键
from django.db import models
from other_course.models import Course_models
class Plan_models(models.Model):
"""
培养计划 models
traning_plan_id
plan_year
college_major
plan_plan : 外键指向的
"""
plan_year = models.PositiveIntegerField()
plan_major = models.CharField(max_length=100)
def __str__(self):
return "第"+str(self.plan_year)+"学年"+str(self.plan_major)+"专业培养计划"
class Plan_Plan_models(models.Model):
"""
实际的培养计划存储的models, 外键指向Plan_models
"""
p_id = models.ForeignKey(to=Plan_models, on_delete=models.CASCADE, related_name="plan_id_f")
plan_course = models.ForeignKey(to=Course_models, on_delete=models.CASCADE, related_name="plan_course_f", to_field="id")
# def __str__(self):
# return ""
查询某个教学计划下面的某门课
Plan_models.objects.get(pk=2).plan_id_f.get(pk=1).plan_course.course_name
表单相关
简单的表单类实例
在Django 的设计理念中, 一个表单需要指明两件事:
- 什么位置(action): 与用户输入相对应的数据返回到哪一个URL路径
- 什么方法(method): 采用哪种HTTP方法, 常用的有GET,POST
这种不使用python-Django表单类的写法, 需要在模板文件中完整的写出html表单。
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>表单示例title>
head>
<body>
<form action="/user_name/" method="post">
<label for="user_name">姓名:label>
<input id="user_name" type="text" name="user_name" value="{{ current_name }}">
<input type="submit" value="OK">
form>
body>
html>
tip:
- 新建
forms.py文件
在项目中的应用目录中新建一个form.py文件 - 在
form.py文件中构建表单内容
from django import forms
# 定义表单类,继承自Django的Forms类
class NameForm(forms.Form):
username = forms.CharField(label="姓名", max_length=20)
tip: 表单类所生成的HTML代码不包含标签和提交(submit)按钮,我们需要在模板文件中自己编写。
- 定义对应的视图函数
from django.shortcuts import render
from django.http import HttpResponseRedirect # 导入重定向类
from .forms import NameForm # 导入表单类
def get_name(request):
# POST方式提交
if request.method == "POST":
# 使用提交的数据实例化表单类
form = NameForm(requestt.POST)
# 验证表单数据的有效性
if form.is_valid():
# 如果有效重定向到新的界面
print("1111111")
return HttpResponseRedirect("/thanks1/")
else: # GET方式提交数据
form = NameForm() # 实例化一个空的表格
context = {}
context['form'] = form
return render(request, 'name.html', context)
def thanks(request):
context = {}
context['name'] = "jedi"
return render(request, 'thanks.html', context)
- 定义模板内容
<html lang="zh-cn" dir="ltr">
<head>
<meta charset="utf-8">
<title>表单实例title>
head>
<body>
<form class="#" action="/user_name/" method="post">
{% csrf_token %}
{{ form }}
<input type="submit" value="OK">
form>
body>
html>
- 配置URL
from django.contrib import admin
from django.urls import path
from form1.views import get_name, thanks
urlpatterns = [
path('admin/', admin.site.urls),
path('login/', get_name),
path('user_name/', thanks),
]
运行结果

表单进阶
如果表单类中包含URLField、EmailField或任何整数类型的字段,Django会使用HTML5的输入框类型。默认情况下,浏览器会自动进行这些字段的验证,甚至比Django的验证更加严格。如果要禁用浏览器的自动验证,需要在