11-合久必分,分久必合-MapReduce数据流
MapReduce数据流
1 概述
MapReduce是Hadoop的核心组件,它在处理大规模数据时,将工作分割成一系列独立的任务,然后进行并行处理。我们在本节将了解Hadoop MapReduce内部是如何工作的。
本节提供了完整的MapReduce 数据流图表,我们会介绍该图表中的各个阶段,比如:Input文件, InputFormat, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling&Sorting, Reducer, RecordWriter,OutputFormat。
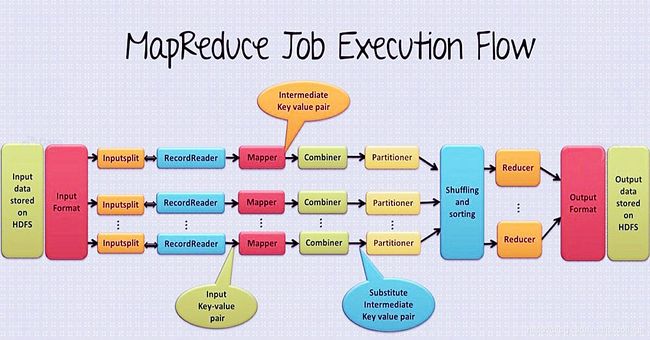
2 Hadoop MapReduce是如何工作的
MapReduce是Hadoop的数据处理层。它是一个软件框架,帮助你非常容易地编写应用程序,处理存储在HDFS(Hadoop分布式文件系统)上的各种结构化和非结构化的数据。它通过将作业拆分成独立的子任务,然后并行处理海量数据。通过并行处理,提高集群处理速度及可靠性。我们只需要将定制的代码(业务逻辑)以map和reduce方式进行组织,剩下的事情就交给引擎去处理。
在Hadoop中,MapReduce将数据处理过程分成两个阶段:Map阶段和Reduce阶段。
Map是数据处理的第一阶段,我们需要在此阶段指定复杂的逻辑,业务规则,重要的代码。Reduce是数据处理的第二个阶段,我们在此阶段编写轻量级的处理代码包括聚合,求和等。
3 MapReduce数据流
下面我们就介绍Hadoop MapReduce作业执行的整个流程
3.1 Input File
输入文件(Input File)是MapReduce任务要处理的数据,这些文件通常存储在HDFS中。这些文件的格式是任意的,包括一行行的日志文件以及二进制格式。
3.2 InputFormat
输入格式(InputFormat)定义了输入文件该如何分割和读取。它选择文件或者其他对象作为输入。输入格式会建立输入分片(InputSplit)。
3.3 InputSplit
输入分片(InputSplit)由输入格式(InputFormat)创建,它是每个独立的Mapper所处理数据的逻辑表示。系统会为每个分片创建一个map任务,也就是说,有多少输入分片就会有多少个map任务。分片会继续分割成记录,而且每个记录最终会交给该分片的mapper处理。
3.4 RecordReader
在Hadoop MapReduce中,RecordReader(记录读取器)和InputSplit(输入分片)交互,将数据转换成适合Mapper读取的键值对。默认情况下,它使用TextInputFormat将数据转换成键值对。RecordReader会和InputSplit保持通讯,直到文件读取完毕。它为文件中的每一行指定一个字节偏移量(唯一编号)。这些键值对会发送给mapper做进一步处理。
3.5 Mapper
Mapper会处理来自RecordReader的每条输入记录,并生成新的键值对,Mapper生成的这个键值对和输入的键值对完全不同。Mapper的输出也被称为中间结果,会写入到本地磁盘。Mapper的输出并不会在HDFS上存储,因为这是临时数据,如果写入HDFS会建立不必要的拷贝,而且HDFS本身也是高延迟的系统。Mapper的输出会传递给combiner继续处理。
3.6 Combiner
Combiner(合并)也称为‘Mini-reducer’(迷你归并),Hadoop MapReduce Combiner对mapper的输出做本地聚合,这样有助于减少mapper和reducer之间的数据传输。一旦合并完成,输出结果将传递给partitioner继续处理。
3.7 Partitioner
如果有一个以上Reducer就会引入Partitioner(,如果仅有一个reducer,是不会使用partitioner的)。
Partitioner从combiner接收输出结果,并执行分区操作。基于对key应用hash函数来进行分区。
在MapReduce中,根据key的值,每个combiner的输出都会被分区,而且相同的key会被分到同一个区,然后每个分区都会发送给reducer,分区允许map输出在reducer上进行分布。
3.8 shuffle和sort
现在,输出结果需要传递到reduce节点(reduce也是一个普通slave节点,只是在运行reduce时,我们就把它称为reducer节点)。shuffle是将数据在网络上进行物理移动的过程。一旦所有mapper完成操作,它们的输出结果就会传输到reducer节点,然后这些中间结果会给合并和排序,最后作为reduce阶段的输入。
3.9 Reducer
Reducer接收mapper产生的中间键值对作为输入,任何对每个键值对运行reducer函数产生输出。。reducer的输出会是最终输出,它将存储在HDFS中。
3.10 RecordWriter
RecordWriter将reducer阶段产生的键值对输出写入到输出文件。
3.11 OutputFormat
RecordWriter将输出键值对写入到输出文件的格式取决于OutputFormat。Hadoop所提供的OutputFormat实例用于将文件写入HDFS或者本地磁盘。因此reducer的最终输出会通过OutputFormat实例写入到HDFS中。
4 总结
我们在这里了解了MapReduce数据的流转过程。详细介绍了各个组件在hadoop MapReduce工作中扮演的重要角色。这些组件包括:Input文件, Hadoop InputFormat, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling&Sorting, Reducer, RecordWriter, OutputFormat。