13-如何分-InputFormat&InputSplit&RecordReader解析
Hadoop InputFormat&InputSplit&Recorder解析
1 概述
本节我们来介绍InputFormat、InputSplit以及Recorder,了解Hadoop是如何使用这些组件来分割数据的。我们从而掌握这些组件之间的联系和区别。
2 Hadoop InputFormat
Hadoop InputFormat检查作业的输入规范。InputFormat将输入文件分割成InputSplit(输入分片),并分配给独立的mapper。
InputFormat定义了在Hadoop中输入文件如何被分割和读取。在MapReduce中,Hadoop InputFormat是第一个组件,它负责建立输入分片并把它们拆分成记录。
最初,MapReduce任务的数据是存储在输入文件中的,输入文件一般在HDFS上面。这些文件的格式可以是任意的,包括基于行的日志文件以及二进制格式的文件。使用InputFormat,我们可以定义输入文件如何分割和读取。在Hadoop MapReduce框架中,InputFormat类是一个基础类,它提供了如下功能:
- 用于输入的文件或者对象是由InputFormat负责选取的。
- InputFormat定义了数据分片,数据分片定义着单独的map任务的大小以及可能执行的服务。
- InputFormat定义了RecordReader,RecordReader负责从输入文件中读取实际的记录。
2.1 Mapper如何获取数据
在MapReduce中有两个方法负责向mapper提供数据:getsplits()和 createRecordReader() :
public abstract class InputFormat
{
public abstract List getSplits(JobContext context)
throws IOException, InterruptedException;
public abstract RecordReader
createRecordReader(InputSplit split,TaskAttemptContext context)
throws IOException,InterruptedException;
}
2.2 MapReduce中InputFormat的类型
下面让我们看看InputFormat有哪些类型。

2.2.1 FileInputFormat
FileInputFormat是所有基于文件的InputFormat的基类。Hadoop FileInputFormat指定了数据文件所在的目录。当我们开始一个Hadoop作业时,包含要读取文件的路径会提供给FileInputFormat。FileInputFormat会读取所有文件,并且把这些文件分割成一个或者更多的输入分片(InputSplit)。
2.2.2 TextInputFormat
这是MapReduce默认的InputFormat。TextInputFormat将输入文件的每一行看成一个记录,并不执行解析。这适合未格式化的数据或者像日志文件这样的基于行的记录。
- Key-文件中行开始处以字节为单位的偏移量(相对于整个文件的开始处),组合了文件名之后会变得唯一。
- Value-行的内容,不包括行结束符。
2.2.3 KeyValueTextInputFormat
它和TextInputFormat类似,也是将输入的每一行作为单独的记录。TextInputFormat会把一整行作为值,而KeyValueTextInputFormat会将这一行使用tab字符(/t)分割成key和value。这里,key是tab字符之前的内容,tab字符之后一直到行尾的内容作为值。
2.2.4 SequenceFileInputFormat
Hadoop SequenceFileInputFormat也是一种InputFormat,它用来读取sequence file。sequence file是一种二进制文件,它存储键值对的二进制序列。sequence file支持block(块)压缩,并且可以直接对任意类型数据(不仅仅是文本类型)提供序列化和反序列化。这里键和值都是用户进行定义的。
2.2.5 SequenceFileAsTextInputFormat
Hadoop SequenceFileAsTextInputFormat是SequenceFileInputFormat的另外一种形式,它将sequence file的key和value转换成文本对象。通过在键和值上调用tostring()方法来执行转换。该类型的InputFormat非常适合以流式输入sequence file.
2.2.6 SequenceFileAsBinaryInputFormat
Hadoop SequenceFileAsBinaryInputFormat也是一种SequenceFileInputFormat,我们可以使用它将sequence file的键和值提取为二进制对象。
2.2.7 NLineInputFormat
通过 TextInputFormat 和 KeyValueTextInputFormat,每个 Mapper 收到的输入行数不同。行数取决于输入分片的大小和行的长度。 如果希望 Mapper 收到固定行数的输入,需要将 NLineInputFormat 作为 InputFormat。与 TextInputFormat 一样, 键是文件中行的字节偏移量,值是行本身。N 是每个 Mapper 收到的输入行数。N 设置为1(默认值)时,每个 Mapper 正好收到一行输入。 如果N=2,那么每个分片会包含2行。 一个Mapper会接受头两个键值对,而另外一个Mapper会收到接下来的2个键值对。
2.2.8 DBInputFormat
Hadoop DBInputFormat是从关系型数据库中通过JDBC读取数据的InputFormat。由于DBInputFormat的局限性,我们最好加载小的关系数据集,然后在HDFS中通过MultipleInput连接成大数据集。这里的key是LongWritables而value是DBWritables。
3 Hadoop InputSplit
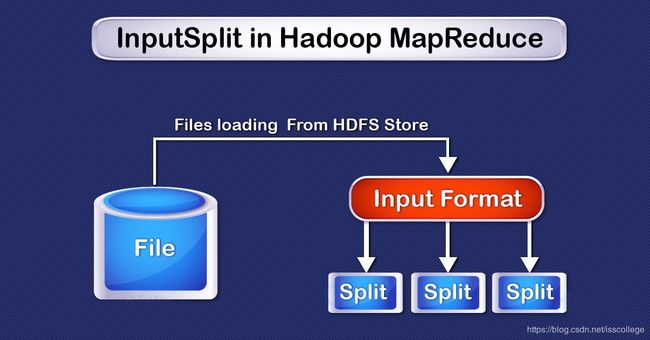
Hadoop MapReduce中的InputSplit(输入分片),是数据的逻辑表示。它描述了MapReduce程序中,一个map任务的工作单元。InputSplit所表示的数据将被一个独立的Mapper所处理。这个分片将被分成多条记录。mapper会处理每一条记录(也就是键值对)。
MapReduce InputSplit的长度用字节表示,而且每个InputSplit有一个存储位置(主机名字符串)。MapReduce系统会让map任务的存储位置尽可能地靠近分片数据。Map任务会按照分片大小的顺序进行处理,以便最大的分片最先处理(类似贪婪算法),这样也是对MapReduce作业的优化。我们还需要记住一个重要的事情,就是InputSplit并不包含输入数据,它只是到数据的引用。
作为用户,我们不需要直接处理InputSplit,因为它们是由InputFormat建立的(InputFormat建立InputSplit并且拆分成记录)。默认情况下是FileInputFormat,把文件分成128MB的块(和HDFS块一样),你可以通过设置mapred-site.xml中的mapred.min.split.size参数,来控制这个值,或者在作业对象中重写该参数。我们可以通过编写定制的InputFormat来控制文件如何分割成分片(split)。
3.1 如何在Hadoop中修改分片大小
Hadoop的InputSplit是用户定义的。在MapReduce程序中,用户可以数据的大小来控制分片的大小。map任务数等于InputSplit数。
客户端(运行作业的地方)可以通过调用getSplit()方法来为作业计算出分片,然后将其发送给application master,application master使用分片的存储位置来调度集群中处理分片的map作业。map作业将分片传递给InputFormat的createRecordReader()方法从而得到分片的RecordReader,RecordReader生成记录(键值对),然后将记录传递给map函数。
3.2 InputSplit和HDFS数据块(Block)的关系
HDFS数据块(Block)
数据块(block)是硬盘上存储数据的连续位置。通常,文件系统将数据存储为一系列的数据块(block)。按照同样的方式,HDFS也将文件以数据块(block)的形式存储。Hadoop应用程序负责在多个节点间分布式存储数据块。
Hadoop中的InputSplit
每个Mapper所处理数据的表示形式就是InputSplit。分片被分割成记录,而每条记录(键值对)再经由map处理。map任务数就等于inputSplit数。
最初,MapReduce任务所需的数据是存储在输入文件中的,输入文件位于HDFS上面。InputFormat用于定义这些输入文件如何分割和读取。InputFormat负责创建InputSplit。
3.2.1 MapReduce InputSplit和Block对比
InputSplit和Block的大小对比
- Block
HDFS block的默认大小是128MB,当然,我们也可以根据自己的需求进行配置。文件的所有数据块都是同一大小,除非是最后一个数据块,最后一个数据块要么相同大小,要么会更小些。文件会被分割成128MB的Block,然后存储在Hadoop文件系统中。
- InputSplit
默认情况下,InputSplit的大小近似等于block大小。InputSplit是由用户定义的,在MapReduce程序中,用户会根据数据的大小控制分片大小。
Hadoop Block和InputSplit的数据表示
- block
它是数据的物理表示。它包含可以被读取或者写入的最小数据单元。
- InputSplit
它是block中数据的逻辑表示。MapReduce程序或者其他处理技术在处理数据期间会使用它。InputSplit不包含实际的数据,只是到数据的引用。
3.3 Hadoop block和InputSplit示例



考虑这样一个例子,我们需要将文件存储到HDFS中,HDFS会以数据块的方式存储文件。数据块是从磁盘中存储和返回数据的最小单元,并且默认大小时128MB。HDFS会把文件分割成数据块,并且将这些数据块存储在集群中的不同节点之上。假设我们有一个130MB的文件,这时HDFS会将这个文件分成2个数据块。
现在,如果我们想对这些数据块执行MapReduce操作,这是不能执行的,因为第2个数据块是不完整的。因此,这个问题通过InputSplit来解决。由于InputSplit包含下一个数据块的位置和需要完成该数据块的字节偏移量,所以InputSplit对数据块在逻辑上进行分组形成了一个单独的数据块。
InputSplit只是数据的逻辑分块,它包含数据块的地址信息。在MapReduce执行过程中,Hadoop会扫描整个数据块,并建立InputSplit,而每个InputSplit会被指定给一个单独的mapper进行处理。因此Split实际上就是block和mapper之间的中介。
4 Hadoop RecordReader
要理解RecordReader,我们需要理解Hadoop数据流。下面我们看看Hadoop中的数据流是怎样的。
MapReduce有一个数据处理的简单模型。map和reduce函数的输入和输出都是键值对。
如下图所示:
- map:(K1,V1) ->list(K2,V2)
- reduce:(K2,list(V2))->list(K3,V3)
在数据处理之前,需要知道处理哪些数据,这是InputFormat的事情。InputFormat类将从HDFS中为map函数的输入选择文件。InputFormat也负责建立InputSplit,并且将其拆分成记录。HDFS中的数据被分割成很多分片(通常每128Mb为64个分片).这些分片被称为输入分片,因为将作为输入被单独的map所处理。
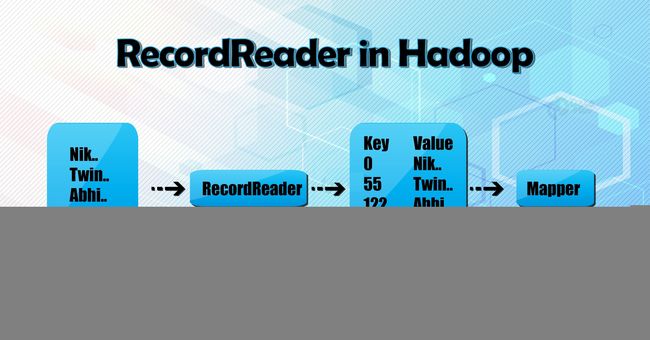
InputFormat类调用getSplits()函数,为每个文件计算出分片,然后将其发送给JobTracker,JobTracker使用输入分片的位置在TaskTracker上调度map任务来处理这些分片。Map任务接着会将分片传递给InputFormat 的createRecordReader()方法,在taskTracker上为分片获取RecordReader。RecordReader从它的资源中加载数据,并将其转换成适合map读取的键值对。
Hadoop RecordReader使用InputSplit边界内的数据为mapper建立键值对。RecordReader会从文件中开始的字节位置处,开始生成键值对,而在结束的地方停止生成记录(键值对也称为记录)。Hadoop RecordReader从它的资源中加载数据,然后将这些数据转换成适合Mapper读取的键值对。它和InputSplit保持交互,直到读完整个文件。
4.1 RecordReader是怎样工作的
下面我们来介绍RecordReader是如何工作的。RecordReader不仅仅是记录的迭代器,map任务也使用它将一条记录生成传递给map函数的键值对。我们可以通过map的run函数看出来:
public void run(Context context) throws IOException, InterruptedException{
setup(context);
while(context.nextKeyValue())
{
map(context.setCurrentKey(),context.getCurrentValue(),context)
}
cleanup(context);
}
在运行完setup(context)方法之后,nextKeyValue()会重复处理上下文,为mapper组装key和value对象,也就是以上下文的方式从RecordReader中获取key和value,并将其传递给map()方法。map函数的输入是键值对(K,V),键值对会被map代码做逻辑上的处理。当取到记录的结尾时,nextKeyValue()会返回false。
RecordReader会在InputSplit建立的边界之间生成键值对,但这也不是强制的行为。通过定制,也可以读取InputSplit之外的数据,但不鼓励这样做。
4.2 Hadoop RecordReader类型
RecordReader实例是由InputFormat定义的。默认情况下使用TextInputFormat对数据做键值对转换。TextInputFormat提供2种类型的RecordReader:
4.2.1 LineRecordReader
LineRecordReader是TextInputFormat提供的默认RecordReader类型,它将输入文件的每一行作为新值和key进行关联,这里的key是字节偏移量。如果不是第一个分片,LineRecordReader总是跳过分片中的第一行。它从分片结束的边界之后读取一行(如果数据有效,那么它不是最后的分片)。
4.2.2 SequenceFileRecordReader
用于从sequence文件中读取数据。
4.3 记录的最大长度
可以处理的单条记录的最大长度是由限制的。这个值可以通过如下参数设置:
conf.setInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);
如果一行记录的长度超过这个最大值(默认是:2,147,483,647),则会被忽略。
5 总结
InputFormat定义了如何分割和读取输入文件,也定义了RecordReader。InputFormat也根据不同的目的定义了不同类型的InputFormat,包括:FileInputFormat,TextInputFormat,KeyValueTextInputFormat,SequenceFileInputFormat等等。
InputSplit不包含实际数据,只是到数据的引用。在MapReduce程序或者其他处理技术在数据处理过程中会使用InputSplit。分片会被分成记录,而每条记录(也就是键值对)将由map进行处理。
我们本节还介绍了什么是RecordReader,工作过程以及RecordReader的类型。