python 绘制混淆矩阵(以遥感场景数据集UCM为例)
##
############################### 训练网络 #############################
以遥感图像场景分类为例,采用UC Merced数据集。
一、以ImageNet数据集下的预训练模型,采用ResNet-18网络模型对UCM数据集进行fine-tune。
在数据集训练上,按照一定的train-test比例,这里设置为50%-50%。训练10次,取平均值和标准差作为精度评价指标。
(1)参数设置(根据自己的路径进行配置)
# *_*coding: utf-8 *_*
# author --liming--
import os
########################### 数据划分参数 ############################
origion_path = 'F:\\my_project\\scene_classification\\scene_classification_dataset\\UCMerced_LandUse\\'
save_train_dir = 'F:\\my_project\\scene_classification\\paper_v1\\data\\RS_UC\\5_5\\train\\'
save_test_dir = 'F:\\my_project\\scene_classification\\paper_v1\\data\\RS_UC\\5_5\\test\\'
train_rate = 0.5
split_dataset_save_dir = 'F:\\my_project\\scene_classification\\paper_v1\\data\\RS_UC\\5_5\\'
########################### 网络训练参数 ##################################
project_path = os.getcwd()
resize = 256
crop_size = 224
classes_num = 21
train_batch_size = 48
test_batch_size = 48
epochs = 100
init_lr = 0.001
momentum = 0.9
log_interval = 10
stop_accuracy = 90.00
adjust_lr_epoch = 60
img_save_path = project_path + '/fig/'(2)数据划分代码
# *_*coding: utf-8 *_*
# Author --LiMing--
import os
import random
import shutil
def dataset_split(origion_path, save_train_dir, save_test_dir, train_rate):
# 定义复制文件函数
def copyFile(fileDir, class_name):
image_list = os.listdir(fileDir)
image_number = len(image_list)
train_number = int(image_number * train_rate)
train_sample = random.sample(image_list, train_number) # 从image_list中随机获取0.8比例的图像.
test_sample = list(set(image_list) - set(train_sample))
sample = [train_sample, test_sample]
# 复制图像到目标文件夹
for k in range(len(save_dir)):
if os.path.isdir(save_dir[k] + class_name):
for name in sample[k]:
shutil.copy(os.path.join(fileDir, name), os.path.join(save_dir[k] + class_name+'/', name))
else:
os.makedirs(save_dir[k] + class_name)
for name in sample[k]:
shutil.copy(os.path.join(fileDir, name), os.path.join(save_dir[k] + class_name+'/', name))
# 原始数据集路径
save_dir = [save_train_dir, save_test_dir]
# 数据集类别及数量
file_list = os.listdir(origion_path)
num_classes = len(file_list)
for i in range(num_classes):
class_name = file_list[i]
image_Dir = os.path.join(origion_path, class_name)
copyFile(image_Dir, class_name)
print('%s划分完毕!' % class_name)(3)数据集加载
# -*- coding: utf-8 -*-
# author ---liming---
import torch
import torchvision
from PIL import Image
import config
def data_train(train_dataset):
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((config.resize, config.resize), Image.BILINEAR),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(config.crop_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
train_data = torchvision.datasets.ImageFolder(root=train_dataset,
transform=train_transforms)
CLASS = train_data.class_to_idx
print('训练数据label与文件名的关系为:', CLASS)
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=config.train_batch_size,
shuffle=True)
return train_data, train_loader
def data_test(test_dataset):
test_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((config.resize, config.resize),Image.BILINEAR),
torchvision.transforms.CenterCrop(config.crop_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
test_data = torchvision.datasets.ImageFolder(root=test_dataset,
transform=test_transforms)
CLASS = test_data.class_to_idx
print('验证数据label与文件名的关系为:', CLASS)
test_loader = torch.utils.data.DataLoader(test_data,
batch_size=1,
shuffle=False)
return test_data, test_loader
if __name__ == '__main__':
data_train()
data_test()(4)训练函数
# *_*coding: utf-8 *_*
# author --liming--
import os
import shutil
import time
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torchvision.models as models
import matplotlib.pyplot as plt
import config
from data_load import data_train, data_test
from data_split import dataset_split
os.environ['CUDA_VISION_DEVICES'] = '0'
# 训练函数
def model_train(model, train_data_load, optimizer, loss_func, epoch, log_interval):
model.train()
correct = 0
train_loss = 0
total = len(train_data_load.dataset)
for i, (img, label) in enumerate(train_data_load, 0):
begin = time.time()
img, label = img.cuda(), label.cuda()
optimizer.zero_grad()
outputs = model(img)
loss = loss_func(outputs, label)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == label).sum()
if (i + 1) % log_interval == 0:
traind_total = (i + 1) * len(label)
acc = 100. * correct / traind_total
end = time.time()
print('Train Epoch: {} [{}/{} ({:.0f}%)]\t Loss: {:.6f}\t lr: {}\t Train_Acc: {:.6f}\t Speed: {}'.format(epoch,
i * len(img),
total,
100. * i / len(train_data_load),
loss.data.item(),
optimizer.param_groups[0]['lr'],
acc,
end - begin))
global_train_acc.append(acc)
def model_test(model, test_data_load, epoch, kk):
model.eval()
correct = 0
total = len(test_data_load.dataset)
for i, (img, label) in enumerate(test_data_load):
img, label = img.cuda(), label.cuda()
outputs = model(img)
_, pre = torch.max(outputs.data, 1)
correct += (pre == label).sum()
acc = correct.item() * 100. / (len(test_data_load.dataset))
# 记录最佳分类精度
global best_acc
if acc > best_acc:
best_acc = acc
print('\nTest Set: Accuracy: {}/{}, ({:.6f}%)\nBest_Acc: {}\n'.format(correct, total, acc, best_acc))
global_test_acc.append(acc)
if best_acc > config.stop_accuracy:
torch.save(model.state_dict(), str(kk+1) + '_ResNet34_BestScore_' + str(best_acc) + '.pth')
def show_acc_curv(ratio, kk):
# 训练准确率曲线的x、y
train_x = list(range(len(global_train_acc)))
train_y = global_train_acc
# 测试准确率曲线的x、y
# 每ratio个训练准确率对应一个测试准确率
test_x = train_x[ratio - 1::ratio]
test_y = global_test_acc
plt.title('M ResNet34 ACC')
plt.plot(train_x, train_y, color='green', label='training accuracy')
plt.plot(test_x, test_y, color='red', label='testing accuracy')
plt.legend()
plt.xlabel('iterations')
plt.ylabel('accs')
plt.savefig(config.img_save_path + 'acc_curv_' + str(kk+1) + '.jpg')
#plt.show()
def adjust_learning_rate(optimizer, epoch):
if epoch % config.adjust_lr_epoch == 0:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
if __name__ == '__main__':
# 按设定的划分比例,得到随机数据集,分别进行10次训练,然后计算其均值和方差.
for k in range(10):
best_acc = 0
global_train_acc = []
global_test_acc = []
# 如果k=0, 则表示对第一次随机划分进行训练.
dataset_split(config.origion_path, config.save_train_dir, config.save_test_dir, config.train_rate)
# 加载数据集
trainset, train_loader = data_train(config.save_train_dir)
testset, test_loader = data_test(config.save_test_dir)
print('\n数据加载完毕,开始训练\n')
cudnn.benchmark = True
# 加载模型
"""
# VGG16
model = models.vgg16(pretrained=True)
model.classifier[-1].out_features = config.classes_num
model = model.cuda()
"""
# ResNet
model = models.resnet18(pretrained=True)
fc_features = model.fc.in_features
model.fc = torch.nn.Linear(fc_features, config.classes_num)
model = model.cuda()
# 优化器与损失
optimizer = optim.SGD(model.parameters(), lr=config.init_lr, momentum=config.momentum)
loss_func = nn.CrossEntropyLoss().cuda()
start_time = time.time()
# 训练
for epoch in range(1, config.epochs+1):
print('----------------------第%s轮----------------------------' % epoch)
model_train(model, train_loader, optimizer, loss_func, epoch, config.log_interval)
model_test(model, test_loader, epoch, k)
adjust_learning_rate(optimizer, epoch)
end_time = time.time()
print('Train Speed Time:', end_time - start_time)
# 显示训练和测试曲线
ratio = len(trainset) / config.train_batch_size / config.log_interval
ratio = int(ratio)
show_acc_curv(ratio, k)
# 保存模型
#torch.save(model.state_dict(), 'resnet_fs_' + str(k+1) + '.pth')
## 清除数据文件夹中的文件
RS_path = config.split_dataset_save_dir
file_list = os.listdir(RS_path)
for m in range(len(file_list)):
shutil.rmtree(RS_path + file_list[m])
print('第{}次训练结束, 最佳分类精度为:{}'.format(k+1, best_acc))
print('--------------------------------------------------\n')
print('全部训练完毕!')训练好的模型存放格式为(第一轮训练的模型):1_ResNet34_BestScore_96.19047619047619.pth
###########################绘制混淆矩阵###############################
二、绘制混淆矩阵的函数
# _*_ coding: UTF-8 _*_
# Author: liming
import numpy as np
import matplotlib.pyplot as plt
# 绘制混淆矩阵函数
def plot_confusion_matrix(classes, cm, savename, title='Confusion Matrix'):
plt.figure(figsize=(15, 12), dpi=200)
np.set_printoptions(precision=2)
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.0f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('Actual label')
plt.xlabel('Predict label')
# offset the tick
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
# 显示混淆矩阵
# plt.show()
plt.savefig(savename, format='jpg')二、绘制混淆矩阵代码
# _*_ coding: UTF-8 _*_
# Author: liming
import torch
import numpy as np
import torchvision.models as models
from sklearn.metrics import confusion_matrix
import config
from data_load import data_test
from utils import plot_confusion_matrix
# 模型权重和类别标签
weight_path = 'F:\\my_project\\scene_classification\\paper_v1\\1_ResNet34_BestScore_96.28571428571429.pth'
classes = ['agricultural', 'airplane', 'baseballdiamond', 'beach', 'buildings', 'chaparral', 'denseresidential',
'forest', 'freeway', 'golfcourse', 'harbor', 'intersection', 'mediumresidential',
'mobilehomepark', 'overpass', 'parkinglot', 'river', 'runway', 'sparseresidential',
'storagetanks', 'tenniscourt']
def LoadNet(weight_path):
net = models.resnet18(pretrained=False)
fc_features = net.fc.in_features
net.fc = torch.nn.Linear(fc_features, config.classes_num)
net.load_state_dict(torch.load(weight_path))
net.eval()
net.cuda()
return net
# 导入测试数据集
testset, test_loader = data_test(config.save_test_dir)
print('\n测试数据加载完毕\n')
true_label = []
pred_label = []
# 加载模型
model = LoadNet(weight_path)
for batch_idx, (image, label) in enumerate(test_loader):
image, label = image.cuda(), label.cuda()
output = model(image)
pred = output.data.max(1, keepdim=True)[1]
prediction = pred.squeeze(1)
prediction = prediction.cpu().numpy()
label = label.cpu().numpy()
print('输入图像的真实标签为:{}, 预测标签为:{}'.format(label[0]+1, prediction[0]+1))
true_label.append(label[0]+1)
pred_label.append(prediction[0]+1)
# 计算混淆矩阵并绘图
cm = confusion_matrix(true_label, pred_label)
plot_confusion_matrix(classes, cm, 'confusion_matrix_96.jpg', title='confusion matrix')三、混淆矩阵结果
(1)未归一化的混淆矩阵图
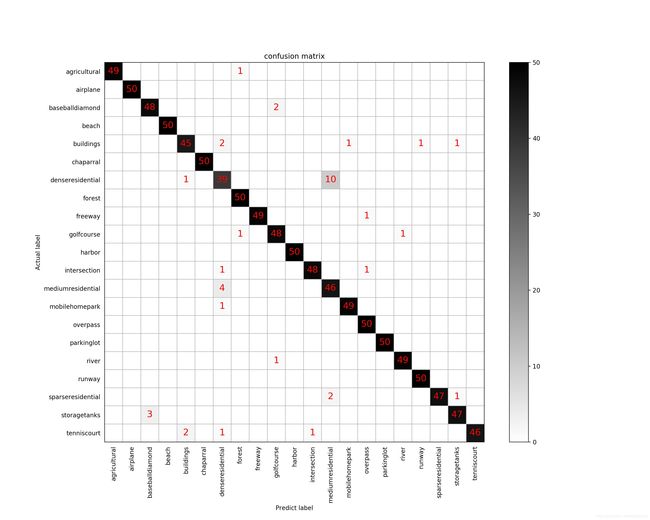
(2)归一化后的混淆矩阵图

完毕!