PSPNet 摸索(一)
补充
PASCAL VOC Challenge performance evaluation and download server
http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?cls=mean&challengeid=11&compid=6&submid=14249#KEY_Bayesian%20FCN
PSPNet的源码是在cudnn v4版本上运行的,降版本好像可以,我的是cudnn v5,知乎上很多人都跪在这一步,不过在github的issus里有PSPNet-cudnn v5的代码,是别人修改作者的源码放出来的,如果主机不支持可以换这里的代码:https://github.com/BassyKuo/PSPNET-cudnn5
不过我是通过修改原作者的代码,也能在自己的主机上运行;
图1:这里给出PSPNet的简要概述。给定输入图像(a),首先使用CNN得到最后一个卷积图层(b)的特征映射,然后应用金字塔解析模块收集不同的子区域表示,然后进行上采样和连接层以形成(c)中包含本地和全局上下文信息的最终特征表征。最后,之前得到的特征表征被反馈回到卷积层以获得最终的每个像素的预测(d)。
摘要
场景分析对于无约束的开放、多样化场景具有很大挑战性。在作者的Paper中,作者利用通过其金字塔池模块和提出的金字塔场景分析网络(PSPNet)获得基于不同区域的上下文聚合的全局上下文信息的能力。文中给出的全局先验表示法对于在场景解析任务中产生高质量的结果是有效的,而PSPNet为像素级预测任务提供了一个更好的框架。所提出的方法在各种数据集上实现了最先进的性能。它在ImageNet 2016场景解析挑战,PASCAL VOC 2012基准测试和Cityscapes基准测试中名列第一。并且PSPNet产生了新的记录,在PASCAL VOC 2012中的mIoU准确率为85.4%,在Cityscapes中准确率为80.2%。
记录更新
https://www.youtube.com/watch?v=qWl9idsCuLQ
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
https://www.youtube.com/watch?v=rB1BmBOkKTw&feature=youtu.be
Pyramid Scene Parsing Network (CVPR 2017)
https://www.youtube.com/watch?v=BNE1hAP6Qho
CASENet: Deep Category-Aware Semantic Edge Detection
RefineNet Results on the CityScapes Dataset
https://www.youtube.com/watch?v=L0V6zmGP_oQ
DeepLab v2
https://bitbucket.org/aquariusjay/deeplab-public-ver2
Introduction
DeepLab is a state-of-art deep learning system for semantic image segmentation built on top of Caffe.
It combines (1) atrous convolution to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks, (2) atrous spatial pyramid pooling to robustly segment objects at multiple scales with filters at multiple sampling rates and effective fields-of-views, and (3) densely connected conditional random fields (CRF) as post processing.
This distribution provides a publicly available implementation for the key model ingredients reported in our latest arXiv paper. This version also supports the experiments (DeepLab v1) in our ICLR’15. You only need to modify the old prototxt files. For example, our proposed atrous convolution is called dilated convolution in CAFFE framework, and you need to change the convolution parameter “hole” to “dilation” (the usage is exactly the same). For the experiments in ICCV’15, there are some differences between our argmax and softmax_loss layers and Caffe’s. Please refer to DeepLabv1 for details.
DeepLab是一个先进的深度学习系统,用于在Caffe之上构建语义图像分割。它结合了
(1) 无限卷积atrous convolution 以明确控制在深度卷积神经网络内计算特征响应的分辨率,
(2) atrous spatial空间金字塔积累池,以多个采样率和有效场的滤波器在多个尺度上鲁棒地分割对象 - (3)densely connected conditional random fields密集连接的条件随机场(CRF)作为后处理。
https://github.com/xmyqsh/deeplab-v2
这是CSDN上关于deeplab-v2的配置的参考链接:
【1】DeepLab V2安装配置
【2】图像语义分割:从头开始训练deeplab v2系列之二【VOC2012数据集】
【3】Deeplab v2 调试全过程(Ubuntu 16.04+cuda8.0)
【4】语义分割 - 数据集准备
下面是自己根据以上链接教程学习后的配置过程,使用的环境是ubuntu14.04+cuda8.0+cudnn5.1
1、安装Matio
下载 matio
我下载的是matio-1.5.12
进入matio-1.5.12文件夹:
cd matio-1.5.12
chmod a+x configure
./configure
make
make check
sudo make install
sudo ldconfig2、安装wget
安装 wget
sudo pip install wget 出错
按照下面的命令成功:
pip install –upgrade pip –user
pip install –upgrade setuptools –user
sudo pip install wget$ sudo pip install wget
Downloading/unpacking wget
Downloading wget-3.2.zip
Running setup.py (path:/tmp/pip_build_root/wget/setup.py) egg_info for package wget
Installing collected packages: wget
Running setup.py install for wget
Could not find .egg-info directory in install record for wget
Successfully installed wget
Cleaning up...3、安装deeplab-v2
这里安装的过程跟caffe的配置过程类似
进入deeplab-v2文件夹
将Makefile.config.example根据自己的需要更改下,更改完重命名为Makefile.config
在Makefile.config文件中可以选择开启cuda加速,定义python等的路径,指定opencv版本,如果有opencv2和opencv3多版本安装caffe等,也可以通过pkd-config来指定opencv的版本完成编译;
make all -j4 #这里 -j 视自己的主机而定
make test -j4
make runtest -j4
make pycaffe#上述编译过程有问题可以自行查询caffe编译-csdn上的博客
#然后添加环境变量
sudo gedit /etc/profile
#添加
export PYTHONPATH=/home/relaybot/mumu/slam/deeplab-v2/python:$PYTHONPATH
source /etc/profile #使环境变量生效
然后进入python文件夹
python
>>>import caffe
>>> #无反应说明配置成功
>>>exit() #退出4、安装PSPNet出现的问题
issues:https://github.com/hszhao/PSPNet/issues/10
relaybot@ubuntu:~/mumu/slam/PSPNet$ make all -j4
CXX .build_release/src/caffe/proto/caffe.pb.cc
CXX src/caffe/syncedmem.cpp
CXX src/caffe/parallel.cpp
CXX src/caffe/internal_thread.cpp
In file included from ./include/caffe/util/device_alternate.hpp:40:0,
from ./include/caffe/common.hpp:19,
from src/caffe/syncedmem.cpp:1:
./include/caffe/util/cudnn.hpp: In function ‘void caffe::cudnn::createPoolingDesc(cudnnPoolingStruct**, caffe::PoolingParameter_PoolMethod, cudnnPoolingMode_t*, int, int, int, int, int, int)’:
./include/caffe/util/cudnn.hpp:127:41: error: too few arguments to function ‘cudnnStatus_t cudnnSetPooling2dDescriptor(cudnnPoolingDescriptor_t, cudnnPoolingMode_t, cudnnNanPropagation_t, int, int, int, int, int, int)’
pad_h, pad_w, stride_h, stride_w));
^
./include/caffe/util/cudnn.hpp:15:28: note: in definition of macro ‘CUDNN_CHECK’
cudnnStatus_t status = condition; \
^
In file included from ./include/caffe/util/cudnn.hpp:5:0,
from ./include/caffe/util/device_alternate.hpp:40,
from ./include/caffe/common.hpp:19,
from src/caffe/syncedmem.cpp:1:
/usr/local/cuda/include/cudnn.h:803:27: note: declared here
cudnnStatus_t CUDNNWINAPI cudnnSetPooling2dDescriptor(
^
make: *** [.build_release/src/caffe/syncedmem.o] Error 1
make: *** Waiting for unfinished jobs....
In file included from ./include/caffe/util/device_alternate.hpp:40:0,
from ./include/caffe/common.hpp:19,
from ./include/caffe/blob.hpp:8,
from ./include/caffe/caffe.hpp:7,
from src/caffe/parallel.cpp:12:
./include/caffe/util/cudnn.hpp: In function ‘void caffe::cudnn::createPoolingDesc(cudnnPoolingStruct**, caffe::PoolingParameter_PoolMethod, cudnnPoolingMode_t*, int, int, int, int, int, int)’:
./include/caffe/util/cudnn.hpp:127:41: error: too few arguments to function ‘cudnnStatus_t cudnnSetPooling2dDescriptor(cudnnPoolingDescriptor_t, cudnnPoolingMode_t, cudnnNanPropagation_t, int, int, int, int, int, int)’
pad_h, pad_w, stride_h, stride_w));
^
./include/caffe/util/cudnn.hpp:15:28: note: in definition of macro ‘CUDNN_CHECK’
cudnnStatus_t status = condition; \
^
In file included from ./include/caffe/util/cudnn.hpp:5:0,
from ./include/caffe/util/device_alternate.hpp:40,
from ./include/caffe/common.hpp:19,
from ./include/caffe/blob.hpp:8,
from ./include/caffe/caffe.hpp:7,
from src/caffe/parallel.cpp:12:
/usr/local/cuda/include/cudnn.h:803:27: note: declared here
cudnnStatus_t CUDNNWINAPI cudnnSetPooling2dDescriptor(
^
make: *** [.build_release/src/caffe/parallel.o] Error 1
In file included from ./include/caffe/util/device_alternate.hpp:40:0,
from ./include/caffe/common.hpp:19,
from ./include/caffe/internal_thread.hpp:4,
from src/caffe/internal_thread.cpp:4:
./include/caffe/util/cudnn.hpp: In function ‘void caffe::cudnn::createPoolingDesc(cudnnPoolingStruct**, caffe::PoolingParameter_PoolMethod, cudnnPoolingMode_t*, int, int, int, int, int, int)’:
./include/caffe/util/cudnn.hpp:127:41: error: too few arguments to function ‘cudnnStatus_t cudnnSetPooling2dDescriptor(cudnnPoolingDescriptor_t, cudnnPoolingMode_t, cudnnNanPropagation_t, int, int, int, int, int, int)’
pad_h, pad_w, stride_h, stride_w));
^
./include/caffe/util/cudnn.hpp:15:28: note: in definition of macro ‘CUDNN_CHECK’
cudnnStatus_t status = condition; \
^
In file included from ./include/caffe/util/cudnn.hpp:5:0,
from ./include/caffe/util/device_alternate.hpp:40,
from ./include/caffe/common.hpp:19,
from ./include/caffe/internal_thread.hpp:4,
from src/caffe/internal_thread.cpp:4:
/usr/local/cuda/include/cudnn.h:803:27: note: declared here
cudnnStatus_t CUDNNWINAPI cudnnSetPooling2dDescriptor(
^
make: *** [.build_release/src/caffe/internal_thread.o] Error 1
#这里是替换cudnn的一些相关文件
relaybot@ubuntu:~/mumu/slam/PSPNet$ cp ../deeplab-v2/include/caffe/util/cudnn.hpp include/caffe/util/cudnn.hpp
relaybot@ubuntu:~/mumu/slam/PSPNet$ cp ../deeplab-v2/include/caffe/layers/cudnn_* include/caffe/layers/
relaybot@ubuntu:~/mumu/slam/PSPNet$ cp ../deeplab-v2/src/caffe/layers/cudnn_* src/caffe/layers/
**issues:error: function "atomicAdd(double *, double)" has already been defined
https://stackoverflow.com/questions/39274472/error-function-atomicadddouble-double-has-already-been-defined**
./include/caffe/common.cuh(9): error: function "atomicAdd(double *, double)" has already been defined
1 error detected in the compilation of "/tmp/tmpxft_00001fe1_00000000-5_interp.cpp4.ii".
make: *** [.build_release/cuda/src/caffe/util/interp.o] Error 1
make: *** Waiting for unfinished jobs....修改commmon.cuh文件
I finally got it working with the help of @Robert Crovella's comment.
I had to modify the file common.cuh from the DeepLab_v2 master branch in the following way: #ifndef CAFFE_COMMON_CUH_
#define CAFFE_COMMON_CUH_
#include 安装PSPNet
make all -j4
make pycaffe
#添加环境变量
#不要忘记这一步编译matlab-caffe
下载链接:(已经保存到我的云盘空间)
http://yunpan.taobao.com/s/ZFLGQjNABU#/
提取码:dxBxMJ**
数据集:camvid、The Cityscapes
https://blog.csdn.net/u010069760/article/details/77847595
Pyramid Scene Parsing Network 学习0420
https://hszhao.github.io/projects/pspnet/ 主页
http://groups.csail.mit.edu/vision/datasets/ADE20K/ 数据集
制作自己的caffe,cmake
build中出现问题:
In file included from /home/relaybot/mumu/slam/PSPNet/include/caffe/caffe.hpp:7:0,
from /home/relaybot/mumu/slam/pspnet_1/src/pspnet.cpp:6:
/home/relaybot/mumu/slam/PSPNet/include/caffe/blob.hpp:9:34: fatal error: caffe/proto/caffe.pb.h: No such file or directory
#include "caffe/proto/caffe.pb.h"
^寻找自己的PSPNet中的 include/caffe/ 中没有proto文件夹
参照https://github.com/NVIDIA/DIGITS/issues/105
When I ran make all --jobs=4 I got:
In file included from ./include/caffe/util/device_alternate.hpp:40:0,
from ./include/caffe/common.hpp:19,
from ./include/caffe/blob.hpp:8,
from ./include/caffe/net.hpp:10,
from src/caffe/solver.cpp:7:
./include/caffe/util/cudnn.hpp:8:34: fatal error: caffe/proto/caffe.pb.h: No such file or directory
#include "caffe/proto/caffe.pb.h"
^
compilation terminated.
I solved this by running:
$ protoc src/caffe/proto/caffe.proto --cpp_out=.
$ mkdir include/caffe/proto
$ mv src/caffe/proto/caffe.pb.h include/caffe/proto
同样参照上述指令,重新编译caffe-PSPNet
make all -j4
make test -j4http://manutdzou.github.io/2016/05/29/master-note.htmlAR -o .build_release/lib/libcaffe.a
LD -o .build_release/lib/libcaffe.so.1.0.0-rc3
/usr/bin/ld: 找不到 -lhdf5_serial_hl
/usr/bin/ld: 找不到 -lhdf5_serial
collect2: error: ld returned 1 exit status
make: *** [.build_release/lib/libcaffe.so.1.0.0-rc3] 错误 1
zmz@zmz-inin:~/zhaolin_2018/PSPNET-cudnn5$
cd /usr/lib/x86_64-linux-gnu
\然后根据情况执行下面两句:
sudo ln -s libhdf5_serial.so.10.1.0 libhdf5.so
sudo ln -s libhdf5_serial_hl.so.10.0.2 libhdf5_hl.so
https://blog.csdn.net/madman_z/article/details/70136104
解决方法
在Makefile.config文件的第85行,添加 /usr/include/hdf5/serial/ 到 INCLUDE_DIRS,也就是把下面第一行代码改为第二行代码。
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/
在Makefile文件的第173行,把 hdf5_hl 和hdf5修改为hdf5_serial_hl 和 hdf5_serial,也就是把下面第一行代码改为第二行代码。
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial 实际我的解决方法是:
改Makefile:
##############################
# Derive include and lib directories
##############################
CUDA_INCLUDE_DIR := $(CUDA_DIR)/include
CUDA_LIB_DIR :=
# add /lib64 only if it exists
ifneq ("$(wildcard $(CUDA_DIR)/lib64)","")
CUDA_LIB_DIR += $(CUDA_DIR)/lib64
endif
CUDA_LIB_DIR += $(CUDA_DIR)/lib
INCLUDE_DIRS += $(BUILD_INCLUDE_DIR) ./src ./include
ifneq ($(CPU_ONLY), 1)
INCLUDE_DIRS += $(CUDA_INCLUDE_DIR)
LIBRARY_DIRS += $(CUDA_LIB_DIR)
LIBRARIES := cudart cublas curand
endif
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5PSPNet python 运行记录
github上给出的实际效果是这样的:
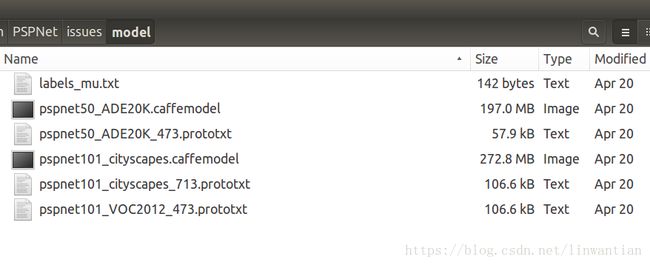
然后我们下载github上的model和利用源码中的网络结构定义文件
先给出demo的py文件:
我们新建一个文件夹demo放在PSPNet下面,/demo/model里面放模型
注意修改主函数中的:
input_file = "/home/relaybot/mumu/slam/dataset/ade20k/5.png"
output_file = "/home/relaybot/mumu/slam/dataset/ade20k/5_rs.png"然后注意_MAX_DIM = 473
这里如果输入图片长和宽都小于473,则输出图片的大小维持不变;如果大于473,则其尺寸按比例缩小
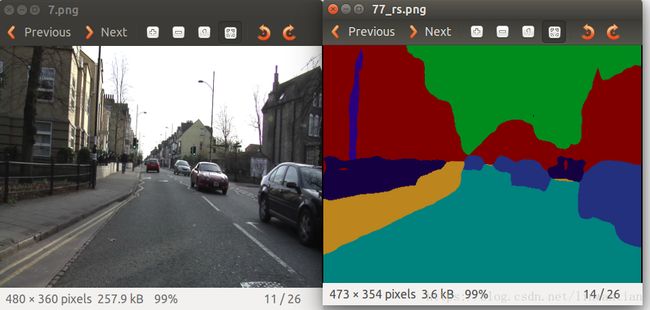
利用AEK20数据集,此demo运行的结果如图:
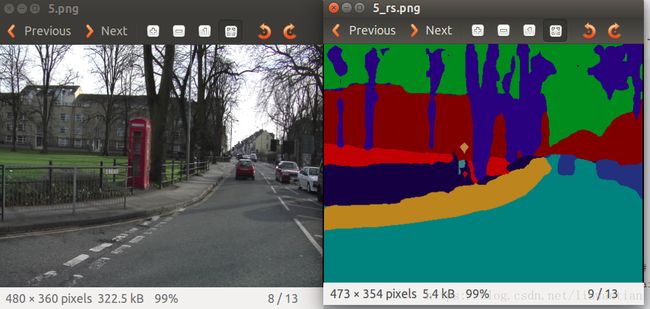
如果是要运行cityscapes数据集,在笔记本上显卡不够用,直接崩溃了~~~
但是实际上这里的demo比较简单粗暴,如果真要运行cityscapes数据集,应该按照github上按照matlab,之后会花时间继续摸索,本周到此结束~
import sys
import time
import getopt
import os
import numpy as np
from PIL import Image as PILImage
# Path of the Caffe installation.
_CAFFE_ROOT = "../"
# Model definition and model file paths
_MODEL_DEF_FILE = "model/pspnet50_ADE20K_473.prototxt" # Contains the network definition
_MODEL_FILE = "model/pspnet50_ADE20K.caffemodel" # Contains the trained weights.
sys.path.insert(0, _CAFFE_ROOT + "python")
import caffe
_MAX_DIM = 473
def get_palette(num_cls):
""" Returns the color map for visualizing the segmentation mask.
Args:
num_cls: Number of classes
Returns:
The color map
"""
n = num_cls
palette = [0] * (n * 3)
for j in xrange(0, n):
lab = j
palette[j * 3 + 0] = 0
palette[j * 3 + 1] = 0
palette[j * 3 + 2] = 0
i = 0
while lab:
palette[j * 3 + 0] |= (((lab >> 0) & 1) << (7 - i))
palette[j * 3 + 1] |= (((lab >> 1) & 1) << (7 - i))
palette[j * 3 + 2] |= (((lab >> 2) & 1) << (7 - i))
i += 1
lab >>= 3
return palette
def crfrnn_segmenter(model_def_file, model_file, gpu_device, inputs):
""" Returns the segmentation of the given image.
Args:
model_def_file: File path of the Caffe model definition prototxt file
model_file: File path of the trained model file (contains trained weights)
gpu_device: ID of the GPU device. If using the CPU, set this to -1
inputs: List of images to be segmented
Returns:
The segmented image
"""
assert os.path.isfile(model_def_file), "File {} is missing".format(model_def_file)
assert os.path.isfile(model_file), ("File {} is missing. Please download it using "
"./download_trained_model.sh").format(model_file)
if gpu_device >= 0:
caffe.set_device(gpu_device)
caffe.set_mode_gpu()
else:
caffe.set_mode_cpu()
net = caffe.Net(model_def_file, model_file, caffe.TEST)
num_images = len(inputs)
num_channels = inputs[0].shape[2]
assert num_channels == 3, "Unexpected channel count. A 3-channel RGB image is exptected."
caffe_in = np.zeros((num_images, num_channels, _MAX_DIM, _MAX_DIM), dtype=np.float32)
for ix, in_ in enumerate(inputs):
caffe_in[ix] = in_.transpose((2, 0, 1))
start_time = time.time()
out = net.forward_all(**{net.inputs[0]: caffe_in})
end_time = time.time()
print("Time taken to run the network: {:.4f} seconds".format(end_time - start_time))
predictions = out[net.outputs[0]]
return predictions[0].argmax(axis=0).astype(np.uint8)
def run_crfrnn(input_file, output_file, gpu_device):
""" Runs the CRF-RNN segmentation on the given RGB image and saves the segmentation mask.
Args:
input_file: Input RGB image file (e.g. in JPEG format)
output_file: Path to save the resulting segmentation in PNG format
gpu_device: ID of the GPU device. If using the CPU, set this to -1
"""
input_image = 255 * caffe.io.load_image(input_file)
input_image = resize_image(input_image)
image = PILImage.fromarray(np.uint8(input_image))
image = np.array(image)
palette = get_palette(256)
#PIL reads image in the form of RGB, while cv2 reads image in the form of BGR, mean_vec = [R,G,B]
mean_vec = np.array([123.68, 116.779, 103.939], dtype=np.float32)
mean_vec = mean_vec.reshape(1, 1, 3)
# Rearrange channels to form BGR
im = image[:, :, ::-1]
# Subtract mean
im = im - mean_vec
# Pad as necessary
cur_h, cur_w, cur_c = im.shape
pad_h = _MAX_DIM - cur_h
pad_w = _MAX_DIM - cur_w
im = np.pad(im, pad_width=((0, pad_h), (0, pad_w), (0, 0)), mode='constant', constant_values=0)
# Get predictions
segmentation = crfrnn_segmenter(_MODEL_DEF_FILE, _MODEL_FILE, gpu_device, [im])
segmentation = segmentation[0:cur_h, 0:cur_w]
output_im = PILImage.fromarray(segmentation)
output_im.putpalette(palette)
output_im.save(output_file)
def resize_image(image):
""" Resizes the image so that the largest dimension is not larger than 500 pixels.
If the image's largest dimension is already less than 500, no changes are made.
Args:
Input image
Returns:
Resized image where the largest dimension is less than 500 pixels
"""
width, height = image.shape[0], image.shape[1]
max_dim = max(width, height)
if max_dim > _MAX_DIM:
if height > width:
ratio = float(_MAX_DIM) / height
else:
ratio = float(_MAX_DIM) / width
image = PILImage.fromarray(np.uint8(image))
image = image.resize((int(height * ratio), int(width * ratio)), resample=PILImage.BILINEAR)
image = np.array(image)
return image
def main(argv):
""" Main entry point to the program. """
input_file = "/home/relaybot/mumu/slam/dataset/ade20k/5.png"
output_file = "/home/relaybot/mumu/slam/dataset/ade20k/5_rs.png"
gpu_device = 0 # Use -1 to run only on the CPU, use 0-3[7] to run on the GPU
# try:
# opts, args = getopt.getopt(argv, 'hi:o:g:', ["ifile=", "ofile=", "gpu="])
# except getopt.GetoptError:
# print("crfasrnn_demo.py -i -o -g ")
# sys.exit(2)
# for opt, arg in opts:
# if opt == '-h':
# print("crfasrnn_demo.py -i -o -g ")
# sys.exit()
# elif opt in ("-i", "ifile"):
# input_file = arg
# elif opt in ("-o", "ofile"):
# output_file = arg
# elif opt in ("-g", "gpudevice"):
# gpu_device = int(arg)
print("Input file: {}".format(input_file))
print("Output file: {}".format(output_file))
if gpu_device >= 0:
print("GPU device ID: {}".format(gpu_device))
else:
print("Using the CPU (set parameters appropriately to use the GPU)")
run_crfrnn(input_file, output_file, gpu_device)
if __name__ == "__main__":
main(sys.argv[1:])另外给出一些demo的例子: 分别给出ADE20K的图片和我在自己的电脑上得到的results