reference1: 邹sir的rh442系统调优课程
系统调优
[TOC]
reference1: 邹sir的调优课程
推荐书目:
基本概念
调优是一门黑色艺术
调优方法(由好到差):
架构 -> 硬件 -> 软件配置(SQL调优)
关闭不需要的服务
换算单位:
| KB的单位: | KiBi的单位 : |
|---|---|
| 1000 | 1024 |
sosreport # 会在/tmp下生成报告文件
系统内核帮助手册:
# 软件包: kernel-doc, 安装好之后可在以下目录查询:
/usr/share/doc/kernel-doc-*/Documentation/
# 只有redhat7光盘无此包
grep -irn ip_forwrad 目录 # 可利用此命令查你需要的参数在哪个文件中
如何监控系统
1. iostat
yum whatprovides "*/sar"
yum -y install sysstat
iostat # 展示系统从开机到现在的统计信息(静态, 平均值且非实时), 包括CPU, 磁盘
%user # 应用程序所占的百分比
%nice # 调整应用程序的优先级从而使CPU不停切换进程,消耗系统资源所占的百分比
%system # 内核所占的百分比
%iowait # IO相关百分比
%steal # 虚拟化所占百分比
%idle # 空闲率


| tps | kB_read/s | kB_wrtn/s | kB_read | kB_wrtn |
|---|---|---|---|---|
| 22 | 444 | 451 | 5963560 | 6060483 |
| 每秒传输的io请求数 | 开机到现在的读 |
从上面的表格中提供的数据可以计算出系统每个IO大小的平均值: ( 444 + 451 ) / 22 = 40, 根据此处计算出的结果可以获得系统内的IO是小IO (小于64K)还是大IO (大于64K), 从而进行对应的调优
# 实例1: 只显示设备的统计信息
iostat -d 2 6
# 实例2: 显示指定的磁盘sda和sdb
iostat -x sda sdb 2 6
# 实例3: 显示制定设备的分区的统计信息
iostat -p sda 2 6
# 实例4:
iostat -k|-m # 单位
2. iotop
当系统的%iowait值非常高时, 说明系统IO等待时间非常高, 此时可用iotop查看哪个程序导致io负载高:
iotop # simple top-like I/O monitor

dd if=/dev/zero of=/tmp/test.txt bs=1M count=2048 oflag=direct
# 此命令的if和of本身写于内存
# oflag=direct 直接写入磁盘

3. 衡量硬盘的性能指标
- IOPS: 每秒处理的IO次数
- 随机的小IO一般用此参数衡量
- 用途: 数据库(OLTP, 联机事务处理): 例如银行的每次交易
- 带宽: 每秒处理的数据大小
- 顺序的大IO
- 用途: 1. 备份数据; 2. 视频监控
下为实例:
| 硬盘类型 | IOPS/延迟 | 带宽 |
|---|---|---|
| SSD | > 2000/1ms | 100MB/s |
| 15K HHD | 200/10ms | 30MB/s |
4. sar
Collect, report, or save system activity information
可查看之前某个时刻和当前时刻的系统信息, 此命令比较全面, 可以实时查看系统的cpu, 内存, 磁盘, swap信息
alias sar='LANG=C sar' # 设置显示的时间格式为24小时制
sar -u # 查看实时的cpu信息, 与iostat的不同之处在于iostat查看到的是开机到现在的
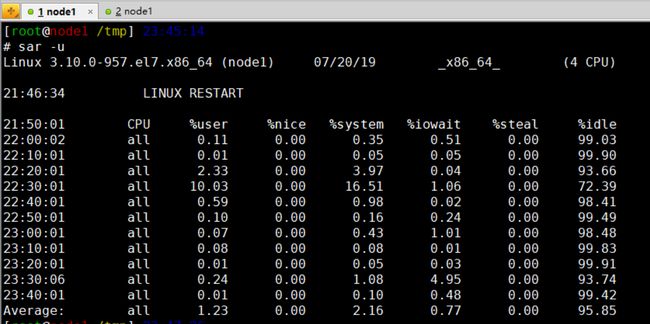
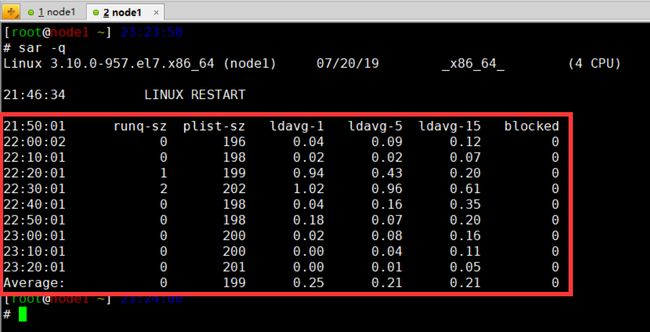
iostat -q # 查看队列长度和1分钟, 5分钟, 15分钟的平均负载
sar -r # 查看内存, 类似free -m

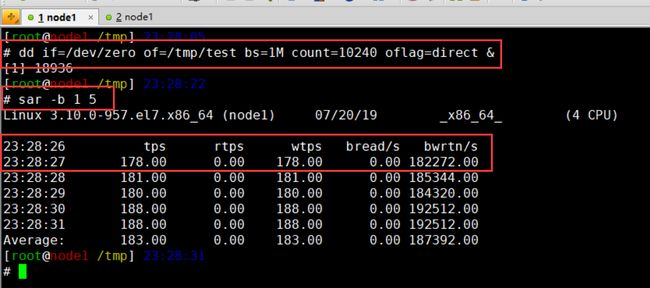
sar -b 1 5 # 查看硬盘设备的实时io数, 注意和iostat之间的区别, 首先单位就不一样
sar -S # 查看swap的信息
sar -d 1 5 # 显示主次设备编号(利用ll /dev/sd* 可查看对应关系)
sar -d -p 1 5 # 显示对应设备名的设备
sar -r -f /var/log/sa/sa08 # /etc/cron.d/sysstat文件里设置系统每隔10分钟, 会将系统状态记录到/var/log/sa/sa${DATE}文件中, 但这些文件需要通过-f选项指定file才能查看, 以及在每天的23:53会执行命令记录系统状态并记录到/var/log/sa/sar${DATE}文件中, 这些文件通过less可以直接查看
sar -d -p -s 19:00:00 -e 19:40:00 -f /var/log/sa/sa14
-s [hh:mm:ss] # start time
-e # end time
-A # 指定显示系统的所有信息
sar -n DEV 1 5 # 查看network信息, DEV选项表是查看network devices信息
sar -u 1 5 -o /tmp/sar.data # 将cpu信息收集并存入/tmp/sar.data文件中, 查看时需用-f指定文件
time cp -r /etc/ /tmp # 计时
watch -n 1 free -m # 每秒监视一次
vmstat # 查看进程, 内存, swap, io, system, cpu的统计信息
bigmem 500 # 申请使用500M内存
# top命令解释:
cp -a /etc/ /tmp/ # 输入命令后使用ctrl + z 暂停
top # 然后用top命令查看时会发现后台的Tasks中会有一个stopped显示, 就是刚才暂停的任务
5. pmstat
yum -y install pcp pcp-gui
# 安装这两个包时可能报错: UnicodeDecodeError: 'ascii' codec can't decode byte 0xc2
# 解决方法: https://blog.51cto.com/dihuo/1568438
# 在/usr/share/yum-cli/yummain.py和/usr/lib64/python2.7/encodings/utf_8.py中加入三行
import sys
reload(sys)
sys.setdefaultencoding('gbk')
ssh root@ip -X # 让ssh支持图形化界面展示
6. gunplot
Queue Theory
根据下面的公式可以判断系统的瓶颈在哪里!
调优思想的起源, 利特尔定律: L = A * W
-
L: 队列长度, 系统有多少请求在等待
- 队列位于内存的buffer中
- 长: 消耗内存, 但可重新整合IO, 然后写入磁盘, 减少磁盘的寻道次数
- 短: 优化内存, 但数据写入磁盘时寻道次数多
- 队列位于内存的buffer中
A: 到达率, 每秒来的请求数
W: 等待时间, 每个请求需要多长时间处理
cat /proc/meminfo | grep Dirty # 查看内存中的脏数据
sysctl -a | grep dirty # 其中有个内核参数: vm.dirty_expire_centisecs = 3000
# 用来设定脏数据的过期时长: 3000 (百分之一秒)
# 30s后内存中的脏数据写回磁盘, 可临时将此值调大:
sysctl -w vm.dirty_expire_centisecs=6000
# 当数据都是随机的小IO时, 让其充分整合以提升性能
# 如果要永久生效:
vi /etc/sysctl.conf
vm.dirty_expire_centisecs=6000 # 添加此项
sysctl -p # 重载配置文件: sysctl.conf和sysctl.d/*.conf
w = Q + S
- Q: 队列等待时间
- S: 服务时间
类比与去银行处理业务: 整个等待时间W = 银行排队时间Q + 银行业务人员处理的时间S
W = Q + ( T_sys + T_user )
- T_sys: 内核占用的时间 (打印机, 电脑特别慢)
- T_user: 应用程序占用的时间 (业务员对业务不熟练)
# 实例:
time cp -r /etc/ /data/
real 0m14.379s
user 0m0.003s
sys 0m0.541s
# T_sys + T_user = 0.544s, 那多的13.835s去哪里了呢? 多的时间其实是Q的时间
内核模块调优
主要对以下目录进行调优:
- /proc: 主要是对内核, 文件系统, 进程, 网络调优
- /sys: 主要是对设备, 驱动, 模块的调优
首先强调一点: 所有内核模块都必须匹配内核版本! 内核模块对内核版本非常敏感, 差一个小版本都不行!
lsmod # 查看系统当前加载的模块
modprobe 模块名 # 加载模块
modprobe -r 模块名 # 卸载模块
modprobe ext4
# 随便在任意目录下使用modprobe 模块名加载模块, 为什么能够加载成功?
/lib/modules/$(uname -r)/modules.dep # 加载模块时读会取此文件中记载的模块路径
/boot/initrd-2.6.18-208.el5.img # ram disk, gzip格式压缩的文件, 内含驱动, 安装系统时被读到内存
zcat initrd-...img | cpio -id # 可将此文件中的内容解压至当前目录
cpio # 将文件复制到存档包, 也可以从存档包中复制出文件
-i # 解压
-d # 目录
# 解压后的lib/*.ko为各种驱动
8k: 如何将特定驱动添加到initrd中?
# 1. 官网下载驱动
# 2. 编译驱动: /lib/modules/$(uname -r)/kernel/下新建目录, 然后build
# 3. 备份原有的/boot/initrd-2.6.18-208.el5.img文件
# 4. mkinitrd --with=lsi2008 --force /boot/initrd-2.6.18-208.el5.img 2.6.18-208.el5
# 模块名 # 此处不可接绝对路径,
# 且内核版本要与上面编
# 译的驱动放置的内核目
# 录是同一个才行
模块参数调优 (parm)
# 系统真实放置模块的位置:
/lib/modules/$(uname -r)/kernel/drivers/
lsmod ext4
# 模块名 模块大小 模块使用次数 模块描述
Module Size Used by
ext4 579979 0
mbcache 14958 1 ext4
jbd2 107478 1 ext4
modinfo ext4 # 查看模块的详细信息
# 部分模块有一个参数: parm, 可用于调优
# redhat5有/etc/modprobe.conf, 可直接在此文件内添加内容:
options snd-card-0 index=0 # 调整模块参数
# 但redhat6开始需要在/etc/modprobe.d/下新建*.conf文件, 用于调优模块参数:
vi /etc/modprobe.d/st.conf
options st buffer_kbs=128 # 特别注意, 模块名和参数不可以写错!
# 修改模块参数后如何验证参数生效?
# 方法一:
# 修改后重载st模块, 然后去/sys/目录下查看参数是否生效
# 方法二:
modprobe --showconfig 模块名
8k: 重建ram disk文件, 解决P2V问题
- P2V问题: 物理机迁移到虚拟机时系统无法启动
# redhat5, 6
mkinitrd /boot/initrd-2.6.18-208.el5xen.img $(uname -r)
# redhat7
dracut --add-drivers "module1 module2 ..." /boot/initramfs-3.10.0-123.el7.x86_64.img $(uname -r)
--add-drivers # 可添加模块
# 如何查看redhat7的ram disk文件中的内容:
/usr/lib/dracut/skipcpio /tmp/initramfs-...img | zcat | cpio -id
小白式系统调优 (redhat7)
tune: n,v 曲调; 调整
/usr/lib/tuned/下有可调参数
yum -y install tuned
systemctl enable tuned && systemctl start tuned
tuned-adm list # 列出所有可以调优的参数
tuned-adm profile throughput-performance # 系统调优, 选用throughput-performance
tuned-adm list # 马上生效且重启有效
自定义某些配置:
cd /usr/lib/tuned/
cp -r throughput-performance/ my442 # 新建自定义目录
vi my442/tuned.conf # 修改配置你需要的参数
tuned-adm profile mu442 # 让你配置的参数生效
系统资源限制调优
# 编辑完limit.conf文件, 立即生效
rss - max resident set size (KB) # 常驻内存(物理), 无法限制
as - address space limit (KB) # 虚拟内存, 可做限制
# 用户可自己调整限制至最大值: ulimit -n 20
Cgroup <==> Controller group
mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
软件包: libcgroup (redhat6默认不装, redhat7安装)
redhat6中如何利用cgroup对系统资源做限制:
yum -y install libcgroup
/etc/init.d/cgconfig start # 服务启动后系统就有/cgroup/这个目录
- 临时生效:
# /cgroup/内控制资源, 可在其内新建目录, 将需要控制的进程对应的PID写入新建目录内的tasks文件中
mkdir /cgroup/memory/{bigdata,rh442} # 想对bigdata, rh442的内存做限制,
# 就在/cgroup/memory/目录下新建目录
echo 102400000 > /cgroup/memroy/rh442/memory.limit_in_bytes # 可通过此方式临时对rh442组的
# 内存做限制, 只能用100M内存
echo $(pidof vsftpd) > /cgroup/memory/rh442/tasks # 将需对内存做限制的进程的PID写入rh442组
# 的tasks中, 这样就对对应进程做了限制
pmap PID # 查看进程使用内存情况, 可以看到一个进程运行时一共需要的内存
# 如何删除内存中的文件夹:
rmdir rh442
- 永久生效: 可对云, 虚拟机, docker等容器使用的资源做限制
vi /etc/cgconfig.conf # 添加如下内容:
group bigdata { # bigdata为需要限制的组的组名, 名字可自定义, 可以创建多个group
blkio { # blkio为需要限制的内容
参数 = "值"; # 可以限制的参数能在/cgroup/blkcio/目录下找到
}
memory {
参数 = "值";
memory.limit_in_bytes = "100M";
}
}
/etc/init.d/cgconfig restart
# 注: 如果这样配置后在/cgroup/memory/内执行重启命令, 会报错: Device or resource busy
# 故需要到其他无关目录内重启, 才会成功
# 这样配置以后重启cgconfig服务, 会在/cgroup/memory/目录下创建文件夹bigdata和memroy,
# 但还没针对服务做限制, 因此还需进行下面步骤
vi /etc/cgrules.conf # 策略文件, 添加上述参数对应的配置:
#用户:命令 需要限制的内容 组名
*:cp blkio,memory bigdata/redhat/ # group内有子组时, 可在bigdata后面添加redhat
# 上面这行的含义为对所有用户执行cp命令时, 会使用bigdata内关于memory和blkio做限制的参数
# 在/etc/cgconfig.conf对内存做了100M的限制, 因此超出100M时不会执行cp命令
*:bigmem memory bigdata/ # 命令最好是绝对路径
*:/etc/init.d/vsftpd memory bigdata/ # 针对服务做限制
/etc/init.d/cgred restart
# 也可用以下命令重启服务:
service cgconfig restart
service cgred restart
redhat7中如何利用cgroup对系统资源做限制:
书本P98, P99
- redhat7内可针对服务或用户做限制
软件包: memload (类似于bigmem), 可用作测试内存
memload 256: 单位M, 申请使用256M内存
man system.resource-control # 查看可以用来限制的参数
/etc/systemd/system/ # 此目录下针对服务做限制
/etc/systemd/user/ # 此目录下针对用户做限制
# 实例: 需限制nginx.service的内存使用量为512M
cd /etc/systemd/system/
mkdir nginx.service.d # 新建需要限制的服务对应的目录
vi 00-limit.conf # 新建00-limit.conf文件, 添加以下内容:
[service]
MemoryLimit=512M
systemctl daemon-reload # 然后重载以及重启服务, 限制即可生效
systemctl restart nginx
硬件监控
CPU
基本概念:
- 一个核就是一个cpu
- 核与线程:
- 单线程: 人脑处理任务
- 多线程: 电脑处理2个任务
- 队列: 10个任务同时来
衡量cpu性能:
-
lscpu | grep BogoMIPS:BogoMIPS: 5616.00
每秒处理百万指令集的数目, 5616 * 1000,000
-
lscpu | grep "L3 cache"- L3 cache: 6144K
cpu <-- FSB --> mem: cpu和内存之间通过 FSB (前端总线) 交换数据
UMA: 一致性内存访问
-
NUMA: 非一致性内存访问, cpu和mem在同一个NUMA node中
- 优: 减少前端总线的压力
- 缺: 开启NUMA无法内存复用

- L1: 一级缓存, 一般CPU的L1i和L1d具备相同的容量
- L1d: 数据缓存 (Data Cache, D-Cache)
- L1i: 指令缓存 (Instruction Cache, I-Cache)
- L2: 二级缓存
- L3: 三级缓存
为什么CPU缓存会分为一级缓存L1、L2、L3?有什么意义?
- Virtualization type: full (支持全虚拟化)
# 更加详细的关于cpu的信息, 可以查看:
cat /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid mpx rdseed adx smap clflushopt xsaveopt xsavec arat spec_ctrl intel_stibp flush_l1d arch_capabilities
# flags: 支持的指令集, 如lm (long mode, 64bits), vmx (全虚拟化)
address sizes : 43 bits physical, 42 bits virtual
# 支持 2^42 = 4TB 的物理内存以及 2^42 = 4TB 的虚拟内存
内存
dmidecode # 查看内存信息, 如条数, 大小, 插槽, 频宽, 电压, 是否支持NUMA等
numactl # 设置cpu和内存在哪个NUMA node中
存储
| SATA | SAS | SSD | |||
|---|---|---|---|---|---|
| 容量 | > | > | |||
| 性能 | < | < |
常用RAID Level:
| 1 | 5 | 10 |
|---|---|---|
| 装系统 | 分布式 |
-
RAID5:
-
带奇偶校验的条带化, 有写惩罚- 大写: > 一半, 读整个分条, 写回 P
- 小写: < 一半
- 适用场景: 顺序的大IO ( 如视频监控, 备份, OLAP )
-
-
RAID10:
- 使用场景: 随机的小IO ( 如数据库OLTP, 事务型, 交易系统 )
FC - SAN: 一般用于公司内部业务, 距离有限
IP - SAN: 热备
网络
- 网卡选型
- 组网 ( GE/10GE/IB ) 40Gb/56Gb/100Gb
- 双网卡绑定模式 ( mode = 0-6 ) 0: 轮循 1: 主备 4: LACP 6: 最佳, 计算最小负载, 然后分发数据包至最小负载那里
- VLAN
- 网卡是否支持虚拟化: 指令集: VT-d(直通模式, 运算在网卡中进行), VT-x, SR-IOV(单根IO虚拟化, 硬直通, 直通虚拟机网卡)
cat /var/log/dmesg # 记录启动时的硬件信息
dmesg | grep eth # 可用于判断内核是否识别网卡
[ 2.698411] e1000 0000:02:01.0 eth0: (PCI:66MHz:32-bit) 00:0c:29:8d:4d:36 # mac地址
[ 2.698423] e1000 0000:02:01.0 eth0: Intel(R) PRO/1000 Network Connection # 别名
# 耗费时间
dmesg | grep sd # 查看硬盘信息
[ 3.126098] sd 2:0:0:0: [sda] 419430400 512-byte logical blocks: (214 GB/200 GiB)
[ 3.126170] sd 2:0:0:0: [sda] Write Protect is off
系统启动时, 红字之后的是服务和文件系统的信息 !!!
生产环境中可能遇到的问题以及一些补充说明
书本P115:
系统启动时显示: [
一般是物理机的内存不兼容或者硬件问题造成的.
lscpu, lspci, lsusb
# getconf此命令一般用于将系统配置变量值写入标准输出, 本身是个ELF可执行文件,也可以用于获取系统信息
getconf -a | grep -i page # 查看系统内存分页大小
# 内存页: 内存最小单元 (类比与block块的大小), 本例为4K
PAGESIZE 4096
PAGE_SIZE 4096
-a # 获取全部系统信息
dmidecode --from-dump 文件名 > dmi.txt # 分析二进制文件
# 可分析出L1, L2的大小, 注意内核个数!
影响磁盘IO性能的因素
- 机械硬盘:
- 转数
- 寻道时间
存储密度
分区号越低, 越靠近外环
读性能提升
读预取 (顺序读):
- 固定预取
- 倍数预取
- 智能预取
-
/sys/block/sda/queue/read_ahead_kb--> 4096 KB, 可调整此参数提升读预取的大小
-
- 不预取
写性能提升
硬盘调优的角度(可针对某块硬盘):
- 方法一:
/sys/block/sda/queue/nr_requests队列长度 - 方法二:
/sys/block/sda/queue/scheduler调度算法-
noop [deadline] cfq, 中括号中为当前使用的调度算法 - 调整:
echo noop > /sys/block/sda/queue/scheduler
-
调度算法:
-
deadline 最终期限
- 适合小IO和ext4文件系统
-
noop 没有任何调优
- 存储映射时无需调优
-
as 猜想时间
- 适合大IO和xfs文件系统
-
cfg 给每个应用不同大小
iostat # 对一个程序设置或获取I/O调度级别和优先级 ionice -p 1 # 查看PID为1的进程的I/O调度级别以及优先级 ionice -p 1 -c 1 -n 2 # 设置PID为1的进程为class1, nice值为2 -c参数:
| class | 1 | 2 | 3 | ||
|---|---|---|---|---|---|
| 优先级 | > | > | |||
| 实时: 先进先出 | 轮循: n越小, 分到的时间片越多, 但每个进程都会轮到 | 空闲 |
- -n参数:
- 0 - 7, 越小越重要, 优先级越高
mailload.py 压力测试工具
当然也可以通过tuned.conf修改参数进行调优
进程管理和调度
ps axo %cpu,%mem,nice,psr
nice # 查看进程的优先级
psr # 显示程序与运行在哪个cpu上
优先级:
- 静态: 1 - 99, 数字越大, 优先级越高
- 动态: 0 <=> 100 - 129 ( -20 - 19 )
chrt -p 1 # 实时查看PID为1的进程优先级
pid 1's current scheduling policy: SCHED_OTHER
pid 1's current scheduling priority: 0
FIFO和RR谨慎使用, 因为一旦使用会将整个CPU占用 !!!
-
SCHED_FIFO
- 先进先出, first input first output, 优先级 1 - 99
- 优先级高的会抢占cpu
-
chrt -f 10 dd if=/dev/zero of=/dev/null:实时设置FIFO且优先级为10
-
SCHED_RR
- 类似FIFO但有时间片的概念
chrt -r 20 dd if=/dev/zero of=/dev/null- 只有RR级别才会轮循, 优先级越高, 分到的时间片越多
-
SHCED_OTHER
nice
renice
-
other如何获得更长的时间片?
方法一: 类似cgroup中的内存管理去设置 CPUShares=128 (份额 = 2的倍数), 永久生效
方法二:
systemctl set-property httpd.service CPUShares=512, 临时生效
# 如何对已运行的程序调整优先级:
chrt -p 2420
chrt -p -f 10 2420 # 对PID为2420的进程调整优先级为FIFO, 10
跟踪系统和库调用
系统调用
排错时会用到 !
strace -c ls -l # 计数每步的操作时间
-c # count
strace -e read cp -r /etc/ /data/ # 查看read的具体操作
strace -p PID # 实时查看某程序的系统和库的调用情况
库调用
ltrace cp # 查看某个命令会调用哪些库
减少磁盘访问次数
- VFS: 虚拟文件系统, 对应用而言, 只要调用驱动, 写入数据就好了, 所以任何的文件系统对应用来讲都是VFS
tune2fs -l /dev/vda1 # 查看原数据, 简略
dumpe2fs /dev/vda1 # 详细
# 可以看到元数据中由block group, 即分组的概念, 以此保证数据连续
8K: 超级块损坏时如何修复? 一定要记得先卸载分区再修复 !!!
dd if=/dev/zero of=/dev/vda1 bs=1k count=20 # 模拟生产环境中超级块损坏的情况, 此处为破坏超级块
# 修复ext类型文件系统:
# 方法一:
umount /dev/vda1
fsck -v /dev/vda1 # 一直yes
# 方法二:
umount /dev/vda1
e2fsck -b 98304 /dev/vda1 # 使用98304的超级块来恢复,
# 特别注意, 不同的文件系统, 超级块的位置固定的
# 修复xfs类型文件系统:
xfs_repair /dev/vda1
日志型文件系统
ext3/ext4/xfs/NTFS
优: 减少开机扫描
缺: 写数增加( 两次写: 1. journal 2.inode )
外部日志区如何配置
条件:
- (1) journal size =2^N < 400M
- (2) 整个分区只能用于journal device, 不能用作其他
- 多个文件系统可以共用一个外部日志区, 不过block size必须相同
- (3) journal block size 必须与源文件系统一致
现在有两块硬盘, sda1和sdb1, 需要将sdb1用作sda1的外部日志区, 从而减少硬盘访问次数, 下面为配置方法:
# 1. 卸载文件系统
umount /dev/sda1
umount /dev/sdb1
# 2. 查看文件系统的block大小及日志位置
dumpe2fs /dev/sda1 | egrep -i (journal|size)
# 3. 在已存在的文件系统中删除内部日志
tune2fs -O ^has_journal /dev/sdb1
# 4. 创建一个扩展的日志设备
mke2fs -O journal_dev -b block_size /dev/sdb1
# 5. 更新文件系统的超级块, 从而使用扩展的日志
tune2fs -j -J device=/dev/sdb1 /dev/sda1
cpu的IRQ均衡 (IRQ balance)
用来均衡cpu的访问次数, 但cpu的缓存效果会减弱
- 每个硬件都会对应一个中断号, 一般IRQ只会指向某一个cpu, 所以某个设备只会在使用对应的cpu跑任务, 即只在某个cpu上消耗资源
cat /proc/interrupts

| 中断号 | CPU0 | CPU1 | CPU2 | CPU3 | ||
|---|---|---|---|---|---|---|
| 19: | 8417 | 0 | 0 | 0 | IO-APIC-fasteoi | eno16777736 |
| cpu编号说明: | 2^0=1 | 2^1=2 | 2^2=4 | 2^3=8 |
cat /proc/irq/19/smp_affinity # smp_affinity: 多处理器亲缘
08 # 说明只用了CPU3
cat /proc/irp/27/smp_affinity
20 # 2^2 + 2^4 = 20, 使用了CPU2和CPU4
修改多处理器亲缘:
echo 2 > /proc/irq/19/smp_affinity # 将多处理器亲缘改为CPU1
echo 3 > /proc/irq/3/smp_affinity # 改为使用CPU0和CPU1, f: 15
Tuning process affinity with taskset (不均衡)
- 一般应用程序运行的时候会在不同的cpu上来回切换:
ps axo %cpu,%mem,psr - 优: 设置应用程序运行在指定的某个cpu或某些cpu上, 提高缓存命中率, 从而提升性能
- 缺: 不均衡的运行队列会导致较长的等待时间, 一般用于NUMA架构
taskset -p PID # 查看PID的进程运行在哪个cpu上
taskset -p 3 PID # 此处的3为16进制, 例如1, 2, 4, 8, f
cpu隔离
如何做cpu隔离, 实现某个cpu只运行特定程序?
# 1. 启动时编辑/etc/grub.conf, 隔离cpu
isolcpus=cpu_number,cpu_number,... # 设定只使用某几个cpu, 其他不用
# 2. 设定某个程序运行在特定cpu上
taskset -p cpu_number PID
# 3. 考虑调整IRQ亲缘
cpu支持热插拔
- CPU0以外的cpu支持如拔插, 0号不支持的原因是因为它是启动cpu
- 支持热拔插的前提: 硬件支持 (BIOS支持物理热拔插)
- 对NUMA系统非常有用
- 热拔插的操作后内核会动态更新
/proc/cpuinfo及其他文件内的信息 see kernel-doc-*/Documentation/cpu-hotplug.txt
# 1. 查看cpu号
grep processor /proc/cpuinfo
cat /proc/interrupts
# 2.动态关闭某个cpu, 如cpu1
echo 0 > /sys/devices/system/cpu/cpu1/online # online: 相当于一个开关
cat /proc/interrupts # 关闭后无法看到cpu1的信息
# 3. 重开cpu1
echo 1 > sys/devices/system/cpu/cpu1/online
cat /proc/interrupts # 再次可以看到cpu1的信息
注: cpu1在被关闭时已有程序在上面运行, 关闭时其上的程序会被迁移到其他cpu, 不会影响原来程序的运行, 就算指定某程序在cpu1上运行, 当cpu1被关闭时, 该程序依旧不会受到影响, 同样会被迁移到其他cpu上, 但cpu1再次被开启时, 原来指定的程序不会再次回到cpu1上运行
调度域 (scheduler domains)
cpuset: 进程组, 支持多核和NUMA架构
/sys/fs/cgroup/cpuset/
cat /proc/filesystem | grep cpuset # 可以看到有种特殊的vfs: cpuset
nodev cpuset
mkdir /cpuset
mount -t cpuset nodev /cpuset/
cd /cpuset/; ls
cat cpuset.cpus
0-3 # 包含的cpu号
cat cpuset.mems
0 # 包含的内存zone
cat tasks # 包含的所有任务
此架构用于NUMA特别方便:
mkdir {rh442,cl210}
echo 0-1 > rh442/cpuset.cpus # 每个cpuset至少包含一个cpu和一个内存zone
echo 0 > rh442/cpuset.mems
echo 2-3 > cl210/cpuset.cpus # cpuset支持嵌套, 故可将 2-3 改为 0-1
echo 0 > cl210/cpuset.mems
# 关闭cpu嵌套, 注意需要先关闭根cpuset的嵌套才有效
echo 1 > /cpuset/cpuset.cpu_exclusive
可将指定程序运行在NUMA node中:
systemctl start vsftpd
echo $(pidof vsftpd) > /cpuset/rh442/tasks
查看某程序运行在哪个cpuset中, 以vsftpd为例:
cd /proc/$(pidof vsftpd)
cat cpuset # 查看到结果为/rh442
cd /proc/1
cat cpuset # 查看到结果为/, 根cpuset包含所有系统资源
内存管理(地址和分配)
- 虚拟内存
- 应用程序申请的内存 (按需分配)
- 应用程序申请虚拟内存时时, 总认为每一个程序都有一段线性的, 连续的地址空间, 但实际映射到的物理内存上是不连续的
- 地址范围从0到最大值
- 32bits架构的系统, 内存最大支持 2^32 = 4GB
- 64bits架构的系统, 内存最大支持 2^48 = 256TB, 但由于内核与硬件的限制, 实际只支持到 2^42 = 4TB
- 用内存页来表示
- 物理内存
- 物理内存 = 内存 + swap, 即 96G = 64G + 32G
- swap上的数据只做暂存, 不作处理
- cpu的内存管理单元 MMU: 负责管理虚拟内存与物理内存之间的映射关系
- 物理内存 = 内存 + swap, 即 96G = 64G + 32G
ps aux | less # 可以查看到虚拟内存VSZ和物理内存RSS的使用情况
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 193580 6584 ? Ss 2018 17:55 /usr/lib/systemd/systemd --system --deserialize 20
root 2 0.0 0.0 0 0 ? S 2018 0:09 [kthreadd]
root 3 0.0 0.0 0 0 ? S 2018 0:25 [ksoftirqd/0]
root 73900 0.0 0.0 918368 32492 ? Ssl May24 0:30 PM2 v3.0.0: God Daemon (/root/.pm2)
root 86904 0.0 0.0 157860 2424 ? S Apr23 0:00 top
bigmem -v 500 # 申请使用500MB虚拟内存
watch -n 1 'cat /proc/meminfo | grep AS' # AS:地址空间
- PTE: 页表条目 (page table entries)
- 记录虚拟内存到物理内存的映射关系
- TLB: 记录PTE内映射关系的缓存
- Hugepage (大页): 用于存放TLB的缓存数据
cat /proc/meminfo | grep -i huge-
bigmem -H NUM: -H, 指定使用Hugepage, 此命令可用作测试大页 - 一旦分配了大页, 其他应用程序无法申请到大页使用的内存
- Hugepage (大页): 用于存放TLB的缓存数据
内存架构
x86, 即32bits的系统上:
| 1024M, 具体分配如下 | 物理内存的第一个GB分配给内核使用 (直接映射内存) |
|---|---|
| 128M | 高位内存, 用于存放PTE |
| 896M, 包括下面的1M和16M和879M | |
| 1M | 给BIOS和IO设备使用 |
| 16M | 给DMA (直接内存访问) 使用 |
| 879M | 低位内存 |
x86_64, 及64bits的系统上:
| 128T | 系统使用 |
|---|---|
| 128T | 应用使用 |
页中断 (page fault)
ps axo pid,comm,minflt,majflt
PID COMMAND MINFLT MAJFLT
53399 sshd 6937 0
53401 sftp-server 1444 0
66588 snmpmagt 637 0
66872 PatrolAgent 1739153756 0
66987 pukremotexec.xp 273 0
73900 PM2 v3.0.0: God 107465 0
- 次页中断
- 由物理内存分配
- 主页中断
- 由swap分配
- 主页中断越多, 系统性能越差
页:
(1) dirty page: 内存中已被修改, 还未写入磁盘的数据, 可用sync命令将drity page的数据写入磁盘
(2) clean page: free -m中的caches, 以写入磁盘, 但是作为缓存, 提升读性能的数据
生产环境中一个特别有用的参数: vm.swappiness
vm.swappiness默认值的范围在: 0 - 100
- 此值越高, 越多的使用swap
- 此值越低, 越多的使用内存
sysctl -a | grep swappiness
vm.swappiness = 30
生产环境中, 若swap使用过多, 如何更多的使用内存, 减少swap的使用量:
# 方法一: 临时生效
sysctl -w vm.swappiness=20
# 方法二: 永久生效
vi /etc/sysctl.conf
vm.swappiness = 20
sysctl -p
如果需要清空swap中的缓存, 该怎么做?
# 先看看当前swap和内存的使用情况: 如果swap使用量已经超过内存的空闲量, 则无法被清空!
swapon -s
Filename Type Size Used Priority
/dev/sda1 partition 8257532 8257532 -1
swapoff /dev/sda1 # 一定要注意, 生产环境中千万不要随便去卸载swap!!!
watch -n 1 'free -m'
扩展swap
一些概念:
冷数据, anon (匿名页, 可用命令
pmap查看) 都会大量放于swap中.一般内存越大, swap也分配的越大, 因为内存中的冷数据也越多.
如何提升swap的性能:
- 将swap分到不同的硬盘上
- 分配分区号小的分区, (分区号越小, 越靠近外圈, 磁头每转过一圈读取到的数据越多)
方法一: 使用硬盘分区
注: swap分区Priority的值越大, 优先级越高, 越先被使用!
# (1) 先在不同的两块硬盘上都分出1个分区, 都用作swap
fdisk /dev/sdb # 分出/dev/sdb1
fdisk /dev/sdc # 分出/dev/sdc1
# (2) 然后格式化
mkswap /dev/sdb1
mkswap /dev/sdc1
# (3) 编辑/etc/fstab, 注意调整各自的优先级, 做到均衡使用两个分区的swap (即轮循)
vi /etc/fstab # UUID可用命令blkid查看
UUID="..." swap swap defaults,pri=-2 0 0
UUID="..." swap swap defaults,pri=-2 0 0
方法二: 使用文件
RHCE课程中已学过, 此处不再赘述.