HashMap原理及实现
title: HashMap原理及实现
tags: [算法与数据结构,Java,HashMap]
categories: 算法与数据结构
什么是hash
- 它将一个长度为二进制通过一个映射关系转换成一个固定长度的二进制值。
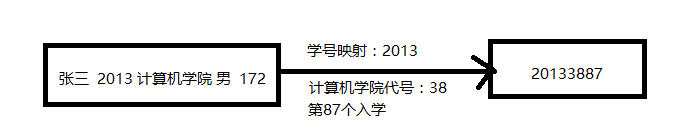
- 1.任意长度的二进制
- 2.映射关系(哈希算法–就相当于一个大学里面的学号的一个映射规则)
- 3.固定的二进制(哈希值–相当于我大学里面的学号)
- 任意长度的二进制和固定长度的二进制 是一个一一对应关系
- 固定长度的二进制就相当于一个任意长度的二进制的摘要
- 固定长度的二进制 相当于一个关键字 key
- 真正有效的数据 就是这个学生的基本信息,一个任意长度的二进制value
key – value
- hash 只是确定了一个key和一个value的唯一映射关系
hash表
- 特点:它存储效率很高,取数据的时间复杂度是1 o(1)
-hash 通过一个key一个输入,通过一个哈希函数,来找到数组与这个key唯一映射的value,根据这个hash函数找到数组中这个value的下标
table a = []
int index = hash(key)
int value = a[index]
hash函数
key,找下标,有哪些方法可以找到下标
除留取余数法(取模)
- 定义数 a 长度是16
- int index = key%m;
- m的取值规则:
- m要取比数组长长度小的最大质数
- m = 13
平方取中法
hash 表处理冲突
- 1.线性探测法:探测的步长n=1;
- 如果插入新数据时在index位置发现有老数据存在,新数据插入的位置向后移动 步长n,如果后面还有数据则继续往后移动步长n,直到把新数据没有数据存在的位置
- 2.链表形式
- 插入发现位置有老数据存在,新的放在老的位置并使新的数据next指向刚覆盖的老数据

- 插入发现位置有老数据存在,新的放在老的位置并使新的数据next指向刚覆盖的老数据
MD5 函数
- MD5 签名是一个哈希函数,可以将任意长度的数据量转换为一个固定长度的数字(通常是4个整型,128位)。计算机不可能有2的128次方那么大内存,因此实际的哈希表都会是URL.MD5再%n(即取模)。现实世界的URL组合必然超越哈希表的槽位数,因此碰撞是一定存在的,一般的HASH函数,例如Java的 HashTable 是一个HASH表再跟上一个链表,链表里存的是碰撞结果

hashMap(java)代码实现
定义接口Ihashmap.java
public interface Ihashmap<K,V> {
public V put(K k,V v);
public V get(K k);
public int size();
public interface Entry<K,V>{
public K getKey();
public V getValue();
}
}
实现接口hMap.java
import java.util.ArrayList;
import java.util.List;
public class hMap<K,V> implements Ihashmap<K,V> {
private static int defaultLength = 16;
//负载因子 超过defaultLength*defalutLoader Hasp必须扩容
private static double defalutLoader = 0.75;
private Entry<K,V> [] table = null;
private int size = 0;
public hMap(int length,double loader){
defalutLoader = loader;
defaultLength = length;
table = new Entry[defaultLength];
}
public hMap(){
this(defaultLength,defalutLoader);
}
public V put(K k,V v){
//在这里判断一下size是否达到扩容的标准
if(size >= defaultLength*defalutLoader){
up2size();
}
//1.创建一个hash函数,根据key和hash函数算出数组下标
int index = getIndex(k);
Entry<K,V> entry = table[index];
if (entry == null){
//如果entry为null,说明table的index位置没有元素
table[index] = newEntry(k,v,null);
size++;
}else{
//如果index位置不为空,说明index位置有元素,那么要进行一个替换,然后next指针指向老数据
table[index] = newEntry(k,v,entry);
}
return table[index].getValue();
}
private void up2size(){
Entry<K,V>[] newTable = new Entry[2*defaultLength];
//新创建的数组以后,以前老数组里面的元素要对新数组再进行散列
againHash(newTable);
}
private void againHash(Entry<K,V>[]newTable){
List<Entry<K,V>> list = new ArrayList<Entry<K, V>>();
for (int i=0;i<table.length;i++){
if(table[i] == null){
continue;
}
findEntryByNext(table[i],list);
}
if(list.size()>0){
//要进行一个数组的再散列
size = 0;
defaultLength = defaultLength * 2;
table = newTable;
for(Entry<K,V> entry:list){
if(entry.next != null){
entry.next = null;
}
put(entry.getKey(),entry.getValue());
}
}
}
private void findEntryByNext(Entry<K,V> entry,List<Entry<K,V>> list){
if(entry != null && entry.next != null){
list.add(entry);
findEntryByNext(entry.next,list);
}else{
list.add(entry);
}
}
private Entry<K,V> newEntry(K k,V v,Entry<K,V>next){
return new Entry(k,v,next);
}
private int getIndex(K k){
int m = defaultLength;
int index = k.hashCode()%m;
return index>=0 ? index:-index;
}
public V get(K k){
//1.创建一个hash函数,根据key和hash函数算出数组下标
int index = getIndex(k);
if (table[index] == null){
return null;
}
return findValueByEqualKey(k,table[index]);
}
public V findValueByEqualKey(K k,Entry<K,V> entry){
if(k == entry.getKey() || k.equals((entry.getKey()))){
return entry.getValue();
}else {
if (entry.next != null){
return findValueByEqualKey(k,entry.next);
}
}
return null;
}
public int size(){
return size;
}
class Entry<K,V> implements Ihashmap.Entry<K,V>{
K k;
V v;
Entry<K,V> next;
public Entry(K k,V v,Entry<K,V> next){
this.k = k;
this.v = v;
this.next = next;
}
public K getKey(){
return k;
}
public V getValue(){
return v;
}
}
}
测试类test.java
import java.util.HashMap;
import java.util.Map;
/**
* Created by Administrator on 2017/6/15.
*/
public class Test {
public static void main(String[] args){
Ihashmap<String,String> lmap = new hMap<String,String>();
Long t1 = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
lmap.put("key"+i,"value"+i);
}
for (int i = 0; i < 1000; i++) {
System.out.println("key:"+"key"+i + " value:"+lmap.get("key"+i));
}
Long t2 = System.currentTimeMillis();
System.out.println("手写实现haspmap耗时:"+(t2-t1));
System.out.println("--------------hashMap--------------");
Map<String,String> map = new HashMap<String,String>();
Long t3 = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
lmap.put("key"+i,"value"+i);
}
for (int i = 0; i < 10000; i++) {
System.out.println("key:"+"key"+i + " value:"+lmap.get("key"+i));
}
Long t4 = System.currentTimeMillis();
System.out.println("JDK实现haspmap耗时:"+(t4-t3));
System.out.println("手写实现haspmap耗时:"+(t2-t1));
}
}
- git源码
更多内容请关注微信公众号:
