【spark】on yarn的模式下,如何上传files并在程序中读取到?
在使用spark的时候,往往我们需要外部传入文件,来配合程序做数据处理
那么这就涉及到,如何传入,如何获取(本文讨论的是spark on yarn)
讲实话,我觉得这个问题挺烦的,我百度了好久(可能我姿势不对?),各种博客,stackoverflow,community.cloudera.com都找过,我觉得回答方都停留在理论基础,并没有show me code,我实际测试的时候,好像又和他们说的不太一样,哎,要是能有统一的入口,统一的出口就好了
1、client模式
client模式下,driver开启在提交任务的机器上,所以他可以直接读取到本地的文件,这就很简单了
(1)、从shell中传入文件的绝对路径(关键在spark.filename这一行)
bin/spark-submit \
--master yarn \
--class spark.LoadFileTest \
--deploy-mode client \
--conf spark.file.absolutepath=/opt/data/sql.txt \
/opt/CDH/spark-2.2.0-bin-2.6.0-cdh5.12.1/spark.jar
其实随便找个名字,不一定要用spark.file.absolutepath来作为参数名称,但是你的参数名称必须是spark开头的,才会被sparkConf加载
(2)、在代码中获取到shell传入的路径,然后通过java的io流读取数据
public static void main(String[] args) {
SparkSession sparkSession = buildSparkSession(false, "LoadFileTest");
String absolutePath = sparkSession.conf().get("spark.file.absolutepath");
System.out.println("===============文件绝对路径=================");
System.out.println("absolutePath = "+ absolutePath);
String sql = readFileContent(absolutePath);
System.out.println("文件内容 = "+ sql);
}
private static String readFileContent(String absolutePath) {
BufferedReader reader = null;
StringBuffer stringBuffer = new StringBuffer();
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream(absolutePath)));
String str;
//一次读取一行
while ((str = reader.readLine()) != null) {
stringBuffer.append(str + "\n");
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
return stringBuffer.toString();
}(3)、获得了之后想干嘛就干嘛吧,如果想让executor处理的时候也用到这个数据,可以把这个数据做为广播变量广播出去就好了
2、cluster模式
cluster模式下,driver会在任意有资源的节点启动,那么他就读取不到当前提交任务的这台机器的数据了,所以理论上,我们需要提供一个分布式的文件系统,让所有机器都可以通过这个系统获取数据
(1)、在shell中使用--files的方式上传文件,并且还要传入文件名
bin/spark-submit \
--master yarn \
--class spark.LoadFileTest \
--deploy-mode client \
--conf spark.filename=sql.txt \
--files /opt/sql.txt \
/opt/CDH/spark-2.2.0-bin-2.6.0-cdh5.12.1/spark.jar
通过以上shell,你会发现日志中有一条info,把本地的文件上传到了hdfs上,这样就可以通过hdfs访问这个数据

(2)、代码中获取
可以通过spark的read直接读数据,也可以自己写io流读取hdfs上的文件,这里我选的第一种,比较方便
public static void main(String[] args) {
SparkSession sparkSession = buildSparkSession(false, "LoadFileTest");
String fileName= sparkSession.conf().get("spark.file.absolutepath");
System.out.println("===============文件名=================");
System.out.println("fileName= "+ fileName);
Dataset confSql = spark
.read()
.textFile(System.getenv("SPARK_YARN_STAGING_DIR") + "/" + fileName);
confSql.show(false);
//这里可以通过take,collect等方法,把Dataset的中的数据取出转成String
//由于太简单我就不写了
}
有同学会问,诶,你这个SPARK_YARN_STAGING_DIR哪里来的呀?
通过cluster提交的任务,我们无法在提交的机器直接看到日志,所以我的hadoop开启了jobhistory服务之后,我运行如下查看日志的命令
bin/yarn logs -applicationId 这里传入具体的$application_id
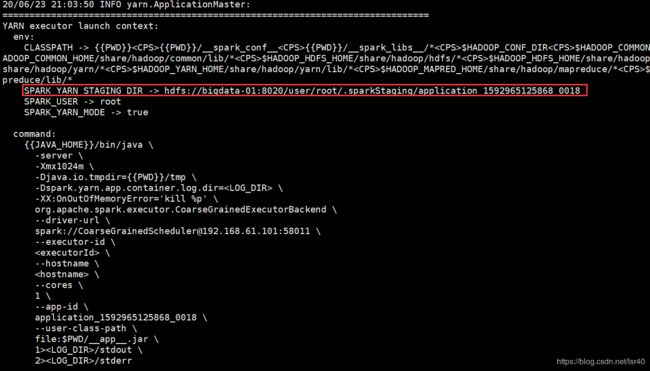
3、备注
另我觉得烦的事情是这样的,我在想,有没有统一的方法,不管是client还是cluster都可以使用这个方法读取数据
不知道是就没有这样的方法,还是我找不到
你看,理论上来说,client模式,我也通过--files把文件上传到hdfs上,然后读取hdfs上的数据就好了呀,但是关键在于client模式下,SPARK_YARN_STAGING_DIR居然为null,这实在太难受了。。。。那我就不能方便的得到--files上传的数据的目录了,所以client模式我才会用io直接读取本地文件,不知道各位老哥们有没有解决这个问题的方法呢?
所以如果不确定用户提及shell中,会使用client还是cluster,那代码中,只能先加一层判断,判断sparkSession.conf().get("spark.submit.deployMode")这个值是client还是cluster,然后再调用对应模式下的文件的读取,想想就觉得好烦啊!
好了菜鸡一只,下次再见!
马上端午节加上我的生日到了,提前祝自己生日快乐吧!