CVPR 2020 论文大盘点-图像分割完整篇

前文已经盘点了大部分CVPR 2020 图像分割方向论文,主要分为以下几类:
CVPR 2020 论文大盘点-语义分割篇
CVPR 2020 论文大盘点-实例分割篇
CVPR 2020 论文大盘点-全景分割与视频目标分割篇
本文对剩余所有分割论文进行了总结,每个方向论文数量较少,但不少论文都很有意思,非常值得关注。
比如交互式图像分割(Interactive Image Segmentation),鼠标点两下就能分割出想要的目标,这将极大方便设计师和广大的AI数据标注员。
运动目标分割(Moving Object Segmentation),分割视频监控中运动的目标,在实际应用中很需要。
基于文本的实例分割(Referring Image Segmentation),既要理解文本语义还要在图像中找到对应物体再分割出来,简直不要太神奇。
还有学者为分割问题定义P值,以后算法可以自己评估结果好坏了。
还有比传统算法快30万倍的颜色分割,代码开源了,相信能促进视频编辑的应用。
在传统的非语义分割和超像素分割方向也有论文。
总计 25 篇文章,已经开源或者即将开源的论文,把代码地址也附上了。
大家可以在:
http://openaccess.thecvf.com/CVPR2020.py
按照题目下载这些论文。
如果想要下载所有CVPR 2020论文,请点击这里:
CVPR 2020 论文全面开放下载,含主会和workshop
交互式图像分割
[1].Interactive Image Segmentation With First Click Attention
作者 | Zheng Lin, Zhao Zhang, Lin-Zhuo Chen, Ming-Ming Cheng, Shao-Ping Lu
单位 | 南开大学
网站 | http://mmcheng.net/fclick/

[2].F-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
作者 | Konstantin Sofiiuk, Ilia Petrov, Olga Barinova, Anton Konushin
单位 | 三星人工智能中心–莫斯科
代码 | https://github.com/saic-vul/fbrs_interactive_segmentation
[3].Interactive Object Segmentation With Inside-Outside Guidance
作者 | Shiyin Zhang, Jun Hao Liew, Yunchao Wei, Shikui Wei, Yao Zhao
单位 | 北京交通大学等
代码 | https://github.com/shiyinzhang/Inside-Outside-Guidance

多目标分割
[4].Learning Multi-Object Tracking and Segmentation From Automatic Annotations
作者 | Lorenzo Porzi, Markus Hofinger, Idoia Ruiz, Joan Serrat, Samuel Rota Bulo, Peter Kontschieder
单位 | Mapillary Research;格拉茨技术大学等

[5].Sparse Layered Graphs for Multi-Object Segmentation
作者 | Niels Jeppesen, Anders N. Christensen, Vedrana A. Dahl, Anders B. Dahl
单位 | 丹麦技术大学
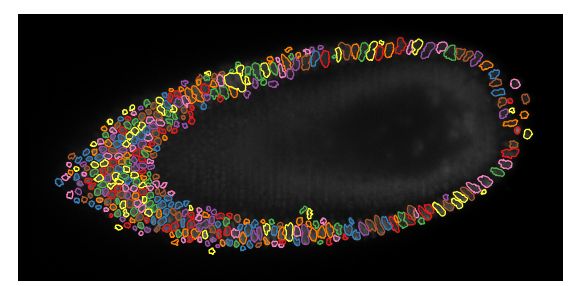
3D点云分割
[6].SegGCN: Efficient 3D Point Cloud Segmentation With Fuzzy Spherical Kernel
作者 | Huan Lei, Naveed Akhtar, Ajmal Mian
单位 | 西澳大学
代码 | https://github.com/hlei-ziyan/SegGCN
[7].Few-Shot Learning of Part-Specific Probability Space for 3D Shape Segmentation
作者 | Lingjing Wang, Xiang Li, Yi Fang
单位 | 纽约大学阿布扎比分校;纽约大学

自适应形状联合分割
[8].AdaCoSeg: Adaptive Shape Co-Segmentation With Group Consistency Loss
作者 | Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J. Guibas, Hao Zhang
单位 | 西蒙弗雷泽大学;中国人民解放军国防科技大学;Adobe Research;印度理工学院孟买分校;谷歌;斯坦福大学

多边形结构分割
[9].Bundle Pooling for Polygonal Architecture Segmentation Problem
作者 | Huayi Zeng, Kevin Joseph, Adam Vest, Yasutaka Furukawa
单位 | 华盛顿大学;西蒙弗雷泽大学;Nike

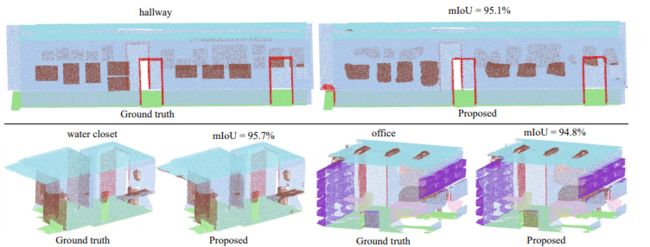
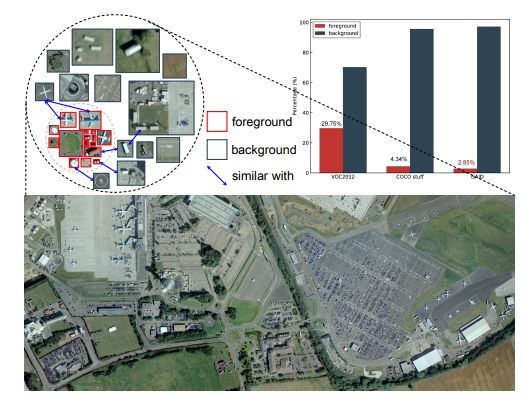
遥感影像目标分割
[10].Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery
作者 | Zhuo Zheng, Yanfei Zhong, Junjue Wang, Ailong Ma
单位 | 武汉大学
运动目标分割
可应用于视频监控
[11].An End-to-End Edge Aggregation Network for Moving Object Segmentation
作者 | Prashant W. Patil, Kuldeep M. Biradar, Akshay Dudhane, Subrahmanyam Murala
单位 | CVPR Lab;印度理工学院;英伟达

快速软颜色分割
可改进图像和视频编辑,使用神经网络方法,相较以往方法快30万倍!分割质量也更好。
[12].Fast Soft Color Segmentation
作者 | Naofumi Akimoto, Huachun Zhu, Yanghua Jin, Yoshimitsu Aoki
单位 | 日本庆应义塾大学;Preferred Networks
代码 | https://github.com/pfnet-research/FSCS

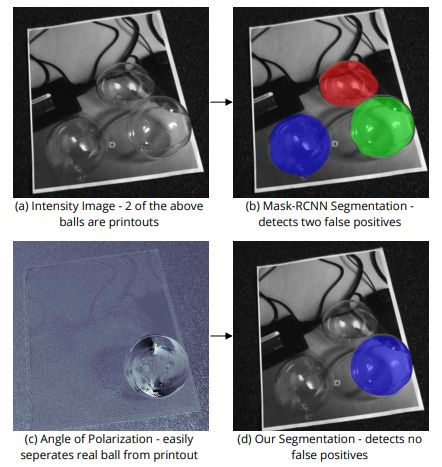
透明目标分割
[13].Deep Polarization Cues for Transparent Object Segmentation
作者 | Agastya Kalra, Vage Taamazyan, Supreeth Krishna Rao, Kartik Venkataraman, Ramesh Raskar, Achuta Kadambi
单位 | Akasha Imaging;麻省理工学院媒体实验室;UCLA
分割结果可靠性的P值计算
[14].Computing Valid P-Values for Image Segmentation by Selective Inference
作者 | Kosuke Tanizaki, Noriaki Hashimoto, Yu Inatsu, Hidekata Hontani, Ichiro Takeuchi
单位 | 名古屋工业大学;日本理化学研究所RIKEN

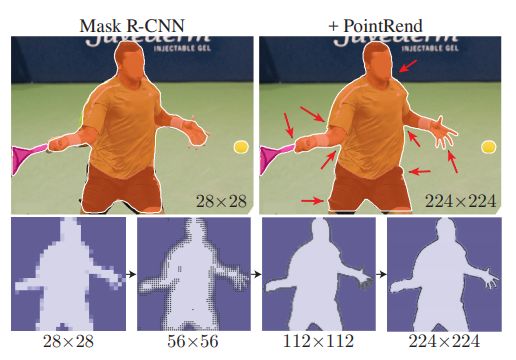
Point-based rendering 模块改进实例和语义分割
[15].PointRend: Image Segmentation As Rendering
作者 | Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
单位 | FAIR
代码 | https://github.com/facebookresearch/detectron2
/tree/master/projects/PointRend
解读 | https://zhuanlan.zhihu.com/p/98508347
基于文本的实例分割
[16].PhraseCut: Language-Based Image Segmentation in the Wild
作者 | Chenyun Wu, Zhe Lin, Scott Cohen, Trung Bui, Subhransu Maji
单位 | 马萨诸塞大学阿默斯特分校;Adobe Research
代码 | https://github.com/ChenyunWu/PhraseCutDataset
网站 | https://people.cs.umass.edu/~chenyun/phrasecut/

[17].Bi-Directional Relationship Inferring Network for Referring Image Segmentation
作者 | Zhiwei Hu, Guang Feng, Jiayu Sun, Lihe Zhang, Huchuan Lu
单位 | 大连理工大学;鹏城实验室

[18].Referring Image Segmentation via Cross-Modal Progressive Comprehension
作者 | Shaofei Huang, Tianrui Hui, Si Liu, Guanbin Li, Yunchao Wei, Jizhong Han, Luoqi Liu, Bo Li
单位 | 中科院;国科大;北航;中山大学;悉尼科技大学;360 AI Institute
代码 | https://github.com/spyflying/CMPC-Refseg

[19].Multi-Task Collaborative Network for Joint Referring Expression Comprehension and Segmentation
作者 | Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Liujuan Cao, Chenglin Wu, Cheng Deng, Rongrong Ji
单位 | 厦门大学;DeepWisdom;西安电子科技大学
代码 | https://github.com/luogen1996/MCN
备注 | CVPR2020 oral

道路标记分割的知识蒸馏
[20].Inter-Region Affinity Distillation for Road Marking Segmentation
作者 | Yuenan Hou, Zheng Ma, Chunxiao Liu, Tak-Wai Hui, Chen Change Loy
单位 | 香港中文大学;商汤;南洋理工大学
代码 | https://github.com/cardwing/Codes-for-IntRA-KD

语义分割改进非监督单目深度估计
[21].The Edge of Depth: Explicit Constraints Between Segmentation and Depth
作者 | Shengjie Zhu, Garrick Brazil, Xiaoming Liu
单位 | 密歇根州立大学;
代码 | https://github.com/TWJianNuo/EdgeDepth-Release

通用(非语义)分割
学习区域表示增强通用(非语义)的图像分割
[22].Enhancing Generic Segmentation With Learned Region Representations
作者 | Or Isaacs, Oran Shayer, Michael Lindenbaum
单位 | 以色列理工学院

手部分割的域适应
[23].Generalizing Hand Segmentation in Egocentric Videos With Uncertainty-Guided Model Adaptation
作者 | Minjie Cai, Feng Lu, Yoichi Sato
单位 | 湖南大学;北航;鹏城实验室;东京大学
代码 | https://github.com/cai-mj/UMA

超像素分割
基于全卷积网络的超像素分割算法
[24].Superpixel Segmentation With Fully Convolutional Networks
作者 | Fengting Yang, Qian Sun, Hailin Jin, Zihan Zhou
单位 | 宾夕法尼亚州立大学;Adobe Research
代码 | https://github.com/fuy34/superpixel_fcn

[25].Super-BPD: Super Boundary-to-Pixel Direction for Fast Image Segmentation
作者 | Jianqiang Wan, Yang Liu, Donglai Wei, Xiang Bai, Yongchao Xu
单位 | 华中科技大学;哈佛大学
代码 | https://github.com/JianqiangWan/Super-BPD

往期"精彩阅读"
CVPR 2020 论文大盘点-超分辨篇
CVPR 2020 论文大盘点-目标检测篇
CVPR 2020 论文大盘点-人脸技术篇
CVPR 2020 论文大盘点-目标跟踪篇
CVPR 2020 论文大盘点-行人检测与重识别篇
CVPR 2020 论文大盘点-实例分割篇
CVPR 2020 论文大盘点-语义分割篇
CVPR 2020 论文大盘点-全景分割与视频目标分割篇
END

备注:分割

图像分割交流群
语义分割、实例分割、全景分割、抠图等技术,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号 : aicvml
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 