数据库-高级查询
EXISTS子查询
Exists子查询就是用来判断某些条件是否满足(跨表),Exists是接在where之后,Exists返回的结果只有0和1。
EXISTS子查询的语法
| SELECT …… FROM 表名 WHERE EXISTS(子查询); |
子查询有返回结果: EXISTS子查询结果为TRUE
子查询无返回结果: EXISTS子查询结果为FALSE, 外层查询不执行
子查询注意事项
1.任何允许使用表达式的地方都可以使用子查询
2.嵌套在父查询SELECT语句的子查询可包括
| SELECT子句 FROM子句 |
| WHERE子句 GROUP BY子句 ------>可选子句,根据业务需求决定 HAVING子句 |
3.只出现在子查询中而没有出现在父查询中的列不能包含在输出列中
in、not in、exists和not exists的区别:
先谈谈in和exists的区别:
exists:存在,后面一般都是子查询,当子查询返回行数时,exists返回true。
| select * from class where exists (select'x"form stu where stu.cid=class.cid) |
当in和exists在查询效率上比较时,in查询的效率快于exists的查询效率
exists(xxxxx)后面的子查询被称做相关子查询, 他是不返回列表的值的.只是返回一个ture或false的结果(这也是为什么子查询里是select 'x'的原因 当然也可以select任何东西) 也就是它只在乎括号里的数据能不能查找出来,是否存在这样的记录。
其运行方式是先运行主查询一次 再去子查询里查询与其对应的结果 如果存在,返回ture则输出,反之返回false则不输出,再根据主查询中的每一行去子查询里去查询.
执行顺序如下:
1.首先执行一次外部查询
2.对于外部查询中的每一行分别执行一次子查询,而且每次执行子查询时都会引用外部查询中当前行的值。
3.使用子查询的结果来确定外部查询的结果集。如果外部查询返回100行,SQL 就将执行101次查询,一次执行外部查询,然后为外部查询返回的每一行执行一次子查询。
in:包含查询和所有女生年龄相同的男生
| select * from stu where sex='男' and age in(select age from stu where sex='女') |
in()后面的子查询 是返回结果集的,换句话说执行次序和exists()不一样.子查询先产生结果集,然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出.
not in和not exists的区别:
not in 只有当子查询中,select 关键字后的字段有not null约束或者有这种暗示时用not in,另外如果主查询中表大,子查询中的表小但是记录多,则应当使用not in,
例如:查询那些班级中没有学生的,
| select * from class where cid not in(select distinct cid from stu) |
当表中cid存在null值,not in 不对空值进行处理
解决:select * from classwhere cid not in
(select distinct cid from stu where cid is not null)
not in的执行顺序是:是在表中一条记录一条记录的查询(查询每条记录)符合要求的就返回结果集,不符合的就继续查询下一条记录,直到把表中的记录查询完。也就是说为了证明找不到,所以只能查询全部记录才能证明。并没有用到索引。
not exists:如果主查询表中记录少,子查询表中记录多,并有索引。
例如:查询那些班级中没有学生的,
select * from class2
where not exists
(select * from stu1 where stu1.cid =class2.cid)
not exists的执行顺序是:在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。
之所以要多用not exists,而不用not in,也就是not exists查询的效率远远高与not in查询的效率。
分组查询用法
掌握GROUP BY子句实现分组查询
| SELECT …… FROM <表名> WHERE …… GROUP BY …… |
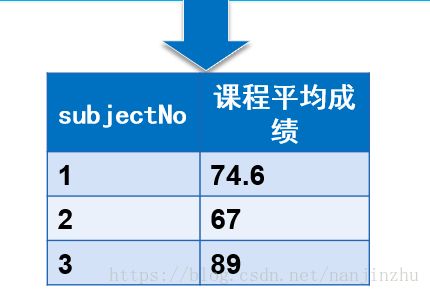
| SELECT `subjectNo`,AVG(`studentResult`) AS 课程平均成绩 FROM `result` GROUP BY `subjectNo`; |
| 注意:SELECT列表中只能包含: 1.被分组的列 2.为每个分组返回一个值的表达式,如聚合函数 |
分组查询解析
查询每门课程的平均分,并且按照分数由高到低的顺序排列显示
| SELECT `subjectNo`,AVG(`studentResult`) AS 课程平均成绩 FROM `result` GROUP BY `subjectNo` ORDER BY AVG(`studentResult`); |
| 课程编号 |
平均分 |
| 3 |
89 |
| 1 |
74.6 |
| 2 |
67 |
多列分组
分别统计每个年级男、女生人数
| SELECT `gradeId` AS 年级编号,`sex` AS 性别,COUNT(*) AS 人数 FROM `student` GROUP BY `gradeId`,`sex` ORDER BY `gradeId`; |
| 年级 |
性别 |
人数 |
| 1 |
女 |
4 |
| 1 |
男 |
4 |
| 2 |
女 |
1 |
| 2 |
男 |
1 |
| 3 |
女 |
2 |
分组筛选语句
| SELECT …… FROM <表名> WHERE …… GROUP BY …… HAVING…… |
示例:
| SELECT `subjectNo`,AVG(`studentResult`) AS 课程平均成绩 FROM `result` GROUP BY `subjectNo` HAVING AVG(`studentResult`) >=60; |
WHERE与HAVING对比
WHERE子句: 用来筛选 FROM 子句中指定的操作所产生的行
GROUP BY子句 : 用来分组 WHERE 子句的输出
HAVING子句: 用来从分组的结果中筛选行
常用的多表连接查询
内连接(INNER JOIN)外连接左外连接 (LEFT JOIN)右外连接 (RIGHT JOIN) |
内连接语句
| SELECT …… FROM 表1 INNER JOIN 表2 ON …… |
<--等价--> | SELECT …… FROM 表1,表2 WHERE …… |
示例:
| SELECT `student`.`studentName`,`result`.`subjectNo`,`result`.`studentResult` FROM `student`,`result` WHERE `student`.`studentNo` = `result`.`studentNo`; |
| SELECT S.`studentName`,R.`subjectNo`,R.`studentResult` FROM `student` AS S INNER JOIN `result` AS R ON (S.`studentNo` = R.`studentNo`); |
三表内连接
示例:
| SELECT S.studentName AS 姓名,SU.subjectName AS 课程,R.studentResult AS 成绩 FROM student AS S INNER JOIN `result` AS R ON (S.`studentNo` = R.`studentNo`) INNER JOIN `subject` AS SU ON (SU.subjectNo=R.subjectNo); |
左外连接

| 主表(左表)student中数据逐条匹配表result中的数据 1.匹配,返回到结果集 2.无匹配,NULL值返回到结果集 |
示例:
| SELECT S.studentName,R.subjectNo,R.studentResult FROM student AS S LEFT JOIN result AS R ON S.studentNo = R.studentNo; |
| SELECT S.studentName,R.subjectNo,R.studentResult FROM result AS R LEFT JOIN student AS S ON S.studentNo = R.studentNo; |
<以上两种查询结果不一样,因为主表和从表位置已互换>
右外连接
右外连接的原理与左外连接相同
右表逐条去匹配记录;否则NULL填充
示例:
| SELECT 图书编号,图书名称,出版社名称 FROM 图书表 RIGHT JOIN 出版社表 ON 图书表.出版社编号 = 出版社表.出版社编号; |

