一、总结
1、很郁闷,只爬到一千多条数据,就报告运行完毕了,原因未知,执行了两次,都一样。
不知道是不是做了什么限制,现在58 和赶集,的二手,都是叫做转转了 。
2、从url_list4 数据表中,一条一条取出来,放到函数中,解析商品详情,而后,写入item_info4
3、郁闷的事,没有找到商品上架时间,,我就把浏览 抓了出来 。
4、希望老师,跑一下程序,看看问题出在哪里 ?
二、抓图 展示 运行情况
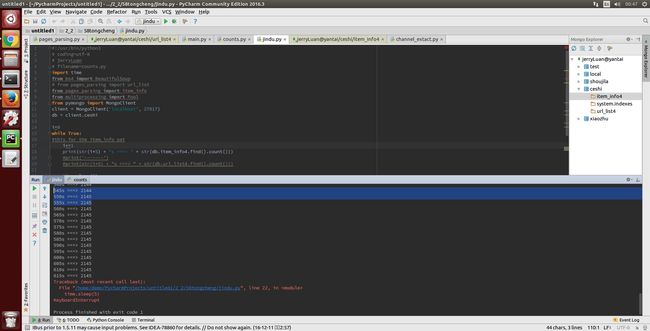
1112.png
1123.png
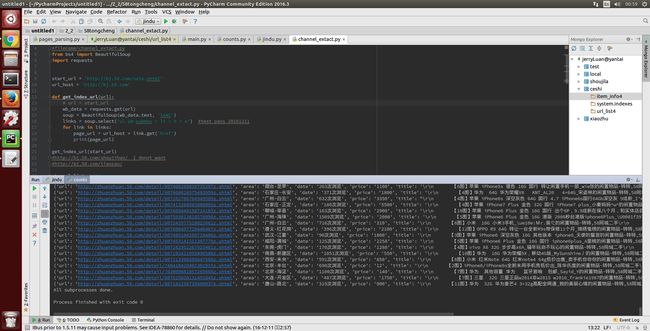
1124.png
一,所有代码
一共是5个文件 。
#!/usr/bin/python3
# coding=utf-8
# jerryLuan
#filename=channel_extact.py
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
def get_index_url(url):
# url = start_url
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
links = soup.select('ul.ym-submnu > li > b > a') #test pass 20161211
for link in links:
page_url = url_host + link.get('href')
print(page_url)
get_index_url(start_url)
#http://bj.58.com/shoujihao/ I donot want
#http://bj.58.com/tiaozao/
channel_list = '''
http://bj.58.com/shouji/
http://bj.58.com/tongxunyw/
http://bj.58.com/danche/
http://bj.58.com/fzixingche/
http://bj.58.com/diandongche/
http://bj.58.com/sanlunche/
http://bj.58.com/peijianzhuangbei/
http://bj.58.com/diannao/
http://bj.58.com/bijiben/
http://bj.58.com/pbdn/
http://bj.58.com/diannaopeijian/
http://bj.58.com/zhoubianshebei/
http://bj.58.com/shuma/
http://bj.58.com/shumaxiangji/
http://bj.58.com/mpsanmpsi/
http://bj.58.com/youxiji/
http://bj.58.com/jiadian/
http://bj.58.com/dianshiji/
http://bj.58.com/ershoukongtiao/
http://bj.58.com/xiyiji/
http://bj.58.com/bingxiang/
http://bj.58.com/binggui/
http://bj.58.com/chuang/
http://bj.58.com/ershoujiaju/
http://bj.58.com/bangongshebei/
http://bj.58.com/diannaohaocai/
http://bj.58.com/bangongjiaju/
http://bj.58.com/ershoushebei/
http://bj.58.com/yingyou/
http://bj.58.com/yingeryongpin/
http://bj.58.com/muyingweiyang/
http://bj.58.com/muyingtongchuang/
http://bj.58.com/yunfuyongpin/
http://bj.58.com/fushi/
http://bj.58.com/nanzhuang/
http://bj.58.com/fsxiemao/
http://bj.58.com/xiangbao/
http://bj.58.com/meirong/
http://bj.58.com/yishu/
http://bj.58.com/shufahuihua/
http://bj.58.com/zhubaoshipin/
http://bj.58.com/yuqi/
http://bj.58.com/tushu/
http://bj.58.com/tushubook/
http://bj.58.com/wenti/
http://bj.58.com/yundongfushi/
http://bj.58.com/jianshenqixie/
http://bj.58.com/huju/
http://bj.58.com/qiulei/
http://bj.58.com/yueqi/
http://bj.58.com/chengren/
http://bj.58.com/nvyongpin/
http://bj.58.com/qinglvqingqu/
http://bj.58.com/qingquneiyi/
http://bj.58.com/chengren/
http://bj.58.com/xiaoyuan/
http://bj.58.com/ershouqiugou/
'''
#!/usr/bin/python3
# coding=utf-8
# jerryLuan
# filename=jindu.py
import time
from bs4 import BeautifulSoup
# from pages_parsing import url_list
from pages_parsing import item_info
from multiprocessing import Pool
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.ceshi
i=0
while True:
#this for the item_info set
i+=1
print(str(i*5) + "s ===> " + str(db.item_info4.find().count()))
#print('-------')
#print(str(i*5) + "s ===> " + str(db.url_list4.find().count()))
time.sleep(5)
----------------
#!/usr/bin/python3
# coding=utf-8
#jerryLuan
#filename=counts.py
import time
from bs4 import BeautifulSoup
#from pages_parsing import url_list
from pages_parsing import item_info
from multiprocessing import Pool
#from channel_extact import channel_list
#from pages_parsing import get_links_from
from pages_parsing import get_item_info
import multiprocessing
import requests
import pymongo
import os
from pymongo import MongoClient
#client = MongoClient('localhost', 27017)
#db = client.ceshi
#uuu=db.url_list4
#cursor= uuu.find()
def insertbig():
client = MongoClient('localhost', 27017)
db = client.ceshi
uuu = db.url_list4
cursor = uuu.find()
for i in range(1,160000):
#time.sleep(2)
r=cursor.next()
url =r['url']
#url=cursor['url']
#print(url)
#url="http://zhuanzhuan.58.com/detail/784982311052254404z.shtml"
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
#print(soup)
#body > div.content > div > div.box_left > div.info_lubotu.clearfix > div.info_massege.left > div.button_li > span.soldout_btn
#kk=soup.find('script', type="text/javascript") #zenme faxian huaide
kk=soup.find('span',"soldout_btn")
#date = soup.select('.look_time')[0].text
#print(date)
#nnn=soup.select('div.palce_li span i')[0].text
#print(nnn)
#price = soup.select('span.price_now i')[0].text #ceshi 20161213 ok
#price = soup.select('span.price_now' > i).text
#price = soup.select(body > div.content > div > div.box_left > div.info_lubotu.clearfix > div.info_massege.left > div.price_li > span > i)
#div.price_li > span > i
#div.price_li > span
#body > div.content > div > div.box_left > div.info_lubotu.clearfix > div.info_massege.left > div.price_li > span > i
#print(price)
#qq=kk.text
#print(qq)
#no_longer_exist = '商品已下架' in (soup.find('span',"soldout_btn").text)
#print(no_longer_exist)
if kk!=None:
pass
else:
title = soup.title.text
price = soup.select('span.price_now i')[0].text
date = soup.select('.look_time')[0].text
area = soup.select('div.palce_li span i')[0].text if soup.find_all('div', 'palce_li') else None
#area = list(soup.select('div.place_li span i')[0].stripped_strings) if soup.find_all('span', 'c_25d') else None
item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
print({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
if __name__ == '__main__':
pool = Pool()
pool.apply_async(insertbig)
print('Waiting for all subprocesses done...')
pool.close()
pool.join()
print('All subprocesses done.')
'''
if __name__=='__main__':
pool=multiprocessing.Pool(2)
pool.apply_async(insertbig)
print 'Waiting for all subprocesses done...'
pool.close()
pool.join()
print 'All subprocesses done.'
pool = Pool()
#soldout_btn
#商品已下架
#http://zhuanzhuan.58.com/detail/784982311052254404z.shtml shangpin xiajia
print(kk)
#get_item_info(url)
#print("%s" %str(cursor.next()))
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.ceshi
print('sdfsdf')
#r= db.url_list4.findOne()
print(db.url_list4.find().count())
r= db.url_list4.findOne()
print(r)
i=0
#print(item_info.find().count())
r= db.url_list.find_one().pretty()
print(r)
import pymongo
import datetime
import random
#创建连接
conn = pymongo.Connection('localhost',27017)
#连接数据库
db = conn.study
while True:
#this for the item_info set
i+=1
print(str(i*5) + "s ===> " + str(item_info.find().count()))
time.sleep(5)
while True:
#this for the url_list set
i+=1
print(str(i*5) + "s ===> " + str(url_list.find().count()))
time.sleep(5)
while True:
i += 1
print(str(i)+ "kkkk"+ str(i*2))
if i>22:
break
'''
#!/usr/bin/python3
# coding=utf-8
#jerryLuan
#filename=main.py
from multiprocessing import Pool
from channel_extact import channel_list
from pages_parsing import get_links_from
from pages_parsing import get_item_info
def get_all_links_from(channel):
for i in range(1,111):
get_links_from(channel,i)
if __name__ == '__main__':
pool = Pool()
# pool = Pool(processes=6)
#pool.map(get_all_links_from,channel_list.split())
#get_item_info
-----
#!/usr/bin/python3
# coding=utf-8
#jerryLuan
#filename=pageers_parsing.py
from bs4 import BeautifulSoup
import requests
import time
import pymongo
client = pymongo.MongoClient('localhost', 27017)
ceshi = client['ceshi']
url_list = ceshi['url_list4']
item_info = ceshi['item_info4']
# 在最左边是在python 中对象的名称,后面的是在数据库中的名称
# spider 1
def get_links_from(channel, pages, who_sells=0):
# td.t 没有这个就终止
list_view = '{}{}/pn{}/'.format(channel, str(who_sells), str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text, 'lxml')
if soup.find('td', 't'):
for link in soup.select('td.t a.t'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url': item_link})
print(item_link)
# return urls
else:
# It's the last page !
pass
# spider 2
def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
no_longer_exist = '404' in (str(soup.find('script', type="text/javascript").get('src')).split('/'))
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price.c_f50')[0].text
date = soup.select('.time')[0].text
area = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span', 'c_25d') else None
item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
print({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})