【Web编程实践课第一次作业】体育新闻爬虫
僕の世界から君を無くしたら 如果我的世界没有你
意味が無いから 无论何事都尽失意义
君の世界まで僕が向かうから 我会向着你的世界奔去
待っててくれるかな 请你等着我好吗
——《君のいない夜を越えて》
跑错片场了。
2020年3月12日上午8:00~9:30,通过微信群平台,我们完成了Web编程第一次实践课;而在13日,我也完成了第一次作业的编程任务。

实验内容
此次实验的内容是,通过Node.js实现一个新闻爬虫,从3~5个新闻网站中爬取新闻信息,同时提取出标题、摘要、内容、时间、作者、来源等等信息。
要求是,必须使用Node.js实现爬虫,用Node.js实现网络后端,用HTML实现前端,且不使用任何前端框架。
实验效果
先看最终的效果如何——
前端效果:

单关键词搜索效果:
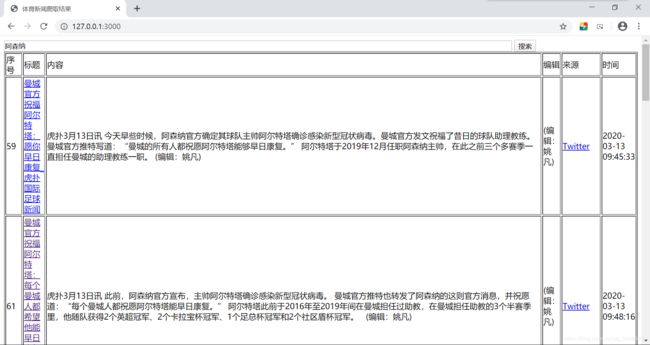
多关键词搜索效果:

准备
首先使用npm安装cheerio和request包,方法是,在控制台输入
npm install -g cheerio
npm install -g request
但事实证明,npm给我扔了一个EINVALIDPACKAGENAME异常,百度后得知,国家有一堵伟大的墙挡住了我学习的脚步。
于是我在用户文件夹下的.npmrc文件中加入了如下几行:
proxy=null
registry=https://registry.npm.taobao.org/
disturl=https://npm.taobao.org/dist
使用了淘宝的镜像站,成功下载了cheerio和request依赖包。

分析页面
虎扑
首先在程序中敲入如下代码:
'use strict'; //使用严格模式
var http = require('http'); //http包
var myRequest = require('request'); //request包
var myCheerio = require('cheerio'); //cheerio包,用法与jQuery极其相似
var fs = require('fs'); //fs包,用于读文件
function getNewsPage(url, callback) { //请求新闻导航页
var options = {
url: url, encoding: null, headers: null
}
myRequest(options, callback);
}
function request(url, callback) { //请求某一新闻帖页面
var options = {
url: url,
encoding: null,
headers: null
}
myRequest(options, callback);
}
//标题、内容、编者、来源、时间以及新闻地址
var Titles = new Array();
var Contexts = new Array();
var Editor = new Array();
var ComeFrom = new Array();
var ComeURLs = new Array();
var DateTime = new Array();
var URLs = new Array();
接着,我们进入虎扑的四个新闻网站:
https://voice.hupu.com/soccer
https://voice.hupu.com/nba
https://voice.hupu.com/china
https://voice.hupu.com/cba
按F12审查元素,观察他们的前端代码:
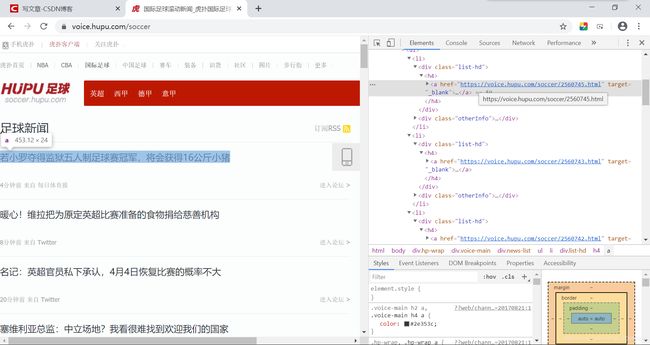
我们得到一个结论:进入这些新闻页面的链接,都在每个h4标签中的a子标签的href属性之中。
接下来,我们点开一个页面进入,并查看源码:
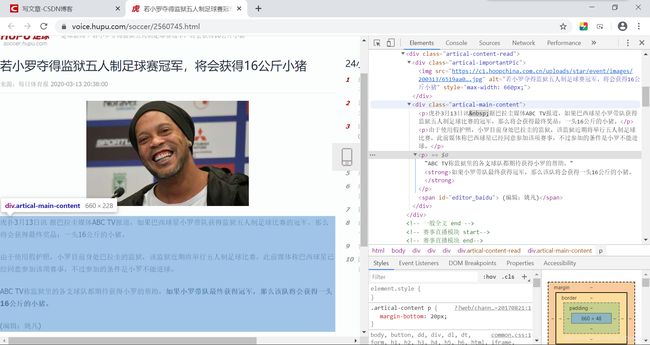
可以看到,新闻的标题正好是网页的标题title的内容,正文则是div[class=“artical-main-content”]标签下的内容,编者、来源、时间等分别来自于span[id=“editor_baidu”]、span[class=“comeFrom”]的a子标签、span[id=“pubtime_baidu”]。
顺便吐槽一句,为什么命名为baidu呢,和百度公司有关系吗?

那么虎扑新闻网的爬虫也就写好了:
var hupuSpider = {
NewsURLs : [
"https://voice.hupu.com/soccer",
"https://voice.hupu.com/nba",
"https://voice.hupu.com/china",
"https://voice.hupu.com/cba"
], //虎扑的几个新闻网页
GetURL: function (err, res, body) { //从新闻总页获取统一资源定位器,并爬取信息
var BuildDataset = function (err, res, body) {
if (err || res.statusCode != 200) { //失败
Titles.push(`新闻抓取失败-${err}`);
Contexts.push('暂无内容');
Editor.push('暂无编者');
ComeFrom.push('暂无来源');
ComeURLs.push('');
DateTime.push('暂无时间')
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//console.log($.html()); //Debug代码,输出网页源码
URLs.push(res.request.uri.href); //将解析的信息塞进数组
Titles.push($('title').text());
Contexts.push($('div[class="artical-main-content"]').text());
Editor.push($('span[id="editor_baidu"]').text());
ComeFrom.push($('span[class="comeFrom"]').children("a").text());
ComeURLs.push($('span[class="comeFrom"]').children("a").attr("href"));
DateTime.push($('span[id="pubtime_baidu"]').text());
}
};
if (err || res.statusCode != 200) { //err不为null,说明出现了异常
console.log(`新闻抓取失败-${err}`);
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//找到第cnt个标签中的href属性
let cnt = 0; //新闻子页面的计数器
let h4Arr = $("h4").eq(cnt);
let str = h4Arr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
console.log(str);
request(str, BuildDataset);
++cnt;
h4Arr = $("h4").eq(cnt);
str = h4Arr.children("a").attr("href");
}
}
}
};
球天下
由于期望获取到的信息更加多元化 (其实是不满虎扑爬取难度过低) ,3月23日,我为爬虫添加了球天下这一新闻获取渠道。
比起虎扑,球天下的爬取难度略微高一些。
球天下主要有两个新闻网页:
https://www.qtx.com/
https://www.qtx.com/others
这两个网页虽然看起来并不一样,但前端代码还是有几分相似的。
首先,观察发现,所有新闻内容都在div[class=“baseNewsList”]之中:

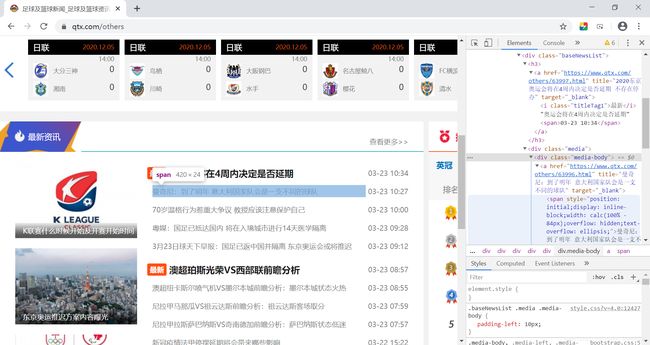
其次,所有的链接都在h3、h4、div[class=“media-body”]、a这四种标签之中。所以,只要用cheerio定位这些标签就可以。
接下来就是每个新闻网页中内容的提取了,随便点开一个网页:

我们发现,其网页标题依然是新闻标题,正文位于div[class=“artContent”]标签中。编者反而位于右侧,是球天下的注册用户,其用户名位于div[class=“bzhead”]标签下的p子标签中。来源和时间都在div[class=“mes”]标签中,需要根据空格来分离开。
那么球天下的爬虫也可以写好了:
var qtxSpider = {
NewsURLs: [
"https://www.qtx.com/others",
"https://www.qtx.com/"
], //球天下新闻网页
GetURL : function (err, res, body) { //从新闻总页获取统一资源定位器,并爬取信息
var BuildDataset = function (err, res, body) {
if (err || res.statusCode != 200) { //失败
Titles.push(`新闻抓取失败-${err}`);
Contexts.push('暂无内容');
Editor.push('暂无编者');
ComeFrom.push('暂无来源');
ComeURLs.push('');
DateTime.push('暂无时间')
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//console.log($.html()); //Debug代码,输出网页源码
URLs.push(res.request.uri.href); //将解析的信息塞进数组
Titles.push($('title').text());
Contexts.push($('div[class="artContent"]').text());
Editor.push($('div[class="bzhead"]').children('p').text());
ComeFrom.push($('div[class="mes"]').text().split(" ")[0]);
ComeURLs.push($('div[class="mes"]').children("a").attr("href"));
DateTime.push(($('div[class="mes"]').text().split(" ")[1] + $('div[class="mes"]').text().split(" ")[2]).toString().replace("年", "-").replace("月", "-").replace("日", " "));
}
};
if (err || res.statusCode != 200) { //err不为null,说明出现了异常
console.log(`新闻抓取失败-${err}`);
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
let baseNewsList = $('div[class="baseNewsList"]');
//找到news列表中的第cnt个标签中的href属性
let cnt = 0; //新闻子页面的计数器
let h3Arr = baseNewsList.children("h3").eq(cnt);
let str = h3Arr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
console.log(str);
request(str, BuildDataset);
++cnt;
h3Arr = baseNewsList.children("h3").eq(cnt);
str = h3Arr.children("a").attr("href");
}
//找到news列表中的第cnt个标签中的href属性
cnt = 0;
let h4Arr = baseNewsList.children("h4").eq(cnt);
str = h4Arr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
console.log(str);
request(str, BuildDataset);
++cnt;
h4Arr = baseNewsList.children("h4").eq(cnt);
str = h4Arr.children("a").attr("href");
}
//找到news列表中的第cnt个标签下标签中的href属性
cnt = 0;
let divArr = baseNewsList.children("div").eq(cnt).children("div");
str = divArr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
console.log(str);
request(str, BuildDataset);
++cnt;
divArr = baseNewsList.children("div").eq(cnt).children("div");
str = divArr.children("a").attr("href");
}
//找到news列表中的第cnt个标签的href属性
cnt = 0;
let aArr = baseNewsList.children("a").eq(cnt);
str = aArr.attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
console.log(str);
request(str, BuildDataset);
++cnt;
aArr = baseNewsList.children("a").eq(cnt);
str = aArr.attr("href");
}
}
}
};
搜狐体育
搜狐体育是我最想吐槽的新闻网站,没有之一。
好吧。3月24日我为了挑战自己,为爬虫增加了搜狐体育的渠道。
这一渠道的第一个问题则是导航页过多:
https://sports.sohu.com/s/integrated
https://sports.sohu.com/s/csl
https://sports.sohu.com/s/cnmenfootball
https://sports.sohu.com/s/ccl
https://sports.sohu.com/s/afccl
https://sports.sohu.com/s/premierleague
https://sports.sohu.com/s/bundesliga
https://sports.sohu.com/s/laliga
https://sports.sohu.com/s/ligue1
https://sports.sohu.com/s/seriea
https://sports.sohu.com/s/uefacl
https://sports.sohu.com/s/nba
https://sports.sohu.com/s/cba
https://sports.sohu.com/s/tcb
https://sports.sohu.com/s/wcba
https://sports.sohu.com/s/badminton
https://sports.sohu.com/s/pingpong
https://sports.sohu.com/s/billiards
https://sports.sohu.com/s/swimming
https://sports.sohu.com/s/running
https://sports.sohu.com/s/volleyball
https://sports.sohu.com/s/golf
https://sports.sohu.com/s/e_sport
https://sports.sohu.com/s/tennis
https://sports.sohu.com/s/chess
https://sports.sohu.com/s/boxing
https://sports.sohu.com/s/racing
https://sports.sohu.com/s/bicycle
https://sports.sohu.com/s/uefael
https://sports.sohu.com/s/womenfootball
https://sports.sohu.com/s/cfac
https://sports.sohu.com/s/sailing
https://sports.sohu.com/s/euro2020
https://sports.sohu.com/s/afac
https://sports.sohu.com/s/fifa

所有新闻都在ul[class=“news-list first”]和ul[class=“news-list second”]两个列表的li标签中。
然而这些导航页的链接,让爬虫报错了——我的爬虫发现无法访问到这些链接。
无奈之下查看了网页源代码,望着这只有一行的网页源码,我捡起了掉在键盘上的那把头发。
结果发现,这些链接,有的是变量不全,有的没有“https:”……
于是我在爬取过程中,对这些不合法的链接进行清洗。
终于完成了导航页的问题,接下来是新闻页面:

可以发现,新闻标题依然是网页标题;而内容在article[class=“article”]中;作者在左侧div[class=“user-info”]下的h4子标签中;时间则在span[class=“time”]之中。
那么接下来就可以写好搜狐体育新闻爬虫啦!
var sohuSpider = {
NewsURLs: [
"https://sports.sohu.com/s/integrated",
"https://sports.sohu.com/s/csl",
"https://sports.sohu.com/s/cnmenfootball",
"https://sports.sohu.com/s/ccl",
"https://sports.sohu.com/s/afccl",
"https://sports.sohu.com/s/premierleague",
"https://sports.sohu.com/s/bundesliga",
"https://sports.sohu.com/s/laliga",
"https://sports.sohu.com/s/ligue1",
"https://sports.sohu.com/s/seriea",
"https://sports.sohu.com/s/uefacl",
"https://sports.sohu.com/s/nba",
"https://sports.sohu.com/s/cba",
"https://sports.sohu.com/s/tcb",
"https://sports.sohu.com/s/wcba",
"https://sports.sohu.com/s/badminton",
"https://sports.sohu.com/s/pingpong",
"https://sports.sohu.com/s/billiards",
"https://sports.sohu.com/s/swimming",
"https://sports.sohu.com/s/running",
"https://sports.sohu.com/s/volleyball",
"https://sports.sohu.com/s/golf",
"https://sports.sohu.com/s/e_sport",
"https://sports.sohu.com/s/tennis",
"https://sports.sohu.com/s/chess",
"https://sports.sohu.com/s/boxing",
"https://sports.sohu.com/s/racing",
"https://sports.sohu.com/s/bicycle",
"https://sports.sohu.com/s/uefael",
"https://sports.sohu.com/s/womenfootball",
"https://sports.sohu.com/s/cfac",
"https://sports.sohu.com/s/sailing",
"https://sports.sohu.com/s/euro2020",
"https://sports.sohu.com/s/afac",
"https://sports.sohu.com/s/fifa"
], //搜狐新闻网页
GetURL: function (err, res, body) { //从新闻总页获取统一资源定位器,并爬取信息
var BuildDataset = function (err, res, body) {
if (err || res.statusCode != 200) { //失败
Titles.push(`新闻抓取失败-${err}`);
Contexts.push('暂无内容');
Editor.push('暂无编者');
ComeFrom.push('暂无来源');
ComeURLs.push('');
DateTime.push('暂无时间')
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//console.log($.html()); //Debug代码,输出网页源码
URLs.push(res.request.uri.href); //将解析的信息塞进数组
Titles.push($('title').text());
Contexts.push($('article[class="article"]').text());
Editor.push($('div[class="user-info"]').children('h4').text());
ComeFrom.push($('a[id="backsohucom"]').text());
ComeURLs.push($('a[id="backsohucom"]').attr("href"));
DateTime.push($('span[class="time"]').text());
}
};
if (err || res.statusCode != 200) { //err不为null,说明出现了异常
console.log(`新闻抓取失败-${err}`);
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//找到news列表中的第cnt个标签下- 标签中的href属性
let cnt = 0; //新闻子页面的计数器
let newsList = $('ul[class="news-list first"]');
let liArr = newsList.children("li").eq(cnt);
let str = liArr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
str = "https://" + str.split("//")[1].split("?")[0]; //在此强烈谴责某狐程序员
console.log(str);
request(str, BuildDataset);
++cnt;
liArr = newsList.children("li").eq(cnt);
str = liArr.children("a").attr("href");
}
//找到news列表中的第cnt个标签下- 标签中的href属性
cnt = 0;
newsList = $('ul[class="news-list second"]');
liArr = newsList.children("li").eq(cnt);
str = liArr.children("a").attr("href");
while (str) { //如果找得到,那么输出并继续寻找下一个
str = "https://" + str.split("//")[1].split("?")[0]; //再次强烈谴责某狐程序员
console.log(str);
request(str, BuildDataset);
++cnt;
liArr = newsList.children("li").eq(cnt);
str = liArr.children("a").attr("href");
}
}
}
};
这之后,我们的数组中已经包含了所有信息。接下来就看如何呈现出来。

前端设计
我期望的效果是,网页主要有一个表格构成,这个表格展示了所有新闻的标题、内容、编者、来源、时间,同时可以点击新闻标题和来源跳转至相应网站。此外,表格头部还要有一个搜索框,用于筛选新闻。
表格,众所周知,需要用到table标签,其中每一行都是一个tr标签,该行每个单元格都是一个td标签。
同时每一行需要一个id属性,便于搜索时隐藏无关信息。
而检索算法则是,通过空格分隔关键词,然后对所有新闻进行匹配,如果某一新闻不包含这些关键词中的任意一个,那么它将会被隐藏。否则将会将其保留显示。
这里可以做一些优化,比如用jieba分词,然后再进行匹配。这样代码就稍显复杂,下面则是我的实现方法:
for (let x in hupuSpider.NewsURLs) {
getNewsPage(hupuSpider.NewsURLs[x], hupuSpider.GetURL);
} //根据虎扑导航页获取新闻信息
for (let x in qtxSpider.NewsURLs) {
getNewsPage(qtxSpider.NewsURLs[x], qtxSpider.GetURL);
} //根据球天下导航页获取新闻信息
for (let x in sohuSpider.NewsURLs) {
getNewsPage(sohuSpider.NewsURLs[x], sohuSpider.GetURL);
} //根据搜狐导航页获取新闻信息
let $ = myCheerio.load(`
体育新闻爬取结果
`); //网页标题与输入框
$("table").append(`
序号
标题
内容
编辑
来源
时间
`); //表头
http.createServer(function (req, res) { //建立网站
for (let x in URLs) { //完善表格
$("table").append(`
${x}">
${x}
${URLs[x]}" id="t${x}">${Titles[x]}
${x}">${Contexts[x]} ${Editor[x]}
${ComeURLs[x]}">${ComeFrom[x]}
${DateTime[x]}
`); //表格中插入一行
}
$("body").append(`
`); //搜索关键词代码
let body = $.html(); //将cheerio处理的html设置为网页源码
res.writeHead(200, {'Content-type': 'text/html'});
res.end(body);
}).listen(3000); //监听3000端口
后端——数据库
4月1日,我用数据库代替了数组,完善了爬虫程序。
首先是引入MySQL:
//database包
var mysql = require("mysql"); //mysql包,存放数据
var pool = mysql.createPool({
host: 'localhost',
port: 3306,
user: 'root',
password: 'root',
database: 'newslist'
});
var query = function (sql, sqlparam, callback) {
pool.getConnection(function (err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, sqlparam, function (qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
var query_noparam = function (sql, callback) {
pool.getConnection(function (err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, function (qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
exports.query = query;
exports.query_noparam = query_noparam;
然后定义两个函数:
var database = require('./database'); //自定义database包,与数据库交互
//MySQL语句
function query_and_request(str, BuildDataset) {
database.query('select URL from fetches where URL=?', [str], function (qerr, vals, fields) {
if (qerr) {
console.error(`数据库查重失败-${qerr}`);
} else {
if (vals.length > 0) {
console.log(`\t-查重到${vals.length}条信息`);
} else {
request(str, BuildDataset);
}
}
});
}
function query_and_insert(myFetch) {
database.query('INSERT INTO fetches(URL,Title,Content,Editor,ComeFrom,ComeURL,DateTime) VALUES(?,?,?,?,?,?,?)',
[myFetch.URL, myFetch.Title, myFetch.Content, myFetch.Editor, myFetch.ComeFrom, myFetch.ComeURL, myFetch.DateTime],
function (qerr, vals, fields) {
if (qerr) {
console.error(`数据库插入失败-${qerr}`);
}
});
}
然后在所有调用request的位置,修改为:
query_and_request(str, BuildDataset);
每个爬虫的BuildDataset函数也要重写,以虎扑爬虫为例,其代码应修改为:
var BuildDataset = function (err, res, body) {
if (err || res.statusCode != 200) { //失败
console.error(`新闻页面抓取失败-${err}`);
} else {
let html = body; //网页源码,送入cheerio解析
let $ = myCheerio.load(html, { decodeEntities: false });
//console.log($.html()); //Debug代码,输出网页源码
var myFetch = {}; //抓取信息
//将解析的信息塞进数组
myFetch.URL = res.request.uri.href;
myFetch.Title = $('title').text();
myFetch.Content = $('div[class="artical-main-content"]').text();
myFetch.Editor = $('span[id="editor_baidu"]').text();
myFetch.ComeFrom = $('span[class="comeFrom"]').children("a").text();
myFetch.ComeURL = $('span[class="comeFrom"]').children("a").attr("href");
myFetch.DateTime = new Date($('span[id="pubtime_baidu"]').text());
query_and_insert(myFetch);
}
};
主函数则是一个让我调了两天的回调地狱:
for (let x in hupuSpider.NewsURLs) {
getNewsPage(hupuSpider.NewsURLs[x], hupuSpider.GetURL);
} //根据虎扑导航页获取新闻信息
for (let x in qtxSpider.NewsURLs) {
getNewsPage(qtxSpider.NewsURLs[x], qtxSpider.GetURL);
} //根据球天下导航页获取新闻信息
for (let x in sohuSpider.NewsURLs) {
getNewsPage(sohuSpider.NewsURLs[x], sohuSpider.GetURL);
} //根据搜狐导航页获取新闻信息
//网页标题与输入框
let $ = myCheerio.load(fs.readFileSync("./html/index.html"));
$("table").append(`
序号
标题
内容
编辑
来源
时间
`); //表头
//完善表格
var cnt = 0;
http.createServer(function (req, res) { //建立网站
database.query_noparam("SELECT * from fetches", function (qerr, vals, fields) {
if (qerr) {
console.error(`数据库查询失败-${qerr}`);
return;
}
cnt = vals.length;
for (var x = 0; x < cnt; ++x) {
var myFetch = vals[x];
$("table").append(`
${x}">
${x}
${myFetch.URL}" id="t${x}">${myFetch.Title}
${x}">${myFetch.Content} ${myFetch.Editor}
${myFetch.ComeURL}">${myFetch.ComeFrom}
${myFetch.DateTime}
`); //表格中插入一行
}
$("body").append(`
`); //搜索关键词代码
let body = $.html(); //将cheerio处理的html设置为网页源码
res.writeHead(200, { 'Content-type': 'text/html' });
res.end(body);
console.log("成功建立网站!");
});
}).listen(3000); //监听3000端口
网页html我也是单独放在了一个文件index.html之中:
<html>
<head>
<meta charset="utf-8">
<title>体育新闻爬取结果title>
head>
<body>
<input type="text" name="keyword" style="width:1000px;" value="震惊!华东师范大学信息学部足球队门将刘冬煜竟开发出这种网站……" id="SearchText">
<input type="button" value="搜索" onclick="SearchForKeyword()">
<table border="1">
table>
body>
html>
于是我们的爬虫就大功告成啦!

测试
3月14日
至于实时爬取,3月14日我再次截图:

输入关键词“鲁能”、“佩莱”:
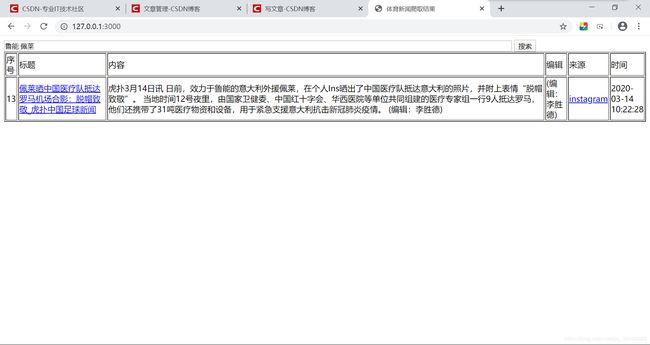
3月21日
武磊于今日确诊的消息已经刷屏了空间微博朋友圈。再度爬取新闻,希望磊哥挺住!
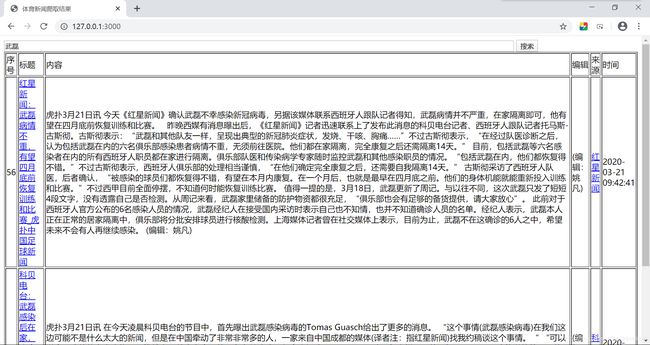
3月23日
昨日山东增加了一例输入病例,出乎我意料的是,这位患者正是鲁能泰山队的中场外援费莱尼。今日我再次爬取新闻,并关注因为疫情造成的欧洲五大联赛的消息。


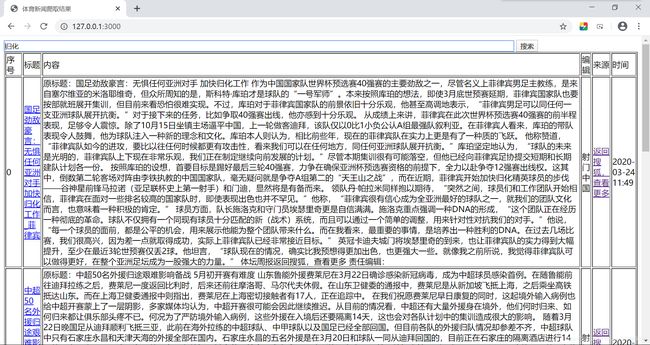
3月24日
增加了新闻获取渠道,再次爬取,并提取出关于国足归化的消息。
4月1日
今年愚人节,我完成了数据库的编写工作,并以愚人节为关键词再度搜索:

心得体会
这一次实验课让我近距离接触了最基本的前后端设计与开发,一直在算法岗工作的我,面对迎面而来的很多困难,一时不知如何下手。
起初,我不知如何下载依赖,即使使用npm也无法下载成功,报错连连。百度后才知道需要使用镜像站才能成功。
接着,我开始使用的建站方法是:
res.writeHead(200, {'Content-Type': 'text/plain; charset=utf-8'});
但事实证明它并不能显示html代码所表示的界面。多方查资料才知道需要使用:
res.writeHead(200, {'Content-type': 'text/html'});
构建缓冲区、完成Header的搭建,然后才能显示前端界面。
后来,我发现点击新闻的标题,跳转的链接和标题并不匹配,因为我将:
URLs.push(url);
写在了request函数中,由于Node.js的异步特性,每个网站的响应时间不同,使得url与内容未必匹配。最终我将它放到了request的回调函数中。
最后,我未把向表格中插入行写在createServer的回调函数中,结果因为Node.js的异步特性,网站并未能像我预期的那样展示所有新闻项。直到百度后才渐渐理解了回调函数对运行同步的贡献。
前后端开发并没有我想象中那么容易,所谓鄙视链也只是业界玩笑而已。
这次爬虫项目比较成功,今后我也将继续努力。
希望疫情早些过去。武汉加油,中国加油,世界加油!