Hbase高可用集群搭建
主机配置环境如下表
| 主机名 | IP | 系统 | 软件版本 | 安装目录 |
|---|---|---|---|---|
| hadoop-01 | 192.168.10.51 | Centos 7.6 | hadoop-2.7.7、jdk1.8、zookeeper-3.4.6、hbase-2.1.5 | /usr/local/hbase |
| hadoop-02 | 192.168.10.52 | Centos 7.6 | hadoop-2.7.7、jdk1.8、zookeeper-3.4.6、hbase-2.1.5 | /usr/local/hbase |
| hadoop-03 | 192.168.10.53 | Centos 7.6 | hadoop-2.7.7、jdk1.8、zookeeper-3.4.6、hbase-2.1.5 | /usr/local/hbase |
安装后进程运行进程如下
| hadoop-01 | hadoop-02 | hadoop-03 |
|---|---|---|
| NodeManager | NodeManager | NodeManager |
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| DFSZKFailoverController | DFSZKFailoverController | |
| JournalNode | JournalNode | JournalNode |
| ResourceManager | ResourceManager | |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| HMaster | HMaster | |
| HRegionServer | HRegionServer | HRegionServer |
相对上篇安装hadoop集群,多了HMaster、HRegionServer两个进程
详细搭建过程如下:
1 修改配置文件
(1)将hbase安装包解压,重命名为hbase,拷贝至/usr/local目录下
(2)修改配置文件,所有的配置文件都在/usr/local/hbase/conf/目录下
修改hbase-env.sh,需要修改3处
# The java implementation to use. Java 1.8+ required.
# 配置JDK
export JAVA_HOME=/usr/java/jdk1.8.0_131/
# 如果ssh默认端口不是22,需要添加此条配置语句
export HBASE_SSH_OPTS="-p 9431"
# The directory where pid files are stored. /tmp by default.
# 保存pid文件
export HBASE_PID_DIR=/usr/local/hbase/pids
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
# 修改HBASE_MANAGES_ZK,禁用HBase自带的Zookeeper,因为我们是使用独立的Zookeeper
export HBASE_MANAGES_ZK=false
配置 hbase-site.xml
hbase.rootdir
hdfs://cluster/hbase
hbase.master.info.port
60010
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop-01:2181,hadoop-02:2181,hadoop-03:2181
hbase.zookeeper.property.dataDir
/usr/local/zookeeper-3.4.6
hbase.zookeeper.property.clientPort
2181
编辑regionservers
hadoop-01
hadoop-02
hadoop-03
(3) 创建pid文件保存目录
mkdir /usr/local/hbase/pids
(4) 拷贝hbase目录到其它节点
[root@hadoop-01 ~]# scp -r -P 9431 /usr/local/hbase hadoop-02:/usr/local/
[root@hadoop-01 ~]# scp -r -P 9431 /usr/local/hbase hadoop-03:/usr/local/
(5) 配置hbase环境变量(3台)
# vim /etc/profile.d/hbase.sh
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
(6)启动hbase
在主节点上启动HBase(主节点指Hadoop的NameNode节点状态为active的节点,非指文中的机器声明):
cd /usr/local/hbase/bin/
sh start-hbase.sh
查看HMaster、Regionserver进程是否启动
[root@hadoop-01 ~]# jps | grep -v Jps
26849 NodeManager
2770 QuorumPeerMain
27331 DFSZKFailoverController
29971 HRegionServer
26308 DataNode
26537 JournalNode
26154 NameNode
29835 HMaster
26733 ResourceManager
注意:此时Hadoop集群应处于启动状态,并且是在主节点执行start-hbase.sh启动HBase集群,否则HMaster进程将在启动几秒后消失,
而备用的HMaster进程需要在备用主节点单独启动,命令是:./hbase-daemon.sh start master。
在备用主节点启动HMaster进程,作为备用HMaster:
/usr/local/hbase/bin/hbase-daemon.sh start master
[root@hadoop-02 ~]# jps | grep -v Jps
7489 JournalNode
7281 NameNode
627 QuorumPeerMain
10424 HRegionServer
8233 DFSZKFailoverController
11627 HMaster
8123 ResourceManager
7389 DataNode
7631 NodeManager
(7) 通过浏览器查看hbase信息
浏览器访问http://192.168.10.51:60010
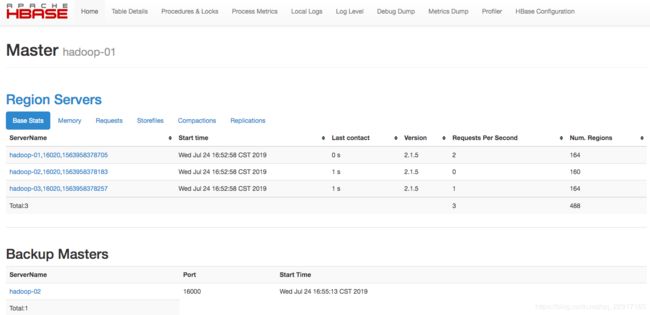
浏览器访问http://192.168.10.52:60010
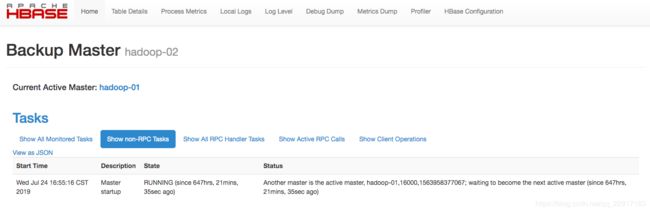
可以看到,在hadoop-02上显示“Current Active Master: master188”,表示当前HBase主节点是hadoop-01机器
(8) HA高可用测试
kill掉主节点的HMaster进程,在浏览器中查看备用主节点的HBase是否切换为active;
若上述操作成功,则在主节点启动被杀死的HMaster进程:
/usr/local/hbase/bin/hbase-daemon.sh start master
然后,kill掉备用主节点的HMaster进程,在浏览器中查看主节点的HBase是否切换为active,若操作成功,则HBase高可用集群搭建完成;
在此做下总结:
1)备用节点上的zkfc、NameNode、ResourceManager、HMaster均需单独启动;
hadoop-daemon.sh start namenode
yarn-daemon.sh start resourcemanager
hbase-daemon.sh start master
2)在备用主节点同步主节点的元数据时,主节点的HDFS必须已经启动;
3)格式化namenode时要先启动各个JournalNode机器上的journalnode进程:
否则会报journalnode拒绝连接错误